Traditional data warehouses are slow, expensive, and locked behind proprietary systems. They demand constant tuning and create friction for analytics teams that need speed and scale, and slow down decisions across finance, operations, and product teams. Databricks SQL (DBSQL) removes these limits. It is 5x faster on average, runs serverless, and follows open standards. This default performance intelligence is not locked behind premium tiers.
**Over 60% of the Fortune 500 use DBSQL **for analytics and BI on the Databricks Data Intelligence Platform.
In 2025, DBSQL continued to deliver functionality that improved performance, AI, cost management, and open SQL capabilities. This roundup highlights the updates that made the biggest impact for data teams this year.
Performance t…
Traditional data warehouses are slow, expensive, and locked behind proprietary systems. They demand constant tuning and create friction for analytics teams that need speed and scale, and slow down decisions across finance, operations, and product teams. Databricks SQL (DBSQL) removes these limits. It is 5x faster on average, runs serverless, and follows open standards. This default performance intelligence is not locked behind premium tiers.
**Over 60% of the Fortune 500 use DBSQL **for analytics and BI on the Databricks Data Intelligence Platform.
In 2025, DBSQL continued to deliver functionality that improved performance, AI, cost management, and open SQL capabilities. This roundup highlights the updates that made the biggest impact for data teams this year.
Performance that improves automatically
Faster queries without tuning
Since 2022, DBSQL Serverless has delivered an average 5x performance improvement. Dashboards that once took 10 seconds now load in about 2 seconds, without requiring index management or manual tuning.
In 2025, performance improved again:
- Up to 25 percent faster queries on top of the existing 5x gains
- Delivered automatically, no configuration required
- No need to manage indexes or parameters
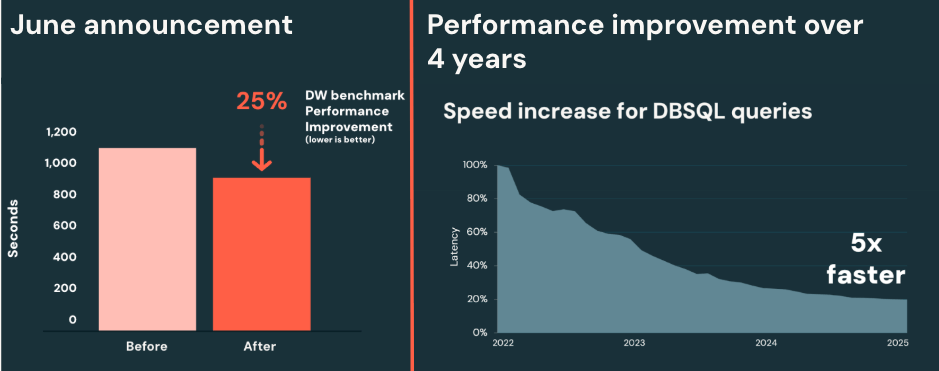
Because Databricks is built on the Data Intelligence Platform, this intelligence is available to every customer by default, not locked behind premium tiers or the highest-priced offerings.
Better visibility with Query Profile
To help teams understand performance patterns, the updated Query Profile view now includes:
- A visual summary of read and write metrics
- A “Top operators” panel to identify expensive parts of a query
- Clearer navigation through the execution graph
- Filters to focus on specific metrics
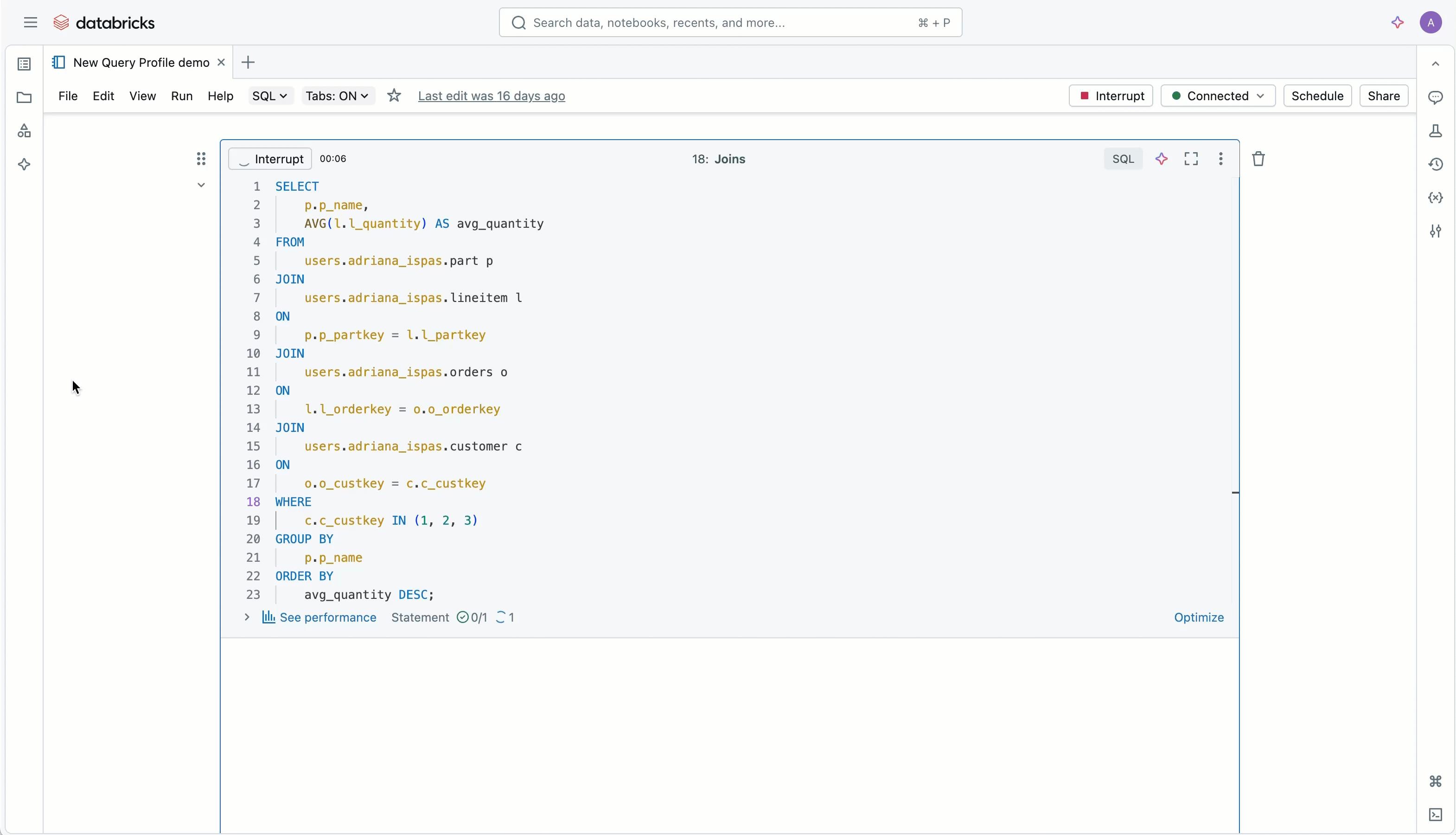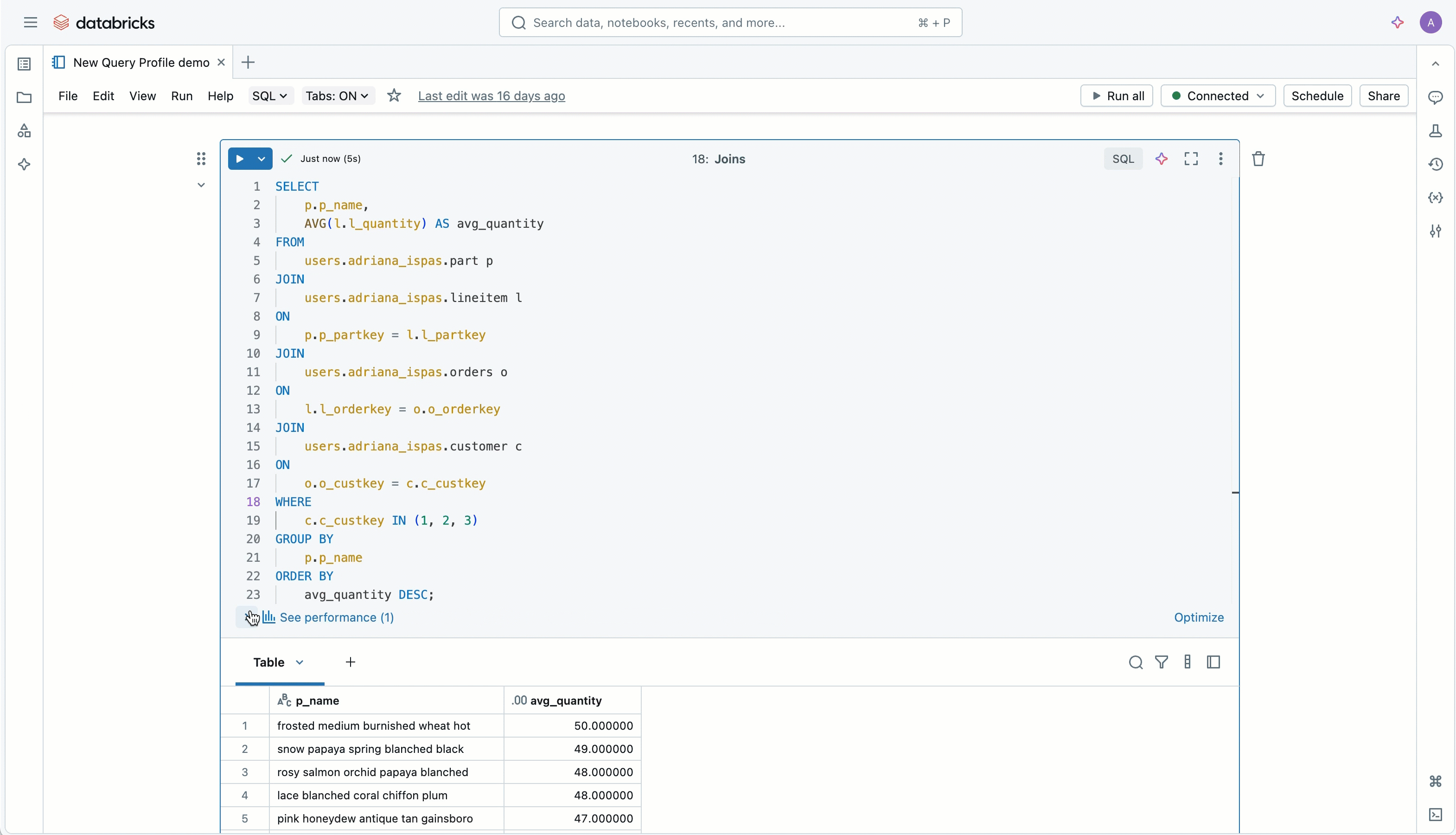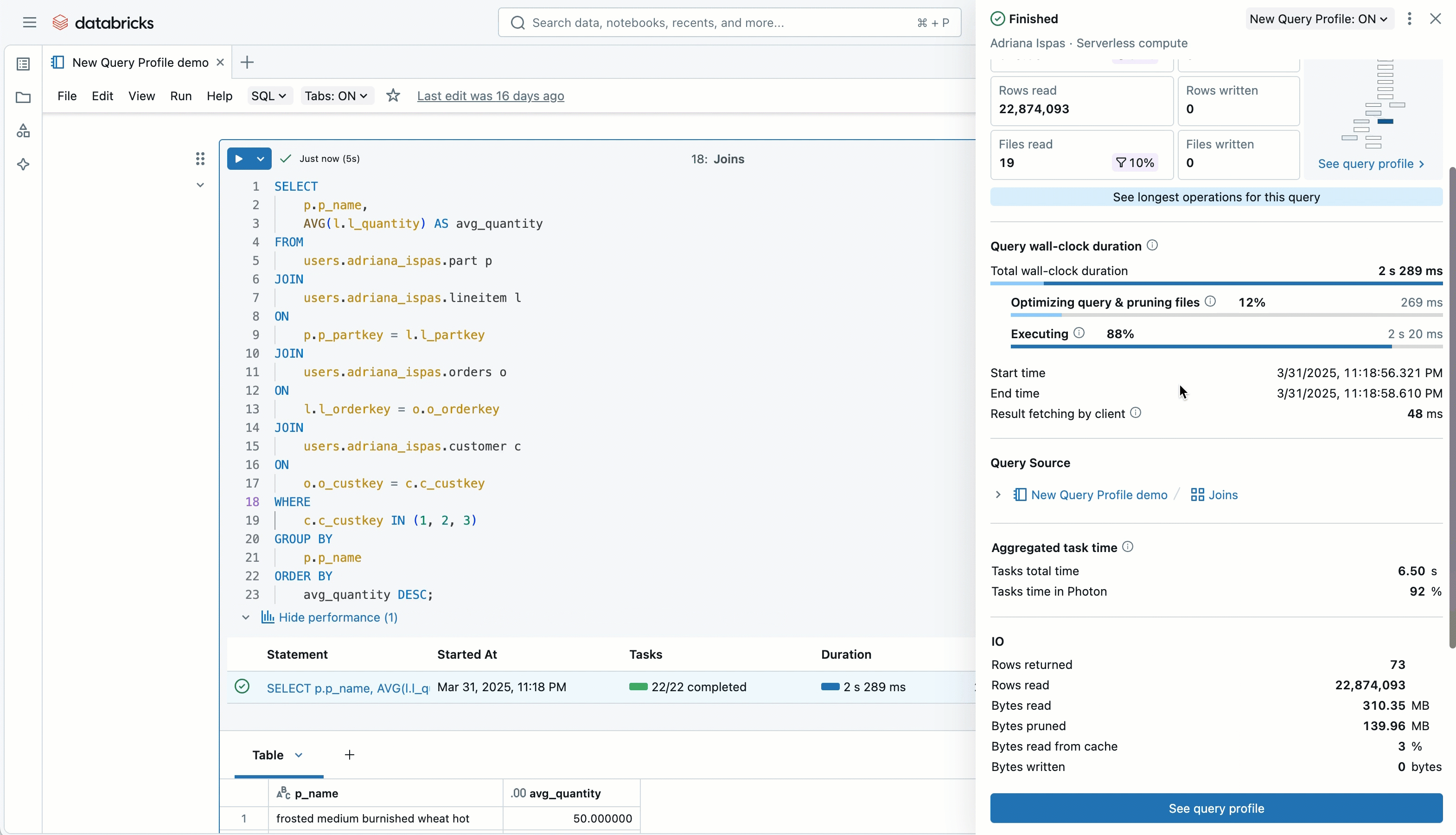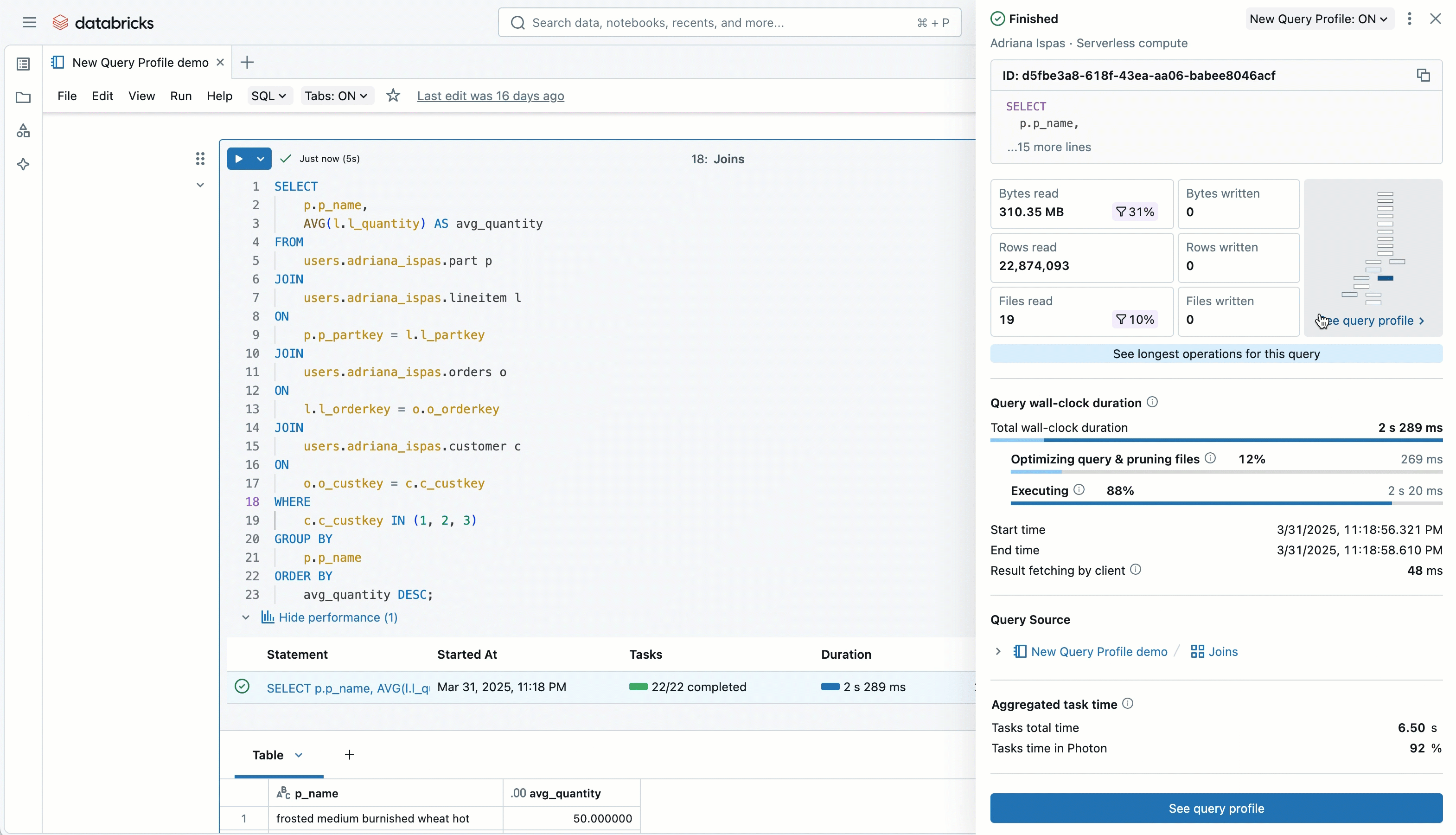
This helps teams diagnose slow dashboards and complex models more quickly, without relying on guesswork.
AI built directly into SQL workflows
AI is now part of everyday analytics. In 2025, DBSQL introduced native AI functions so analysts can use large language models directly in SQL. A few new capabilities include:
- i_query for summarization, classification, extraction, and sentiment analysis
- ai_parse_document, currently in beta, converts PDFs and other unstructured documents into tables
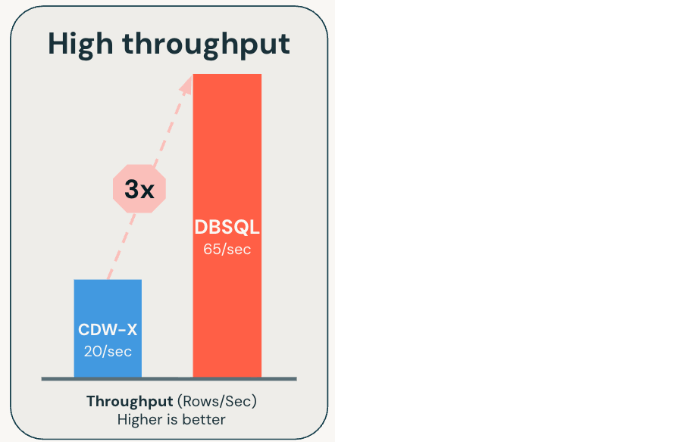
These functions run on Databricks-hosted models, such as Meta Llama and OpenAI GPT OSS, or on custom models you provide. They are optimized for scale and up to 3x faster than alternative approaches.
Teams can now summarize support tickets, extract fields from contracts, or analyze customer feedback directly inside reporting queries. Analysts stay in SQL. Workflows move faster. No more tool switching or coding in Python.
Automated performance management with Predictive Optimization
As data grows and workloads change, performance often degrades over time. Predictive Optimization addresses this problem directly.
In 2025, Automatic Statistics Management became generally available. It removes the need to run ANALYZE commands or manage optimization jobs manually.
Now, Predictive Optimizations automatically:
- Collects optimization statistics after data loads
- Selects data skipping indexes
- Continuously improves execution plans over time
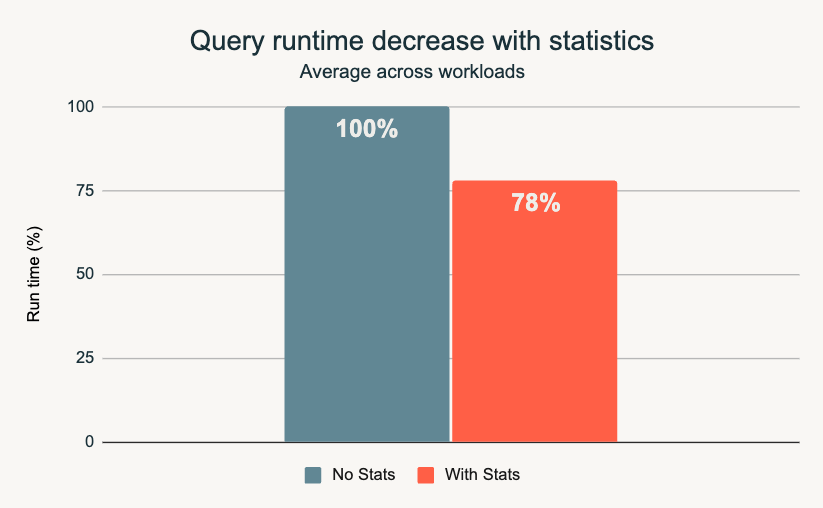
This reduces operational overhead and prevents the gradual performance drift many warehouses struggle with.
Open SQL features that simplify migrations
For many customers, stored procedures, transactions, and proprietary SQL constructs are the hardest part of leaving legacy warehouses. But, many companies want to migrate from legacy systems like Oracle, Teradata, and SQL Server for TCO and innovation reasons. DBSQL continued its investment in open, ANSI-compliant SQL features to reduce migration effort and increase portability.
New capabilities include:
- Stored Procedures (Public Preview) with Unity Catalog governance
- SQL Scripting (Public Preview) for loops and conditionals in SQL
- Recursive CTEs (Public Preview) for hierarchical queries
- Collations (Public Preview) for language-aware sorting and comparison
- Temporary Tables (Public Preview) for removing the burden of managing intermediate tables or tracking down residual data
These features follow open SQL standards and are available in Apache Spark. They make migrations easier and reduce dependency on proprietary constructs.
DBSQL also added Spatial SQL with geometry and geography types. Over 80 functions like ST_Distance and ST_Contains support large-scale geospatial analysis directly in SQL.
Cost management for large-scale workloads
As SQL adoption grows, teams struggle to explain rising spend across warehouses, dashboards, and tools. DBSQL introduced new tools that help teams monitor and control spend at the warehouse, dashboard, and user level.
Key updates include:
- Account Usage Dashboard to identify rising costs
- Tags and Budgets to track spend by team
- System Tables for detailed query level analysis
- Granular Cost Monitoring Dashboard** and Materialized Views** (Private Preview) for alerts and cost driver tracking
These features make it easier to understand which queries, dashboards, or tools drive consumption.
Warehouse monitoring and access control
As more teams rely on DBSQL, admins need to monitor concurrency and warehouse health without over-privileging users. DBSQL also added new governance and observability capabilities:
- Completed Query Count (GA) to show how many queries finish in a time window, helping identify concurrency patterns
- CAN VIEW permissions so admins can grant read-only access to monitoring without giving execution rights
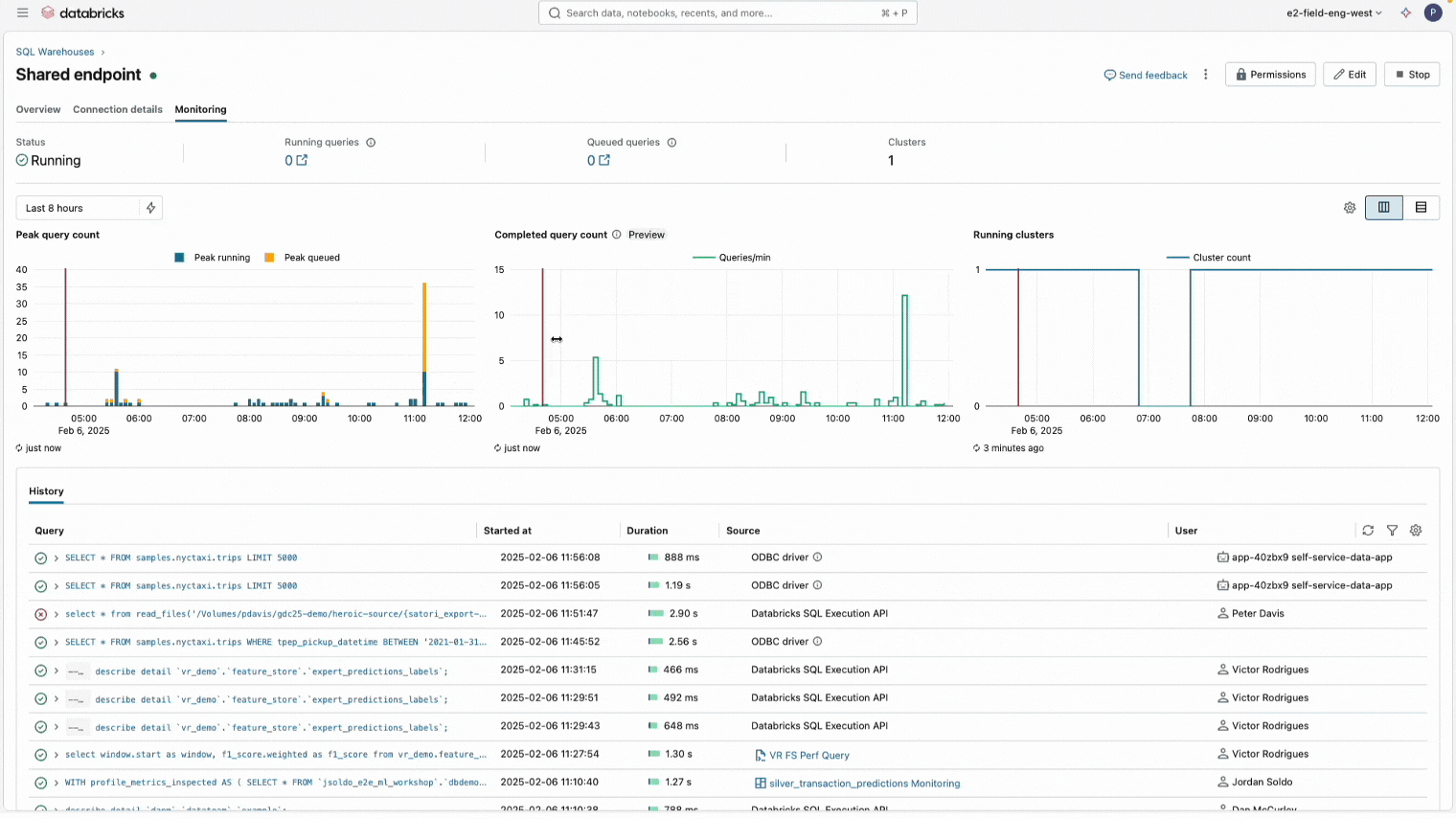
These updates make it easier to run secure, reliable analytics at scale.
The outcome
DBSQL continued to improve in 2025. It now delivers faster serverless performance, built-in AI, open SQL standards for easier migrations, and clearer visibility into cost and workload behavior. Because DBSQL runs on the Databricks lakehouse architecture, analytics, data engineering, and AI all operate on a single, governed foundation. Performance improves automatically, and teams spend less time tuning systems or managing handoffs.
DBSQL remains an open, intelligent, cost-efficient warehouse designed for the realities of AI-driven analytics — and 2025 pushed it forward again.
What’s next
Databricks SQL continues to lead the market as an AI-native, operations-ready warehouse that eliminates the complexity customers face in legacy systems. Upcoming features include:
- Multi-statement transactions, which give teams atomic updates across multiple tables and remove the brittle custom rollback logic many customers built themselves. Multi-statement transactions will also be beneficial for migrating to Databricks.
- Alerts V2, which extends reliability into day-to-day operations, replacing a complex alerting system with a simpler, scalable model designed for thousands of scheduled checks and enterprise-grade operational patterns.
- More AI capabilities, so analysts can apply LLMs and process documents without leaving their workflows, closing the gap between warehouse logic and intelligence.
Together, these capabilities move DBSQL toward a unified, intelligent warehouse that handles core transactional logic, operational monitoring, and AI-assisted analytics in one place.
More details on innovations
We hope you enjoy this bounty of innovations in Databricks SQL. You can always check this What’s New post for the previous three months. Below is a complete inventory of launches we’ve blogged about over the last quarter:
- December 2025: Databricks Lakehouse Data Modeling Myths and Best Practices
- September 2025: Introducing Spatial SQL Databricks: 80+ Functions for High-Performance Geospatial Analytics
- August 2025: Introducing SQL Stored Procedures on Databricks
- August 2025: Introducing the new SQL Editor (GA additions)
- July 2025: What’s new in AI/BI, July 2025 Roundup
- July 2025: Introducing Recursive Common Table Expressions to Databricks
- June 2025: Introducing Lakebride: Free, Open Data Migration to Databricks SQL
- June 2025: Databricks SQL Accelerates Customer Workloads by 5x in Just Three Years
- May 2025: Navigating Your Oracle to Databricks Migration: Tips for a Seamless Transition
- May 2025: Navigating Your SQL Server to Databricks Migration: Tips for a Seamless Transition
- May 2025: Navigating Your Teradata to Databricks Migration: Tips for a Seamless Transition
- May 2025: Navigating Your Netezza to Databricks Migration: Tips for a Seamless Transition
- May 2025: How Databricks Simplifies Data Warehouse Migrations with Proven Strategies and Tools
- May 2025: From Warehouse to Lakehouse: Migration Approaches to Databricks
- May 2025: Introducing SQL Scripting Support in Databricks, Part 1
- May 2025: Introducing SQL Scripting in Databricks, Part 2
- May 2025: Top 10 Tricks for DBAs Migrating to Databricks
- May 2025: Announcing Updates to Databricks Query Profiles
- May 2025: Implementing ETL for SCD Tables
- May 2025: Implementing ETL Patterns Supporting Dimensional Tables
- March 2025: Announcing Automatic Publishing to Power BI
- March 2025: Implementing a Dimensional Data Model in Databricks SQL, Part 1
- April 2025: What’s new in AI/BI Dashboards - April 2025 Roundup
- February 2025: What’s new in Databricks SQL
Getting started
Ready to transform your data warehouse? The best data warehouse is a lakehouse! To learn more about Databricks SQL, take a product tour. Visit databricks.com/sql to explore Databricks SQL and see how organizations worldwide are revolutionizing their data platforms.