When running open-source LLMs in production, you probably hit GPU limits faster than expected.
VRAM fills up quickly. The KV cache grows with every request. Latency spikes as soon as concurrency increases. A model that works fine in a demo actually needs multiple high-end GPUs for production.
For many teams, proprietary models like GPT-5 feel like an easy way out. A simple API call hides the complexity of GPU memory management, batching, and scaling. However, that convenience comes with [trade-offs](https://www.bentoml.com/blog/chatgpt-u…
When running open-source LLMs in production, you probably hit GPU limits faster than expected.
VRAM fills up quickly. The KV cache grows with every request. Latency spikes as soon as concurrency increases. A model that works fine in a demo actually needs multiple high-end GPUs for production.
For many teams, proprietary models like GPT-5 feel like an easy way out. A simple API call hides the complexity of GPU memory management, batching, and scaling. However, that convenience comes with trade-offs: vendor lock-in, limited customization, unpredictable pricing at scale, and ongoing concerns about data privacy.
This tension brings teams back to self-hosting. The good news is that you no longer need large models to get strong results. Over the past year, advances in distillation, training data, and post-training have made small language models far more capable than their parameter counts suggest. Many now deliver solid reasoning, coding, and agentic performance, and fit comfortably on a single GPU.
In this post, we’ll look at the best open-source small language models, and explain when and why they make sense in certain cases. After that, we’ll answer some FAQs teams have when evaluating them for production deployments.
What are small language models?#
Small language models (SLMs) are best defined by their deployability, not just their parameter count. In practice, the term usually refers to models ranging from a few hundred million to around 10 billion parameters that can run reliably in resource-constrained environments.
Some people might think SLMs are impractical for production. They are faster and cheaper to run, but noticeably weaker at reasoning, coding, and instruction following tasks. In fact, that gap has narrowed significantly with recent advances:
- Distillation from frontier models transfers reasoning and instruction-following behaviors into much smaller architectures.
- Higher-quality training data improves generalization without brute-force scaling.
- Post-training techniques such as reinforcement learning refine behavior for real-world tasks.
- Advanced inference frameworks and stacks make better use of limited GPU memory
Today, many popular open-source LLM families offer small parameter variants that are strong enough for production use. They power chatbots, agent pipelines, and high-throughput automation workflows where latency, cost, and operational simplicity matter more than sheer model size.
Now, let’s take a look at the top SLMs.
Gemma-3n-E2B-IT#
Gemma-3n-E2B-IT is an instruction-tuned multimodal small model from Google DeepMind, built for on-device and other low-resource deployments. It accepts text, image, audio, and video inputs and generates text outputs.
While the raw parameter count is around 5B, it uses selective parameter activation, so it can run with a memory footprint closer to a traditional 2B model in many deployments.
The Gemma 3n family is trained on data spanning 140+ languages, which is a big deal if you need multilingual support without jumping to much larger models.
Why should you use Gemma-3n-E2B-IT:
- Multimodal by design (text, image, audio, video). If you need one model that can transcribe speech, describe an image, analyze a short clip, and still handle normal chat, Gemma 3n is built for that from the ground up.
- Mobile-first architecture. Gemma 3n pairs the language model with efficient encoders, including a mobile-optimized vision encoder and an integrated audio encoder. This makes it a good fit for real-time or near-real-time on-device experiences.
- Solid baseline quality. For many product features (e.g., captioning, transcription, translation, lightweight Q&A), the quality is good enough without the cost and latency of larger models. If you need better performance, consider the E4B variant, which achieves an LMArena score over 1300, surpassing models like Llama 4 Maverick 17B 128E and GPT 4.1-nano.
Points to be cautious about:
- Context is shared across modalities. The model has a total input context of 32K tokens across text, image, audio, and video. Multimodal tokens can consume context quickly; for long multimodal sessions, you need careful prompt budgeting and chunking.
- Production needs modality-specific evaluation. The performance of the model in use cases like speech-to-text and speech translation can vary by language, accent, noise, and domain. You should always benchmark the model in these aspects before production rollout.
Phi-4-mini-instruct#
Phi-4-mini-instruct is a lightweight, instruction-tuned model from Microsoft’s Phi-4 family. It is trained on a mix of high-quality synthetic data and carefully filtered public datasets, with a strong emphasis on reasoning-dense content.
With only 3.8B parameters, Phi-4-mini-instruct shows reasoning and multilingual performance comparable to much larger models in the 7B–9B range, such as Llama-3.1-8B-Instruct. It’s a solid choice for teams that want strong instruction following and reasoning without the operational overhead of larger models.
Why should you use Phi-4-mini-instruct:
- Multilingual support out of the box. Phi-4-mini-instruct supports over 20 languages, making it suitable for global products that requires lightweight multilingual capability.
- Long context window. Native support for 128K tokens means you can use it in scenarios like document analysis, RAG, and agent traces.
- Production-friendly licensing. Released under the MIT license, it can be freely used, fine-tuned, and deployed in commercial systems without restrictive terms.
Points to be cautious about:
Limited factual knowledge. Phi-4-mini-instruct doesn’t store large amounts of world knowledge. It may produce inaccurate or outdated facts, especially for knowledge-heavy or long-tail queries. I suggest you pair it with RAG or external tools for production use.
Language performance varies. Although it supports multiple languages, performance outside English can be uneven. Non-English or low-resource languages should be carefully benchmarked before deployment.
Sensitive to prompt format. Phi-4-mini-instruct performs best with its recommended chat and function-calling formats. Otherwise, it can negatively impact instruction adherence and output quality. For example, you should use the following format for general conversation and instructions:
<|system|>Insert System Message<|end|><|user|>Insert User Message<|end|><|assistant|>
Qwen3-0.6B#
Qwen3-0.6B is the smallest dense model in Alibaba’s Qwen3 family, released under the Apache 2.0 license. Despite its tiny size, it inherits much of what makes Qwen3 notable: strong reasoning, improved agent and tool-use capabilities, and broad multilingual support.
Architecturally, Qwen3-0.6B is a 0.6B parameter causal LM with 32K context length. Like the rest of the Qwen3 line, it supports a hybrid behavior pattern that can switch between deeper reasoning and faster responses depending on your use case.
By December 2025, Qwen3-0.6B is among the most downloaded text generation models on Hugging Face.
Why should you use Qwen3-0.6B:
Strong capability for a sub-1B model. If you want something meaningfully stronger than “toy” small models, but still lightweight enough for low-cost deployments, Qwen3-0.6B is a solid baseline. In some evaluations, it’s competitive even against much larger models like DeepSeek-R1-Distill-Llama-8B.
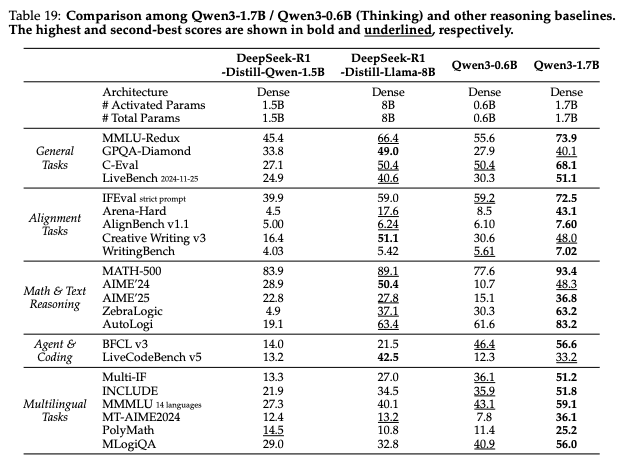 Image Source: Qwen3 Technical Report
Image Source: Qwen3 Technical Report
Multilingual out of the box. Qwen3 supports 100+ languages and dialects, and Qwen3-0.6B benefits from that training focus. It is an ideal choice for on-device global products that can’t afford larger multilingual models.
Agent and tool-use friendly ecosystem. Qwen3 is designed with agent workflows in mind, and the tooling around it (templates, parsers, Qwen-Agent) reduces integration friction.
Points to be cautious about:
- Small model limits still apply. At 0.6B, it’s less reliable for deep reasoning, long-horizon planning, and complex coding than 3B+ models, even if it’s strong for its class.
- Repetition can show up with the wrong configurations. Qwen3-0.6B can get stuck in repetitive loops in some cases. Use recommended sampling settings and consider adding a presence penalty to solve this problem.
If you can afford a bit more compute, I also recommend Qwen3-1.7B and Qwen3-4B. They keep the same hybrid reasoning and agent-friendly design, but offer better performance for more complex tasks than the 0.6B model.
SmolLM3-3B#
SmolLM3-3B is a fully open instruct and reasoning model from Hugging Face. At the 3B scale, it outperforms Llama-3.2-3B and Qwen2.5-3B, while staying competitive with many 4B-class alternatives (including Qwen3 and Gemma 3) across 12 popular LLM benchmarks.
What also sets SmolLM3 apart is the level of transparency. Hugging Face published the full engineering blueprint of it, including architecture decisions, data mixture, and post-training methodology. If you’re building internal variants or want to understand what actually drives quality at 3B, that matters.
Why should you use SmolLM3-3B:
- Dual-mode reasoning. It supports
/thinkand/no_think, so you can default to fast responses and only pay the reasoning cost when a request is genuinely hard. - Long context window. The model is trained to 64K and can stretch to 128K tokens with YaRN extrapolation, making it a strong fit for use cases like long-running agent sessions.
- Fully open recipe. The model is released under the Apache 2 license plus detailed training notes, public data mixture, and configs. These reduce guesswork if you want to fine-tune or build a derivative.
Points to be cautious about:
- Multilingual coverage is narrower than some peers. SmolLM3 works best in six main European languages. If you need broader global coverage, benchmark carefully and consider alternatives.
Ministral-3-3B-Instruct-2512#
Ministral-3-3B-Instruct-2512 is a multimodal SLM developed by Mistral AI. It’s the smallest instruct model in the Ministral 3 family, designed specifically for edge and resource-constrained deployments.
Architecturally, it combines a 3.4B language model with a 0.4B vision encoder, supporting basic visual understanding alongside chat and instruction following. In practice, it can run on a single GPU and fit into roughly 8 GB of VRAM in FP8, or even less with further quantization.
Why should you use Ministral-3-3B-Instruct-2512:
- Vision + text in one small model. It is a practical choice for lightweight image tasks like screenshot understanding, image captioning, and simple visual Q&A, without moving to a large VLM.
- Agent-ready. Designed with function calling and structured (JSON-style) outputs in mind, it can be easily integrated into tool-using and agentic workflows.
- Large context for its size. It supports up to 256k tokens, which is useful for document-heavy prompts, long logs, or multi-file inputs.
Points to be cautious about:
- Vision is functional, not deep. While it supports image inputs, the visual reasoning capability is limited. I suggest you use it for simple descriptions and basic Q&A rather than detailed image analysis or complex visual reasoning. If you need stronger multimodal reasoning, consider Ministral-3-3B-Reasoning-2512 instead.
Now let’s take a look at some FAQs.
How small is “small” for language models?#
There’s no strict cutoff, but in practice, SLMs usually fall in the sub-1B to ~10B parameter range. Models in this range can often run on a single GPU without sharding or complex distributed inference setups.
Are SLMs good enough for production?#
Yes, for many use cases. Modern SLMs benefit from better training data, distillation, and post-training techniques, making them far more capable than earlier generations. In fact, you don’t need GPT-5.2-level capability for most real-world tasks.
One of their biggest advantages is fine-tuning. Small models are easier and cheaper to fine-tune on proprietary data such as internal documents, domain-specific workflows, or product knowledge. In narrow or specialized tasks, a well fine-tuned small model can outperform much larger general-purpose models, running faster and at a fraction of the cost.
As a result, SLMs are widely used in production for internal copilots, agent workflows and automation.
Why should I use open-source SLMs?#
Open-source SLMs offer several advantages compared to LLMs, especially in production environments:
- Easier and cheaper to fine-tune. Small models can be fine-tuned with your proprietary data using far less compute. For domain-specific tasks, a well fine-tuned SLM can outperform a much larger general-purpose LLM.
- On-device and edge friendly. Many small models can run on laptops, mobile devices, or edge hardware, supporting offline use cases and ensuring data privacy.
- Lower inference cost. Smaller parameter counts mean less GPU memory usage and lower KV-cache pressure, which matters a lot at scale.
- Simpler deployment. Most SLMs run on a single GPU without sharding or complex parallelism, which are easier to operate and debug than large models.
- Faster inference. Small models respond more quickly, which is critical for real-time and high-throughput applications.
For many real-world applications, open-source SLMs provide a better balance of performance, cost, and operational simplicity.
What are the main differences between SLMs and LLMs?#
The key differences come down to scale, cost, and operational complexity, which directly affect how and where each type of model makes sense in production.
| Item | Small Language Models (SLMs) | Large Language Models (LLMs) |
|---|---|---|
| Typical size | Sub-1B to a few billion parameters | Tens to hundreds of billions of parameters, or even trillion-level |
| Hardware requirements | Single GPU, CPU, or on-device in some cases | High-VRAM GPUs, often with multi-GPU setups and distributed inference |
| Inference cost | Low and predictable | Higher and scales quickly with usage |
| Latency | Fast, suitable for real-time workloads | Higher latency, especially under concurrency |
| Reasoning strength | Good for many tasks, weaker on very complex reasoning | Stronger for deep reasoning and long-horizon planning |
| Deployment complexity | Simple to deploy and operate | Complex infrastructure and ops overhead |
| Use cases | Simple agents, automation, edge, on-device workloads | Frontier reasoning, complex coding, open-ended tasks |
Final thoughts#
SLMs aren’t a compromise anymore. Used well, they’re often one of the fastest paths to reliable, scalable AI in production.
Why? Today, you’re not building AI products around a single model. You’re building AI systems.
Many production setups combine multiple models with different strengths: SLMs for fast, cost-efficient inference, larger models for harder reasoning, and specialized vision or speech models where needed. In that kind of system, SLMs play a critical role. They’re easier to fine-tune, cheaper to run, and simple to scale, which makes them ideal building blocks for real-world AI workflows.
Trying to build modern AI systems? This is where the Bento Inference Platform comes in. Bento lets you chain multiple models together, route traffic intelligently, and scale each component independently. You can mix SLMs and larger models freely, without locking your architecture to a single model or vendor.
If you’re thinking about running SLMs in production, we’d love to help.
- Contact us to discuss your use case and architecture
- Join our Slack community to learn from other teams building with SLMs
- Sign up for the Bento Inference Platform to start deploying and scaling models with confidence