Post navigation
← Previous
Introduction
In Zach Wissner-Gross’s Fiddler on the Proof, he mentions the following problem from nearly five years ago, when it was still FiveThirtyEight’s The Riddler:
You are one of  finalists in a skiing championship. There are two rounds: in the first round, each finalist skis down the mountain, recording their finishing time; this is repeated in the second round, with the least *total *time for both runs winning the championship. This is th…
finalists in a skiing championship. There are two rounds: in the first round, each finalist skis down the mountain, recording their finishing time; this is repeated in the second round, with the least *total *time for both runs winning the championship. This is th…
Post navigation
← Previous
Introduction
In Zach Wissner-Gross’s Fiddler on the Proof, he mentions the following problem from nearly five years ago, when it was still FiveThirtyEight’s The Riddler:
You are one of finalists in a skiing championship. There are two rounds: in the first round, each finalist skis down the mountain, recording their finishing time; this is repeated in the second round, with the least *total *time for both runs winning the championship. This is the top talent in the world, so the time for every run is independent and identically distributed. Having learned that you have the best time in the first round, what is the probability that you will win the championship? For extra credit, what if 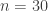 ?
?
In the original problem, the finishing times were normally distributed. The neat feature of this problem is a cocktail-napkin solution for that does not depend on this distribution. However, the extra credit for larger  — for normally distributed run times– appears to require resorting to simulation or approximation, although Josh Silverman provides some really interesting recent asymptotic analysis.
— for normally distributed run times– appears to require resorting to simulation or approximation, although Josh Silverman provides some really interesting recent asymptotic analysis.
The motivation for this post is to capture my notes on the exact solution for any for the case where finishing times are *uniformly *distributed. (This feels to me like a slightly more natural version of the problem, without the unrealistic negative tails.)
Solution
Define random variables  and
and  to be the finishing times for our first and second run, respectively, and similarly define
to be the finishing times for our first and second run, respectively, and similarly define 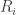 and
and  to be the first and second round times for each competitor
to be the first and second round times for each competitor  . Define event
. Define event  to be
to be  (i.e., we beat competitor
(i.e., we beat competitor  overall) and event
overall) and event 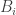 to be
to be  (i.e., we beat competitor in the first round). Then we want to compute the probability
(i.e., we beat competitor in the first round). Then we want to compute the probability

Applying Bayes’ theorem, and re-ordering and re-grouping the intersection of events in the numerator, we have

There are two key observations: first, by symmetry, the probability in the denominator– that we are the leader after the first round– is  . Second, in the numerator, if we condition on fixed times for our two runs, say for example
. Second, in the numerator, if we condition on fixed times for our two runs, say for example  and
and  , then the
, then the  events
events  are independent– so we can multiply them– and they all have the same probability.
are independent– so we can multiply them– and they all have the same probability.
The following figure shows this example situation, where the area of the shaded region is the probability  that we beat a particular competitor in both rounds.
that we beat a particular competitor in both rounds.
This shaded region has two different shapes depending on whether 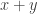 is less than or greater than 1; putting everything together, the desired probability is
is less than or greater than 1; putting everything together, the desired probability is

Applying binomial expansion to the powers and moving the integrals inside the resulting summation gives the following formula:

The figure below shows this probability vs. the number of skiers .
For 5 or 6 skiers, it’s roughly a coin toss whether you retain your first-round lead. When , the probability is about 0.226.