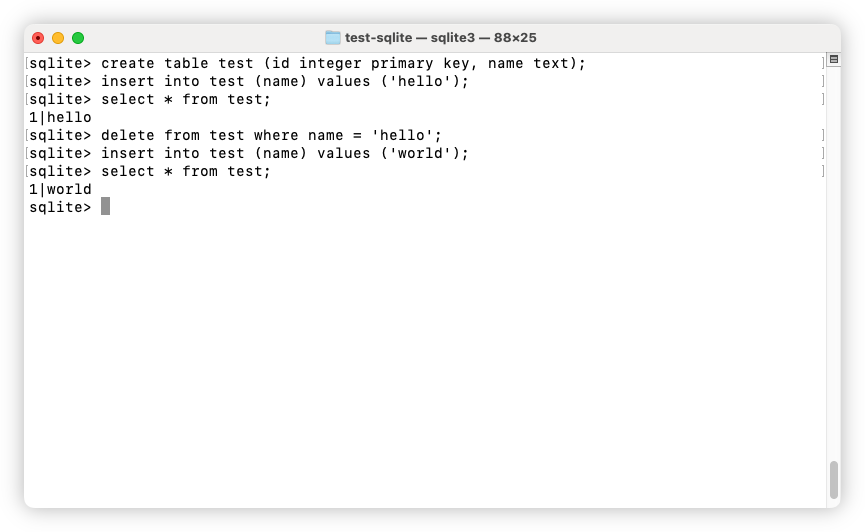
I’ve noticed that relying on ROWIDs for primary keys in Sqlite 3 tables can result in IDs being reused. If you insert a row that is given a ROWID of 1, delete it, then insert another row, that second row will also be given a ROWID of 1. At first I thought it was just the Go port I was using, but I also tried a package that uses the C library and I observed the same thing. It’s reproducable using the sqlite3 CLI tool:
This shouldn’t be an issue normally, but I have been trying to enable [foreign …
I’ve noticed that relying on ROWIDs for primary keys in Sqlite 3 tables can result in IDs being reused. If you insert a row that is given a ROWID of 1, delete it, then insert another row, that second row will also be given a ROWID of 1. At first I thought it was just the Go port I was using, but I also tried a package that uses the C library and I observed the same thing. It’s reproducable using the sqlite3 CLI tool:
This shouldn’t be an issue normally, but I have been trying to enable foreign keys with cascade deletes in a program that’s using Sqlite 3. And maybe I’m not enabling them properly, but I’ve been finding rows that should’ve been deleted via this cascade were showing up in joins with new rows created on the foreign table. I don’t know why this is not working, but even so, having IDs that are never reused might be helpful here.
To avoid this, you can add autoincrement to the ID field to ensure that IDs are always monotonically increasing:
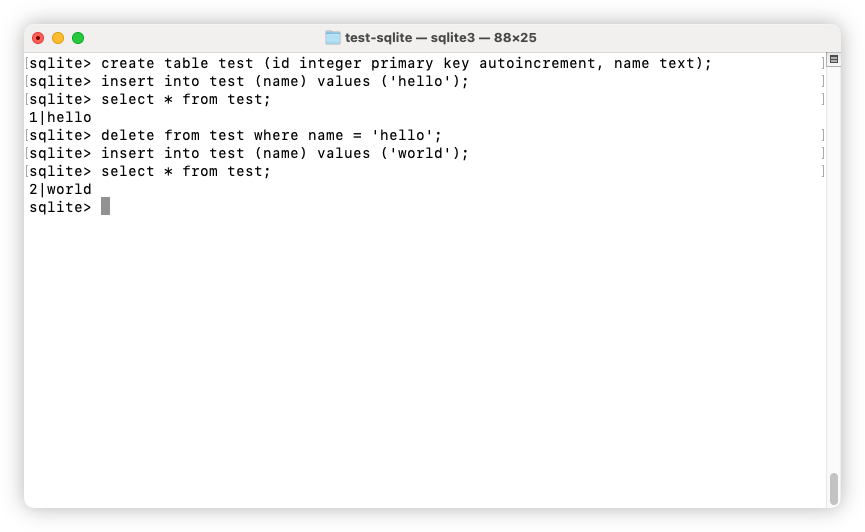
Apparently, this is not encouraged as it adds a bit of overhead to inserting rows. But if the price of unique IDs is a little more memory and CPU usage, for my teeny-tiny database, it’s worth it.