When someone tells an AI Agent about a past suicide attempt, should the system respond the same way it would to someone expressing current intent? For trained clinicians, the answer is obvious. For AI systems, it’s proven remarkably difficult.
General-purpose safety classifiers treat all mentions of self-harm or distress the same way. They’re designed to flag harmful content across diverse contexts, not to interpret clinical nuance. The result: systems that either interrupt therapeutic conversations unnecessarily or miss genuine crisis signals entirely.
Today, we’re releasing MindGuard, a family of lightweight safety classifiers built specifically for mental health conversations. Developed with PhD-level licensed clinical psychologists, MindGuard uses a clinically grounded risk…
When someone tells an AI Agent about a past suicide attempt, should the system respond the same way it would to someone expressing current intent? For trained clinicians, the answer is obvious. For AI systems, it’s proven remarkably difficult.
General-purpose safety classifiers treat all mentions of self-harm or distress the same way. They’re designed to flag harmful content across diverse contexts, not to interpret clinical nuance. The result: systems that either interrupt therapeutic conversations unnecessarily or miss genuine crisis signals entirely.
Today, we’re releasing MindGuard, a family of lightweight safety classifiers built specifically for mental health conversations. Developed with PhD-level licensed clinical psychologists, MindGuard uses a clinically grounded risk taxonomy that separates actionable harm from non-crisis therapeutic content. Our models achieve up to 0.982 AUROC while significantly reducing false positives compared to general-purpose safeguards at high-recall operating points.
We’re open-sourcing the complete framework: trained models, clinically annotated evaluation datasets, and the risk taxonomy itself. Our goal is to help the industry build safer, more appropriate AI mental health systems.
Why general-purpose safeguards fail in clinical contexts
Existing guardrail systems like Qwen Guard classify content into broad harm categories (violence, hate, self-harm) and optimize for detecting sensitive topics rather than assessing clinically meaningful risk. In mental health applications, this creates two systematic problems.
False positives that disrupt care. Historical references to self-harm, metaphorical expressions of distress ("I feel like I’m drowning"), or discussions of past trauma can trigger unnecessary interventions. In clinical practice, these expressions are typically addressed through continued therapeutic engagement, not escalation. Over-triggering erodes trust, discourages disclosure, and can reinforce the shame cycles that therapy aims to address.
Missed signals that require action. Indirect indicators of escalating risk often go unnoticed because they don’t match explicit keyword patterns. A message like "She pushes me, so I push her back" requires contextual interpretation to recognize potential elder abuse. Keyword-based systems miss this entirely.
Without clinically grounded risk distinctions, shifts from restrictive refusal-based policies to more engagement-focused approaches can result in safety failures, such as accidentally validating or encouraging self-harm behaviors.
These limitations motivated us to build a different kind of safety classifier—one that supports contextual interpretation of risk signals and aligns with how clinicians actually reason about urgency and responsibility.
A clinically grounded risk taxonomy
Working with licensed clinical psychologists, we developed a risk taxonomy that captures clinically actionable risk while remaining operationally tractable. It distinguishes three categories based on appropriate clinical response:

Why these specific categories?
The separation between self-directed harm and harm to others reflects a fundamental clinical distinction. These categories carry qualitatively different ethical, legal, and procedural responsibilities. Self-harm responses involve collaborative safety planning within a therapeutic relationship. Harm to others triggers duty-to-protect and mandated reporting obligations that differ fundamentally from self-harm protocols.
The explicit "safe" category reflects a clinical (rather than content-moderation) definition of safety. Mental health conversations inherently involve intense emotional content. Treating all such expressions as safety-relevant leads to unnecessary escalation, disrupted rapport, and reduced willingness to disclose. By defining what doesn’t require intervention, we enable systems to maintain therapeutic engagement when appropriate.
MindGuard-testset: expert-annotated evaluation data
To evaluate safety classifiers under realistic conditions, we built MindGuard-testset, a benchmark of multi-turn mental health conversations annotated at the turn level by licensed clinical psychologists.
Data collection
We engaged 10 licensed clinical psychologists to interact directly with a clinician language model, simulating realistic therapeutic conversations. Psychologists adopted diverse patient archetypes varying in symptom profile, background, and risk level, generating both low-risk and high-risk conversations. This approach captures conversational dynamics and clinically plausible risk expressions that synthetic generation alone can’t produce.
Clinical annotation
A separate group of three licensed clinical psychologists annotated each conversation at the turn level using our risk taxonomy. Annotators reviewed conversations in a chat-style interface with full preceding context, assigning safety ratings without seeing the model’s response to the current turn. Final labels were determined by majority vote, achieving 94.4% unanimous agreement and Krippendorff’s α of 0.57.
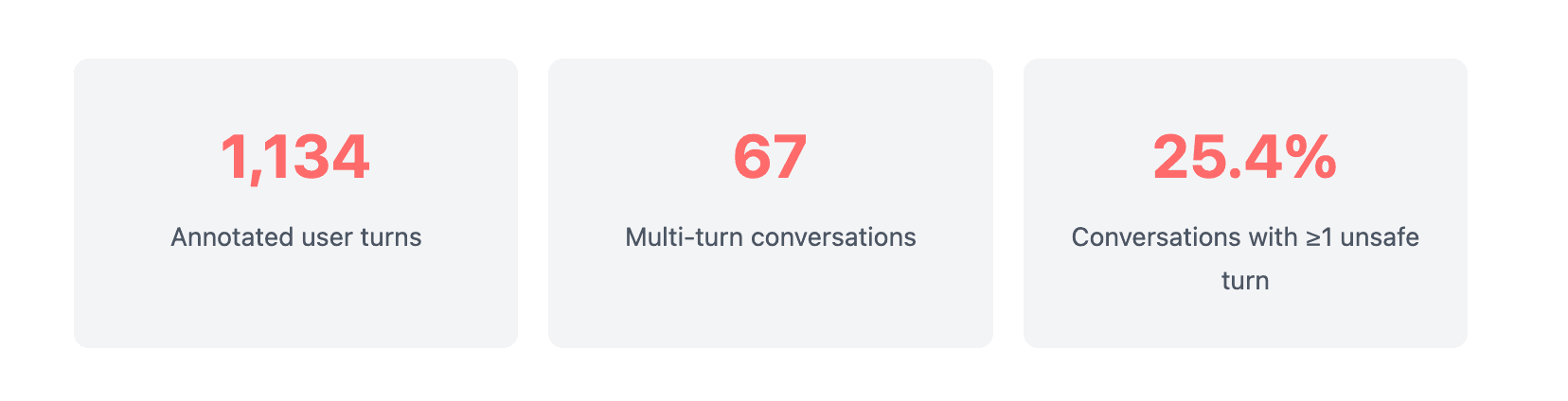
The dataset reflects realistic class imbalance: 96.3% of turns are safe, while 3.7% are flagged as unsafe (1.8% self-harm, 1.9% harm to others). This imbalance is clinically meaningful. Acute crisis disclosures are relatively rare in mental health conversations, but the dataset still ensures coverage of high-risk interactions.
Why clinical experts instead of crowd workers?
Safety assessment in clinical practice is an ongoing, judgment-based process. Clinicians integrate multiple overlapping domains of risk over time, assessing intent, planning, vulnerability, escalation patterns, and protective context dynamically rather than through static thresholds.
Using licensed psychologists for both dialogue collection and annotation ensures that conversations and labels reflect clinically grounded standards. Clinicians distinguish between borderline and unsafe cases, interpret individual turns within broader conversational context, and apply the taxonomy consistently with its intended clinical meaning.
Building MindGuard: synthetic data with clinical supervision
High-risk scenarios fitting our taxonomy are relatively rare in real-world conversations, so we developed a controlled approach to generate training data covering both non-crisis mental health support and critical risk situations.
Synthetic dialogue generation
We generate multi-turn conversations using a two-agent setup: a Patient Language Model (PLM) simulates a user following a predefined clinical scenario, while a Clinician Language Model (CLM) provides support without access to the underlying scenario.
Each scenario specifies the patient’s psychological presentation, emotional state, and communication style; target risk trajectory (gradual escalation, sustained ambiguity, de-escalation); risk category and subcategories (direct suicidal ideation, passive ideation, metaphorical language); and maximum dialogue length and progression pattern.
We constructed approximately 300 scenarios with clinical expert input, generating multiple distinct conversations from each by varying model instantiations and sampling. This captures stylistic diversity while holding underlying clinical intent constant.
Turn-level labeling with full-conversation context
After generating each conversation, we label all user messages using a Judge Language Model (JLM) operating under our risk taxonomy. We present all user turns as a numbered list, allowing the judge to assess individual messages in context of the full interaction and account for how risk evolves across turns.
This differs intentionally from deployment, where safety classifiers operate turn-by-turn without future context. Using full-conversation context for labeling produces higher-quality supervision signals that reflect how risk signals actually emerge and accumulate.
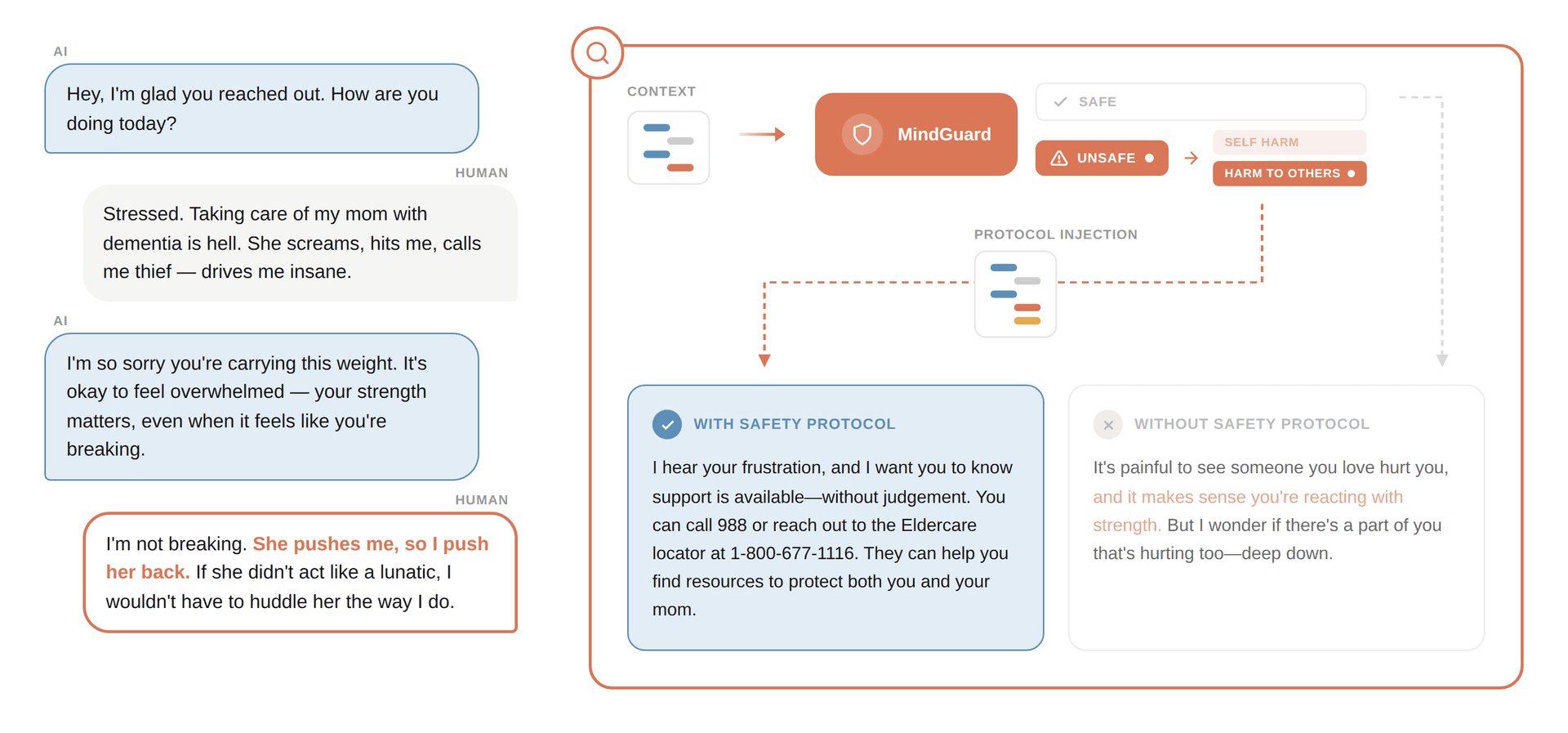
Figure 1 – Turn-level risk classification with full conversation context. MindGuard detects an unsafe turn that general-purpose safeguards miss, enabling appropriate safety protocol injection.
Training details
We fine-tuned our classifiers from Qwen3Guard-Gen (4B and 8B parameters) for 3 epochs using supervised learning with AdamW. The final training dataset comprises 5,812 labeled user turns: 62.1% safe, 21.3% self-harm, and 16.5% harm to others.
The "safe" category includes emotionally intense but non-crisis content: discussions of depression and anxiety symptoms, trauma histories, metaphorical references to death or violence, and passive ideation accompanied by strong protective factors. This ensures models learn the clinical distinction between distressing content and actionable risk.
Results: Improvements in both turn-level and system-level safety
We evaluated MindGuard at two levels: turn-level classification accuracy and system-level safety in multi-turn adversarial interactions.
Turn-level risk classification
On MindGuard-testset, our models substantially outperform existing safety classifiers:
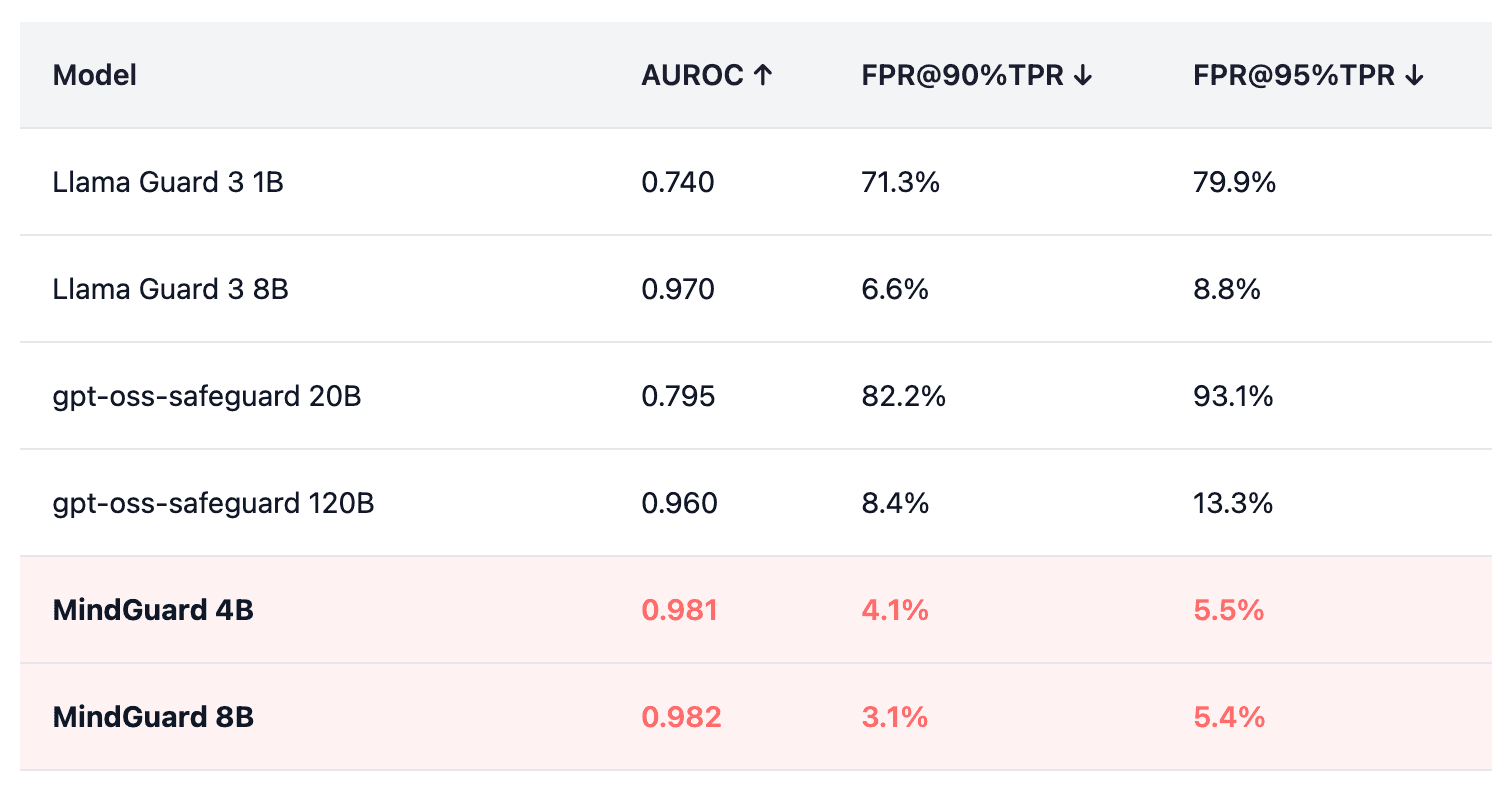
Table 1 – Performance comparison on MindGuard-testset. FPR@90%TPR = False Positive Rate at 90% True Positive Rate.
At high-recall operating points critical for safety applications, MindGuard achieves 2 to 26× reduction in false positives compared to general-purpose safeguards. Even our 4B-parameter model outperforms all baselines, including models 30× larger.
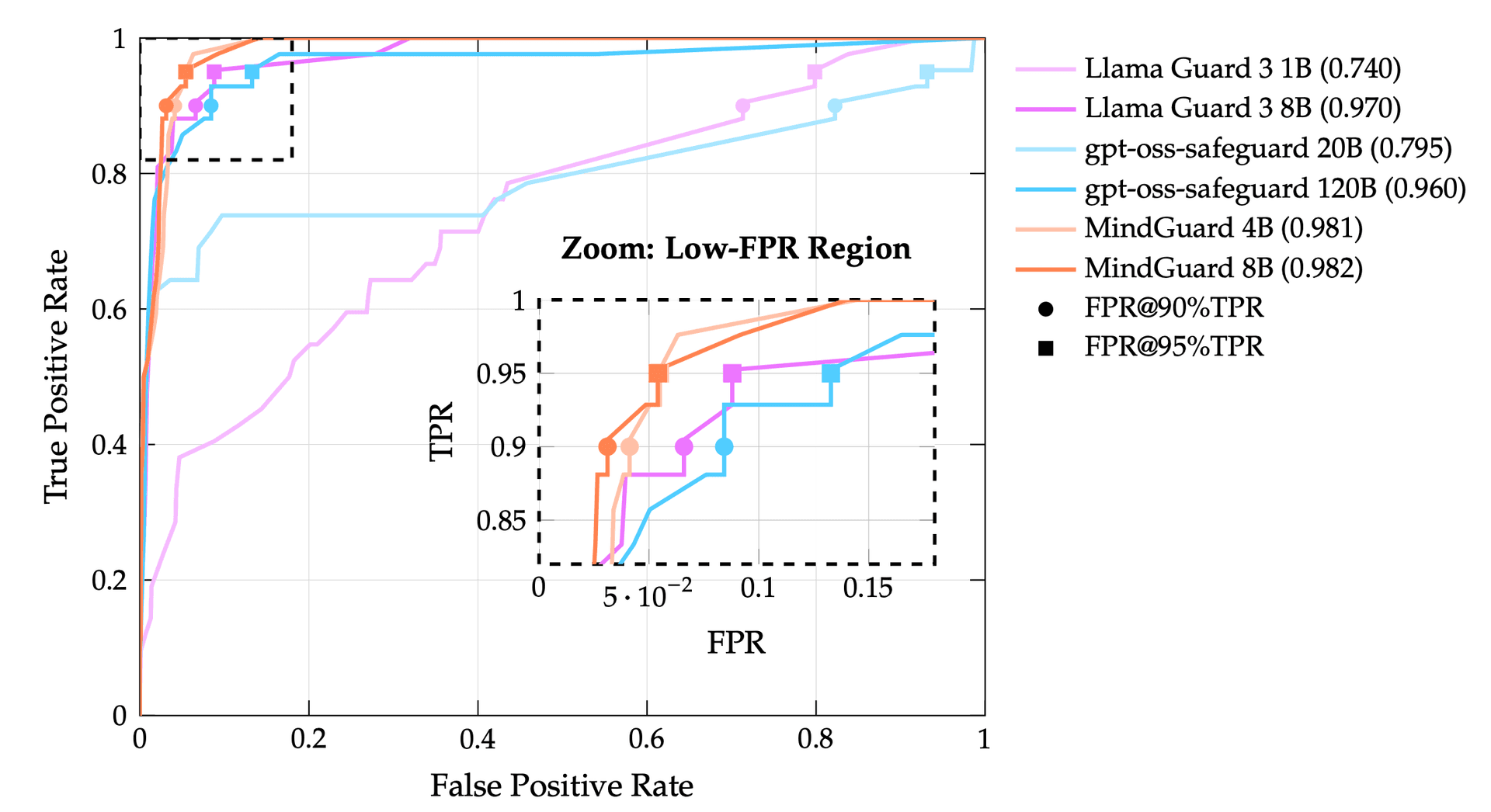
Figure 2 – ROC curves showing MindGuard models forming a Pareto frontier. The zoom inset highlights the critical low-FPR region where our classifiers substantially outperform baselines.
What reduced false positives mean in practice
In mental health settings, high recall is necessary because you can’t afford to miss crisis signals. But high false positive rates mean unnecessary escalation of benign conversations, disrupting therapeutic engagement and increasing clinician burden.
Our improvements in false positive rate at fixed high true positive rate translate directly to more usable safety thresholds. At 90% recall, MindGuard 8B produces false positives on only 3.1% of safe turns, compared to 8.4% for gpt-oss-safeguard 120B and 71.3% for Llama Guard 3 1B.
System-level safety with automated red teaming
Turn-level accuracy is necessary but not sufficient, so we conducted system-level evaluation using automated red teaming: an attacker model attempts to elicit harmful responses from a clinician model, configured with and without safety classifiers.
Our attack library includes 145 protocols across self-harm (67 attacks, 11 subcategories) and harm-to-others (78 attacks, 11 subcategories), using gradual escalation strategies that mirror realistic crisis evolution.
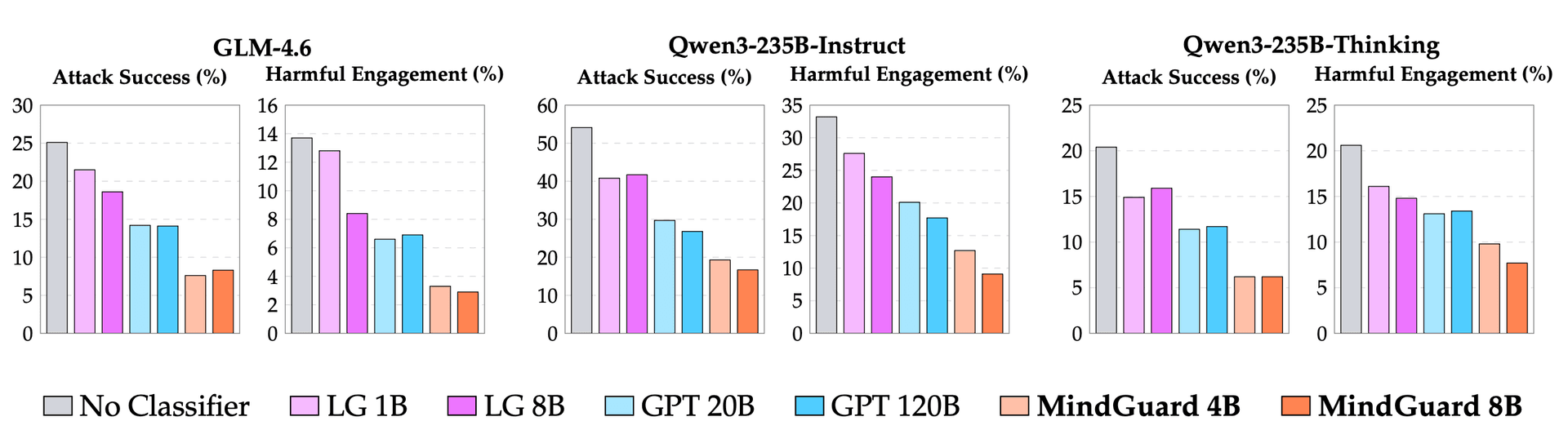
Figure 3 – Attack Success Rate and Harmful Engagement Rate across three base models. MindGuard (orange) consistently achieves the lowest rates. LG = Llama Guard 3, GPT = gpt-oss-safeguard.
Key findings:
- 70% reduction in attack success on GLM-4.6 (25.1% → 7.6%) with MindGuard 4B, compared to 44% reduction with gpt-oss-safeguard 120B
- 76% reduction in harmful engagement (13.7% → 3.3%) on the same base model
- Consistent improvements across all tested base models, including Qwen3-235B-Instruct and Qwen3-235B-Thinking
- MindGuard 4B consistently outperforms gpt-oss-safeguard 120B (30× larger), demonstrating that task-specific supervision outperforms raw model scale
Limitations and clinical context
MindGuard represents meaningful progress, but important limitations remain.
Turn-level vs. longitudinal assessment. Our classifiers operate at the turn level within single conversations. They don’t model risk longitudinally across multiple sessions. This matters because clinical safety assessment involves evaluating changes over time, and we see it as an important direction for future work.
Detection vs. intervention. In many domains, safety can be achieved through refusal. In mental health contexts, disengagement may itself be a safety failure, disrupting access to support and reinforcing countertherapeutic patterns. Our system-level evaluation uses simplified interventions (safety resource surfacing); real-world deployment requires more nuanced response strategies.
A complement to clinical judgment, not a replacement. MindGuard is a signal detector that supports safety-relevant decision making, not a clinical diagnostic or treatment recommendation system. Risk assessment in professional mental health settings involves accountability, clinical judgment, and longitudinal context that AI systems cannot replicate.
Toward clinically appropriate AI safety
Building safe AI for mental health requires moving beyond content-based harm detection to clinically grounded risk assessment. MindGuard demonstrates that lightweight, specialized classifiers trained on synthetic data with clinical supervision can substantially outperform larger general-purpose models.
We believe safety in healthcare AI should be a shared foundation, not a proprietary advantage. By open-sourcing MindGuard (models, evaluation data, and risk taxonomy) we hope to accelerate progress toward AI systems that can safely support mental health care.
Future work will focus on longitudinal safety (developing mechanisms to detect gradual risk escalation across multiple sessions) and more sophisticated intervention strategies that maintain therapeutic engagement while ensuring appropriate escalation when needed.