As AI agents become more common in the enterprise, the sheer number of available tools can overwhelm them. This article explores a practical approach based on the `Tool2Vec` methodology to create a smarter tool retrieval system, allowing even small language models to efficiently find the right tool for the job.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
The Agent’s Dilemma: Too Many Tools, Not Enough Context
The era of AI age…
As AI agents become more common in the enterprise, the sheer number of available tools can overwhelm them. This article explores a practical approach based on the `Tool2Vec` methodology to create a smarter tool retrieval system, allowing even small language models to efficiently find the right tool for the job.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
The Agent’s Dilemma: Too Many Tools, Not Enough Context
The era of AI agents is here. From automating complex IT workflows to powering sophisticated customer service bots, Large Language Models (LLMs) are being equipped with external tools to interact with the world. But as we move from proof-of-concept to production, a critical bottleneck has emerged in the form of tool sprawl.
An LLM agent is like a brilliant mechanic. Give it a handful of wrenches, and it can work wonders. But what happens when you give it a warehouse containing thousands of specialized tools? It becomes overwhelming. The sheer volume of tool descriptions, or prompt bloat, noticeably impacts model performance even with the largest models. For the smaller, more efficient small language models (SLMs) crucial for enterprise applications, this limitation is a hard stop. Performance degrades, latency increases, and the agent fails.
How do we build an agent that can intelligently select the right tool from a vast library without being fed the entire manual? This is the core challenge our team set out to solve.
The Landscape of Tool Retrieval: From Naive Searches to Intelligent Vectors
The problem isn’t new, and several approaches have emerged. The most basic is a naive semantic search, where tool descriptions are embedded and retrieved. While simple, it often lacks the nuance to distinguish between similarly described tools. Other methods, like fine-tuning a dedicated model for tool retrieval, show promise but struggle with dynamic toolsets, a dealbreaker for evolving enterprise environments.
Our research led us to promising academic work, most notably Tool2Vec. The core insight of Tool2Vec is brilliant: instead of embedding (represented as numerical vectors in a high-dimensional space where similar concepts are grouped together) tool descriptions and retrieving them, why not embed the types of questions the description can answer? By generating example queries for each tool and averaging their embeddings, we can create a much more accurate and context aware representation of what a tool actually does.
Under the Hood: The Tool2Vec Methodology
To build a truly effective solution, we first need to understand the academic foundation. The Tool2Vec paper presents a powerful methodology that addresses a core weakness in traditional tool retrieval: the semantic gap. Relying on tool descriptions alone is often ineffective because the way a developer describes a tool and the way a user asks a question can be worlds apart in the embedding space.Tool2Vec solves this by creating usage driven embeddings. Instead of embedding the tool’s description, it embeds multiple example user queries that utilize the tool. The average of these query embeddings becomes the new, more accurate vector for the tool, ensuring it’s located in the same semantic neighborhood as the questions it’s meant to answer.
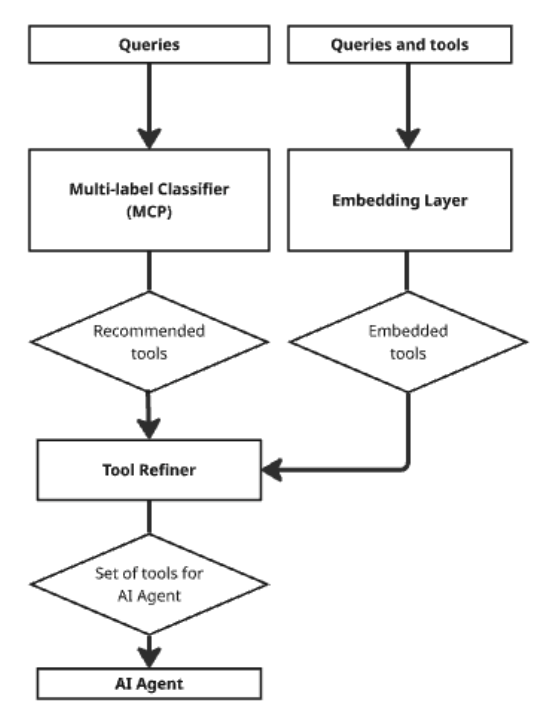 Diagram 1: Tool2Vec architecture , showing stage 1 and stage 2
Diagram 1: Tool2Vec architecture , showing stage 1 and stage 2
The paper proposes an elegant two-stage architecture to leverage this:
- Stage 1: Candidate Retrieval (Fast Pruning): The first step is to rapidly narrow down the vast tool library to a smaller set of likely candidates. The paper outlines two effective methods for this:
- Vector Search: Using the new Tool2Vec embeddings for a fast, similarity-based retrieval.
- Multi-Label Classification (MLC): Training a fast classifier (like DeBERTa) that takes a user query and directly predicts a set of relevant tools.
- Stage 2: The ToolRefiner (Precision Reranking): The candidate tools from Stage 1 are then passed to a more powerful, nuanced model called the ToolRefiner. This model doesn’t just look at the query and one tool at a time; it examines the query alongside the entire set of candidate tools. By understanding the inter-tool and tool query interactions, it can make a much more accurate final selection, calculating a relevance score for each tool and filtering out any noise from the first stage.
This retrieve-then-refine framework, as detailed in the research, provides a blueprint for an efficient and highly accurate system, achieving significant improvements in recall (up to 30.5% on their ToolBank dataset) over description-based methods.
Our Approach: Hardening Tool2Vec for the Enterprise
While the Tool2Vec framework shows impressive results on academic benchmarks, many existing datasets fall short of reflecting real-world industry standards. They often feature randomly sampled tools and incoherent queries scenarios and enterprise developers would never encounter.
We found one dataset that stands out: Stable ToolBench, a comprehensive benchmark with over 7,000 tools and realistic queries. However, it does not use MCP (Model Context Protocol) ,an emerging standard for how AI models interact with tools which is critical for ensuring more secure, scalable, and interoperable tool use, and therefore still fails to represent a true real-world use case.
Our project aims to bridge this gap by adapting Stable ToolBench to fully align with enterprise needs through MCP integration bringing this dataset closer to real world applicability. Its primary limitation is that its tools are not compliant with the MCP.
Our process is methodical:
- First, we are engineering a lightweight MCP proxy server. This critical piece of infrastructure acts as a universal adapter, making the entire Stable ToolBench environment available to our agent as if it were a native enterprise toolset.
- Next, with our MCP-compatible toolkit in place, we will apply the core Tool2Vec principle to generate powerful, usage-driven embeddings for this industry aligned data.
- Finally, we will train our ToolRefiner component on this high quality, correctly formatted data, allowing it to learn the nuances of a realistic and complex tool library.
By taking an established benchmark and layering an enterprise standard protocol on top, our goal is to create a tool retrieval system that is not just academically sound, but empirically proven to be efficient and accurate for the types of interconnected tools our customers use every day.
Putting Theory into Practice: Our Evaluation Framework
A good idea is one thing; proving it works is another. That’s why we’ve developed a rigorous evaluation framework built on two core principles: a solid testing environment and smarter metrics.
**1. The Environment: A Stable, Repeatable Testbed **
Our entire system is built on Stable ToolBench. This benchmark is the ideal foundation because it’s a fully self-contained ecosystem. Using a smart Mirror API model, it simulates thousands of real-world tools without external dependencies. This eliminates variables and gives us a stable, perfectly repeatable testbed for every experiment.
*2. The Metrics: Measuring the Journey, Not Just the Destination ***
A stable environment is only half the story. Standard evaluations often ask a single question: *was the final answer correct? *For us, that’s not nearly enough. Our primary goal is to improve the tool retriever, so we can also ask the question: did the agent pick the right tools in the right order? To answer this, we’re implementing a tool sequence validation metric. This metric compares the sequence of tools our agent calls against the optimal “golden path” in the dataset. This gives us a precise, direct measure of our retriever’s performance, moving far beyond simply judging the final output. The table 1 below shows the list of metrics and their definitions.
| Metric | Definition |
| Tool Execution Rate | How many times tools are actually executed |
| Correct Tool Selection Rate | How many times the correct tool |
| Irrelevant Tool Rate | How many times irrelevant tool |
| Average Latency | Average response time for all queries |
Table: Evaluation metrics definitions
Conclusion: The Path to Smarter, Scalable Agents
The challenge of tool sprawl is a real barrier to deploying powerful, efficient AI agents in the enterprise. A larger context window isn’t the answer; a smarter retrieval process is. By combining the usage driven philosophy of Tool2Vec with a pragmatic, enterprise focused implementation and evaluation framework, we are charting a path toward that solution.
Our work aims to deliver a system that allows even small, efficient language models to navigate vast toolkits with precision and speed. This will enable developers to build more reliable, capable, and scalable agents that can finally tackle the complexity of real world business problems. Stay tuned as we continue to develop this framework and share our results.

