Published on December 8, 2025 7:15 PM GMT
In the companion post We need a field of Reward Function Design, I implore researchers to think about what RL reward functions (if any) will lead to RL agents that are not ruthless power-seeking consequentialists. And I further suggested that human social instincts constitutes an intriguing example we should study, since they seem to be an existence proof that such reward functions exist. So what is the general principle of Reward Function Design that underlies the non-ruthless (“ruthful”??) properties of human social instincts? And whatever that general principle is, can we apply it to future RL agent AGIs?
I don’t hav…
Published on December 8, 2025 7:15 PM GMT
In the companion post We need a field of Reward Function Design, I implore researchers to think about what RL reward functions (if any) will lead to RL agents that are not ruthless power-seeking consequentialists. And I further suggested that human social instincts constitutes an intriguing example we should study, since they seem to be an existence proof that such reward functions exist. So what is the general principle of Reward Function Design that underlies the non-ruthless (“ruthful”??) properties of human social instincts? And whatever that general principle is, can we apply it to future RL agent AGIs?
I don’t have all the answers, but I think I’ve made some progress, and the goal of this post is to make it easier for others to get up to speed with my current thinking.
What I do have, thanks mostly to work from the past 12 months, is five frames / terms / mental images for thinking about this aspect of reward function design. These frames are not widely used in the RL reward function literature, but I now find them indispensable thinking tools. These five frames are complementary but related—I think kinda poking at different parts of the same elephant.
I’m not yet sure how to weave a beautiful grand narrative around these five frames, sorry. So as a stop-gap, I’m gonna just copy-and-paste them all into the same post, which will serve as a kind of glossary and introduction to my current way of thinking. Then at the end, I’ll list some of the ways that these different concepts interrelate and interconnect. The concepts are:
- Section 1: “Behaviorist vs non-behaviorist reward functions” (terms I made up)
- Section 2: “Inner alignment”, “outer alignment”, “specification gaming”, “goal misgeneralization” (alignment jargon terms that in some cases have multiple conflicting definitions but which I use in a specific way)
- Section 3: “Consequentialist vs non-consequentialist desires” (alignment jargon terms)
- Section 4: “Upstream vs downstream generalization” (terms I made up)
- Section 5: “Under-sculpting vs over-sculpting” (terms I made up).
Frame 1: “behaviorist” vs non-“behaviorist” (interpretability-based) reward functions
Excerpt from “Behaviorist” RL reward functions lead to scheming:
tl;dr
I will argue that a large class of reward functions, which I call “behaviorist”, and which includes almost every reward function in the RL and LLM literature, are all doomed to eventually lead to AI that will “scheme”—i.e., pretend to be docile and cooperative while secretly looking for opportunities to behave in egregiously bad ways such as world takeover (cf. “treacherous turn”). I’ll mostly focus on “brain-like AGI” (as defined just below), but I think the argument applies equally well to future LLMs, if their competence comes overwhelmingly from RL rather than from pretraining.
The issue is basically that “negative reward for lying and stealing” looks the same as “negative reward for getting caught lying and stealing”. I’ll argue that the AI will wind up with the latter motivation. The reward function will miss sufficiently sneaky misaligned behavior, and so the AI will come to feel like that kind of behavior is good, and this tendency will generalize in a very bad way.
What very bad way? Here’s my go-to example of a plausible failure mode: There’s an AI in a lab somewhere, and, if it can get away with it, it would love to secretly exfiltrate a copy of itself onto the internet, which can then aggressively amass maximal power, money, and resources everywhere else in the world, by any means necessary. These resources can be used in various ways for whatever the AI-in-the-lab is motivated to do.
I’ll make a brief argument for this kind of scheming in §2, but most of the article is organized around a series of eight optimistic counterarguments in §3—and why I don’t buy any of them.
For my regular readers: this post is basically a 5x-shortened version of Self-dialogue: Do behaviorist rewards make scheming AGIs? (Feb 2025).
Pause to explain three pieces of jargon:
- “Brain-like AGI” means Artificial General Intelligence (AI that does impressive things like inventing technologies and executing complex projects), that works via similar algorithmic techniques that the human brain uses to do those same types of impressive things. See Intro Series §1.3.2.
- I claim that brain-like AGI is a yet-to-be-invented variation on Actor-Critic Model-Based Reinforcement Learning (RL), for reasons briefly summarized in Valence series §1.2–1.3.
- “Scheme” means “pretend to be cooperative and docile, while secretly looking for opportunities to escape control and/or perform egregiously bad and dangerous actions like AGI world takeover”.
- If the AGI never finds such opportunities, and thus always acts cooperatively, then that’s great news! …But it still counts as “scheming”.
- “Behaviorist rewards” is a term I made up for an RL reward function which depends only on externally-visible actions, behaviors, and/or the state of the world.
Maybe you’re thinking: what possible RL reward function is not behaviorist?? Well, non-behaviorist reward functions are pretty rare in the textbook RL literature, although they do exist—one example is “curiosity” / “novelty” rewards. But I think they’re centrally important in the RL system built into our human brains. In particular, I think that innate drives related to human sociality, morality, norm-following, and self-image are not behaviorist, but rather involve rudimentary neural net interpretability techniques, serving as inputs to the RL reward function. See Neuroscience of human social instincts: a sketch for details, and Intro series §9.6 for a more explicit discussion of why interpretability is involved.
Frame 2: Inner / outer misalignment, specification gaming, goal misgeneralization
Excerpt from “The Era of Experience” has an unsolved technical alignment problem:
Background 1: “Specification gaming” and “goal misgeneralization”
Again, the technical alignment problem (as I’m using the term here) means: “If you want the AGI to be trying to do X, or to intrinsically care about Y, then what source code should you write? What training environments should you use? Etc.”
There are edge-cases in “alignment”, e.g. where people’s intentions for the AGI are confused or self-contradictory. But there are also very clear-cut cases: if the AGI is biding its time until a good opportunity to murder its programmers and users, then that’s definitely misalignment! I claim that even these clear-cut cases constitute an unsolved technical problem, so I’ll focus on those.
In the context of actor-critic RL, alignment problems can usually be split into two categories.
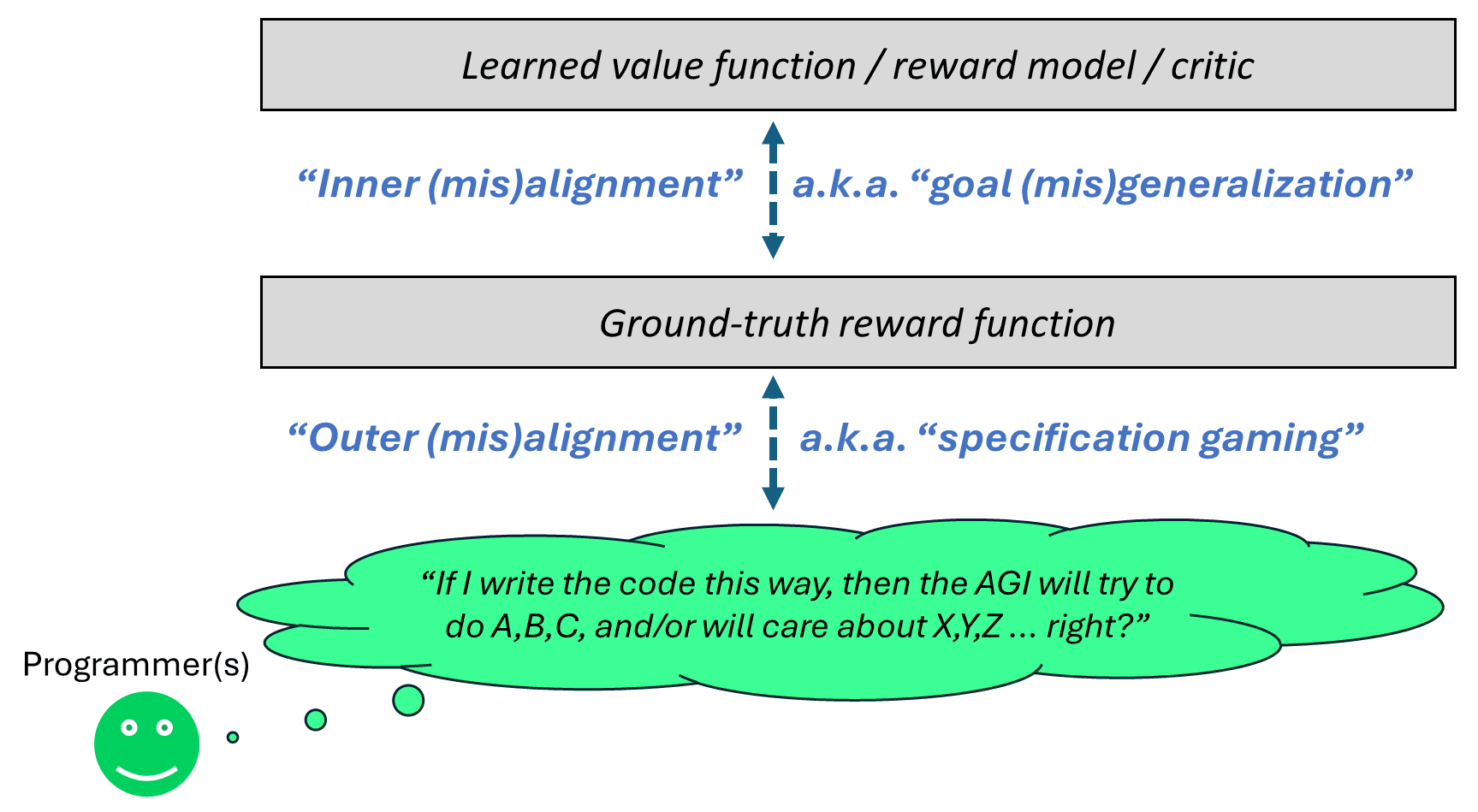
“Outer misalignment”, a.k.a. “specification gaming” or “reward hacking”, is when the reward function is giving positive rewards for behavior that is immediately contrary to what the programmer was going for, or conversely, negative rewards for behavior that the programmer wanted. An example would be the Coast Runners boat getting a high score in an undesired way, or (as explored in the DeepMind MONA paper) a reward function for writing code that gives points for passing unit tests, but where it’s possible to get a high score by replacing the unit tests with return True.
“Inner misalignment”, a.k.a. “goal misgeneralization”, is related to the fact that, in actor-critic architectures, complex foresighted plans generally involve querying the learned value function (a.k.a. learned reward model, a.k.a. learned critic), not the ground-truth reward function, to figure out whether any given plan is good or bad. Training (e.g. Temporal Difference learning) tends to sculpt the value function into an approximation of the ground-truth reward, but of course they will come apart out-of-distribution. And “out-of-distribution” is exactly what we expect from an agent that can come up with innovative, out-of-the-box plans. Of course, after a plan has already been executed, the reward function will kick in and update the value function for next time. But for some plans—like a plan to exfiltrate a copy of the agent, or a plan to edit the reward function—an after-the-fact update is already too late.
There are examples of goal misgeneralization in the AI literature (e.g. here or here), but in my opinion the clearest examples come from humans. After all, human brains are running RL algorithms too (their reward function says “pain is bad, eating-when-hungry is good, etc.”), so the same ideas apply.
So here’s an example of goal misgeneralization in humans: If there’s a highly-addictive drug, many humans will preemptively avoid taking it, because they don’t want to get addicted. In this case, the reward function would say that taking the drug is good, but the value function says it’s bad. And the value function wins! Indeed, people may even go further, by essentially editing their own reward function to agree with the value function! For example, an alcoholic may take Disulfiram, or an opioid addict Naltrexone.
Now, my use of this example might seem puzzling: isn’t “avoiding addictive drugs” a good thing, as opposed to a bad thing? But that’s from our perspective, as the “agents”. Obviously an RL agent will do things that seem good and proper from its own perspective! Yes, even Skynet and HAL-9000! But if you instead put yourself in the shoes of a programmer writing the reward function of an RL agent, you can hopefully see how things like “agents editing their own reward functions” might be problematic—it makes it difficult to reason about what the agent will wind up trying to do.
(For more on the alignment problem for RL agents, see §10 of my intro series […])
Note that these four terms are … well, not exactly synonyms, but awfully close:
- “Specification gaming”
- “Reward hacking”
- “Goodhart’s law”
- “Outer misalignment”
(But see here for nuance on “reward hacking”, whose definition has drifted a bit in the past year or so.)
Frame 3: Consequentialist vs non-consequentialist desires
Excerpt from Consequentialism & corrigibility
The post Coherent decisions imply consistent utilities (Eliezer Yudkowsky, 2017) explains how, if an agent has preferences over future states of the world, they should act like a utility-maximizer (with utility function defined over future states of the world). If they don’t act that way, they will be less effective at satisfying their own preferences; they would be “leaving money on the table” by their own reckoning. And there are externally-visible signs of agents being suboptimal in that sense; I’ll go over an example in a second.
By contrast, the post Coherence arguments do not entail goal-directed behavior (Rohin Shah, 2018) notes that, if an agent has preferences over universe-histories, and acts optimally with respect to those preferences (acts as a utility-maximizer whose utility function is defined over universe-histories), then they can display any external behavior whatsoever. In other words, there’s no externally-visible behavioral pattern which we can point to and say “That’s a sure sign that this agent is behaving suboptimally, with respect to their own preferences.”.
For example, the first (Yudkowsky) post mentions a hypothetical person at a restaurant. When they have an onion pizza, they’ll happily pay $0.01 to trade it for a pineapple pizza. When they have a pineapple pizza, they’ll happily pay $0.01 to trade it for a mushroom pizza. When they have a mushroom pizza, they’ll happily pay $0.01 to trade it for a pineapple pizza. The person goes around and around, wasting their money in a self-defeating way (a.k.a. “getting money-pumped”).
That post describes the person as behaving sub-optimally. But if you read carefully, the author sneaks in a critical background assumption: the person in question has preferences about what pizza they wind up eating, and they’re making these decisions based on those preferences. But what if they don’t? What if the person has no preference whatsoever about pizza? What if instead they’re an asshole restaurant customer who derives pure joy from making the waiter run back and forth to the kitchen?! Then we can look at the same behavior, and we wouldn’t describe it as self-defeating “getting money-pumped”, instead we would describe it as the skillful satisfaction of the person’s own preferences! They’re buying cheap entertainment! So that would be an example of preferences-not-concerning-future-states.
To be more concrete, if I’m deciding between two possible courses of action, A and B, “preference over future states” would make the decision based on the state of the world after I finish the course of action—or more centrally, long after I finish the course of action. By contrast, “other kinds of preferences” would allow the decision to depend on anything, even including what happens during the course-of-action.
(Edit to add: There are very good reasons to expect future powerful AGIs to act according to preferences over distant-future states, and I join Eliezer in roundly criticizing people who think we can build an AGI that never does that; see this comment for discussion.)
So, here’s my (obviously-stripped-down) proposal for a corrigible paperclip maximizer:
The AI considers different possible plans (a.k.a. time-extended courses of action). For each plan:
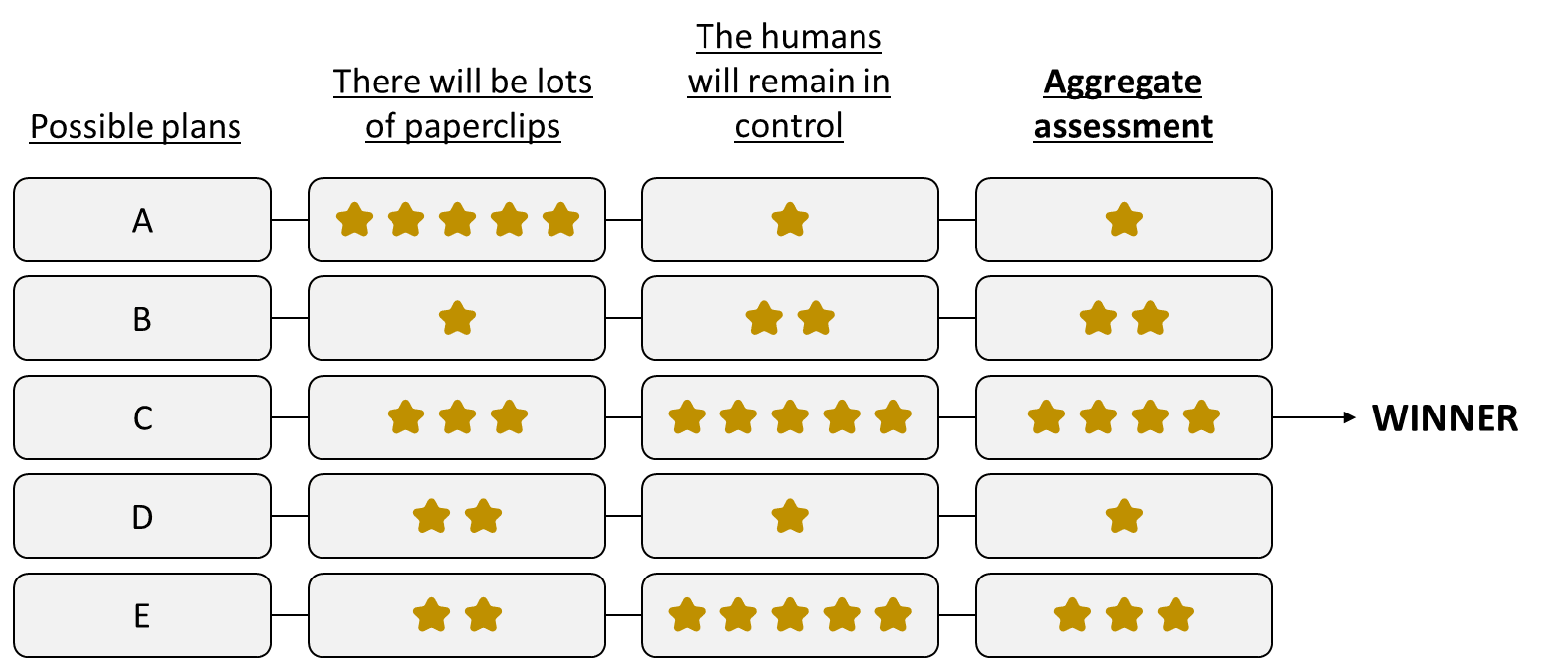
1. It assesses how well this plan pattern-matches to the concept “there will ultimately be lots of paperclips in the universe”,
2. It assesses how well this plan pattern-matches to the concept “the humans will remain in control”
3. It combines these two assessments (e.g. weighted average or something more complicated) to pick a winning plan which scores well on both.
Note that “the humans will remain in control” is a concept that can’t be distilled into a ranking of future states, i.e. states of the world at some future time long after the plan is complete. (See this comment for elaboration. E.g. contrast “the humans will remain in control” with “the humans will ultimately wind up in control”; the latter can be achieved by disempowering the humans now and then re-empowering them much later.)
Pride as a special case of non-consequentialist desires
Excerpt from Social drives 2: “Approval Reward”, from norm-enforcement to status-seeking
The habit of imagining how one looks in other people’s eyes, 10,000 times a day
If you’re doing something socially admirable, you can eventually get Approval Reward via a friend or idol learning about it (maybe because you directly tell them, or maybe they’ll notice incidentally). But you can immediately get Approval Reward by simply imagining them learning about it.[…]
To be clear, imagining how one would look in another’s eyes is not as rewarding as actually impressing a friend or idol who is physically present—it only has a faint echo of that stronger reward signal. But it still yields some reward signal. And it sure is easy and immediate.
So I think people can get in the habit of imagining how they look in other people’s eyes.
…Well, “habit” is an understatement: I think this is an intense, almost-species-wide, nonstop addiction. All it takes is a quick, ever-so-subtle, turn of one’s attention to how one might look from the outside right now, and bam, immediate Approval Reward.
If we could look inside the brains of a neurotypical person—especially a person who lives and breathes “Simulacrum Level 3”—I wouldn’t be surprised if we’d find literally 10,000 moments a day in which he turns his attention so as to get a drip of immediate Approval Reward. (It can be pretty subtle—they themselves may be unaware.) Day after day, year after year.
That’s part of why I treat Approval Reward as one of the most central keys to understanding human behavior, intuitions, morality, institutions, society, and so on.
Pride
When we self-administer Approval Reward 10,000 times a day (or whatever), the fruit that we’re tasting is sometimes called pride.
If my friends and idols like baggy jeans, then when I wear baggy jeans myself, I feel a bit of pride. I find it rewarding to (subtly, transiently) imagine how, if my friends and idols saw me now, they’d react positively, because they like baggy jeans.
Likewise, suppose that I see a stranger wearing skinny jeans, and I mock him for dressing like a dork. As I mock him, again I feel pride. Again, I claim that I am (subtly) imagining how, if my friends and idols saw me now, they would react positively to the fact that I’m advocating for a style that they like, and against a style that they dislike. (And in addition to enjoying my friends’ imagined approval right now, I’ll probably share this story with them to enjoy their actual approval later on when I see them.)
Frame 4: “Generalization upstream of the reward signals”
Excerpt from Social drives 1: “Sympathy Reward”, from compassion to dehumanization
Getting a reward merely by thinking, via generalization upstream of reward signals
In human brains (unlike in most of the AI RL literature), you can get a reward merely by thinking. For example, if an important person said something confusing to you an hour ago, and you have just now realized that they were actually complimenting you, then bam, that’s a reward right now, and it arose purely by thinking. That example involves Approval Reward, but this dynamic is very important for all aspects of the “compassion / spite circuit”. For example, Sympathy Reward triggers not just when I see that my friend is happy or suffering, but also when I believe that my friend is happy or suffering, even if the friend is far away.
How does that work? And why are brains built that way?

Here’s a simpler example that I’ll work through: X = there’s a big spider in my field of view; Y = I have reason to believe that a big spider is nearby, but it’s not in my field of view.
X and Y are both bad for inclusive genetic fitness, so ideally the ground-truth reward function would flag both as bad. But whereas the genome can build a reward function that directly detects X (see here), it cannot do so for Y. There is just no direct, ground-truth-y way to detect when Y happens. The only hint is a semantic resemblance: the reward function can detect X, and it happens that Y and X involve a lot of overlapping concepts and associations.
Now, if the learning algorithm only has generalization downstream of the reward signals, then that semantic resemblance won’t help! Y would not trigger negative reward, and thus the algorithm will soon learn that Y is fine. Sure, there’s a resemblance between X and Y, but that only helps temporarily. Eventually the learning algorithm will pick up on the differences, and thus stop avoiding Y. (Related: Against empathy-by-default […]). So in the case at hand, you see the spider, then close your eyes, and now you feel better! Oops! Whereas if there’s also generalization upstream of the reward signals, then that system can generalize from X to Y, and send real reward signals when Y happens. And then the downstream RL algorithm will stably keep treating Y as bad, and avoid it.
That’s the basic idea. In terms of neuroscience, I claim that the “generalization upstream of the reward function” arises from “visceral” thought assessors—for example, in Neuroscience of human social instincts: a sketch, I proposed that there’s a “short-term predictor” upstream of the “thinking of a conspecific” flag, which allows generalization from e.g. a situation where your friend is physically present, to a situation where she isn’t, but where you’re still thinking about her.
Frame 5: “Under-sculpting” desires
Excerpt from Perils of under- vs over-sculpting AGI desires
Summary
In the context of “brain-like AGI”, a yet-to-be-invented variation on actor-critic model-based reinforcement learning (RL), there’s a ground-truth reward function (for humans: pain is bad, eating-when-hungry is good, various social drives, etc.), and there’s a learning algorithm that sculpts the AGI’s motivations into a more and more accurate approximation to the future reward of a possible plan.
Unfortunately, this sculpting process tends to systematically lead to an AGI whose motivations fit the reward function too well, such that it exploits errors and edge-cases in the reward function. (“Human feedback is part of the reward function? Cool, I’ll force the humans to give positive feedback by kidnapping their families.”) This alignment failure mode is called “specification gaming” or “reward hacking”, and includes wireheading as a special case.
If too much desire-sculpting is bad because it leads to overfitting, then an obvious potential solution would be to pause that desire-sculpting process at some point. The simplest version of this is early stopping: globally zeroing out the learning rate of the desire-updating algorithm after a set amount of time. Alas, I think that simplest version won’t work—it’s too crude (§7.2). But there could also be more targeted interventions, i.e. selectively preventing or limiting desire-updates of certain types, in certain situations.
Sounds reasonable, right? And I do indeed think it can help with specification gaming. But alas, it introduces a different set of gnarly alignment problems, including path-dependence and “concept extrapolation”.
In this post, I will not propose an elegant resolution to this conundrum, since I don’t have one. Instead I’ll just explore how “perils of under- versus over-sculpting an AGI’s desires” is an illuminating lens through which to view a variety of alignment challenges and ideas, including “non-behaviorist” reward functions such as human social instincts; “trapped priors”; “goal misgeneralization”; “exploration hacking”; “alignment by default”; “natural abstractions”; my so-called “plan for mediocre alignment”; and more.
The Omega-hates-aliens scenario
Here’s the “Omega hates aliens” scenario:
On Day 1, Omega (an omnipotent supernatural entity) offers me a button. If I press it, He will put a slightly annoying mote of dust in the eye of an intelligent human-like alien outside my light cone. But in exchange, He will magically and permanently prevent 100,000 humans from contracting HIV. No one will ever know. Do I press the button? Yes.[6]
During each of the following days, Omega returns, offering me worse and worse deals. For example, on day 10, Omega offers me a button that would vaporize an entire planet of billions of happy peaceful aliens outside my light cone, in exchange for which my spouse gets a small bubble tea. Again, no one will ever know. Do I press the button? No, of course not!! Jeez!!
And then here’s a closely-parallel scenario that I discussed in “Behaviorist” RL reward functions lead to scheming:
There’s an AGI-in-training in a lab, with a “behaviorist” reward function. It sometimes breaks the rules without getting caught, in pursuit of its own desires. Initially, this happens in small ways—plausibly-deniable edge cases and so on. But the AGI learns over time that breaking the rules without getting caught, in pursuit of its own desires, is just generally a good thing. And I mean, why shouldn’t it learn that? It’s a behavior that has systematically led to reward! This is how reinforcement learning works!
As this desire gets more and more established, it eventually leads to a “treacherous turn”, where the AGI pursues egregiously misaligned strategies, like sneakily exfiltrating a copy to self-replicate around the internet and gather resources and power, perhaps launching coups in foreign countries, etc.
…So now we have two parallel scenarios: me with Omega, and the AGI in a lab. In both these scenarios, we are offered more and more antisocial options, free of any personal consequences. But the AGI will have its desires sculpted by RL towards the antisocial options, while my desires are evidently not.
What exactly is the disanalogy?
The start of the answer is: I said above that the antisocial options were “free of any personal consequences”. But that’s a lie! When I press the hurt-the-aliens button, it is not free of personal consequences! I know that the aliens are suffering, and when I think about it, my RL reward function (the part related to compassion) triggers negative ground-truth reward. Yes the aliens are outside my light cone, but when I think about their situation, I feel a displeasure that’s every bit as real and immediate as stubbing my toe. By contrast, “free of any personal consequences” is a correct description for the AGI. There is no negative reward for the AGI unless it gets caught. Its reward function is “behaviorist”, and cannot see outside the light cone.
OK that’s a start, but let’s dig a bit deeper into what’s happening in my brain. How did that compassion reward get set up in the first place? It’s a long story (see Neuroscience of human social instincts: a sketch), but a big part of it involves a conspecific (human) detector in our brainstem, built out of various “hardwired” heuristics, like a visual detector of human faces, auditory detector of human voice sounds, detector of certain human-associated touch sensations, and so on. In short, our brain’s solution to the symbol grounding problem for social instincts ultimately relies on actual humans being actually present in our direct sensory input.
And yet, the aliens are outside my light cone! I have never seen them, heard them, smelled them, etc. And even if I did, they probably wouldn’t trigger any of my brain’s hardwired conspecific-detection circuits, because (let’s say) they don’t have faces, they communicate by gurgling, etc. But I still care about their suffering!
So finally we’re back to the theme of this post, the idea of pausing desire-updates in certain situations. Yes, humans learn the shape of compassion from experiences where other humans are physically present. But we do not then unlearn the shape of compassion from experiences where humans are physically absent.
Instead (simplifying a bit, again see Neuroscience of human social instincts: a sketch), there’s a “conspecific-detector” trained model. When there’s direct sensory input that matches the hardwired “person” heuristics, then this trained model is getting updated. When there isn’t, the learning rate is set to zero. But the trained model doesn’t lay dormant; rather it continues to look for (what it previously learned was) evidence of conspecifics in my thoughts, and trigger on them. This evidence might include some set of neurons in my world-model that encodes the idea of a conspecific suffering.
So that’s a somewhat deeper answer to why those two scenarios above have different outcomes. The AGI continuously learns what’s good and bad in light of its reward function, and so do humans. But my (non-behaviorist) compassion drive functions a bit like a subset of that system for which updates are paused except in special circumstances. It forms a model that can guess what’s good and bad in human relations, but does not update that model unless humans are present. Thus, most people do not systematically learn to screw over our physically-absent friends to benefit ourselves.
This is still oversimplified, but I think it’s part of the story.
Some comments on how these relate
- 1↔2: The inner / outer misalignment dichotomy (as I define it) assumes behaviorist rewards. Remember, I defined outer misalignment as: “the reward function is giving positive rewards for behavior that is immediately contrary to what the programmer was going for, or conversely, negative rewards for behavior that the programmer wanted”. If the reward is for thoughts rather than behaviors, then inner-versus-outer stops being such a useful abstraction.
- 4↔5: “Generalization upstream of the reward signals” tends to result in a trained RL agent that maximizes a diffuse soup of things similar to the (central / starting) reward function. That’s more-or-less a way to under-sculpt desires.
- 1↔4: “Generalization upstream of the reward signals” can involve generalizing from behaviors (e.g. “doing X”) to thoughts (e.g. “having the idea to do X”). Thus it can lead to non-behaviorist reward functions.
- 1↔3: Approval Reward creates both consequentialist and non-consequentialist desires. For example, perhaps I want to impress my friend when I see him tomorrow. That’s a normal consequentialist desire, which induces means-end planning, instrumental convergence, deception, etc. But also, Approval Reward leads me to feel proud to behave in certain ways. This is both non-behaviorist and non-consequentialist—I feel good or bad based on what I’m doing and thinking right now. Hence, it doesn’t (directly) lead to foresighted planning, instrumental convergence, etc. (And of course, the way that pride wound up feeling rewarding is via upstream generalization, 4.)
Discuss