Dropbox Dash uses AI to understand questions about your files, work chats, and company content, bringing everything together in one place for deeper, more focused work. With tens of thousands of potential work documents to consider, both search and agents rely on a ranking system powered by real-time machine learning to find the right files fast. At the core of that ranking in Dash is our feature store, a system that manages and delivers the data signals (“features”) our models use to predict relevance.
To help users find exactly what they need, Dash has to read between the lines of user behavior across file types, company content, and the messy, fragmented realities of collaboration. Then it has to surface the most relevant documents, images, an…
Dropbox Dash uses AI to understand questions about your files, work chats, and company content, bringing everything together in one place for deeper, more focused work. With tens of thousands of potential work documents to consider, both search and agents rely on a ranking system powered by real-time machine learning to find the right files fast. At the core of that ranking in Dash is our feature store, a system that manages and delivers the data signals (“features”) our models use to predict relevance.
To help users find exactly what they need, Dash has to read between the lines of user behavior across file types, company content, and the messy, fragmented realities of collaboration. Then it has to surface the most relevant documents, images, and conversations when and how they’re needed. The feature store is a critical part of how we rank and retrieve the right context across your work. It’s built to serve features quickly, keep pace as user behavior changes, and let engineers move fast from idea to production. (For more on how feature stores connect to context engineering in Dash, check out our deep dive on context engineering right here.)
In this post, we’ll walk through how we built the feature store behind Dash’s ranking system, why off-the-shelf solutions didn’t fit, how we designed for speed and scale, and what it takes to keep features fresh as user behavior changes. Along the way, we’ll share the tradeoffs we made and the lessons that shaped our approach.
 Dropbox Dash: The AI teammate that understands your work
Dropbox Dash: The AI teammate that understands your work
Dash knows your context, your team, and your work, so your team can stay organized, easily find and share knowledge, and keep projects secure, all from one place. And soon, Dash is coming to Dropbox.
Our goals and requirements
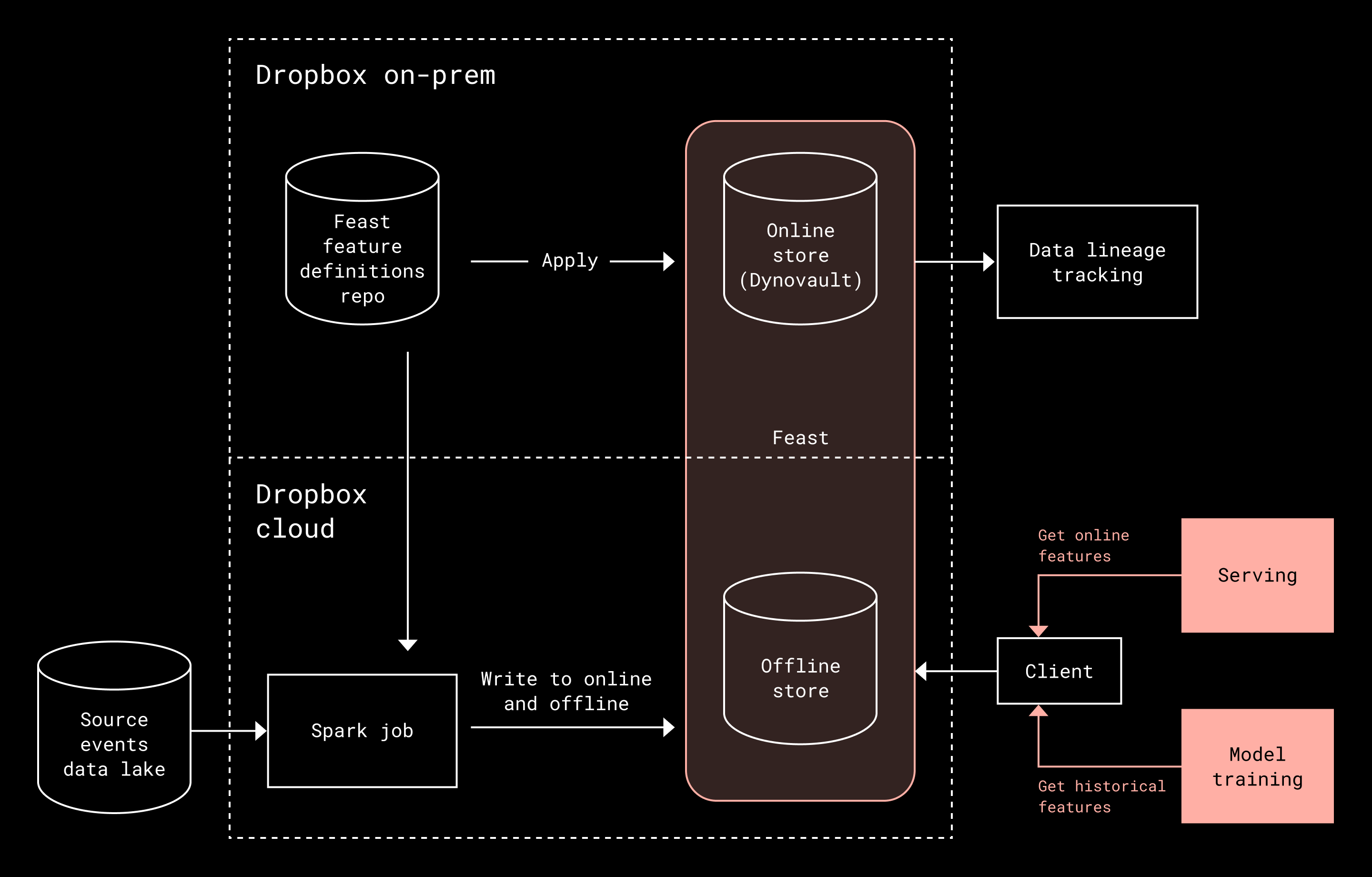
Building a feature store for Dash wasn’t just a matter of picking something off the shelf, and there are a few reasons why. For one, our infrastructure is split across two very different worlds: an on-premises ecosystem designed for low-latency service-to-service communication, and a Spark-native cloud environment where feature engineering and large-scale data processing happens. This split ruled out standard cloud-native feature stores and forced us to find a way to bridge both systems without slowing down development velocity.
On top of that, Dash’s search ranking system brought its own scaling challenge. A single user query doesn’t just pull up one document. Instead, it triggers our ranker to evaluate many files, each requiring dozens of behavioral and contextual features. What starts as one search quickly fans out into thousands of feature lookups across interaction history, metadata, collaboration patterns, and real-time signals. Ultimately, our feature store had to handle those kinds of massive parallel reads while still meeting strict, sub-100ms latency budgets.
Relevance also depends on speed and capturing user intent in real-time. If a user opens a document or joins a Slack channel, that signal should show up in their next search—within a few seconds—which meant building an ingestion pipeline that could keep up with user behavior at scale.
Finally, we had to reconcile two very different computation patterns. Some features naturally fit real-time streaming, while others depend on batch processing of historical data. We needed a unified framework that could support both efficiently, thereby reducing cognitive load for engineers and giving them a faster path from idea to production-ready features.
Designing our hybrid feature store
After surveying the feature store landscape—Feast, Hopsworks, Featureform, Feathr, Databricks, and Tecton—Feast stood out for two reasons. First, its clear separation between feature definitions and infrastructure concerns meant our machine learning engineers could focus purely on writing PySpark transformations rather than the serving, storage, or orchestration complexity. Second, Feast’s modular architecture and extensive adapter ecosystem made it straightforward to integrate with our existing infrastructure. (An adapter refers to a Feast-provided interface that integrates its framework with different backend systems.) Its AWS DynamoDB adapter was particularly crucial, allowing us to leverage Dynovault—our in-house DynamoDB-compatible storage solution—to meet latency requirements while lowering costs.
Our Feast-based architecture combines three key components, each optimized for its role.
Feast gave us the orchestration layer and serving APIs, but we swapped out its Python online serving path for our own Go service so we could actually hit the concurrency and latency numbers we needed.
Cloud-based storage took care of the heavy lifting of offline indexing and storage, while **Spark **jobs handled feature ingestion and computation.
Dynovault handled the instant feature lookups needed for each search query. Co-located with inference workloads and leveraging Dropbox’s hybrid cloud infrastructure, Dynovault avoids the delay of public internet calls and reliably delivers ~20ms client-side latency while balancing cost and geographic scalability.
Around this core architecture, we added observability through job failure monitoring, freshness tracking, and data lineage visibility. The result is a streamlined experience: engineers choose a data source, write PySpark transformations, and request features where needed, while the infrastructure abstracts away offline and online data management, pipeline orchestration, low-latency serving, and data freshness guarantees.
Making search fast
With the architecture in place, the next challenge was meeting Dash’s sub-100ms latency requirements. Feature retrieval sits directly on the critical path of search and LLM answer generation, so even small delays compound quickly at scale and degrade Dash’s snappy search retrieval experience.
Our initial feature-serving implementation was built in Python using the Feast SDK. While parallelism helped at moderate scale, profiling revealed that CPU-bound JSON parsing and Python’s Global Interpreter Lock became the dominant bottlenecks under higher concurrency. Moving to multiple processes temporarily improved latency, but introduced coordination overhead that limited scalability.
To remove these constraints, we rewrote the feature serving layer in Go. Using lightweight goroutines, shared memory, and faster JSON parsing, the Go service delivers true concurrency without the coordination costs we hit in Python. Today, it handles thousands of requests per second while adding only ~5–10ms of processing overhead on top of Dynovault’s client latency, consistently achieving p95 latencies in the ~25–35ms range.
This shift allowed us to meet Dash’s latency targets reliably and ensured that feature serving wouldn’t become the limiting factor as search traffic and feature complexity continued to grow.
Keeping features fresh
Speed matters only when the data itself is fresh. Stale features can lower ranking quality and hurt user experience, so our feature store had to reflect new signals as soon as possible, often within minutes of user actions.
The challenge was scale. Many of Dash’s most important features depend on large joins, aggregations, and historical context, which makes fully real-time computation impractical. We needed an ingestion strategy that balanced freshness with reliability, without overwhelming our infrastructure or slowing development. To do that, we built a three-part ingestion system.
Batch ingestion handles complex, high-volume transformations built atop the medallion architecture (a layered data model that organizes data from raw to refined stages). Rather than rewriting every feature on each run, we added intelligent change detection so only modified records are written to the online store. This reduced write volumes from hundreds of millions to under one million records per run and cut update times from more than an hour to under five minutes.
Streaming ingestion captures fast-moving signals such as collaboration activity or content interactions. By processing unbounded datasets in near-real time, it ensures features stay aligned with what users are doing in the moment.
Direct writes handle lightweight or precomputed features by bypassing batch pipelines entirely. For example, relevance scores produced by a separate LLM evaluation pipeline can be written directly to the online store in seconds instead of waiting for the next batch cycle.
Together, these approaches allow Dash to keep feature values fresh without forcing all computation onto a single ingestion path, maintaining ranking quality while scaling to real-world usage.
What we learned
Building a feature store at Dropbox scale reinforced a few hard-earned lessons about systems design. On the serving side, Python’s concurrency model became a limiting factor for high-throughput, mixed CPU and I/O workloads. Even with careful parallelism, the Global Interpreter Lock capped performance for CPU-bound work like JSON parsing, and moving to multiple processes introduced new coordination bottlenecks. Rewriting the serving layer in Go allowed us to remove those tradeoffs and scale concurrency more predictably.
On the data side, infrastructure changes mattered, but understanding access patterns mattered just as much. By recognizing that only 1–5% of feature values change in a typical 15-minute window, we were able to dramatically reduce write volumes and ingestion time. This shift turned hour-long batch cycles into five-minute updates, improving freshness without increasing system load.
These optimizations came together in a hybrid architecture that balances flexibility and performance: Feast for orchestration and consistency, Spark for large-scale computation, and Dynovault for low-latency online serving. Rather than relying on a single vendor solution, this approach let us tune each layer to its strengths while keeping training and serving aligned.
Ultimately, this work underscored the value of a middle path between building everything from scratch and adopting off-the-shelf systems wholesale. By combining open source foundations with internal infrastructure and tailoring them to real constraints, we were able to build a feature store that fits the needs of Dash today and, ultimately, can evolve with it in the future.
*Acknowledgments: Special thanks to all current and past members of the AI/ML Platform and Data Platform teams for their contributions, as well as our lovely machine learning engineers who spin up the magic with the tooling we build. *
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.