In this article, you will learn practical ways to convert raw text into numerical features that machine learning models can use, ranging from statistical counts to semantic and contextual embeddings.
Topics we will cover include:
- Why TF-IDF remains a strong statistical baseline and how to implement it.
- How averaged GloVe word embeddings capture meaning beyond keywords.
- How transformer-based embeddings provide context-aware representations.
Let’s get right into it.
3 Feature Engineering Techniques for Unstructured Text Data Image by Editor
Introduction
Machine learning models poss…
In this article, you will learn practical ways to convert raw text into numerical features that machine learning models can use, ranging from statistical counts to semantic and contextual embeddings.
Topics we will cover include:
- Why TF-IDF remains a strong statistical baseline and how to implement it.
- How averaged GloVe word embeddings capture meaning beyond keywords.
- How transformer-based embeddings provide context-aware representations.
Let’s get right into it.
3 Feature Engineering Techniques for Unstructured Text Data Image by Editor
Introduction
Machine learning models possess a fundamental limitation that often frustrates newcomers to natural language processing (NLP): they cannot read. If you feed a raw email, a customer review, or a legal contract into a logistic regression or a neural network, the process will fail immediately. Algorithms are mathematical functions that operate on equations, and they require numerical input to function. They do not understand words; they understand vectors.
Feature engineering for text is a crucial process that bridges this gap. It is the act of translating the qualitative nuances of human language into quantitative lists of numbers that a machine can process. This translation layer is often the decisive factor in a model’s success. A sophisticated algorithm fed with poorly engineered features will perform worse than a simple algorithm fed with rich, representative features.
The field has undergone significant evolution over the past few decades. It has evolved from simple counting mechanisms that treat documents as bags of unrelated words to complex deep learning architectures that understand the context of a word based on its surrounding words.
This article covers three distinct approaches to this problem, ranging from the statistical foundations of TF-IDF to the semantic averaging of GloVe vectors, and finally to the state-of-the-art contextual embeddings provided by transformers.
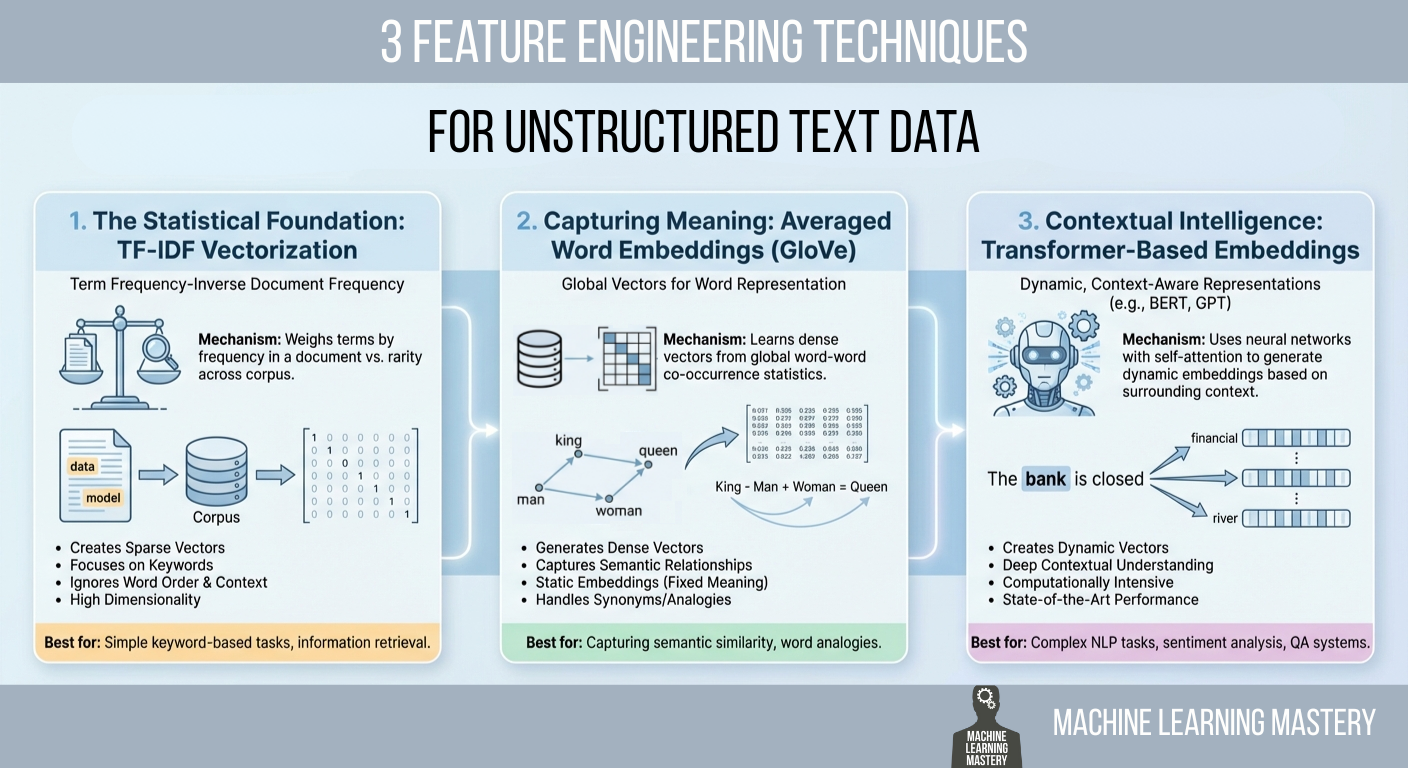
1. The Statistical Foundation: TF-IDF Vectorization
The most straightforward way to turn text into numbers is to count them. This was the standard for decades. You can simply count the number of times a word appears in a document, a technique known as bag of words. However, raw counts have a significant flaw. In almost any English text, the most frequent words are grammatically necessary but semantically empty articles and prepositions like “the,” “is,” “and,” or “of.” If you rely on raw counts, these common words will dominate your data, drowning out the rare, specific words that actually give the document its meaning.
To solve this, we use term frequency–inverse document frequency (TF-IDF). This technique weighs words not just by how often they appear in a specific document, but by how rare they are across the entire dataset. It is a statistical balancing act designed to penalize common words and reward unique ones.
The first part, term frequency (TF), measures how frequently a term occurs in a document. The second part, inverse document frequency (IDF), measures the importance of a term. The IDF score is calculated by taking the logarithm of the total number of documents divided by the number of documents that contain the specific term.
If the word “data” appears in every single document in your dataset, its IDF score approaches zero, effectively cancelling it out. Conversely, if the word “hallucination” appears in only one document, its IDF score is very high. When you multiply TF by IDF, the result is a feature vector that highlights exactly what makes a specific document unique compared to the others.
Implementation and Code Explanation
We can implement this efficiently using the scikit-learn TfidfVectorizer. In this example, we take a small corpus of three sentences and convert them into a matrix of numbers.
| 12345678910111213141516171819202122 | from sklearn.feature_extraction.text import TfidfVectorizerimport pandas as pd# 1. Define a small corpus of textdocuments = [ "The quick brown fox jumps.", "The quick brown fox runs fast.", "The slow brown dog sleeps."]# 2. Initialize the Vectorizer# We limit the features to the top 100 words to keep the vector size manageablevectorizer = TfidfVectorizer(max_features=100)# 3. Fit and Transform the documentstfidf_matrix = vectorizer.fit_transform(documents)# 4. View the result as a DataFrame for clarityfeature_names = vectorizer.get_feature_names_out()df_tfidf = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)print(df_tfidf) |
The code begins by importing the necessary TfidfVectorizer class. We define a list of strings that serves as our raw data. When we call fit_transform, the vectorizer first learns the vocabulary of the entire list (the “fit” step) and then transforms each document into a vector based on that vocabulary.
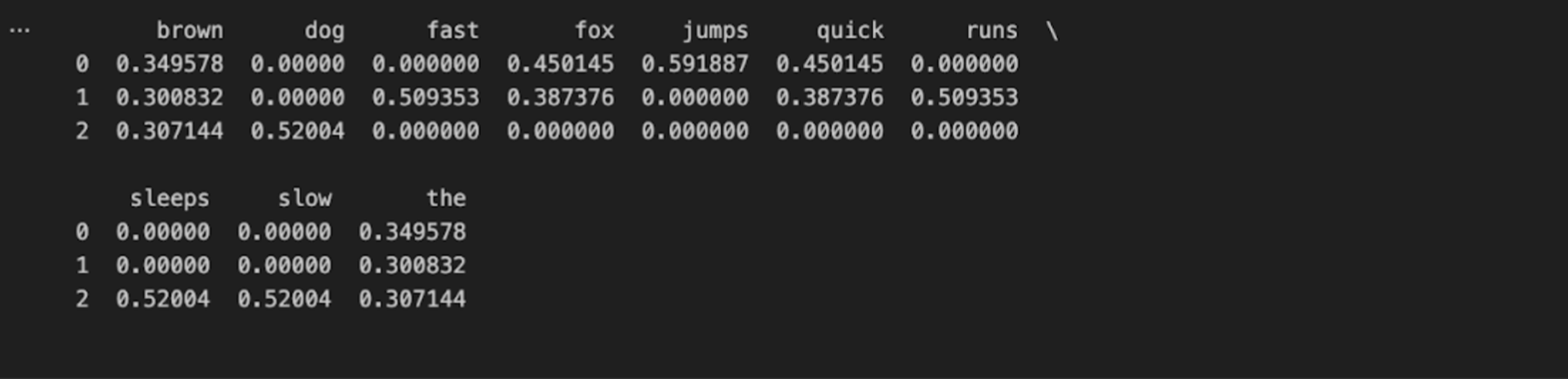
The output is a Pandas DataFrame, where each row represents a sentence, and each column represents a unique word found in the data.
2. Capturing Meaning: Averaged Word Embeddings (GloVe)
While TF-IDF is powerful for keyword matching, it suffers from a lack of semantic understanding. It treats the words “good” and “excellent” as completely unrelated mathematical features because they have different spellings. It does not know that they mean nearly the same thing. To solve this, we move to word embeddings.
Word embeddings are a technique where words are mapped to vectors of real numbers. The core idea is that words with similar meanings should have similar mathematical representations. In this vector space, the distance between the vector for “king” and “queen” is roughly similar to the distance between “man” and “woman.”
One of the most popular pre-trained embedding sets is GloVe (global vectors for word representation), developed by researchers at Stanford. You can access their research and datasets on the official Stanford GloVe project page. These vectors were trained on billions of words from Common Crawl and Wikipedia data. The model looks at how often words appear together (co-occurrence) to determine their semantic relationship.
To use this for feature engineering, we face a small hurdle. GloVe provides a vector for a single word, but our data usually consists of sentences or paragraphs. A common, effective technique to represent a whole sentence is to calculate the mean of the vectors of the words it contains. If you have a sentence with ten words, you look up the vector for each word and average them together. The result is a single vector that represents the “average meaning” of the entire sentence.
Implementation and Code Explanation
For this example, we will assume you have downloaded a GloVe file (such as glove.6B.50d.txt) from the Stanford link above. The code below loads these vectors into memory and averages them for a sample sentence.
| 1234567891011121314151617181920212223242526272829303132333435363738394041424344 | import numpy as np# 1. Load the GloVe embeddings into a dictionary# This assumes you have the glove.6B.50d.txt file locallyembeddings_index = {}with open(‘glove.6B.50d.txt’, encoding=‘utf-8’) as f: for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype=‘float32’) embeddings_index[word] = coefsprint(f"Loaded {len(embeddings_index)} word vectors.")# 2. Define a function to vectorize a sentencedef get_average_word2vec(tokens, vector_dict, generate_missing=False, k=50): if len(tokens) < 1: return np.zeros(k) # Extract the vector for each word if it exists in our dictionary feature_vec = np.zeros((k,), dtype="float32") count = 0 for word in tokens: if word in vector_dict: feature_vec = np.add(feature_vec, vector_dict[word]) count += 1 if count == 0: return feature_vec # Divide the sum by the count to get the average feature_vec = np.divide(feature_vec, count) return feature_vec# 3. Apply to a new sentencesentence = "artificial intelligence is fascinating"# Simple tokenization by splitting on spacetokens = sentence.lower().split()sentence_vector = get_average_word2vec(tokens, embeddings_index)print(f"The vector has a shape of: {sentence_vector.shape}")print(sentence_vector[:5]) # Print first 5 numbers |
The code first builds a dictionary where the keys are English words, and the values are the corresponding NumPy arrays representing their GloVe vectors. The function get_average_word2vec iterates through the words in our input sentence. It checks if the word exists in our GloVe dictionary; if it does, it adds that word’s vector to a running total.
Finally, it divides that total sum by the number of words found. This operation collapses the variable-length sentence into a fixed-length vector (in this case, 50 dimensions). This numerical representation captures the semantic topic of the sentence. A sentence about “dogs” will have a mathematical average very close to a sentence about “puppies,” even if they share no common words, which is a big improvement over TF-IDF.
3. Contextual Intelligence: Transformer-Based Embeddings
The averaging method described above represented a major leap forward, but it introduced a new problem: it ignores order and context. When you average vectors, “The dog bit the man” and “The man bit the dog” result in the exact same vector because they contain the exact same words. Furthermore, the word “bank” has the same static GloVe vector regardless of whether you are sitting on a “river bank” or visiting a “financial bank.”
To solve this, we use transformers, specifically models like BERT (Bidirectional Encoder Representations from Transformers). Transformers do not read text sequentially from left to right; they read the entire sequence at once using a mechanism called “self-attention.” This allows the model to understand that the meaning of a word is defined by the words around it.
When we use a transformer for feature engineering, we are not necessarily training a model from scratch. Instead, we use a pre-trained model as a feature extractor. We feed our text into the model, and we extract the output from the final hidden layer. Specifically, models like BERT prepend a special token to every sentence called the [CLS] (classification) token. The vector representation of this specific token after passing through the layers is designed to hold the aggregate understanding of the entire sequence.
This is currently considered a gold standard for text representation. You can read the seminal paper regarding this architecture, “Attention Is All You Need,” or explore the documentation for the Hugging Face Transformers library, which has made these models accessible to Python developers.
Implementation and Code Explanation
We will use the transformers library by Hugging Face and PyTorch to extract these features. Note that this method is computationally heavier than the previous two.
| 12345678910111213141516171819202122232425 | from transformers import BertTokenizer, BertModelimport torch# 1. Initialize the Tokenizer and the Model# We use ‘bert-base-uncased’, a smaller, efficient version of BERTtokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)model = BertModel.from_pretrained(‘bert-base-uncased’)# 2. Preprocess the texttext = "The bank of the river is muddy."# return_tensors=‘pt’ tells it to return PyTorch tensorsinputs = tokenizer(text, return_tensors="pt")# 3. Pass the input through the model# We use ‘no_grad()’ because we are only extracting features, not trainingwith torch.no_grad(): outputs = model(**inputs)# 4. Extract the features# ‘last_hidden_state’ contains vectors for all words# We usually want the [CLS] token, which is at index 0cls_embedding = outputs.last_hidden_state[:, 0, :]print(f"Vector shape: {cls_embedding.shape}")print(cls_embedding[0][:5]) |
In this block, we first load the BertTokenizer and BertModel. The tokenizer breaks the text into pieces that the model recognizes. We then pass these tokens into the model. The torch.no_grad() context manager is used here to tell PyTorch that we do not need to calculate gradients, which saves memory and computation since we are only doing inference (extraction), not training.
The outputs variable contains the activations from the last layer of the neural network. We slice this tensor to get [:, 0, :]. This specific slice targets the first token of the sequence, the [CLS] token mentioned earlier. This single vector (usually 768 numbers long for BERT Base) contains a deep, context-aware representation of the sentence. Unlike the GloVe average, this vector “knows” that the word “bank” in this sentence refers to a river because it “paid attention” to the words “river” and “muddy” during processing.
Conclusion
We have traversed the landscape of text feature engineering from the simple to the sophisticated. We began with TF-IDF, a statistical method that excels at keyword matching and remains highly effective for simple document retrieval or spam filtering. We moved to averaged word embeddings, such as GloVe, which introduced semantic meaning and allowed models to understand synonyms and analogies. Finally, we examined transformer-based embeddings, which offer deep, context-aware representations that underpin the most advanced artificial intelligence applications today.
There is no single “best” technique among these three; there is only the right technique for your constraints. TF-IDF is fast, interpretable, and requires no heavy hardware. Transformers provide the highest accuracy but require significant computational power and memory. As a data scientist or engineer, your role is to strike a balance between these trade-offs to build the most effective solution for your specific problem.