Yajuan Si, James Wagner, and Ron Kessler write:
The traditional use of high-quality probability samples to carry out psychiatric epidemiological surveys of the household population is facing increasing financial and operational challenges. Surveys from nonprobability and probability-based online panels have emerged as cost-effective alternatives with the additional advantage of rapid turnaround time, albeit with biases that can in some cases be substantial.
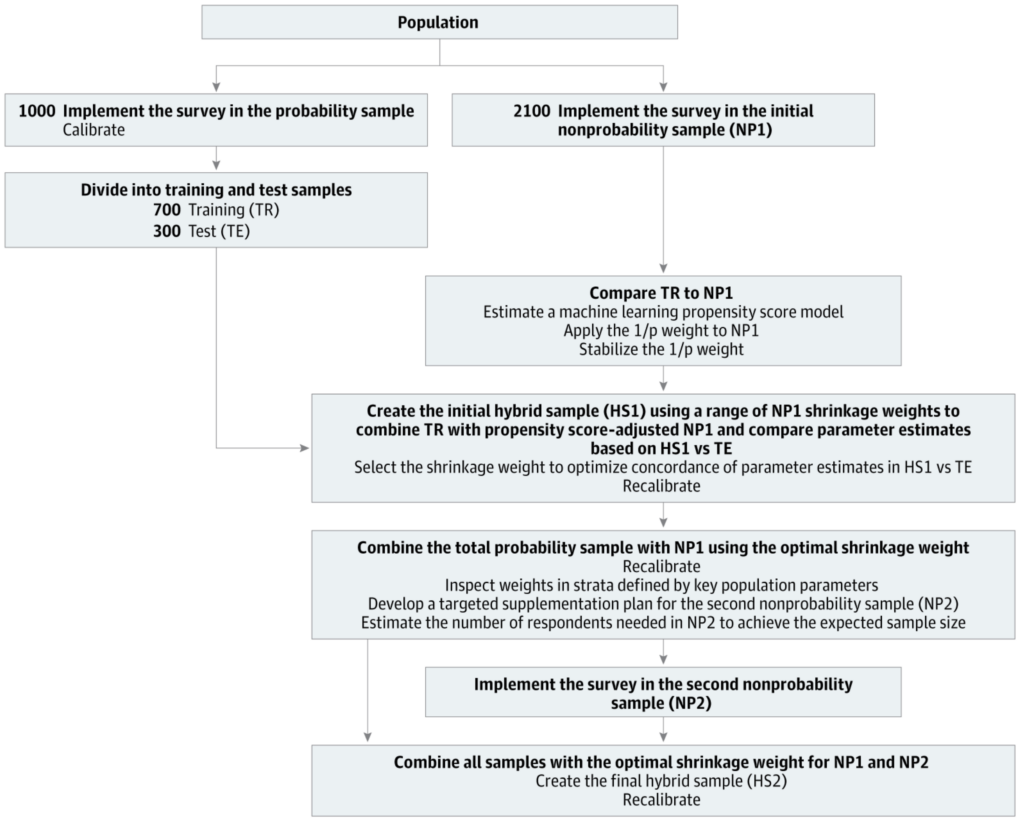
We recommend a middle ground of integrating surveys from online panels with small parallel high-quality probability samples . . . The key features of such “hybrid designs” are as follows: use of a high-quality probability sample as a population surrogate to provide information about the distributions of otherwise unavailable variables that differentiate participants in online panels from the larger household population, inclusion in both surveys of measures that are both strongly associated with the outcomes of interest and strongly predictive of membership in the online panel, and use of best-practice statistical methods that blend results across the 2 samples.
Such a hybrid design should be the minimally acceptable design for psychiatric epidemiological surveys of the household population given the biases known to exist in online panels. However, we also comment on several other designs that might be used for more rapid and less expensive exploratory analyses.
This is interesting, to think of multi-frame, multi-mode sampling as best practice in itself rather than as an awkward problem to be dealt with only if absolutely necessary.
Yajuan offers some background on the project:
This is my first time writing a paper without any equations or data modeling but having to rely on solid statistical knowledge, understanding the extensive literature, and gathering lots of data. And Ron Kesser is a phenomenal collaborator. I learned a lot from working with him.
Anyway, here is the idea of the paper: We propose a hybrid data collection of large-scale nonprobability samples and small parallel high-quality probability samples as common practice for population-based research. For MRP applications, we often struggle with the availability of population information of X. We propose to estimate the population distribution of X in a small probability sample, after we identify the list of highly predictive covariates X for the outcome Y. We can also collect Y in the probability sample. We propose the sequential weighting adjustment by first weighting the probability sample to the census data (this should be based a small list of adjustment factors, say only demographics, assuming the probability sample design is well controlled and nonresponse bias is small) and then weighting the nonprobability sample to the initially weighted probability sample (the list of adjustment factors could be large, even including the outcome). After the sequential weighting, the combined samples can give us enough power for small area estimates. I use weighting adjustment here for simplicity, but we can also use MRP for the adjustment if we have an outcome of interest.
Basically, I’m trying to push the MRP adjustment from post-collection inference to inform study design and modify data collection adaptively, releasing the burden or strong assumptions on analysis by improving the study design from the starting point.
This is interesting and potentially important for several reasons:
1. Data quality of survey responses is becoming more and more of an issue, and it makes sense to try to reach potential respondents in more comfortable places than the traditional survey interview.
2. We should be thinking more systematically about how to integrate data from multiple sources.
3. MRP can be adapted to more general data structures.
4. As Yajuan says, we should be aware of all these data collection and analysis issues in the design stage.