LaunchDarkly believes software releases should be boring. After too many chaotic launches and stressful nights, its co-founders decided there had to be a better way. Today, LaunchDarkly helps teams take control of releases and understand how users experience their products, so shipping software becomes safer, predictable, and drama-free.
But as the platform expanded from feature flag management into experimentation, product analytics, and observability, the team ran into a familiar challenge. The more insight they wanted to give customers about how their software behaved, the more pressure landed on their own data systems. “Latencies ranged from seconds to minutes, and querying raw data directly never worked well,” says Matt Wagner. “We wanted something …
LaunchDarkly believes software releases should be boring. After too many chaotic launches and stressful nights, its co-founders decided there had to be a better way. Today, LaunchDarkly helps teams take control of releases and understand how users experience their products, so shipping software becomes safer, predictable, and drama-free.
But as the platform expanded from feature flag management into experimentation, product analytics, and observability, the team ran into a familiar challenge. The more insight they wanted to give customers about how their software behaved, the more pressure landed on their own data systems. “Latencies ranged from seconds to minutes, and querying raw data directly never worked well,” says Matt Wagner. “We wanted something that combined cheap storage of raw events with fast, low-latency queries. That’s what led us to ClickHouse.”
Matt and Joe Karayusuf, software engineers on LaunchDarkly’s data platform team, have been central to that transition. Matt has spent six years at the company, much of that time working on data infrastructure. Joe joined a few years later, focusing on ingesting large volumes of data efficiently and helping other teams derive meaning from raw events. Together, they’ve helped reshape LaunchDarkly’s data architecture from a collection of brittle streaming and ETL pipelines into a scalable foundation powered by ClickHouse Cloud.
“We’re already seeing the impact inside the company,” Matt says. “The themes are consistent: faster iteration, simplified architecture, and the ability to build entirely new product capabilities that weren’t feasible under our old systems.”
The limits of streams and warehouses
For years, LaunchDarkly built data features on top of streaming systems. Events flowed into Kinesis, then through Lambda or Flink pipelines that performed in-memory aggregations writing the results directly to Postgres or Redis. “This delivered low latency,” Matt says, “but it was expensive and required constant effort to build and maintain new pipelines for every feature.”
Cost was only part of the problem. Once data passed through the stream, it was effectively gone. Engineers couldn’t easily inspect historical events when something went wrong, which made debugging harder. More importantly, the streaming model forced teams to decide up front which aggregations would matter, leaving little room to explore new questions later.
That limitation was especially clear in experimentation. LaunchDarkly’s CUPED-based features rely on analyzing user behavior before an experiment begins to improve accuracy. In a streaming-first setup, that kind of retrospective analysis was hard to support.
To reduce costs and simplify development, LaunchDarkly later built a batch ETL warehouse. It stored Parquet files in S3, used Airflow to orchestrate pipelines, and relied on Athena for querying and lifecycle management. This was cheaper and easier to extend, but it introduced new friction. Latency stretched into minutes, and querying raw data directly for product experiences rarely worked well. In practice, nearly every UI feature still needed a bespoke ETL job and a derived table, often in Postgres, just to stay responsive.
Tired of the constant tradeoffs between speed, cost efficiency, and flexibility, the data platform team went looking for an alternative. ClickHouse had been coming up more often internally and in conversations with peers at other companies, so the team decided to take a closer look.
They started with a small set of relatively simple use cases, including a time-series chart showing counts of flag evaluations. “We needed low latency and a stable pipeline, something that was difficult to achieve with Airflow,” Joe says. “ClickHouse delivered the freshness and reliability we were looking for.”
It didn’t take long for ClickHouse’s impact to ripple beyond the data platform team. In the past, building data features meant defining aggregations upfront, scheduling pipelines, running migrations, and maintaining purpose-built derived tables. With ClickHouse, teams could query raw data directly and iterate much faster. Performance tuning still required involvement from Matt, Joe, and others, but the baseline experience was far simpler.
“The biggest shift was that ClickHouse reduced the operational and engineering overhead needed to ship new data features,” Joe says. What started as a “small experiment” turned into half a dozen teams adopting it within four months. “This dramatic drop in friction enabled us to ship features that would have previously taken months to develop.”
Today, LaunchDarkly runs ClickHouse as a fully hosted service using ClickHouse Cloud. The decision to go with the managed service was “driven more by operational simplicity than by specific product features,” Matt says. “Spinning up clusters is easy, and the way ClickHouse scales in the cloud has been excellent for us.”
Raw events are sent directly into ClickHouse as they happen, and queries from the application layer are served straight from ClickHouse clusters. There’s no external pre-aggregation pipeline to keep in sync just to power product features. Materialized views are used where they make sense, but they live inside ClickHouse rather than a separate ETL system. The basic idea is simple: store raw events, query them directly, and introduce derived tables only when needed.
Ingestion follows a similar philosophy. Events arrive through an HTTP API, which batches them locally and writes them into S3 using an internal protobuf-based format. A Lambda function converts each batch into standardized Parquet files, and ClickHouse is explicitly instructed to load that data into its own storage using INSERT INTO SELECT. Rather than querying S3 at runtime, ClickHouse pulls the data in and owns it. The ability to import common file formats directly into ClickHouse makes it easy to evolve ingestion over time without reworking everything upstream.
The platform ingests roughly six petabytes per month of uncompressed JSON events, covering feature evaluations, context metadata, and observability signals from production systems around the world. Once the data lands in ClickHouse, it compresses down to hundreds of terabytes while staying fully queryable. New data is typically available to product features in around 30 seconds, compared to several minutes in the previous warehouse, and retention has grown to roughly 100 days, a big step up from what was possible before.
ClickHouse Cloud’s separation of compute and storage has also shaped how the team runs the system. As Matt puts it, “We can double cluster size or add nodes in minutes with no need to reshuffle data, which stands in stark contrast to systems like Elasticsearch that must rebalance shards before changes take effect.” Separating ingest and query workloads gives the team “cleaner scaling and more predictable performance,” since ingest is more CPU-bound while queries are more memory- and cache-heavy.
LaunchDarkly runs one ClickHouse architecture per region—US, EU, and FedRAMP—with all customers in a region sharing the same services. Multi-tenancy is handled at the row level through access controls rather than physical separation. At the company’s current scale, this model has worked well, with the flexibility to revisit it as needs evolve.
Unlocking new features and capabilities
ClickHouse has changed the way LaunchDarkly builds, both in terms of the individual features the team can deliver and how it thinks about data as a product foundation.
One of the early breakthroughs, Joe says, was seeing “how well ClickHouse handles high-cardinality data.” Earlier systems forced the team to limit dimensionality. Pushing large volumes of distinct values into relational databases wasn’t practical, so features had to be simplified or avoided entirely. With ClickHouse, that constraint disappeared. “We could suddenly support far more dimensions and much finer granularity without performance issues.”
That shift unlocked “features we simply couldn’t have built before,” including richer filtering, arbitrary dimensions for evaluations, autocomplete powered by distinct attribute discovery, and LaunchDarkly’s new audience feature, which identifies who saw which flag and when at a per-user level. “That level of detail was out of reach in other databases,” Joe adds.
Today, LaunchDarkly has seven features running in production on ClickHouse, including its entire Observability offering and major parts of its Product Analytics capabilities. Several more are in active development or prototyping, and ClickHouse now underpins a significant portion of LaunchDarkly’s analytics and data-driven product functionality. “At this point, nearly any analytics component in the UI that involves time-series or evaluating behavior over time is backed by ClickHouse,” Joe says.
Importantly, all of those datasets now live together. By storing feature flag evaluations, product analytics, and observability signals in the same system, LaunchDarkly can correlate them directly, paving the way for workflows like regression detection and automatic rollbacks. “This aligns strongly with the broader vision of putting product analytics, observability, and warehouse-style data in one place so teams can reason across them,” Joe says.
One of the team’s biggest lessons has been the importance of getting schema design right early. In their first months with ClickHouse, they made decisions based on assumptions that later proved incorrect. “For example, we tried to coarsen our ORDER BY keys because we thought high granularity would hurt performance,” Matt says. “Later, we learned that ClickHouse is perfectly happy ordering by full timestamps.” By the time that became clear, adoption had grown quickly enough that changing schemas was no longer trivial.
Another learning involved retraining old mental models. “Almost everyone on our team comes from relational OLTP database backgrounds,” Matt says. “ClickHouse is not an OLTP system, and many ingrained habits lead to bad performance.” Queries that worked fine in Postgres could fall apart in ClickHouse because access patterns, joins, and sorting behave differently.
One common example was fetching the “latest N events” by ordering entire rows. LaunchDarkly addressed this with a two-stage query pattern: first selecting lightweight identifiers and ordering those, then fetching the full rows in a second query. Newer versions of ClickHouse address this pattern through late materialization, but the lesson remains.
Beyond technical adjustments, the data platform team has also had to adapt organizationally, as ClickHouse adoption has grown faster than the team itself. “We now have more teams using it than there are engineers supporting it,” Matt says. That has led to teams sometimes solving similar problems in different ways, and to the risk that one team’s query or schema choice could impact others. “We expect to break things along the way and will need to isolate workloads or overprovision temporarily,” he adds. “These are growing pains, but expected ones.”
What’s next for LaunchDarkly and ClickHouse
One of LaunchDarkly’s most ambitious new initiatives is Release Guardian, which pushes ClickHouse into a more unusual role. The goal isn’t just to observe what happens after a release, but to react to it automatically.
To do that, Release Guardian needs to connect feature flag evaluations with downstream signals like errors, latency, and other performance metrics, then detect regressions and trigger responses in near real time. “Historically, we ran this logic in a large Flink application,” Joe says. “But maintaining state in Flink, dealing with serialization, and evolving the pipeline were all painful.”
Now, LaunchDarkly is moving that flow directly into ClickHouse. As events arrive, the system joins feature evaluations with observability metrics and stores the enriched results back in ClickHouse. While performing joins at ingest time isn’t a typical ClickHouse pattern, the tradeoff is intentional. The result is a complete, annotated event history that teams can inspect, question, and recompute analytics over long after the fact. As Joe says, “It produces not only the outcome but also the ‘why,’ which is increasingly important for customers.”
This work also continues LaunchDarkly’s broader consolidation effort. Remaining Elasticsearch-backed workloads, particularly around context metadata and search-heavy experiences, are being migrated into ClickHouse using features like the new JSON data type, bloom filters, and other indexing techniques. “Our expectation is that with some tuning, we will be able to migrate the entire workload from Elasticsearch,” Joe says.
Taken together, these efforts move ClickHouse from being an analytics engine to something closer to a control plane for releases, closing the loop between shipping code, measuring impact, and acting on it automatically.
Balancing cost, freshness, and speed
As Matt and Joe point out, it’s hard to draw a clear before-and-after comparison of ClickHouse’s impact, since “the biggest benefit hasn’t been improving an existing workload, but enabling whole classes of features we couldn’t build before.” That expansion also makes cost savings difficult to isolate. “The moment we adopted ClickHouse,” Matt says, “teams started proposing new data features far more advanced than we were delivering before.”
They did, however, share a graph that illustrates how ClickHouse balances cost, data freshness, and time to build compared to LaunchDarkly’s streaming pipelines and batch warehouse:
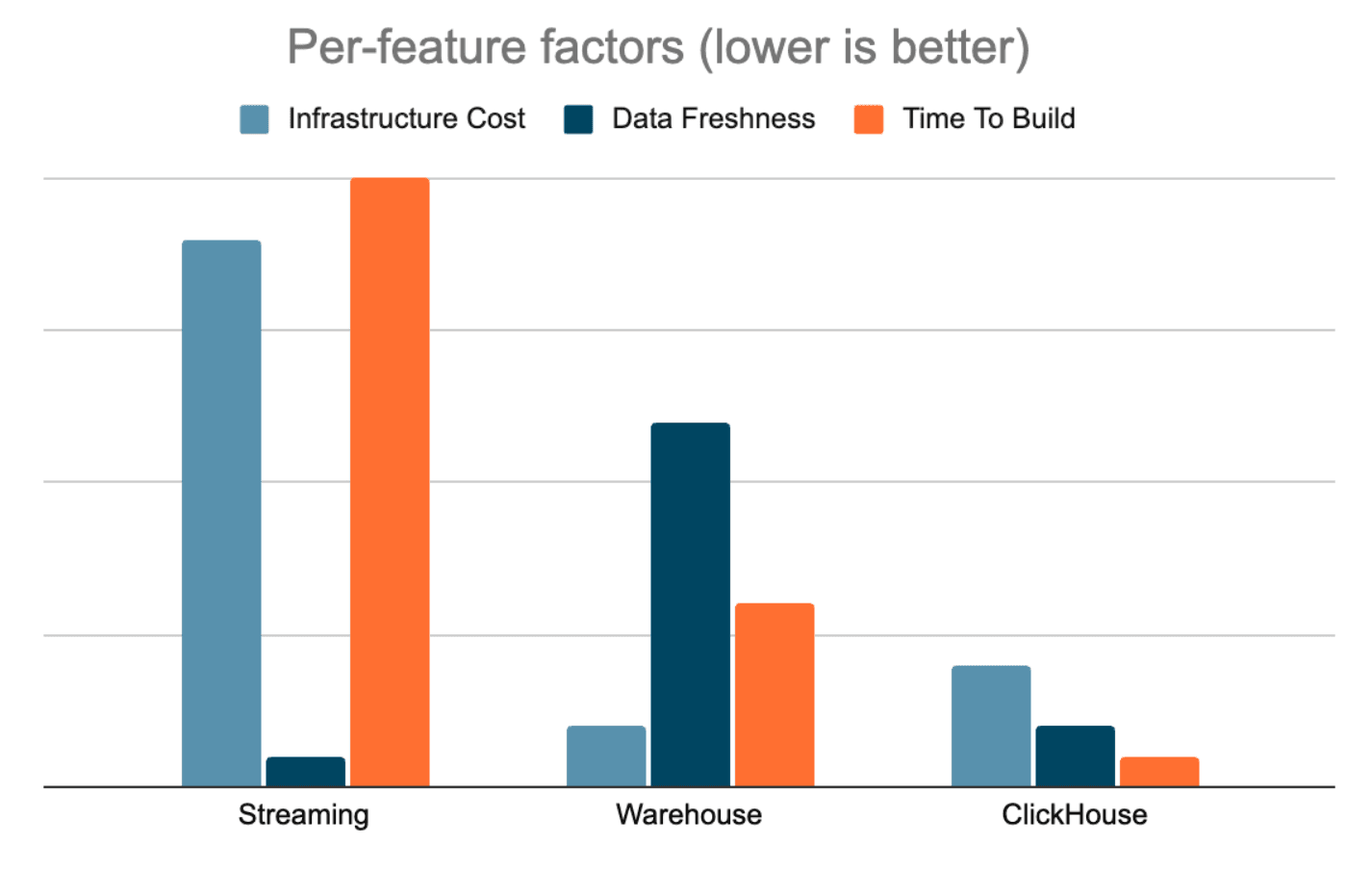
“Our previous streaming architecture was expensive and slow to iterate on, while the batch warehouse was cheaper but had high latency and required extensive ETL work for every new feature,” Matt explains. “With ClickHouse, we can serve fresh data, query raw events directly, lean on materialized views when needed, and build new capabilities in weeks instead of months or quarters.”
Just as important, ClickHouse has unified how LaunchDarkly thinks about data across the organization. By bringing analytics, experimentation, and observability into a single system, the team has reduced architectural complexity while increasing velocity. Engineers can reason across signals, iterate faster, and ship features with more confidence—without rebuilding pipelines every time the product evolves.
Matt sums it up simply: “With ClickHouse, I’ve never seen a technology get adopted for so many big things so quickly, and I’m looking forward to where we’ll be in another year.”