Cross-Attention via Self-Attention
Moritz Böhle*, Amélie Royer*, Juliette Marrie*, Edouard Grave, and Patrick Pérez.
*equal contribution.
CASA is a novel vision-language modeling techniques that builds on — and improves — cross-attention for multimodal fusion. Specifically, CASA layers inject visual tokens into a text stream by using image-to-text cross-attention while additionally enabling text-to-text self-interaction in the same layer within local attention windows. This simple modification to the cross-attention design substantially improves performance while retaining the computational efficiency of cross-attention.
We evaluate CASA on several standard vision-language benchmarks spanning a variety of tasks (visual question answering, document understanding, OCR, etc....
Cross-Attention via Self-Attention
Moritz Böhle*, Amélie Royer*, Juliette Marrie*, Edouard Grave, and Patrick Pérez.
*equal contribution.
CASA is a novel vision-language modeling techniques that builds on — and improves — cross-attention for multimodal fusion. Specifically, CASA layers inject visual tokens into a text stream by using image-to-text cross-attention while additionally enabling text-to-text self-interaction in the same layer within local attention windows. This simple modification to the cross-attention design substantially improves performance while retaining the computational efficiency of cross-attention.
We evaluate CASA on several standard vision-language benchmarks spanning a variety of tasks (visual question answering, document understanding, OCR, etc.), comparing to other fusion mechanisms such as token insertion and cross-attention. To showcase the benefits of CASA for streaming applications, we further finetune and employ our model for the task of live video captioning.
Example of live video captions generated with our ** CASA-Qwen2_5-VL-3B-LiveCC ** model on two videos from the Animal Kingdom dataset. Code to reproduce such examples is available in our github repository . Additional samples are available at at the bottom of this page.
Takeaways
- CASA substantially improves over standard cross-attention. By enabling text-to-text attention alongside text-to-image attention within CASA layers, we observe significant performance gains, especially on benchmarks requiring high-detailed visual information.
- CASA efficiently injects visual information into LLMs. In particular, CASA achieves performance comparable to token insertion approaches, but with a compute and memory cost that scales similar to cross-attention-based designs as the number of tokens grows.
- CASA can be flexibly integrated into existing models. Specifically, it can be used to either (i) train a vision-language model from scratch starting from a text-only LLM, or (ii) adapt an existing insertion-based VLM into a more efficient CASA-based model.
- CASA supports low-latency streaming applications. For example, we show results for live video captioning, which is often impractical with token-insertion-based methods due to the high number of image tokens given in streaming video applications.
Table of Contents
- CASA: An Overview
- Motivation
- Model Training and Release
- Quantitative Evaluation
- Efficiency Analysis on Live Video Captioning
- Qualitative Samples
CASA: Cross-Attention via Self-Attention


(i) Standard self-attention layer
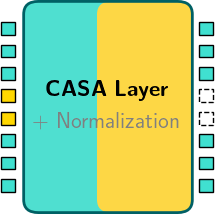
(ii) CASA layer w/ local attention windows
CASA models process and fuse vision and text inputs through two mechanisms:
- (i) Standard self-attention layers process all the text tokens of the current conversation, but without access to any visual tokens (left).
- (ii) CASA layers process both text and image tokens but in local attention windows (right). The windows are defined by the points at which images occur in the stream, e.g., between two video frames. To improve efficiency, CASA layers also leverage asymmetric block-wise attention implemented using Flash Attention.
Click to play
Motivation
Early multimodal transformers employed cross-attention as a way to fuse visual and language information through modular cross-attention layers added to an LLM backbone. However, recent VLMs widely use token insertion as a fusion mechanism, which directly inserts image tokens into the text token stream. While this approach is more costly, token insertion performs significantly better than state-of-the-art cross-attention based models, in particular on tasks requiring a high granularity of details such as document understanding or OCR.
To address the shortcomings of cross-attention, we propose CASA: CASA layers are built as cross-attention layers in which both text and image tokens are used as keys and values. We find that this enables a natural gating mechanism, as shown in the next paragraph, which greatly improves the model performance and largely closes the gap to insertion-based approaches.

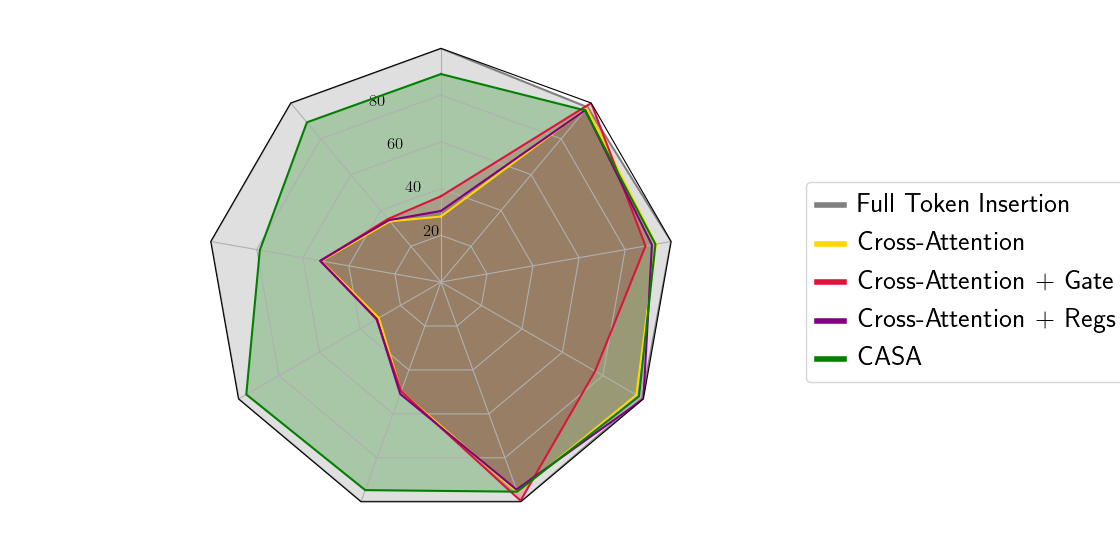
Comparison of token insertion, cross-attention and CASA mechanisms. Left: When comparing current state-of-the-art cross-attention- and insertion-based models, cross-attention approaches achieve comparable performance on general visual question answering tasks. However. they significantly lag behind on fine-grained benchmarks such as chart and document understanding. Right: We obtain the same conclusions in a controlled experimental setting, where we train and compare cross-attention-based models (vanilla, gated, and register-based) with direct insertion of visual tokens into the language model input. Based on this analysis, we propose Cross-Attention via Self-Attention (** CASA **), a simple improvement over standard cross-attention which largely closes the gap to token insertion.
A Key Component: CASA as a Gating Mechanism
We analyze the attention weights inside CASA layers, focusing on how text tokens interact with either text or image tokens. As shown in the figure below, the attention weight of a query text token to itself is by far the strongest, and disabling this component leads to a substantial performance drop (see additional results in our preprint).
This result higlights how text-to-text self-attention is a critical component for implicit gating in CASA layers, as it allows the model to naturally scale the contribution of text and image tokens in the final outputs.

Attention scores of query token in CASA (Qwen2.5-VL) layers (log scale), averaged across heads and layers. We report the attention of query tokens to (1) the vision start and end tokens, (2) image tokens (grouped by 16), (3) other text tokens, and (4) the query token itself.
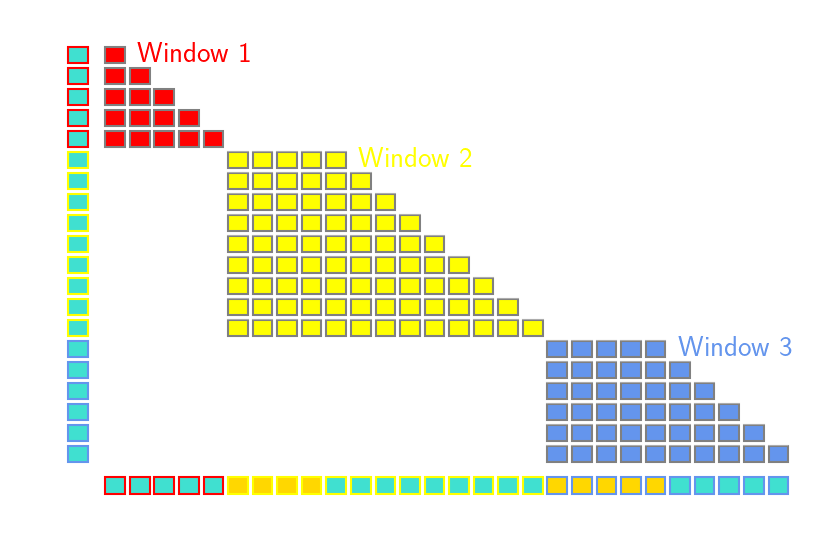
CASA: Local Attention Windows

To preserve efficiency, CASA layers use local attention : The attention operation in CASA layers acts in local attention windows, which are naturally delimited by image occurrences: each window consists of a single image (or multiple consecutive images) followed by the associated text. In practice, this is implemented using blockwise attention.
In particular for live video captioning, this means CASA layers only see a single frame (extracted at 2fps) and the corresponding closed captions for this timestamp, which is typically only a few tokens long. Nevertheless, the global coherence of the entire video script is preserved through the text-only tokens interactions in the self-attention layers.
Model Training and Release
To showcase CASA’s applicability for both extending language-only models with visual understanding as well as adapting existing VLMs, we train our models in two settings:
- Starting from Helium1-2B, a text-only LLM which we fully fine-tune alongside additional CASA layers, to obtain a CASA-based Helium1 model.
- We adapt Qwen2.5-VL-3B, a pretrained VLM which originally handles visual inputs by directly inserting image tokens in the token stream. In this setting we keep the backbone VLM frozen and adapt it to CASA by training only the additional CASA layers.
In both cases, images are embedded using the Qwen2.5-VL visual encoder, whose last four blocks are fine-tuned before feeding visual features into CASA.
Vision-Language Models
All models are first trained on a combination of publically available datasets: namely, the FineVision dataset, and a subset of LLaVA-OneVision-1.5, which together cover a wide range of tasks including image captioning, document and chart understanding, and general visual question answering.
🔹 CASA models release We release
kyutai/CASA-Helium1-VL-2Bandkyutai/CASA-Qwen2_5-VL-3B, pretrained on FineVision and a subset LLaVA-OneVision-1.5.
🔹 Token insertion Helium1 release In addition to CASA-based models, we release
kyutai/Helium1-VL-2B, a VLM based trained from Helium1-2B with direct token insertion on the same training dataset.Helium1-VL-2Bachieves state-of-the-art performance among insertion-based models of comparable size trained with publically available datasets.
Live Video Captioning Models
For live video captioning, we further fine-tune our CASA-Qwen2_5-VL-3B models on the Live-WhisperX-526K dataset, which is an instruction-style video dataset for live captioning, consisting of video frames sampled at 2 fps and interleaved with the corresponding text transcripts of the original video audio.
🔹 LiveCC CASA models. We release
CASA-Qwen2_5-VL-3B-LiveCC, further finetuned on Live-WhisperX for live streaming.
Quantitative Results
We evaluate our image-based models CASA-Helium1-VL-2B, Helium1-VL-2B and CASA-Qwen2_5-VL-2B on a range of benchmarks covering document understanding (DocVQA), chart understanding (ChartQA, InfoVQA), visual text reading (TextVQA, OCRBench), and general QA (RealWorldQA, AI2D, GQA, MME).
| Model | Document / Chart | Scene Text | Knowledge / QA | ChartQA | DocVQA | InfoVQA | OCRBench | TextVQA | RealWorldQA | AI2D | GQA | MME |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Insertion (He-2B) | 81.6 | 89.1 | 61.8 | 728 | 75.5 | 59.9 | 67.7 | 55.5 | 1732 | |||
| CASA (He-2B) | 73.4 | 83.7 | 48.6 | 723 | 71.0 | 58.3 | 63.3 | 54.6 | 1572 | |||
| mPLUG-Owl3 8B | 59.2† | 55.9† | 36.8† | 527† | 69.0 | 63.9† | 73.4 | 65.0 | 1940† | |||
| mPLUG-Owl3 2B | 48.5† | 48.2† | 28.1† | 450† | 62.6 | 56.9† | 62.6 | 61.0 | 1551† |
† Reproduced with the publicly available models on HuggingFace.
Comparing different vision-language fusion mechanisms in the 2-3B range. We compare CASA trained from scratch from the text-only Helium1-2B (CASA-Helium1-VL-2B, orange), a recent cross-attention (CA) baseline (in blue), and our token insertion baseline trained from Helium1 (Helium1-VL-2B, gray). Evaluation is performed using the lmms-eval pipeline and we provide code to reproduce our results in our repository. CASA significantly outperforms current SotA cross-attention-based VLMs, narrowing the gap to insertion-based approaches.
| Model | Document / Chart | Scene Text | Knowledge / QA | ChartQA | DocVQA | InfoVQA | OCRBench | TextVQA | RealWorldQA | AI2D | GQA | MME |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2.5-VL 3B | 84.0 | 93.6 | 77.1 | 797 | 79.3 | 62.2† | 81.6 | 61.0† | 2249† | |||
| CASA (Qwen2.5-VL 3B) | 82.4 | 88.9 | 59.6 | 790 | 77.4 | 62.5 | 75.1 | 59.4 | 1918 |
† Reproduced with the publicly available models on Hugging Face.
Adapting a frozen pretrained Qwen2.5-VL. Our CASA-Qwen2_5-VL-3B model reaches performance close to the original insertion-based model while keeping the base model frozen and training only the CASA layers.
Efficiency Analysis on Live Video Captioning
We further finetune our Qwen2.5-VL CASA model on the Live-WhisperX dataset introduced in LiveCC (Chen et al, 2025). In contrast to token insertion, CASA does not introduce any memory overhead as image tokens are not stored in the KV Cache but simply replaced as inputs to the CASA layers’ K and V projections for every new video frame. As a result, CASA can be applied on long videos with a significantly reduced memory bottleneck.
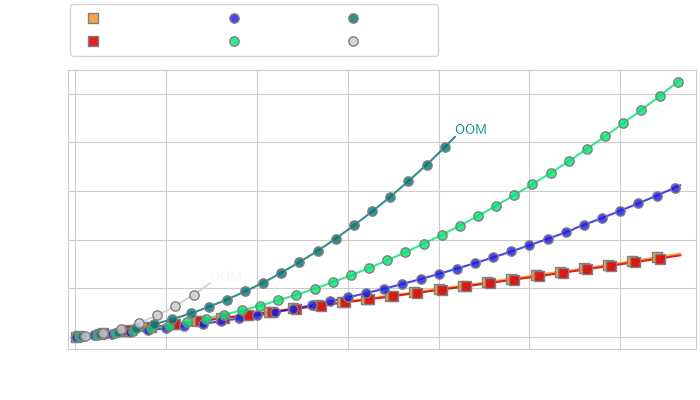
Wall-clock time vs number of turns
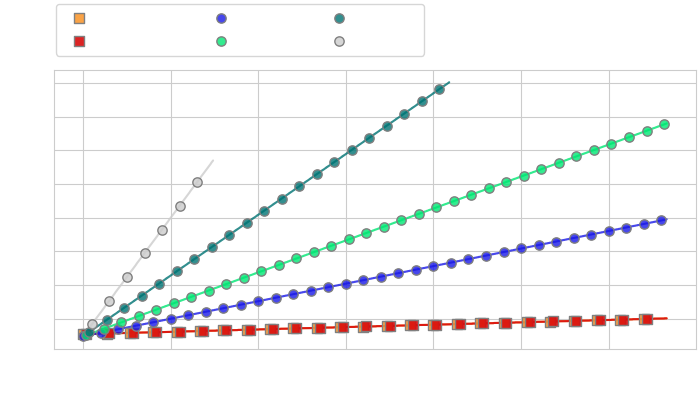
Memory vs number of turns
Efficiency Analysis of CASA vs token compression for streaming applications. We compare the computational cost (left) and memory cost (right) of CASA and token compression methods (Q-Former with varying numbers of query tokens) on the task of live video captioning for video frames extracted at 2fps, with roughly 5 text tokens generated between each consecutive frames.
While token compression reduces the cost of token insertion for short conversations, it cannot alone prevent the increased memory usage leading to OOM when the number of tokens is too high (left). In contrast, CASA maintains high inference speed over much longer horizons (right), while always making high-resolution image information available to the model.
Additional Qualitative Samples
Additional samples are available as a gallery in the following HuggingFace space, embedded below (best seen in Chromium-based browsers).