How Replit’s snapshot engine makes AI agents safe: instant filesystem forks, versioned databases, and isolated sandboxes enable reversible AI development.
Introduction
At Replit, we’ve built a compute and storage fabric that allows us to make changes in an isolated, reversible way, almost like time travel. Envisioned initially to make Replit more powerful for professional developers and team collaboration, these primitives enable developers to experiment more frequently and faster, thanks to the speed at which they can clone a compute environment and start making changes to it.
Later, when we built Replit Agent in 2024, we realized that the same primitives could superpower coding agents: not only does the system help the human driving the Agent, but the Agent itself also gr…
How Replit’s snapshot engine makes AI agents safe: instant filesystem forks, versioned databases, and isolated sandboxes enable reversible AI development.
Introduction
At Replit, we’ve built a compute and storage fabric that allows us to make changes in an isolated, reversible way, almost like time travel. Envisioned initially to make Replit more powerful for professional developers and team collaboration, these primitives enable developers to experiment more frequently and faster, thanks to the speed at which they can clone a compute environment and start making changes to it.
Later, when we built Replit Agent in 2024, we realized that the same primitives could superpower coding agents: not only does the system help the human driving the Agent, but the Agent itself also greatly benefits from these tools!
One motivating example we discovered early in the development of Replit Agent is that giving an AI Agent direct access to your code and database can be risky: it might make a change you don’t like, or drop or alter your database in irreversible ways.
Using our snapshottable filesystems and databases, you can always revert changes to your code or database. We have also added guardrails, such as a complete development/production split and restricting the Agent’s access to the development database.
In this post, we’ll explore the underlying systems that make the Replit Agent safe, how we use them, and a peek at our near-term roadmap.
Bottomless Storage Infrastructure
In 2023, we released our Bottomless Storage Infrastructure, intended initially to address storage limitations in Replit Apps while simultaneously enabling extremely fast Remixing (i.e., copying) of projects’ filesystems.
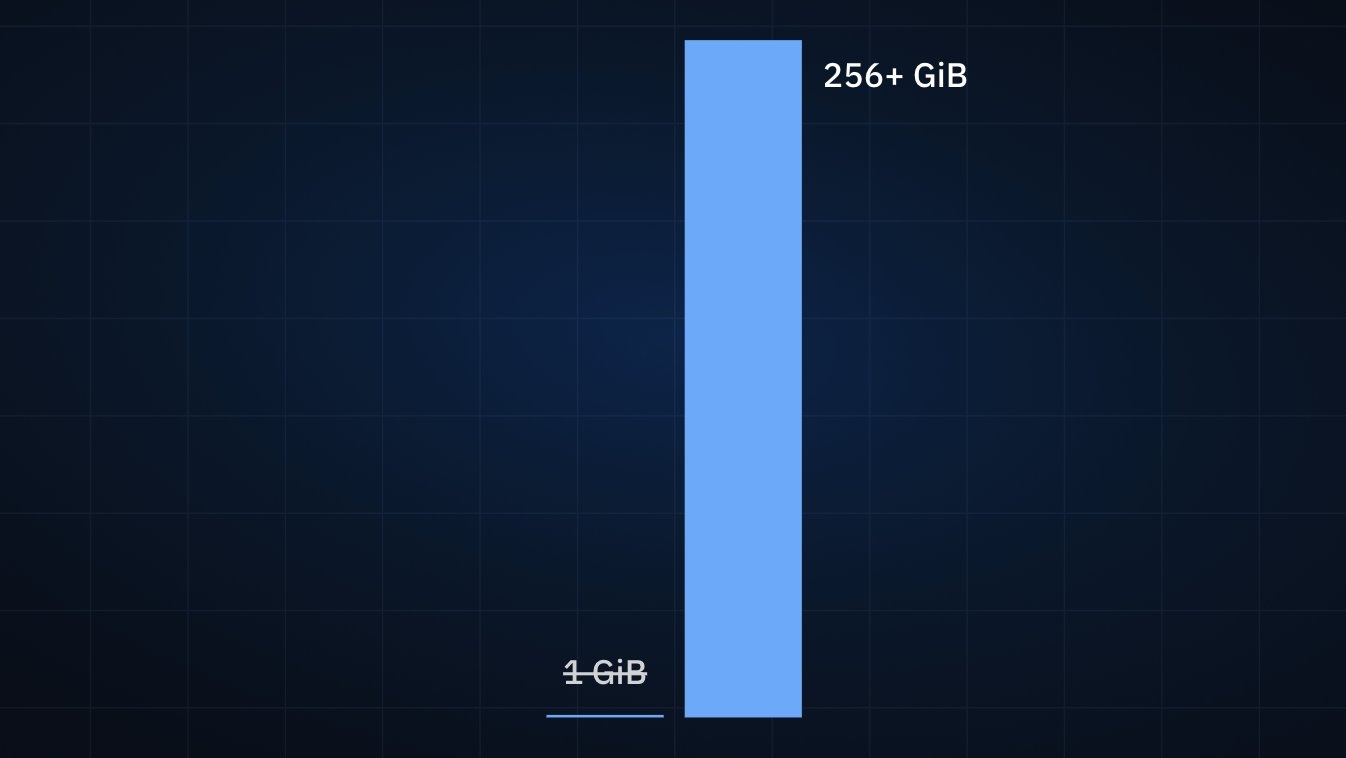
Bottomless storage, allowing your apps to grow >256x
At a high level, our storage engine provides virtual block devices (currently[1] via the Network Block Device protocol) that are backed by Google Cloud Storage and are lazily loaded and cached by our storage servers, co-located with the Virtual Machines and Linux containers that run Replit Apps to reduce latency.
Each block device is split into 16 MiB chunks, which are then stored immutably in GCS. A manifest contains pointers to all of the chunks that comprise a single version of the block device. Since chunks are immutable, copying a disk is a matter of copying the manifest, making it both cheap and constant-time (i.e., it doesn’t matter how large the filesystem is!). This leverages a technique called Copy-on-Write to make the copying race-free and also has strong guarantees that it will not interfere with either copy: each is now completely independent of the other, and they can evolve separately if needed.
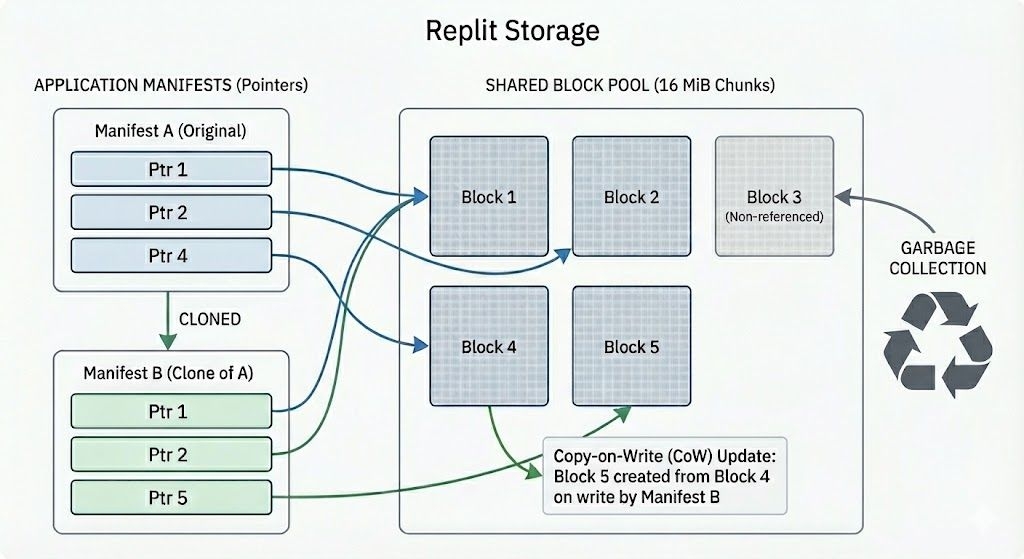
Replit Bottomless Storage manifests exhibiting copy-on-write
It turns out that Copy-on-Write at the block device level is a very powerful primitive: not only does it allow for fast copies of whole Replit Apps, but it also unlocks the ability to version them! One consequence of this design is that two checkpoints performed at different points in time of the same filesystem use the same machinery that remixing uses: we’re actually remixing the same disk over and over, and can restore to any previous checkpoint. This proved extremely useful for almost point-in-time recovery of their filesystems and has been an invaluable tool for disaster recovery and even for our research and data teams.
Versioning Agent Code Changes
Handling code changes is straightforward: we use the industry-standard Git version control system to track versions of code built by the Agent. Whenever the Agent reaches a particular state of “doneness” for a task, we create a Git commit and record it in the checkpoint metadata. If a user wants to undo code changes made by the Agent, they can rollback to any checkpoint, which uses git to revert the code to its earlier state.
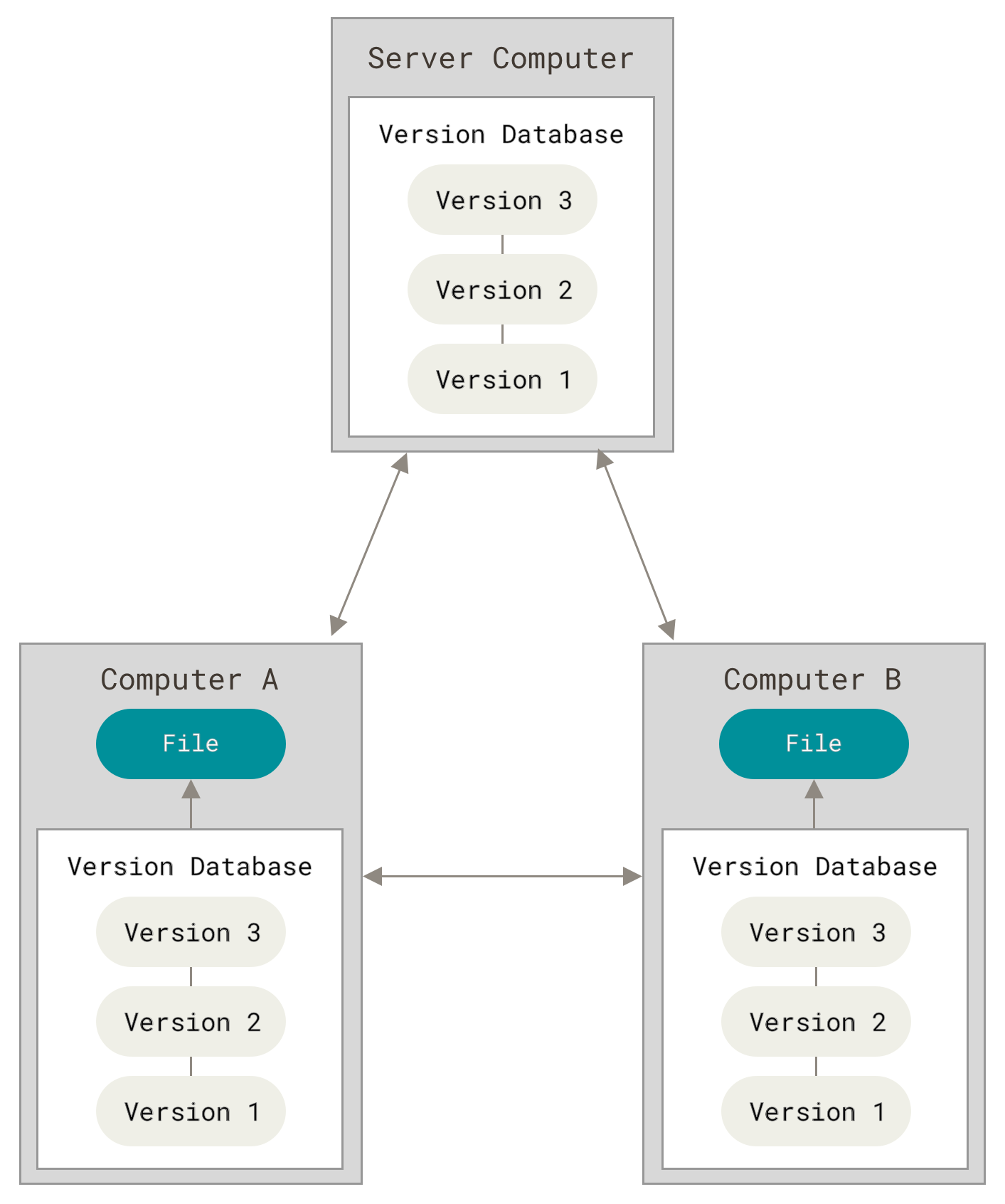
Distributed version control. Image courtesy Giit.com
Since the Agent uses git consistently, we give the Agent the benefit of being able to use the standard git tooling so that it can reason about code changes and history of the project by itself: we even saw it look at the history of a project to restore a bit of code that was refactored away at some point. Having a development tool that is very “In-Distribution” (in other words, very prominent in the LLM’s training dataset) makes it easier for the model to interact with it without further prompting.
But what happens if the Agent accidentally corrupts the git state itself? That is where the design of Bottomless Storage Infrastructure comes in: we can recover just the git object graph from a previous version of the filesystem at a prior point in time. In addition, we store a copy of the git history on a separate disk volume. Every Replit application has an immutable, append-only git remote that can be used to recover the git history even if the entire filesystem is deleted. This gives us much stronger guarantees that we will not lose any critical filesystem data even in the event of an accident.
When we consider the system holistically, an Agent-built application is not just the codebase tracked in git; we also need to consider the Agent state and many side effects, most notably the database.
Forkable Databases and AI Sandboxes
Only versioning the code is not sufficient, as most apps also use a database. The database schema and its data may evolve alongside the code, so it’s essential to keep the database in sync with the code.
Additionally, it’s risky to grant the Agent access to your production database, as the Agent may modify it in destructive or incompatible ways that break your app.
To address this, we use separate production and development databases and grant the Agent access only to the development database. By using our Bottomless Storage Infrastructure, we were able to build this functionality in a fraction of the time and operational overhead it would have taken otherwise: we can create versioned/forkable databases by running an unmodified local instance of PostgreSQL, which stores the data on a filesystem backed by our storage infrastructure.
This means that every time we do a checkpoint, in addition to doing a git commit, we also include the database state, all using the same primitives that we use for regular filesystems.
Aside from regular reads and writes of data, the two most common operations (checkpoint and restore) can be implemented as manifest operations: checkpoint copies the current manifest under a new name, and restore replaces the current manifest with a different version. Now the user can quickly roll back or even fork the database to create a new App and copy the development database contents over. Its performance is also significantly better to provision and update because we’re relying on the same optimizations that we had already built for the rest of storage.
The Future: Transactional Compute and Agent Parallel Simulations
So far, we’ve used this tech to enable easy rollbacks—but it’s so much more powerful. By using fast, isolated forks of both the code and the database, we can give AI agents a sandbox to try out changes in a safe environment.
This means we can relax some of the model’s guardrails in this isolated environment so it can experiment with tools that would be risky to deploy in normal development. Adding log statements, making temporary code and database changes to inject hard-to-codify errors, or even installing additional tools to aid debugging are cases where the model benefits from being a little less constrained.
At the end of the session, the compute and storage go away, but if useful, you can commit the insight and a small code change. If that exploration doesn’t pan out, it can be safely discarded and attempted again with slightly different parameters.
We can even create multiple of these environments in parallel and have different Agents all try to solve the same problem. Using a sub-technique of Inference-Time Scaling called Parallel Sampling, we rely on the LLM’s non-determinism to create multiple different trajectories based on the same initial conditions, which will start diverging from each other. Once they are done, we can pick the best set of changes and apply them atomically to the main app in a single transaction. Previous reports of this technique used in the SWE-bench have increased performance by ~8 percentage points (72→80%).
We’re excited to use these techniques in more places in the Agent. This will allow us to continue making