The other day I went to an AI hackathon organized by my friends Lucia and Malin. The theme was mech interp, but I hardly know PyTorch so I planned to do something at the API layer rather than the model layer.
Something I think about a lot is cognitive architectures (like Soar and ACT-R). This is like a continuation of GOFAI research, inspired by cognitive science. And like GOFAI it’s never yielded anything useful. But I often think: can we scaff…
The other day I went to an AI hackathon organized by my friends Lucia and Malin. The theme was mech interp, but I hardly know PyTorch so I planned to do something at the API layer rather than the model layer.
Something I think about a lot is cognitive architectures (like Soar and ACT-R). This is like a continuation of GOFAI research, inspired by cognitive science. And like GOFAI it’s never yielded anything useful. But I often think: can we scaffold LLMs with cog arch-inspired harnesses to overcome their limitations?
LLM agents like Claude Code are basically “accidental” cognitive architectures: they are designed and built my practitioners rather than theorists, but they have commonalities, they all need a way to manage memory, tool use, a task agenda etc. Maybe building an agent on a more “principled” foundation, one informed by cognitive science, yields a higher-performing architecture.
So I sat around a while thinking how to adapt Soar’s architecture to an LLM agent. And I sketched something out, but then I thought: how can I prove this performs better than baseline? I need an eval, a task.
Math problems? Too one-shottable. A chatbot? Too interactive, I want something hands-off and long-horizon. A coding agent? That’s too freeform and requires too much tool use. And then I thought: text adventures! You have a stylized, hierarchically-structured world accessible entirely tthrough text, long-term goals, puzzles, physical exploration and discovery of the environment. Even the data model of text adventures resembles frame-based knowledge representation systems. And there’s a vast collection of games available online.
Anchorhead, which I played years ago, is a Lovecraft-inspired text adventure by Michael S. Gentry. It takes on the order of hundrds of turns to win across multiple in-game days. And the game world is huge and very open. In other words: a perfect long-horizon task.
So I started hacking. The frotz interpreter runs on the command line and has a “dumb” interface called dfrotz, which takes the ncurses fluff out, and gives you a very stripped command-line experience. It looks like this:
$ dfrotz games/anchor.z8
...
Outside the Real Estate Office day one
ANCHORHEAD
An interactive gothic by Michael S. Gentry
(Type HELP or ABOUT for some useful information.)
Release 5 / Serial number 990206 / Inform v6.15 Library 6/7
Outside the Real Estate Office
A grim little cul-de-sac, tucked away in a corner of the claustrophobic tangle
of narrow, twisting avenues that largely constitute the older portion of
Anchorhead. Like most of the streets in this city, it is ancient, shadowy, and
leads essentially nowhere. The lane ends here at the real estate agent's office,
which lies to the east, and winds its way back toward the center of town to the
west. A narrow, garbage-choked alley opens to the southeast.
>go southeast
Alley day one
Alley
This narrow aperture between two buildings is nearly blocked with piles of
rotting cardboard boxes and overstuffed garbage cans. Ugly, half-crumbling brick
walls to either side totter oppressively over you. The alley ends here at a
tall, wooden fence.
High up on the wall of the northern building there is a narrow, transom-style
window.
It is easy to write a little Python wrapper to drive the interpreter through stdin and stdout:
class Interpreter:
"""Manages the dfrotz Z-machine interpreter process."""
p: Popen
def __init__(self):
log("Starting dfrotz.")
p: Popen = Popen(
["dfrotz", "-m", GAME],
stdin=PIPE,
stdout=PIPE,
stderr=PIPE,
)
log(f"Started dfrotz with PID={p.pid}.")
# Set stdout/stderr to non-blocking mode.
for stream in [p.stdout, p.stderr]:
assert stream is not None
fd = stream.fileno()
flags = fcntl.fcntl(fd, fcntl.F_GETFL)
fcntl.fcntl(fd, fcntl.F_SETFL, flags | os.O_NONBLOCK)
self.p = p
def read(self) -> str:
assert self.p.stdout is not None
b: bytes | None = self.p.stdout.read()
if b is not None:
t: str = b.decode("utf-8")
return t
else:
return ""
def write(self, t: str) -> None:
assert self.p.stdin is not None
self.p.stdin.write(t.encode("utf-8"))
self.p.stdin.flush()
# Give the interpreter time to respond. Not ideal!
time.sleep(0.1)
Now we can play the game from Python: send commands, get game output. Now we need the dual of this: a player.
class Player(ABC):
"""
Interface for game-playing agents.
"""
@abstractmethod
def cycle(self, text: str) -> str:
"""
Send the game's output to the agent, and return the next command to execute.
"""
pass
The Trivial Harness
The trivial harness is basically nothing at all: treat the LLM/game interaction like a chat history. The LLM reads the game output from the interpreter, writes some reasoning tokens, and writes a command that is sent via stdin to the interpreter.
SYSTEM_PROMPT: str = """
Hello Claude. Your task is to play an adventure game. I've hooked up
your output to the dfrotz (dumb frotz) interpreter.
The structure of your output is fairly freeform. The first line that
starts with `>` (and only the first line!) is interpreted as a game
command, everything else is uninterpreted commentary, e.g. you may
write:
We should go north to explore the church.
>go north
Maybe we can use the silver key there.
If you write multiple `>` lines in one response, all but the first
will be ignored.
Have fun! 😊
"""
class SimplePlayer(Player):
"""
The simplest game-playing agent: keep the entire game histoyr in-context.
"""
client: Anthropic
history: list[tuple[EntryType, str]]
def __init__(self):
self.client = Anthropic()
self.history = []
def cycle(self, text: str) -> str:
self.history.append((EntryType.GAME, text))
system = trim(SYSTEM_PROMPT)
messages: list[MessageParam] = []
for entry_type, entry_text in self.history:
role: str
match entry_type:
case EntryType.GAME:
role = "user"
case EntryType.COMMAND:
role = "assistant"
messages.append(
{
"role": role,
"content": entry_text,
}
)
message: Message = self.client.messages.create(
max_tokens=512,
model=MODEL,
system=system,
messages=messages,
)
log(f"Tokens: {message.usage.input_tokens}")
response: str = message.content[0].text
log_claude(response)
lines: list[str] = [line for line in response.split("\n") if line]
cmd: str = [line for line in lines if line.startswith(">")][0][1:]
self.history.append((EntryType.COMMAND, response))
return cmd
And this works well enough. Haiku 4.5 would mostly wander around the game map, but Sonnet 4.5 and Opus 4.5 manage to solve the game’s first puzzle—breaking into the real estate office, and finding the keys to the mansion—readily enough. It takes about ~200 turns for Claude to get to the second in-game day.
The way I thought this would fail is: attention gets smeared across the long context, the model gets confused about the geometry of the world, its goal and task state, and starts confabulating, going in circles, etc.
As usual, I was outsmarting myself. The reason this fails is you run out of credits. By the time you get to day two, each turn costs tens of thousands of input tokens. No good! We need a way to save money.
Memory
Ok, let’s try something that’s easier on my Claude credits. We’ll show Claude the most recent five turns (this is the perceptual working memory), and give it a simple semantic memory: a list of strings that it can append entries to, and remove entries from using tool use.
This keeps the token usage down:
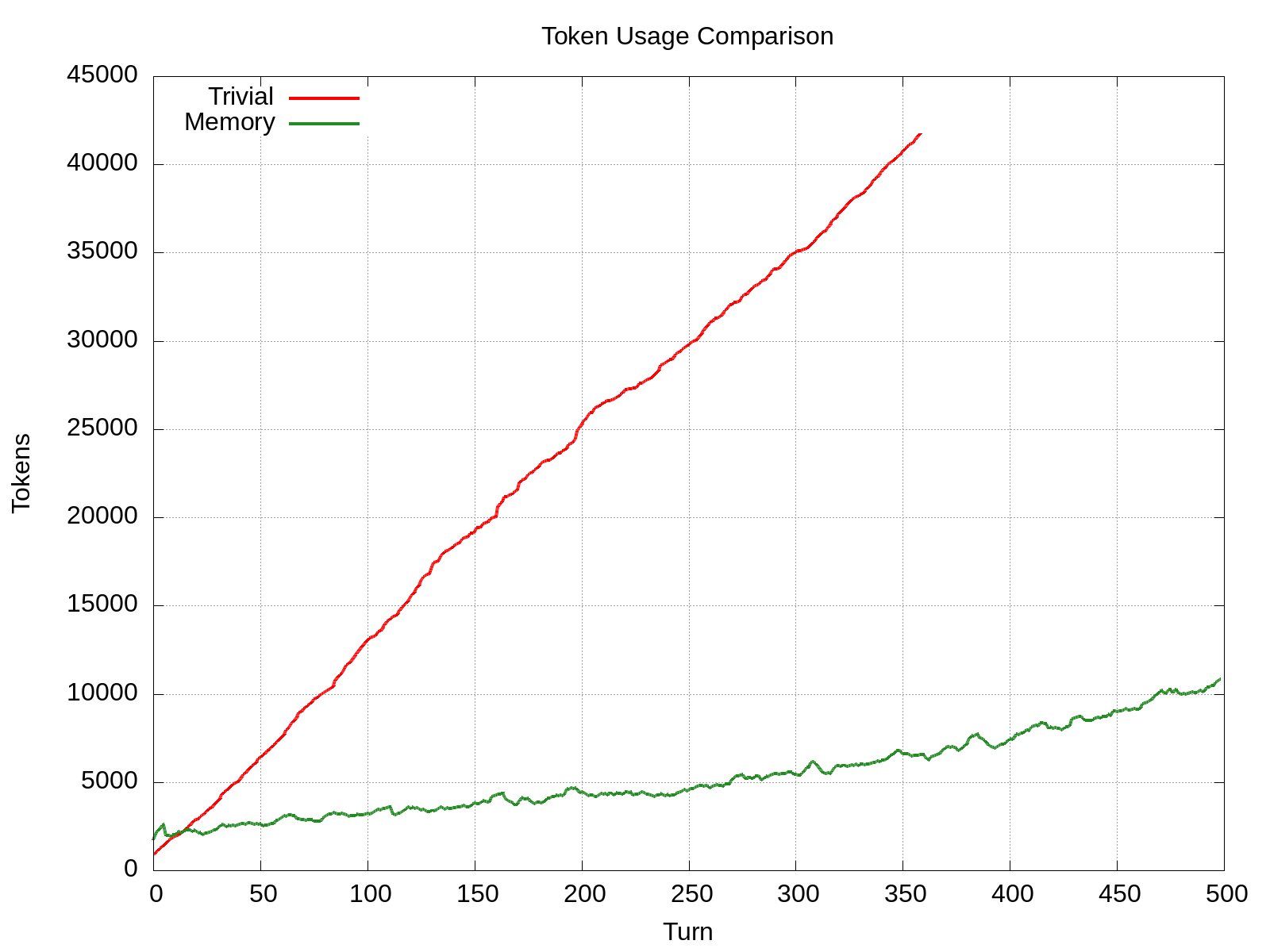
The problem is the narrow time horizon. With the trivial harness, Claude can break into the real estate office in ~10 turns, and does so right at the start of the game. With this new harness, Claude wanders about the town, taking copious notes, before returning to the real estate office, and it spends ~40 turns fumbling around with the garbage cans before managing to break into the real estate office.
The next step, after getting the keys to the house, is to meet your husband Michael at the University and head home. Claude with the trivial harness takes about ~100 turns to find the house, with some tangential wandering about the town, and reaches day two around turn 150.
Claude, with the memory harness, took ~250 turns just to get the keys to the house. And then it spends hundreds of turns just wandering in circles around the town, accumulating redundant memories, and hits the turn limit before even finding the house.
Aside: Small Worlds
Anchorhead is a long, broad game, and from the very beginning you can forget the plot and wander about most of the town. It takes a long time to see if a run with an agent goes anywhere. So I thought: I need something smaller.
Unsurprisingly, Claude can make its own games. The Inform 7 package for NixOS was broken (though Mikael has fixed this recently) so I had to use Inform 6. I started with a trivial escape-the-room type game, which was less than 100 lines of .inf code and any Claude could beat it less than 10 turns. Then I asked for a larger, multi-room heist game.
This one was more fun. It’s short enough that Claude can win with just the trivial harness. I tried a different harness, where Claude has access to only the last five turns of the game’s history, and a read-write memory scratchpad. And this one was interesting.
First, because Claude only ever adds to its own memory, it never deletes memories. I thought it would do more to trim and edit its scratchpad.
Second, because Claude become fixated on this red-herring room: a garden with a well. It kept going in circles, trying to tie a rope to the well and climb down. Because of the limited game history, it only realized it was stuck when it saw that the most recent ~20 entries it wrote to its memories related to various attempts to go down the well. Then I watched Claude walk away from the garden and solve the final puzzle, and hit the turn limit just two turns short of winning.
Tangent: I wonder if models are better at playing games created by other instances of the same model, by noticing tiny correlations in the text to infer what puzzles and obstacles they would have written.
In the end I abandoned the “small worlds” approach because the games are too stylized, linear, and uninteresting. Anchorhead is more unwieldy, but more natural.
Future Work
I have a bunch of ideas I want to test, to better learn how harness implementations affect performance. But I’m short on time, so I’m cutting it here and listing these as todos:
- Domain-Specific Memories: Claude’s notes are all jumbled with information on tasks, locations, etc. It might be better to have separate memories: a todo list, a memory of locations and their connections, etc. This is close to the Soar approach.
- Automatic Geography: related to the above, the harness can inspect the game output and build up a graph of rooms and their connections, and format it in the context. This saves Claude having to note those things manually using a tool.
- Manual Geography: the automatic geography approach has a few drawbacks. Without integration into the Z-machine interpreter, it requires some work to implement (parsing the currente location from the
dfrotzoutput, keeping track of the command history to find standard travel commands e.g.go south) but isn’t 100% deterministic, so that mazes and dynamic rooms (e.g. elevators) will confuse the system. So, instead of doing it manually, we could give Claude a tool likelink(room, direction, other_room). - Episodic Memory: this feels like cheating, but, at the end of a run, you can show Claude the session transcript and ask it to summarize: what it accomplished and how, where it failed and why. Including a short walkthrough for how to get to the “last successful state”. This allows future runs to save time in getting up to speed.
Code
The repository is here.