Small models are rapidly becoming more capable and applicable across a wide variety of enterprise use cases. At the same time,each new GPU generation packs dramatically more compute and memory bandwidth. The result? Even under high-concurrency workloads, small LLMs often leave a large fraction of GPU compute and memory bandwidth idle.
With use cases such as code completion, retrieval, grammar correction, or specialized models, our enterprise customers serve many such small language models on Databricks, and we are constantly pushing GPUs to their limits. NVIDIA’s Multi-Process Service (MPS) looked like a promising tool: it allows multiple inference processes to share a single GPU context, enabling their memory and compute operations t…
Small models are rapidly becoming more capable and applicable across a wide variety of enterprise use cases. At the same time,each new GPU generation packs dramatically more compute and memory bandwidth. The result? Even under high-concurrency workloads, small LLMs often leave a large fraction of GPU compute and memory bandwidth idle.
With use cases such as code completion, retrieval, grammar correction, or specialized models, our enterprise customers serve many such small language models on Databricks, and we are constantly pushing GPUs to their limits. NVIDIA’s Multi-Process Service (MPS) looked like a promising tool: it allows multiple inference processes to share a single GPU context, enabling their memory and compute operations to overlap — effectively squeezing far more work out of the same hardware.
We set out to rigorously test whether MPS delivers higher throughput per GPU in our production environments. We found that MPS delivers meaningful throughput wins in these regimes:
- Very small language models (≤3B parameters) with short-to-medium context (<2k tokens)
- Very small language models (<3B) in prefill-only workloads
- Engines with significant CPU overhead
The key explanation, based on our ablations, is twofold: at the GPU level, MPS enables meaningful kernel overlap when individual engines leave compute or memory bandwidth underutilized—particularly during attention-dominant phases in small models; and, as a useful side effect, it can also mitigate CPU bottlenecks like scheduler overhead or image-processing overhead in multimodal workloads by sharding the total batch across engines, reducing per-engine CPU load.
What is MPS?
NVIDIA’s Multi-Process Service (MPS) is a feature that allows multiple processes to share a single GPU more efficiently by multiplexing their CUDA kernels onto the hardware. As NVIDIA’s official documentation puts it:
The Multi-Process Service (MPS) is an alternative, binary-compatible implementation of the CUDA Application Programming Interface (API). The MPS runtime architecture is designed to transparently enable co-operative multi-process CUDA applications.
In simpler terms, MPS provides a binary-compatible CUDA implementation within the driver that allows multiple processes (like inference engines) to share the GPU more efficiently. Instead of processes serializing access (and leaving the GPU idle between turns), their kernels and memory operations are multiplexed and overlapped by the MPS server when resources are available.
The Scaling Landscape: When Does MPS Help?
On a given hardware setup, the effective utilization depends heavily on model size, architecture, and context length. Since recent large language models tend to converge on similar architectures, we use the Qwen2.5 model family as a representative example to explore the impact of model size and context length.
Below experiments compared two identical inference engines running on the same NVIDIA H100 GPU (with MPS enabled) against a single-instance baseline, using perfectly balanced homogeneous workloads.
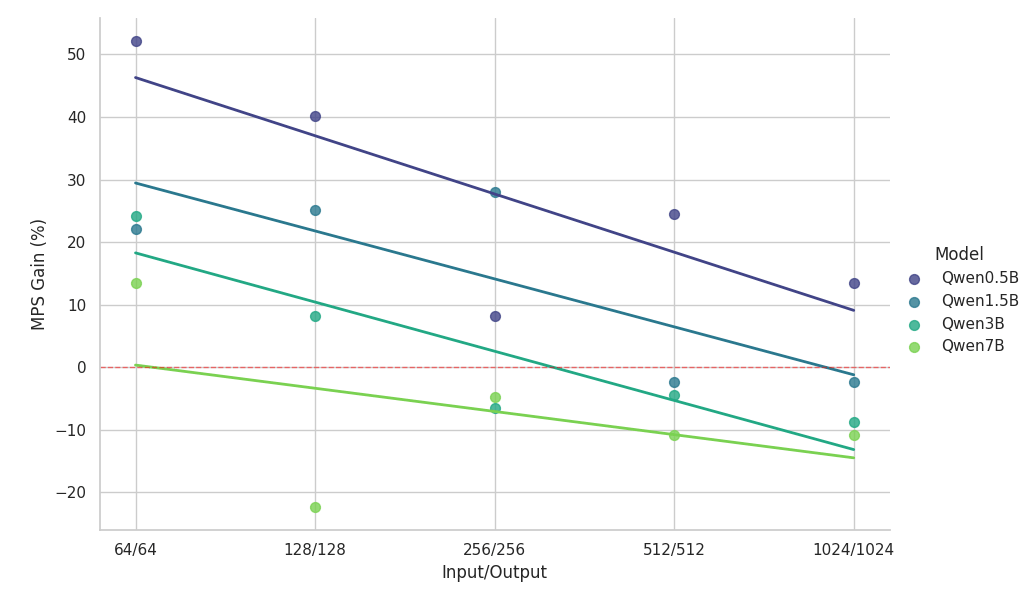
Scaling Study for Qwen2.5 Series Model Family (Fixed Batch Size = 1024)
{kind=link}
Key observations from the scaling study:
- MPS delivers >50% throughput uplift for small models with short contexts
- Gains drop log-linearly as context length increases — for the same model size.
- Gains also shrink rapidly as model size grows — even in short contexts.
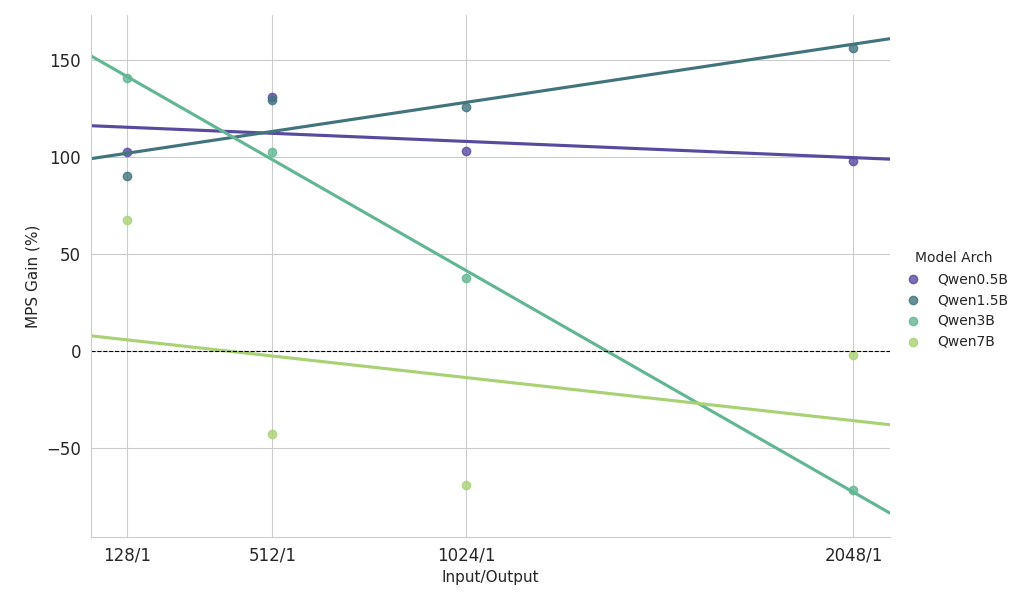
- For the 7B model or 2k context, the benefit falls below 10% and eventually incurs a slowdown. Prefill Scaling Study for Qwen2.5 Series Model Family (Fixed Batch Size = 256)
{kind=link}
Key observations from the scaling study on prefill heavy workload
- Small Models (<3B): MPS consistently delivers a throughput improvement of over 100%.
- Mid-sized Models (~3B): Benefits diminish as context length increases, eventually leading to performance regression.
- Large Models (>3B): MPS provides no performance benefit for these model sizes.
The scaling results above show the benefits of MPS are most pronounced for low GPU utilization setups, small model and short context, which facilitate effective overlapping.
Dissecting the Gains: Where Do MPS Benefits Really Come From?
To pinpoint exactly why, we broke down the problem along the two core building blocks of modern transformers: the MLP (multi-layer perceptron) layers and the Attention mechanism. By isolating each component (and removing other confounding factors like CPU overhead), we could attribute the gains more precisely.
GPU Resources Needed
N = Context LengthPrefill (Compute)Decode (Memory Bandwidth)Decode (Compute) MLPO(N)O(1)O(1) AttnO(N^2)O(N)O(N)
Transformers consist of Attention and MLP layers with different scaling behavior:
- MLP: Loads weights once; processes each token independently -> Constant memory bandwidth and compute per token.
- Attention: Loads KV cache and compute dot product with all previous tokens → Linear memory bandwidth and compute per token.
With this in mind, we ran targeted ablations.
MLP-only models (Attention removed)
For small models, the MLP layer might not saturate compute even with more tokens per batch. We isolated the impact of MLP by removing the attention block from the model.
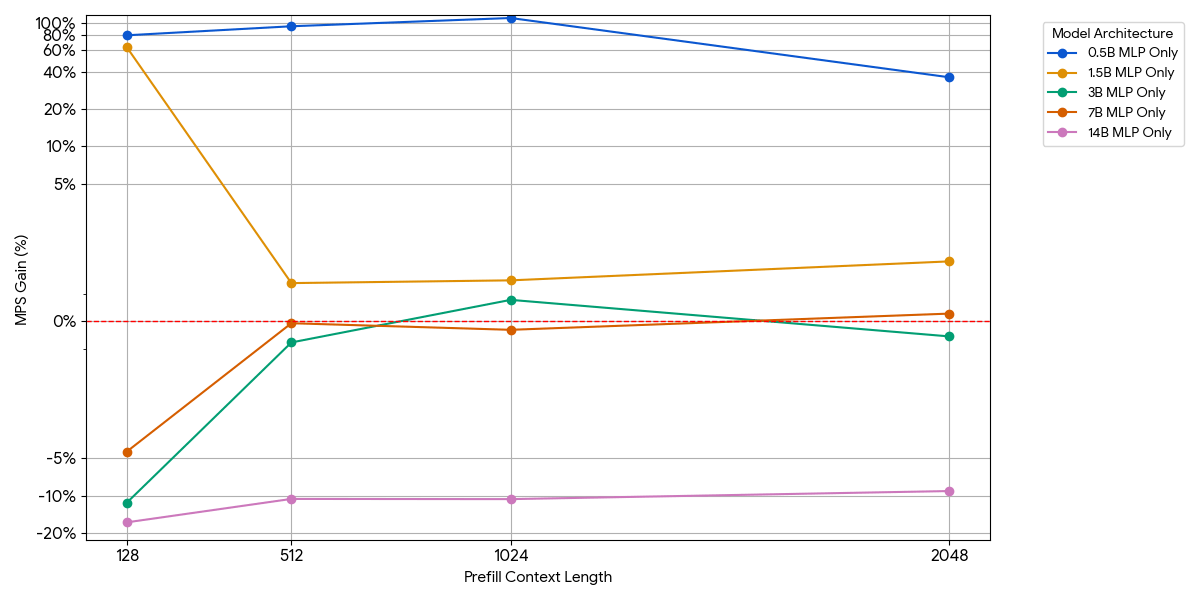{kind=link}
As shown in the above figure, the gains are modest and vanish quickly. As model size or context length increases, a single engine already saturates the compute (more FLOPs per token in larger MLPs, more tokens with longer sequences). Once an engine is compute-bound, running two saturated engines gives almost no benefit — 1 + 1 <= 1.
Attention-only models (MLP removed)
After seeing limited gains from the MLP, we took Qwen2.5-3B and measured the attention-only setup analogously.
Attention vs MLP for decode heavy workload(Qwen2.5-3B) Attention vs MLP for Prefill heavy workload(Qwen2.5-3B)
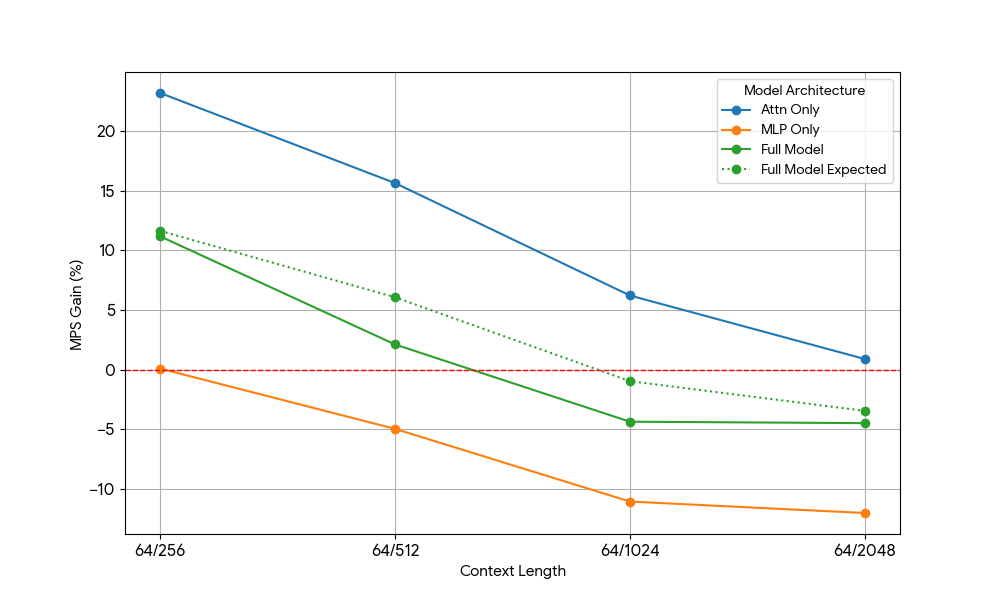{kind=link}
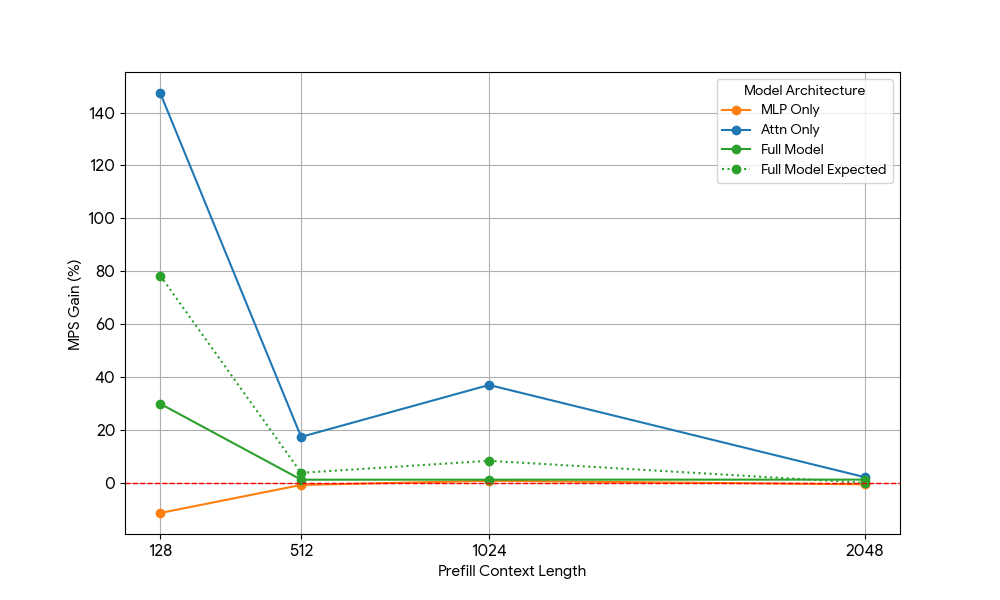{kind=link}
The results was striking:
- Attention-only workloads show significantly larger MPS gains than the full model for both prefill and decode.
- For decode, the gains are diminishing linearly with context length, which aligns with our expectation in the decode stage the resource requirements for attention grow with context length.
- For prefill, the gains dropped more rapidly than decode.
Does the MPS gain come purely from attention gains, or is there some Attention MLP overlapping effect? To study this, we calculated Full Model Expected Gain to be a weighted average of Attention Only and MLP only, with the weights being their contribution to the wall time. This Full Model Expected Gain is basically gains purely from Attn-Attn and MLP-MLP overlaps, while it does not account for Attn-MLP overlap.
For decode workload, the Full Model Expected Gain is slightly higher than the actual gain, which indicates limited impact of Attn-MLP overlap. Furthermore, for prefill workload, the real Full Model Gain is much lower than the expected gains from seq 128, hypothetical explanation could be that there’s less opportunities for the unsaturated Attention kernel being overlapped because the other engine is spending significant fraction of time doing saturated MLP. Therefore, the majority of the MPS gain comes from 2 engines with attention being unsaturated.
Bonus Benefit: Recovering GPU Time Lost to CPU Overhead
The ablations above focused on GPU-bound workloads, but the most severe form of underutilization happens when the GPU sits idle waiting for CPU work — such as scheduler, tokenization, or image preprocessing in multimodal models.
In a single-engine setup, these CPU stalls directly waste GPU cycles. With MPS, a second engine can take over the GPU whenever the first is blocked on the CPU, turning dead time into productive compute.
To isolate this effect, we deliberately chose a regime where the earlier GPU-level gains had vanished: Gemma-4B (a size and context length where attention and MLP are already well-saturated, so kernel-overlap benefits are minimal).
MPS Gain for Gemma-4B on vLLM + Async Scheduling Enabled
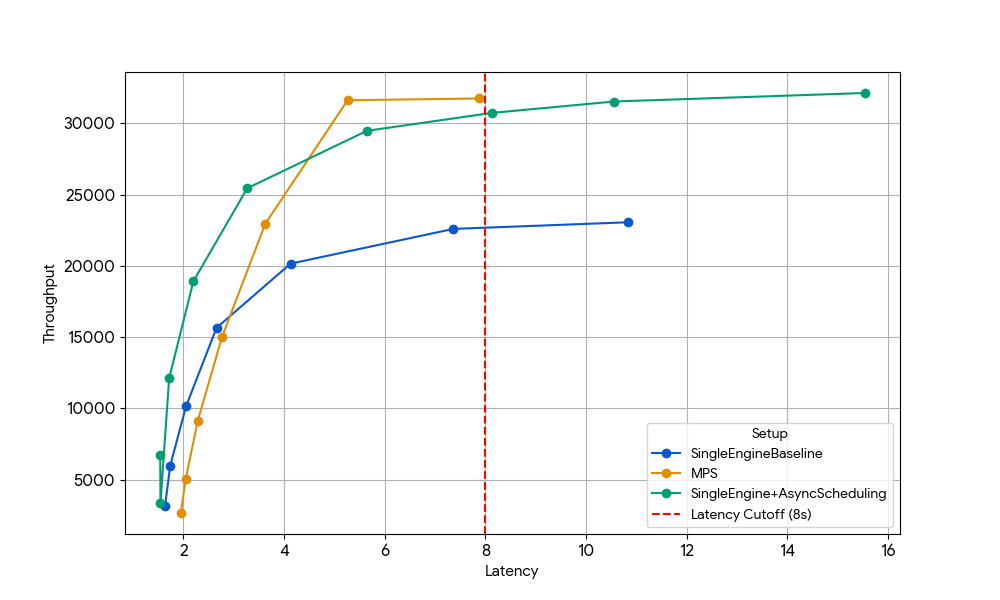{kind=link}
At a latency of 8s, the baseline single engine (blue) is limited by the scheduler CPU overhead, which can be lifted by either enabling asynchronous scheduling in vLLM (green line, +33% throughput), or running two engines with MPS without asynchronous scheduling (yellow line, +35% throughput). This near-identical gain confirms that, in CPU-constrained scenarios, MPS can reclaim essentially the same idle GPU time that async scheduling eliminates. MPS can be useful since vanilla vLLM v1.0 still has CPU overhead in the scheduler layer where optimizations like asynchronous scheduling are not fully available.
A Bullet, Not a Silver Bullet
Based on our experiments, MPS can yield significant gains for small model inference in a few operating zones:
- Engines with significant CPU overhead
- Very small language models (≤3B parameters) with short-to-medium context (<2k tokens)
- Very small language models (<3B) in prefill-heavy workloads
Outside of those sweet spots (e.g., 7B+ models, long-context >8k, or already compute-bound workloads), the GPU-level benefits cannot be captured by MPS easily.
On the other hand, MPS also introduced operational complexity:
- Extra moving parts: MPS daemon, client environment setup, and a router/load-balancer to split traffic across engines
- Increased debugging complexity: no isolation between engines → a memory leak or OOM in one engine can corrupt or kill all others sharing the GPU
- Monitoring burden: we now have to watch daemon health, client connection state, inter-engine load balance, etc.
- Fragile failure modes: because all engines share a single CUDA context and MPS daemon, a single misbehaving client can corrupt or starve the entire GPU, instantly affecting every co-located engine.
In short: MPS is a sharp, specialized tool — extremely effective in the narrow regimes described above, but rarely a general-purpose win. We really enjoyed pushing the limits of GPU sharing and figuring out where the real performance cliffs are. There’s still a huge amount of untapped performance and cost-efficiency across the entire inference stack. If you’re excited about distributed serving systems, or making LLMs run 10× cheaper in production, we’re hiring!
Authors: Xiaotong Jiang