By Factory - January 20, 2026 - 3 minute read -
Share
Product
Engineering
New
A framework for measuring and improving how well your codebase supports autonomous development. Evaluate repositories across eight technical pillars and five maturity levels.
Introducing Agent Readiness
Factory can now evaluate how well your codebase supports autonomous development. Run /readiness-report to see where you stand across eight technical pillars and five maturity levels, with specific recommendations for what to fix first.

The invisible bottleneck
Teams deploying AI coding agents often see uneven results. They blame the model, try a different …
By Factory - January 20, 2026 - 3 minute read -
Share
Product
Engineering
New
A framework for measuring and improving how well your codebase supports autonomous development. Evaluate repositories across eight technical pillars and five maturity levels.
Introducing Agent Readiness
Factory can now evaluate how well your codebase supports autonomous development. Run /readiness-report to see where you stand across eight technical pillars and five maturity levels, with specific recommendations for what to fix first.
The invisible bottleneck
Teams deploying AI coding agents often see uneven results. They blame the model, try a different agent, get the same thing. The real problem is usually the codebase itself.
The agent is not broken. The environment is. Missing pre-commit hooks mean the agent waits ten minutes for CI feedback instead of five seconds. Undocumented environment variables mean the agent guesses, fails, and guesses again. Build processes requiring tribal knowledge from Slack threads mean the agent has no idea how to verify its own work.
These are environment problems, not agent problems. And they compound. A codebase with poor feedback loops will defeat any agent you throw at it. A codebase with fast feedback and clear instructions will make any agent dramatically more effective.
What we measure
Agent Readiness evaluates repositories across eight technical pillars. Each one addresses a specific failure mode we have observed in production deployments. Click through to see what each pillar catches and what happens without it.
Five maturity levels
Repositories progress through five levels. Each level represents a qualitative shift in what autonomous agents can accomplish. Select a level to see its requirements and what agents can do at that stage.
See it in action
We have published Agent Readiness reports for popular open source projects. You can explore them at factory.ai/agent-readiness to see what different maturity levels look like in practice.
The contrast is instructive. CockroachDB at Level 4 has extensive CI, comprehensive testing, clear documentation, and security scanning. Express at Level 2 lacks several foundational signals. Both are successful, widely-used projects. But an agent will have a much easier time contributing to CockroachDB.
How to use it
There are three ways to interact with Agent Readiness in Factory.
CLI: /readiness-report
Run /readiness-report in Droid to evaluate any repository. The report shows your current level, which criteria pass and fail, and prioritized suggestions for what to fix first.
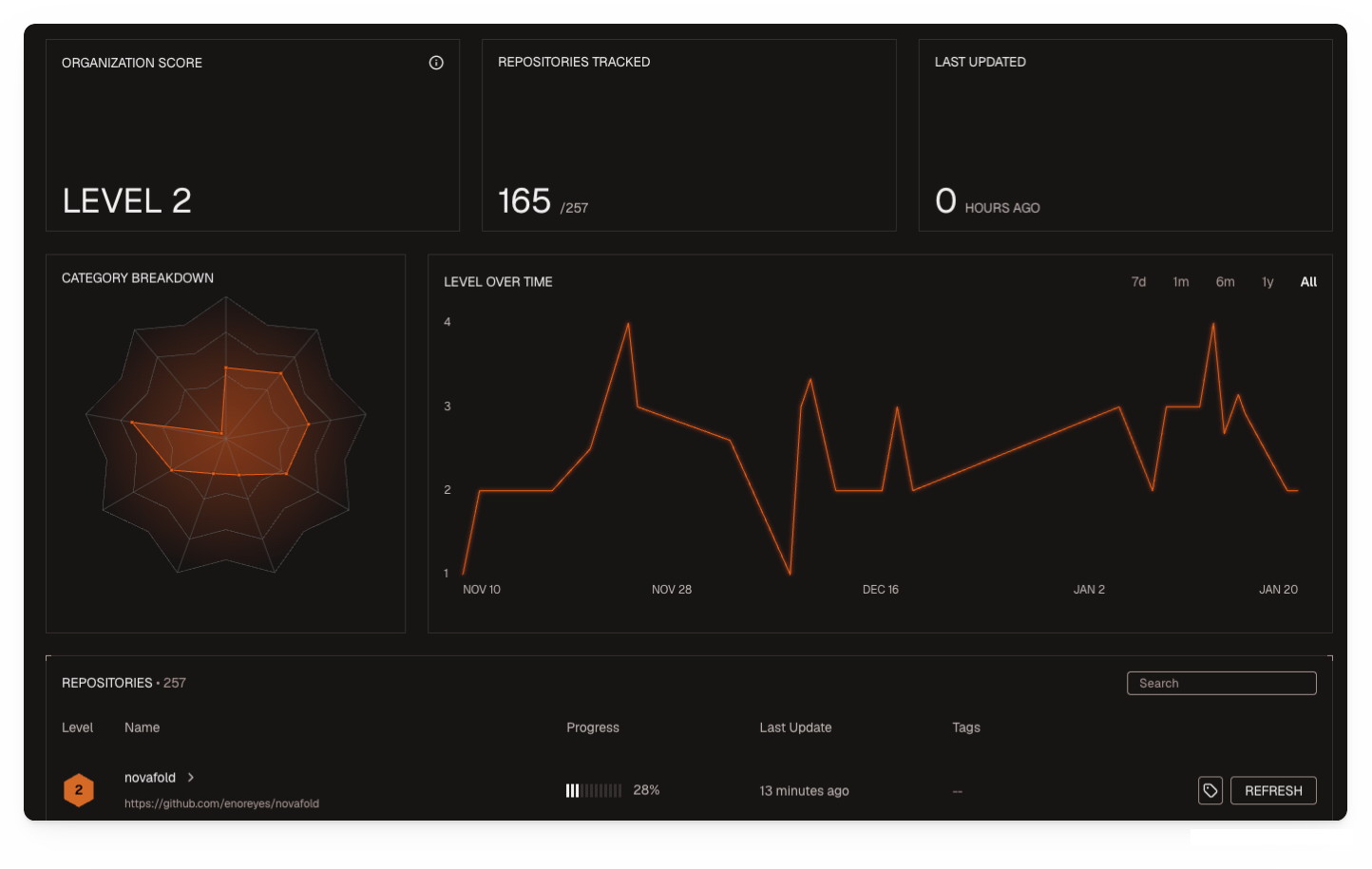
Dashboard: Organization view
View your organization’s readiness scores at app.factory.ai/analytics/readiness. Track progress over time, see the distribution of repositories across maturity levels, and identify which active repositories need attention.
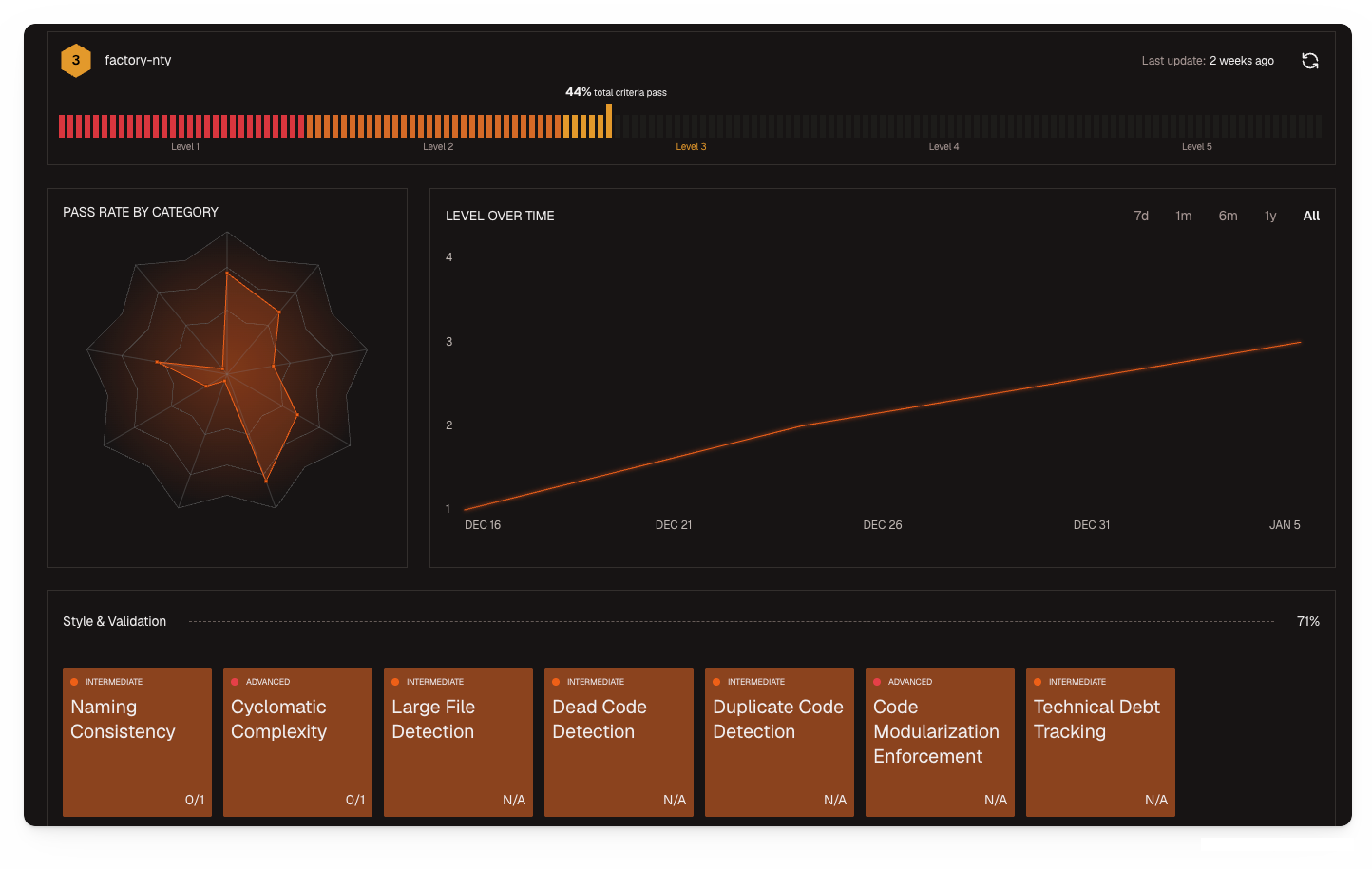
The dashboard surfaces your lowest-scoring active repositories (those with commits in the last 90 days) with specific remediation suggestions.
API: Programmatic access
Access reports via the Readiness Reports API to integrate with your existing tooling. Run readiness checks in CI/CD, build custom dashboards, or set up alerting when scores drop below thresholds.
Consistent evaluations
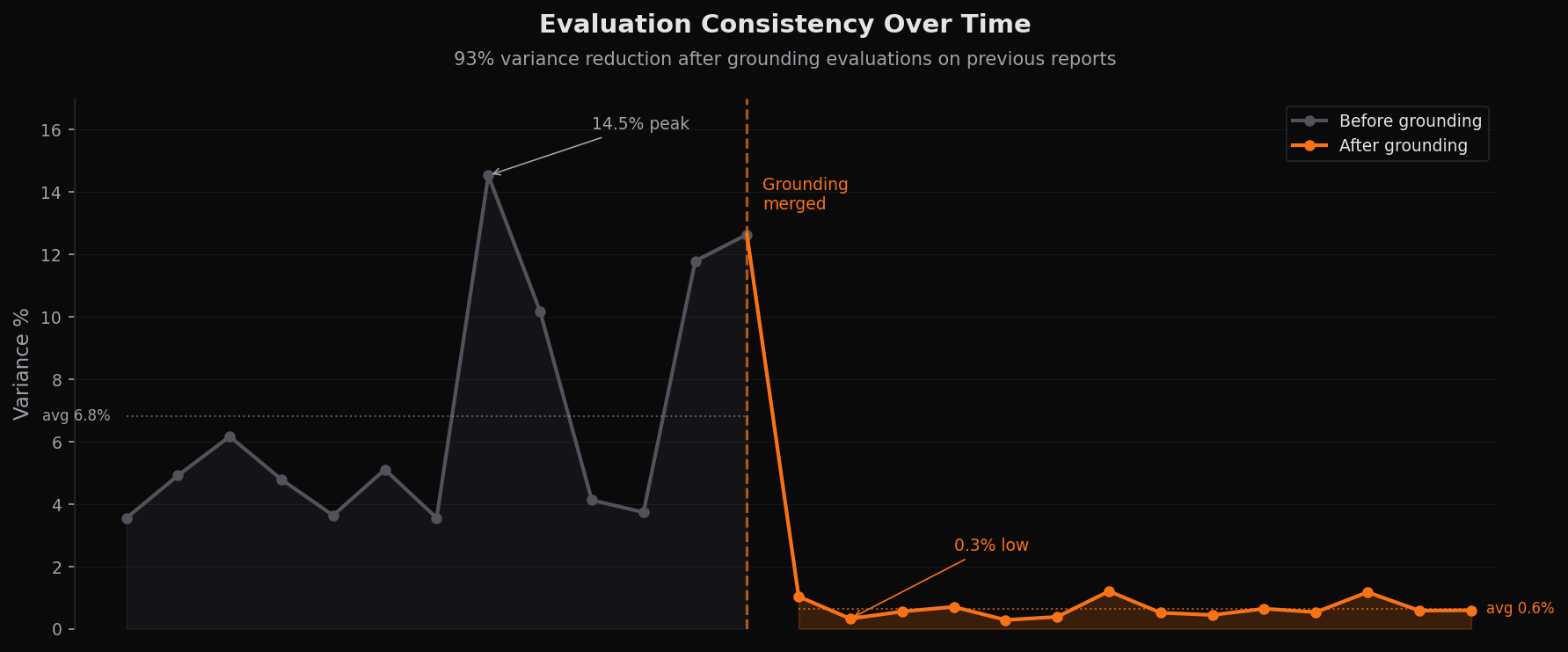
Agent Readiness evaluates 60+ criteria using LLMs, which introduces a challenge: non-determinism. The same repository could receive different scores on consecutive runs, undermining trust. We solved this by grounding each evaluation on the previous report for that repository. Before the fix, variance averaged 7% with spikes to 14.5%. After grounding, variance dropped to 0.6% and has stayed there for six weeks across 9 benchmark repositories spanning low, medium, and high readiness tiers.
How scoring works
Each criterion is binary: pass or fail. Most signals are file existence checks or configuration parsing. Does the linter config exist? Is branch protection enabled? Can tests run locally?
Criteria evaluate at two scopes. Repository-scoped criteria run once for the entire repo (CODEOWNERS exists, branch protection enabled). Application-scoped criteria run per application in monorepos (linter configured for each app, unit tests exist for each app). Monorepos see scores like "3/4" meaning three of four apps pass that criterion.
To unlock a level, you must pass 80% of criteria from that level and all previous levels. This gated progression emphasizes building on solid foundations rather than cherry-picking easy wins at higher levels.
At the organization level, we track the percentage of active repositories that reach Level 3 or higher. "80% of our active repos are agent-ready" is more actionable than "our average score is 73.2%."
Automated remediation
Knowing your gaps is half the problem. We can also fix them.
When you run a readiness report, you can kick off automated remediation from the CLI or dashboard. This spins up an agent that opens a pull request to fix failing criteria: adding missing files like AGENTS.md, configuring linters, setting up pre-commit hooks.
The initial focus is on foundational gaps. Missing documentation, absent configuration files, basic tooling that should exist in every repository. These fixes are straightforward and high-impact. What took a team days of manual configuration work happens in minutes.
After fixes are applied, re-run the readiness check to validate and refresh your score.
The compounding effect
Here is what we have learned from helping organizations like Ernst & Young, Groq, and Bilt get their codebases agent-ready: the work compounds.
Better environments make agents more productive. More productive agents handle more work. That frees up time to improve environments further. Teams that measure this and systematically improve will pull ahead of teams that do not. The gap will widen.
This is not just about Factory. A more agent-ready codebase improves the performance of all software development agents. The investment pays dividends regardless of which tools you use.
Start with /readiness-report on your most active repository. See where you stand. Fix the gaps. Watch your agents get better.