12·12·2025
In the last few days I’ve managed to finalize work on the UringMachine fiber scheduler. Beyond making sure the fiber scheduler is feature complete, that is, it implements all the different Fiber Scheduler hooks and their expected behaviour. To make sure of this, I also spent a couple of days writing test cases, not only of the fiber scheduler, but also of UM’s low-level API.
Beyond the tests, I wrote a series of benchmarks to have an idea of how UringMachine compares to other concurrency solutions:
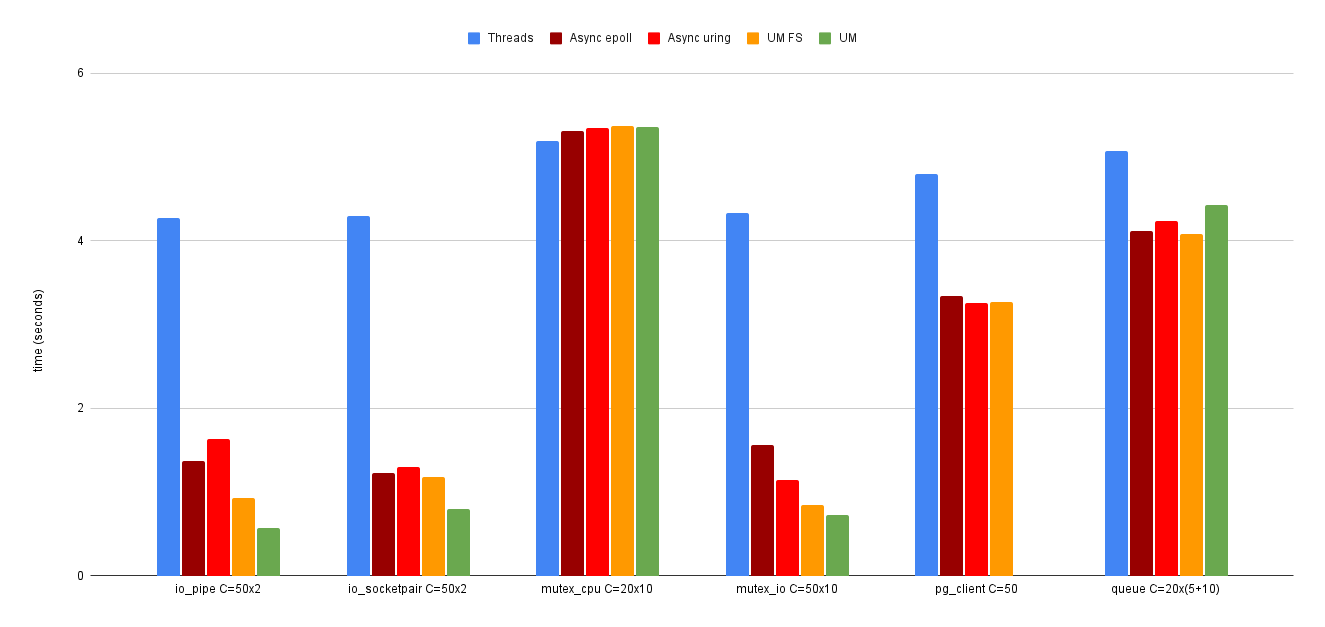
You can consult the full results here. I’ll refrain from making o…
12·12·2025
In the last few days I’ve managed to finalize work on the UringMachine fiber scheduler. Beyond making sure the fiber scheduler is feature complete, that is, it implements all the different Fiber Scheduler hooks and their expected behaviour. To make sure of this, I also spent a couple of days writing test cases, not only of the fiber scheduler, but also of UM’s low-level API.
Beyond the tests, I wrote a series of benchmarks to have an idea of how UringMachine compares to other concurrency solutions:
You can consult the full results here. I’ll refrain from making overly generalized statements about what these benchmark results mean, but I think they demonstrate the promise of working with fibers to create concurrent Ruby apps.
So, as these benchmarks show, the Fiber Scheduler can bring significant benefits to concurrent Ruby apps, with minimal changes to the code (basically, instead of Thread.new you’ll use Fiber.schedule). The fact that the scheduler does the I/O transparently behind the scenes and integrates with the rest of the Ruby ecosystem feels almost like magic.
So I think this really validates the approach of Samuel Williams in designing how the fiber scheduler interfaces with the rest of the Ruby runtime. And the fact that the web server he authored, Falcon, is now used in production at Shopify, is an even stronger validation!
Here’s a detailed report of my work this last week:
Samuel has fixed the issue with the hanging #pwrite (it turns out the the #io_pwrite hook was being invoked with the GVL released.)
Added support for SQPOLL mode when setting up a UringMachine instance. It’s not clear to me what are the performance implications of that, but I’ll try to make some time to check this against TP2, a UringMachine-based web server I’m currently using in a bunch of projects.
started looking at getting #io_close to work, and found out that Samuel has already done the work, that is the code was already there, but was commented out. Samuel explained that it was impossible to get it to work due to the complexity of the implementation of IO#close, and indeed when I tried it myself I saw that in fact it was just not possible the way the IO state is managed when an IO is closed. I then had the idea that maybe we could pass the underlying fd instead of the IO object itself to the #io_close hook. The only issue is that this breaks the convention where the different io_xxx hooks take an io as their first argument. Nevertheless, I suggested this idea to Samuel and gladly he accepted when he saw this is the only we can make this hook work. Samuel then proceeded to prepare a PR and merge it.
Added the #io_close hook to the UringMachine fiber scheduler, as well as a #yield hook for dealing with thread interrupts in response to another PR by Samuel. I also added missing docs for the different methods in the fiber scheduler.
Spent a lot of time writing lots of tests for the fiber scheduler. I tried to cover the entire IO API - both class- and instance methods. I also wrote some “integration” tests - different scenarios not unlike those in the benchmarks, which exercise the different hooks in the fiber scheduler.
Added some new APIs to help with testing: UM#await_fibers is a method for waiting for one or more fibers to terminate. Unlike UM#join, it doesn’t return the return values of the given fibers, it just waits for them to terminate. Another new API is UM.socketpair, which is like Socket.socketpair except it returns raw fd’s.
Fixed some small issues in the UM fiber scheduler and in the UM low-level API implementation.
Added and streamlined metrics that indicate the following:
- The ring size
- Total number of ops
- Total number of fiber switches
- Total number of waits for CQEs
- Current number of pending ops
- Current number of unsubmitted ops
- Current size of runqueue
- Current number of transient ops
- Current number of free ops
I also added some basic time measurements:
- Total CPU time
- Total time spent waiting for CQEs
These are off by default, but can be enabled by calling UM#profile(true). I’d like to do a lot more with profiling, like measuring the CPU time spent on each fiber, but I’m a bit apprehensive of the performance costs involved, as getting the CLOCK_THREAD_CPUTIME_ID clock is relatively slow, and then managing this for each fiber means getting and setting a couple of instance variables, which can really slow things down. On top of that, I’m not that sure this is really needed.
What’s Next for UringMachine
One of the ideas I discussed with Samuel is to add support for registered buffers that integrates with the IO::Buffer class. While UringMachine already has support for buffer rings, it uses a custom implementation of buffers. So I might start by converting this to use IO::Buffer instead.
I’d also like to do a bit more work on performance tuning the UringMachine low-level API, specifically to be able to control the maximum number of fiber context switches before doing I/O work, i.e. submitting ops and checking for completions.
Beyond that, I also want to spend some time documenting the UringMachine API, as it is sorely lacking, and I’d like for other people to be able to play with it.