Share
Introduction
You can order almost anything with Uber Eats. Whether you want to order an iced vanilla latte from your local cafe or order a new coffee machine to kickstart your own coffee-making journey, Uber Eats’ massive catalog of stores and items has got you covered.
From an engineering perspective, managing such a massive collection of items poses really interesting challenges. Outside the user-facing serving layer, you also need to support internal tools that allow operations teams and engineers to manage catalogs and items in real time and with low-latency. Users not only need text search functionality to look up specific items; they also want fast analytics to get broad insights quickly and seamlessly.
This blog shares how we adopted and scaled Apache Pinot™ to han…
Share
Introduction
You can order almost anything with Uber Eats. Whether you want to order an iced vanilla latte from your local cafe or order a new coffee machine to kickstart your own coffee-making journey, Uber Eats’ massive catalog of stores and items has got you covered.
From an engineering perspective, managing such a massive collection of items poses really interesting challenges. Outside the user-facing serving layer, you also need to support internal tools that allow operations teams and engineers to manage catalogs and items in real time and with low-latency. Users not only need text search functionality to look up specific items; they also want fast analytics to get broad insights quickly and seamlessly.
This blog shares how we adopted and scaled Apache Pinot™ to handle the massive volume of Uber’s catalog data to power multiple internal tools and workflows.
Overview
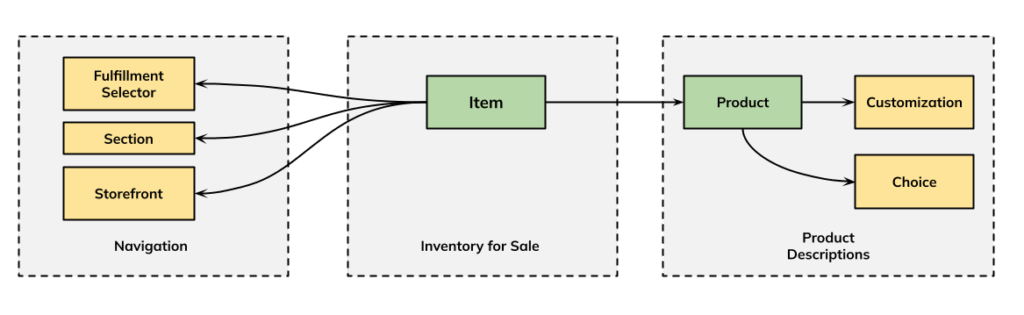 Figure 1: The different INCA entities and their relationships.
Figure 1: The different INCA entities and their relationships.
INCA (INventory and CAtalog) is Uber’s next-generation catalog system engineered to ingest, enrich, and publish massive, diverse inventories in real time. Our catalog is modeled around two core entities: Product and Item.
- Product (the what): The blueprint of what’s being sold. A Product describes general attributes such as name, brand, product type, image, identifiers, and size.
- Item (the how): Defines how a Product is offered in a specific store. An Item connects a Product to a storefront and includes attributes like price, availability, section placement, and fulfillment options. These details vary store by store.
A Catalog serves as the top-level container, grouping all of a merchant’s Products and Items under a unified set of rules and configurations. This hierarchical model is highly dynamic, which is where the real complexity emerges. These entities aren’t static—they are interconnected. A change to a single Product, like updating its name, can trigger a cascading update across thousands of associated Items that inherit its attributes. Similarly, a configuration change at the Catalog level—such as modifying its quality tier—can initiate reprocessing for every entity it contains. This ensures data consistency and quality at a massive scale, but it also necessitates an infrastructure capable of handling these widespread, high-volume changes in near-real-time.
The Need for an INCA Index
The primary source of truth for our catalog is a Docstore instance, which stores entity attributes as proto-encoded blobs. While reliable for persistence and fast point lookups, this isn’t designed for search, filtering, or aggregations. Historically, we also relied on Apache Hive™ for some of our analytics use cases, but Hive is optimized for batch processing. Queries can take minutes to hours to run, making it unsuitable for interactive catalog management.
To support real-time use cases, we needed a separate indexing stack that could:
- Keep data fresh within minutes instead of hours
- Support low-latency flexible filtering, searching, and aggregations
- Scale to billions of rows with hundreds of thousands of updates per second
We’d tried some other internal data offerings at Uber before trying Pinot, but they weren’t able to meet our business requirements. Fast forward to today, and indexes in Pinot now power multiple workflows across Uber, like:
- Catalog management tools (internal). Search and update product attributes, explore coverage (like GTIN, brand), and run aggregations for governance and quality.
- Merchant tools (external). Search for products by name or identifier, check item details, and update the inventory status of an item (for example, marking it out of stock).
- Operations tools. Preview the impact of catalog rules before applying them, slice counts by country or integration, and monitor attribute completeness.
- Quality workflows. Detects duplicates in product data, block linking errors, and monitor daily availability or barcode trends.
Without indexes, these tasks would require scanning proto blobs or waiting on Hive jobs, both of which introduce delays that hurt productivity and scalability. With Pinot, queries are interactive, and data is fresh within minutes.
Ingestion Architecture
We built several reusable components to construct a data pipeline that can ingest to Pinot. At the core of this ingestion pipeline is a service called inca-indexer, which reacts to changes in the catalog and emits the processed events to the respective Apache Kafka® topics, as defined by our business logic. We have one Kafka topic and Pinot table for each entity type (items, products, customizations).
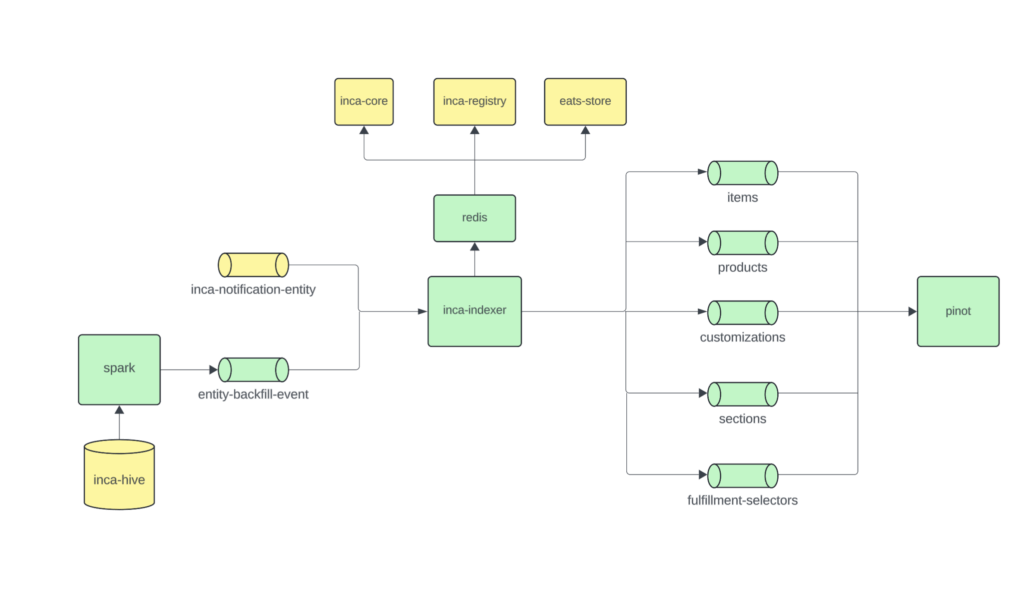 Figure 2: High-level data ingestion pipeline that sinks the data to multiple Kafka topics, each of which is ingested into corresponding Pinot tables.
Figure 2: High-level data ingestion pipeline that sinks the data to multiple Kafka topics, each of which is ingested into corresponding Pinot tables.
How it Works
Whenever a product or item changes in the source of truth, an event generates. The event is enriched with the latest attributes and simplified into a flat structure for easier indexing. Enriched events flow into Kafka, which handles partitioning and delivery at scale. Pinot ingests these events in real time, applying upserts so queries always return the freshest view.
To keep data fully in sync, we run scheduled backfills. These jobs reload the entire dataset every few days to pick up new fields or attributes and fill in any gaps left by dropped events or retention limits. Backfills are carefully rate-limited to protect upstream systems.
Benefits
This setup provides benefits like freshness, speed, and scale. Updates appear in Pinot within 5-10 minutes and queries typically return in 1-3 seconds, even when filtering or grouping across billions of rows. For scale, the system supports over 10 billion entities with room to grow.
Our design also promotes resilience, flexibility, and extensibility. Scheduled backfills keep data consistent and fill gaps, ensuring long-term reliability. And while Pinot is the main OLAP engine, the architecture allows plugging in other stores (like MySQL® or search engines) if a use case demands it. New attributes can be added to the index with minimal effort, making it easy to evolve alongside business needs.
This setup is also an improvement over Hive. Unlike Hive, which is batch-oriented and slow for interactive exploration, Pinot enables near-real-time, low-latency queries that make catalog tools practical and responsive.
Key Pinot Features and Performance Tuning
There are several key Pinot features that made this possible.
Realtime Upserts
One of our biggest tables for this use case has over 10 billion records and handles hundreds of thousands of updates per second. Most of our tables are upsert tables, where each new event logically overwrites the old event with the same primary key. We tried using some other Data Platform offerings internally, but none could handle this scale while meeting our ingestion latency requirement of less than 5 minutes.
Text Search Powered by Apache Lucene
We use Pinot’s TEXT_MATCH filter, powered by Apache Lucene®, to filter items and products based on user input in internal tools. This is perfect for powering search against product and brand names, and combines well with Pinot’s inverted indexes to support advanced search use cases.
Optimizing Search for Non-Latin Text
 Figure 3: Pinot Server CPU profile during high CPU events around Asia morning hours.
Figure 3: Pinot Server CPU profile during high CPU events around Asia morning hours.
After enabling search for an external-facing tool in 2024, we saw huge CPU and latency spikes right around when the Asian markets were expected to open.
A key component of text search is tokenization, and we generally use Lucene’s Standard Analyzer for most of our Pinot-based search use cases. But Lucene’s Standard Analyzer tokenizes much of non-Latin text at each character, which severely impacts queries that contain prefix and suffix wildcards. We confirmed this with a CPU profile of one of the Pinot servers.
To resolve this, we handle Latin and non-latin text separately at query time, generating an optimal search pattern for each scenario.
Inverted Indexes and Raw Columns
We have 90 columns in one of our largest tables, and nearly all of them have inverted indexes enabled. We also have some free-form columns like “Product Name” for which we don’t enable dictionary encoding. Since dictionary encoding is disabled for such columns, they also don’t have inverted indexes on them. Filtering on these columns is done using the text index.
Bloom Filter-Based Segment Pruning
We enabled bloom filters on item_id and catalog_id columns to power fast exact lookups for specific items and catalogs. This allows Pinot to exclude segments quickly for a query, reducing overall CPU requirements while improving individual query latency.
UUID Primary Key Bin Packing
We’d contributed the UUID hash function for upsert primary keys in 2024 to Apache Pinot, and we’ve been using it extensively for high-volume upsert use cases at Uber. Upsert primary keys are stored on-heap by default. If the primary key is a UUID, by default it’s stored as a string, which consumes 36 bytes for each unique key. With the UUID hash function, the UUID string representation is converted to a 16-byte representation, which reduces old gen usage by around 35%, allowing us to pack more keys in each server without risking hash collisions.
This is crucial for keeping hardware requirements low for INCA Indexes since each item and product has a UUID primary key, and overall we have more than 10 billion primary keys.
Java 17 GC Improvements
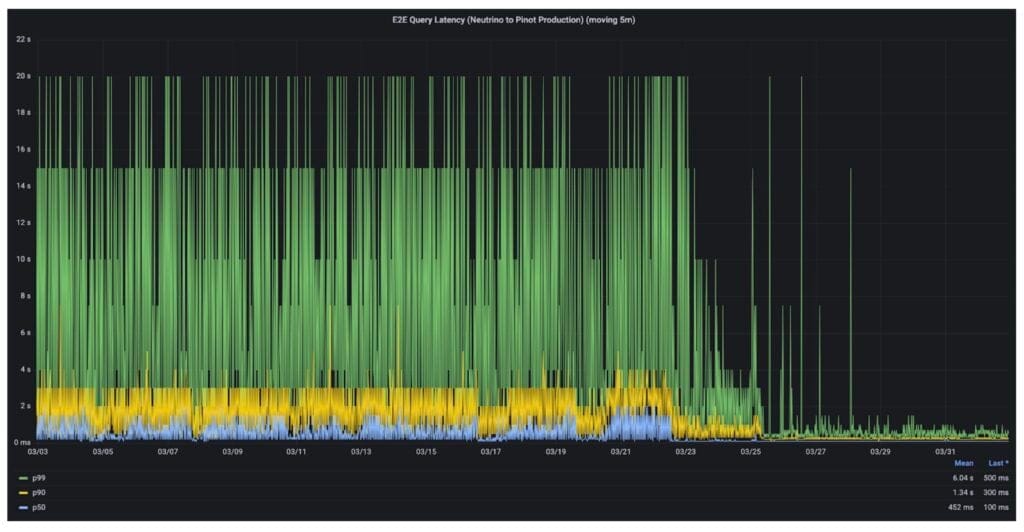 Figure 4: Latency reduction after upgrading from JRE-11 to JRE-17 (both setups used G1GC).
Figure 4: Latency reduction after upgrading from JRE-11 to JRE-17 (both setups used G1GC).
With older Java® versions, we saw garbage collection become a significant bottleneck for upsert use cases with a high number of primary keys. Since primary keys are stored on-heap in Pinot, the number of tenured live objects in the JVM is around the order of the number of active primary keys in a given Pinot server. At our scale, that can get in the range of hundreds of millions.
While UUID primary key compression helps with lowering old gen usage, it doesn’t help with garbage collection time. To address this, in early 2025, we upgraded the Java runtime from JRE-11 to JRE-17, and saw a nearly 10x improvement in peak latencies for each quantile (p50/p90/p99).
Upsert Compaction and Small Segment Merger
Until mid 2025, we only had upsert compaction. While compaction was quite helpful in reducing table size and providing good latencies, it led to many small segments. Because of this, we had to keep the retention of the table to around 10 days and had to re-ingest the universe every few days to ensure that the un-updated records weren’t deleted. This re-ingest backfill used to take more than a day to complete, during which it’d also put a lot of pressure on our source of truth Docstore instance as well as Pinot, since the ingestion traffic from the backfill alone would exceed 100,000 messages per second.
To remediate this, we built and contributed the SSM (Small Segment Merger), minion task to Apache Pinot. This is now enabled for nearly all INCA tables. The SSM minion task performs compaction (removing invalidated records) and merge (coalescing small segments to bigger segments), essentially eliminating the small segment problem. Importantly, customers now get record-level semantics, and they can set extremely high retention for their real-time upsert tables. The SSM minion task can also combine with Pinot’s upsert delete feature to enable infinite retention use cases.
On the performance front, the results with SSM have been quite impressive when compared with the older compaction-only minion task. The segment count was reduced by up to 70% (74,000 to 22,000). Table size has been reduced by 40% (42TB to 24TB). p99 query latency improved by 75% (1150ms to 269ms) and p50 query latency improved by 55% (45ms to 20ms).
As of writing, we’re working on phasing out the backfill jobs altogether.
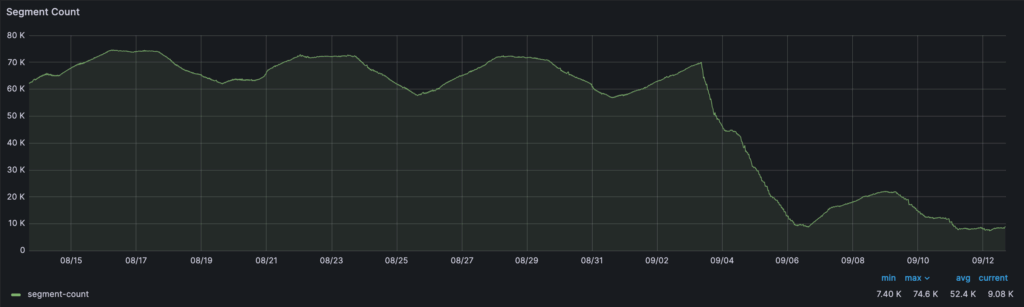 Figure 5: ~70% reduction in segment count, from 74,000 down to 22,000.
Figure 5: ~70% reduction in segment count, from 74,000 down to 22,000.
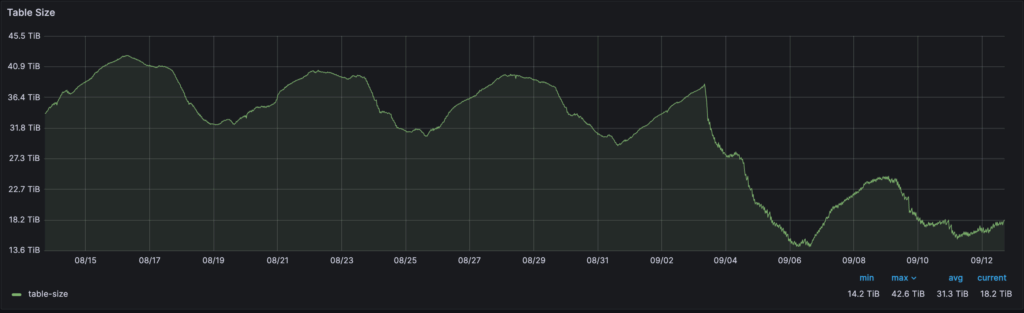 Figure 6: 40% reduction in table size (peak table size reduced from 42TB to 24TB).
Figure 6: 40% reduction in table size (peak table size reduced from 42TB to 24TB).
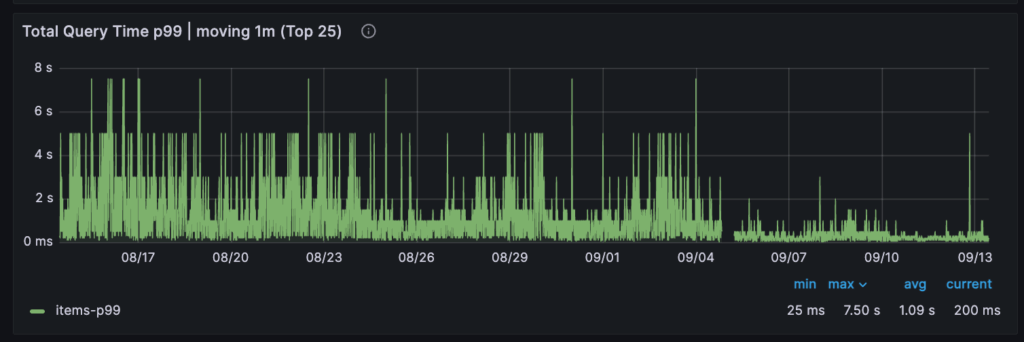 Figure 7: 75% reduction in p99 query latency (1150ms to 269ms).
Figure 7: 75% reduction in p99 query latency (1150ms to 269ms).
Next Steps
We’re working on some core Pinot optimizations like short-circuiting for “AND” index-based filters, commit time compaction, and general improvements like upgrading to Java 21 to further improve performance. We’re also working on improving Pinot’s resiliency to cluster restarts and rollouts.
Conclusion
Our INCA index based on Apache Pinot has seen continuous improvements throughout 2025: from significant latency improvements through modernization efforts like Java 17 adoption, to the multiple improvements we saw from adopting the small segment merger minion task. It’s been great to see Pinot improvements directly lead to product and user experience improvements, and we’re hoping to see this trend continue.
Apache®, Apache Pinot™, Apache Lucene®, Apache Kafka®, Pinot™, and Apache Hive™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Java, MySQL, and NetSuite are registered trademarks of Oracle® and/or its affiliates.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.