Modern data architectures are undergoing a fundamental shift. As organizations demand fresher data, simpler pipelines, and stronger governance, the line between streaming systems and analytical tables is rapidly disappearing.
In the Tech Talk, “From Stream to Table: Building a real-time lakehouse architecture with Redpanda and Databricks,” we explained how streaming data can flow directly into governed, analytics-ready tables without the operational nightmare of traditional batch systems.
The session brought together expert perspectives from both platforms:
- Jason Reed, Director of…
Modern data architectures are undergoing a fundamental shift. As organizations demand fresher data, simpler pipelines, and stronger governance, the line between streaming systems and analytical tables is rapidly disappearing.
In the Tech Talk, “From Stream to Table: Building a real-time lakehouse architecture with Redpanda and Databricks,” we explained how streaming data can flow directly into governed, analytics-ready tables without the operational nightmare of traditional batch systems.
The session brought together expert perspectives from both platforms:
- Jason Reed, Director of Product Management at Databricks
- Matt Schumpert, Head of Product at Redpanda
The full talk is free to watch, but if you’re more of a skimmer, this post covers the key moments from the session and walks through how Redpanda and Databricks enable real-time architectures built on open standards, with Apache Iceberg™ at the core. As Matt put it,
“The goal of this partnership is to remove the artificial line between real-time data and analytical data.”
The road to the open lakehouse
In the Apache Hadoop® era, data lakes had major advantages over traditional data warehouses. They enabled schema-on-read, flexible ELT workflows, and support for multi-structured data, all while significantly lowering costs with cloud object storage. This unlocked new use cases like large-scale analytics, machine learning, and AI workloads that were once too expensive to even think about.
But as adoption grew, so did complexity. Sprawl became a serious challenge, and multiple teams operating on the same datasets introduced issues around governance and reliability. One company that knew these challenges all too well was Netflix.
Here’s where Jason has a story to tell, having worked on the data team at Netflix. The TL;DR is that these challenges ultimately led to the creation of Apache Iceberg—initially developed internally at Netflix and later open-sourced as an Apache project.
“Iceberg provides a foundation that looks and behaves like a warehouse table, while remaining open and cloud-native.” - Jason Reed, Databricks.
In a nutshell, Iceberg made it possible to combine the flexibility of data lakes with the governance and reliability traditionally associated with data warehouses.
Iceberg REST Catalog and unified governance
As Iceberg adoption increased, a new set of challenges entered the ring. Early Iceberg catalogs were often implemented as collections of files stored directly in object storage. But with many users, workloads, and vendors creating and managing Iceberg tables across shared object storage, metadata sprawl and governance gaps were becoming dire.
This set the stage for the next evolution in Iceberg architecture: the Iceberg REST Catalog.
In short, the Iceberg REST Catalog centralizes governance at the catalog layer. Engines interact with the catalog through a standard REST API, without depending on Hadoop, Hive, or storage-specific implementations. The catalog becomes responsible for:
- Managing permissions and access control
- Coordinating concurrent reads and writes
- Dynamically granting engines access to data at runtime
This “single control plane” approach ensures consistent security and policy enforcement across the entire data platform.
Another key advantage of REST-based catalogs is interoperability. Different platforms, written in different languages and running in different environments, can exchange metadata and enforce governance by speaking the same protocol. This standardization led to a surge in lakehouse platforms and standalone catalog providers adopting Iceberg REST catalogs, allowing data and metadata to move freely across tools.
Naturally, this also led to users wanting a deeper integration with Iceberg-based lakehouses. They want their real-time data to be first-class citizens in the open lakehouse architecture: easy to access, governed, and immediately available for analytics.
And so, Redpanda Iceberg Topics was born.
Redpanda Iceberg Topics: the stream is the table
Redpanda’s Iceberg Topics allow you to store topic data in the cloud in the Iceberg open table format, so you can query real-time data while it’s still streaming. This grants you instant analytics on the freshest data without the complexities of traditional ETL processes. Pretty neat.
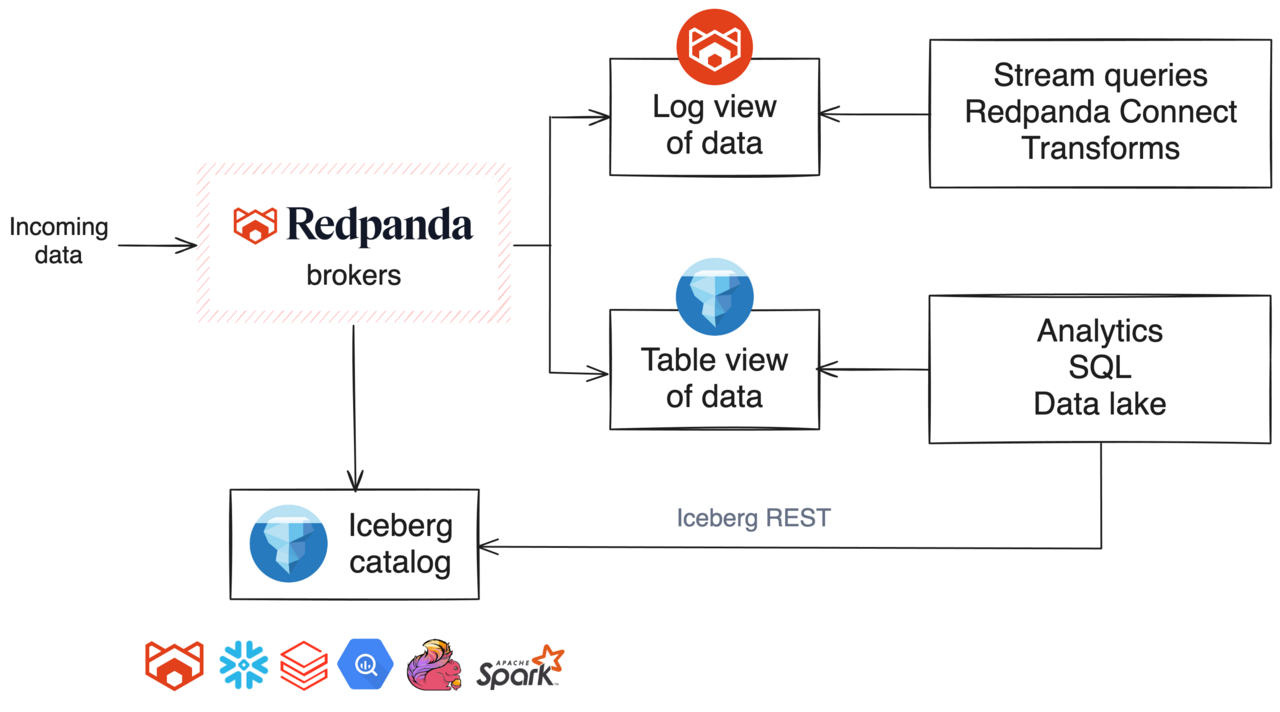
Diagram of Redpanda Iceberg Topics
But let’s take a step back. Before Iceberg Topics, making streaming data available in a lakehouse typically required significant manual effort. Teams either built custom ETL jobs using frameworks like Spark or deployed heavyweight connector architectures to move data from streaming platforms into analytical systems. To add insult to injury, these pipelines were often brittle and operationally expensive.
With Iceberg Topics, teams can simply specify which streams should be made available in the lakehouse and which should remain streaming-only. With a simple configuration change, data appears in the lakehouse and becomes immediately queryable for downstream analytical systems (like Databricks).
“Streaming data is analytics-ready by default.” - Matt Schumpert, Redpanda.
So what does this mean for those beavering away on the pipelines?
- Lower infrastructure costs
- Faster time-to-insight
- Fewer human hours spent on pipeline maintenance
- More free time to build valuable data products and AI applications
Iceberg Topics are now generally available in Redpanda Cloud across AWS, GCP, and Azure, as well as in Self-Managed and BYOC deployments. To learn more, read the Iceberg Topics Documentation.
Integrating with Databricks and Unity Catalog
This architecture fits naturally within the Databricks ecosystem. Once streaming data lands in Iceberg, Unity Catalog serves as a centralized, governed location for managing the table view of the data, ensuring:
- Fine-grained access control
- Consistent security across workloads
- Metadata management and lineage
- Easy discovery for downstream users
As Iceberg is an open table format, this governance layer doesn’t require proprietary ingestion steps or duplicate pipelines.
“The data shows up already structured, already governed, and already queryable.” - Jason Reed, Databricks.
So where does Redpanda fit in? Redpanda integrates directly with Unity Catalog using the Iceberg REST API. Through this integration, Redpanda registers Iceberg tables, manages schema updates, deletes tables when necessary, and handles the full lifecycle of the data.
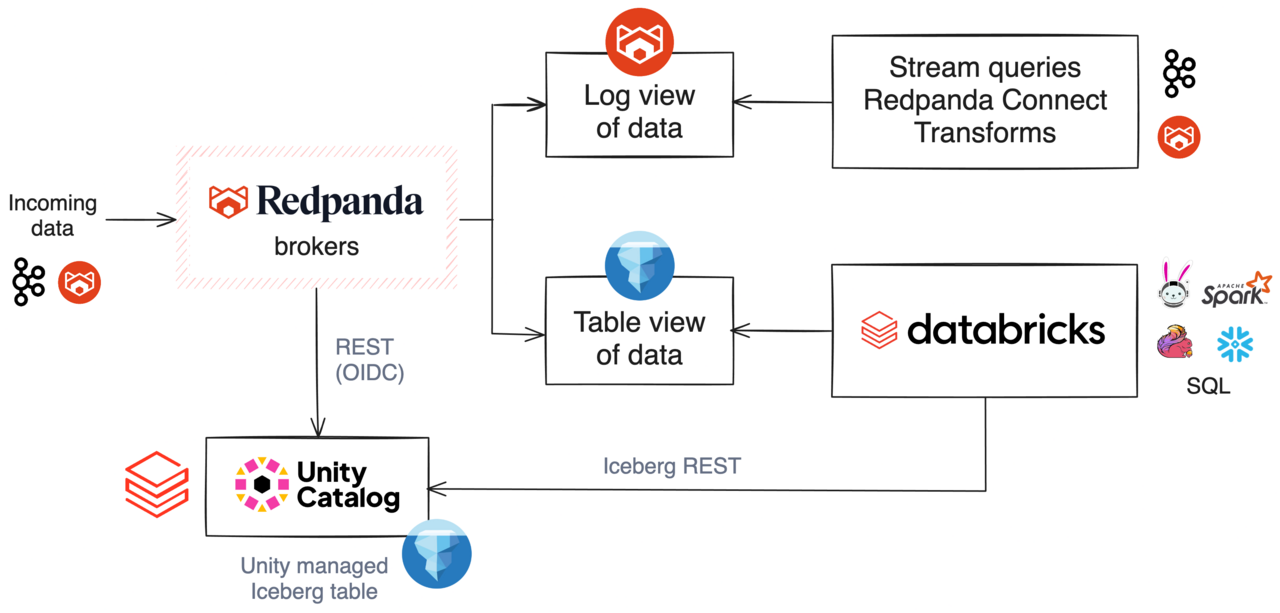
Redpanda Iceberg Topics integrating with Databricks Unity Catalog
Once registered, the data becomes accessible to both worlds:
- The Apache Kafka® ecosystem continues to consume data in real time
- The Iceberg ecosystem gains access to analytics-ready tables that can be queried by any Iceberg-compatible engine connected to Unity Catalog.
In a nutshell, Redpanda delivers real-time performance and reliability at scale. Iceberg provides an open, transactional table format optimized for analytics. Unity Catalog adds governance, optimization, federation, and lifecycle management across the entire system.
Together, they allow teams to build real-time, analytics-ready data pipelines that are simpler to operate, faster to deliver insight, and built on open standards designed to scale with the organization.
**Watch the tech talk for a demo **
So far, you’ve learned that Redpanda Iceberg Topics, Apache Iceberg, and Databricks Unity Catalog blur the line between streaming and analytics. Streaming data becomes instantly queryable without batch jobs, connectors, or orchestration frameworks. (Or the late nights!)
If you’re keen on the technical details and seeing this groovy architecture in action, the full tech talk walks you through:
- The full journey to integrating Redpanda, Iceberg, and Databricks
- Iceberg REST Catalogs and data object storage
- Partitioning, performance, and optimizing queries
- Handling dirty data and dead letter tables
- Optimizing tables and performance at scale
To wrap it all up, the talk ends with a practical demo of Redpanda streaming data directly into Databricks, where it becomes instantly queryable as Iceberg tables in Unity Catalog. It’s actually as simple as it sounds.