Vector search has dominated conversation in context engineering. Pure similarity searches with vector index work well for proof of concepts but face challenges at scale and in production.
ByteDance discovered this while building a search for over one billion vectors with Apache Doris. Their initial pure vector implementation hit three critical problems: 1) Result accuracy due to semantic confusion, 2) Ranking stability due to database optimization, and 3) Very high memory requirements that balloon the cost. These problems make a pure vector search solution unviable. In this blog, we explore how Bytedance overcame these three challenges with Apache Doris 4.0 to build a cost-effective and performant system handling 1 billion + vectors while also achieving the following benchmarks …
Vector search has dominated conversation in context engineering. Pure similarity searches with vector index work well for proof of concepts but face challenges at scale and in production.
ByteDance discovered this while building a search for over one billion vectors with Apache Doris. Their initial pure vector implementation hit three critical problems: 1) Result accuracy due to semantic confusion, 2) Ranking stability due to database optimization, and 3) Very high memory requirements that balloon the cost. These problems make a pure vector search solution unviable. In this blog, we explore how Bytedance overcame these three challenges with Apache Doris 4.0 to build a cost-effective and performant system handling 1 billion + vectors while also achieving the following benchmarks
- 400ms latency (7× faster than pure vector search)
- 500GB memory (20× less than pure HNSW indexing)
- 89% accuracy (+7 points over pure keyword or vector alone)
- Single server deployment (vs 20-30 servers for sharded vector search)
The Three Problems with Pure Vector Search
Problem 1: Result accuracy due to semantic confusion
Vector search finds vectors with a similar meaning. This becomes a problem when users need exact matches.
Example: A recruiter searches for "Python developers in San Francisco with 5+ years of experience."
Pure vector search returns:
- Candidates in Seattle (semantically similar—both are West Coast tech hubs)
- Missing resumes that say "5 years of Python" (embeddings compress numbers imprecisely)
- Candidates with 2 years of experience who worked on "senior-level projects"
The root cause is that embedding models optimize for semantic similarity, not exact matching. In the embedding space, "San Francisco" and "Seattle" are close neighbors. They share similar contexts in training data—both appear in sentences about tech jobs, startups, and West Coast culture. The number "5" in "5 years" carries little weight compared to the surrounding words.
This matters because business requirements often demand precision. A compliance officer searching for "GDPR Article 17" cannot accept results for "GDPR Article 13"—they are legally different documents. A recruiter filtering by location cannot accept candidates in the wrong city.
Impact: In ByteDance’s testing, pure vector search achieved only 58% relevant results for queries with exact-match requirements.
Problem 2: Ranking stability due to database optimization
A recruiter searches "python developer" on Monday, finds the perfect candidate at position #1, and bookmarks the profile. On Tuesday, she runs the same search to share it with her manager. The candidate now appears at position #8. No new resumes were added. No data changed. The search is "broken."
This is not a rare edge case. It happens routinely in production systems.
Why this happens: Databases split large tables into segments for storage efficiency. A billion-row table becomes 100 segments of 10 million rows each. The problem is that BM25 scoring depends on term statistics—how rare is this word?—and these statistics are calculated per segment.
Consider a concrete example:
| Segment | Total Docs | Docs with "python" | Term Frequency | IDF Score |
|---|---|---|---|---|
| Segment A | 10 million | 50,000 | 0.5% | 2.30 |
| Segment B | 10 million | 80,000 | 0.8% | 2.10 |
The same resume with identical text receives a score of 8.5 in Segment A but 7.9 in Segment B. Where your document lands during ingestion affects its ranking permanently.
The problem compounds over time. Databases merge segments during nightly maintenance for storage optimization. When Segment A and Segment B merge:
- Before merge: Resume X scores 8.5 (in Segment A)
- After merge: Combined segment has different statistics, Resume X now scores 8.1
- Result: Resume X drops from position #1 to position #8
No data changed. The database simply reorganized its internal storage. Users see rankings shuffle and conclude the search is unreliable.
The business impact is severe:
- Lost trust: Users stop relying on search and revert to manual browsing
- Support burden: "Why did my saved search change?" becomes a top ticket category
- Compliance risk: In regulated industries, auditors ask why the same query produces different results
- Multi-tenant leakage: In SaaS platforms, one customer’s document volume can bias another customer’s search scores, a subtle but serious data isolation problem
This instability makes search results feel arbitrary, even when the underlying algorithm is correct.
Problem 3: High memory requirements, high cost
A billion 768-dimension vectors requires significant storage. The standard approach, using HNSW (Hierarchical Navigable Small World) indexing, builds a multi-layer graph structure for fast nearest-neighbor search:
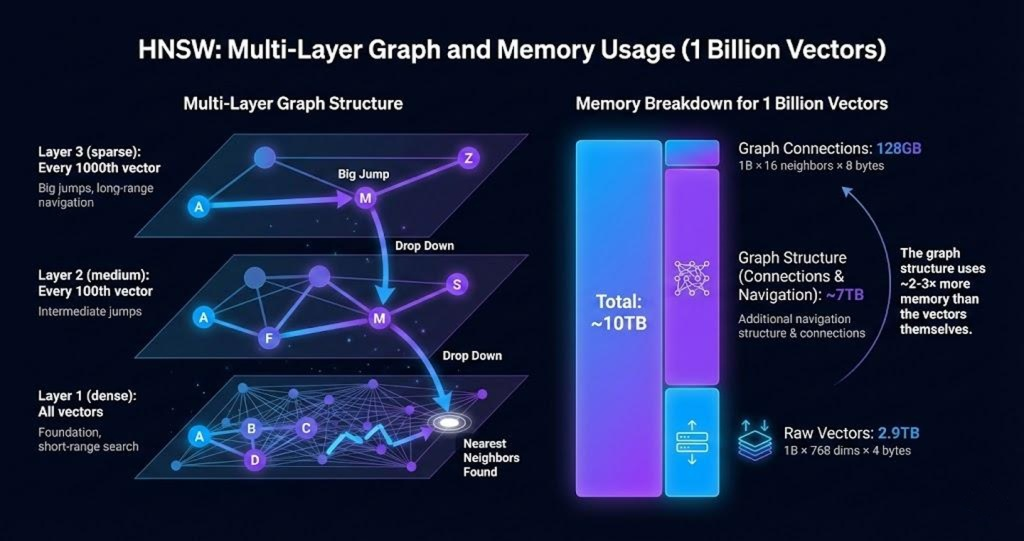
Memory breakdown for 1 billion vectors:
Raw vectors: 1B × 768 dims × 4 bytes = 2.9TB
Graph connections: 1B × 16 neighbors × 8 bytes = 128GB
Multi-layer graph: Navigation structure = ~7TB
Total: ~10TB
Typical production servers have 128GB to 512GB of RAM. Hosting 10TB requires either sharding across 20-30 machines or renting specialized high-memory instances that cost significantly more.
For comparison, a keyword inverted index on the same data requires approximately 50-100GB, 100× smaller than the HNSW index.
Why it matters: Infrastructure cost directly affects whether a feature ships. A 20-server deployment requires budget approval, operational complexity, and cross-team coordination. A single-server deployment ships faster.
How Hybrid Search in Apache Doris Solves Each Problem
Hybrid search with vector search introduced Apache Doris 4.0 addresses these problems through progressive filtering: apply the cheapest operation first, expensive operations last. Each layer reduces the data size before the next step.

Solution to Problem 1: Filter Before Semantic Search
Instead of searching all documents semantically, hybrid search applies structured and keyword filters first.
SELECT candidate_name, resume_text,
bm25_score(resume_text) as keyword_score,
cosine_distance(embedding, query_vec) as vector_score
FROM resumes
WHERE
-- Step 1: Structured filter (B-tree index, ~50ms)
location = 'San Francisco' AND seniority = 'Senior'
-- 100M → 2M candidates
-- Step 2: Keyword filter (inverted index, ~200ms)
AND resume_text MATCH_ANY 'Python'
-- 2M → 15K candidates
-- Step 3: Vector similarity (on filtered set, ~100ms)
AND cosine_distance(embedding, query_vec) < 0.3
-- 15K → 100 candidates
ORDER BY (keyword_score * 0.3 + vector_score * 0.7) DESC
LIMIT 10;
How this solves the problem: The location = 'San Francisco' filter eliminates Seattle candidates before the semantic search runs. The keyword filter ensures "Python" appears literally in the document, no semantic guessing required. Vector search then ranks the most relevant matches within this already-precise subset.
Result: Relevant results increased from 58% to 94% in ByteDance’s testing.
Solution to Problem 2: Calculate Statistics Globally
The ranking instability problem occurs because BM25 calculates term frequencies per segment. ByteDance’s solution: calculate statistics across the entire table before scoring any document.
The approach:
- Before processing segments, execute a pre-scan that visits all segments (~50ms)
- Count total documents (N) and term frequencies (DF) across the entire table
- Cache these global statistics
- Apply the same N and DF values when scoring documents in every segment
How this solves the problem: When every segment uses identical statistics, the same document text produces identical scores regardless of which segment contains it. Segment merges no longer affect rankings because the global counts remain stable.
The tradeoff: Each query requires an additional 50ms pre-scan. This overhead is acceptable because ranking stability directly affects user trust. With this approach, users can now reliably find previously viewed results in the same positions.
Solution to Problem 3: IVPQ Compression Reduces Memory 20×
HNSW uses 10TB because it stores full-precision vectors plus a multi-layer navigation graph. IVPQ (Inverted File + Product Quantization) replaces this with two compression techniques.
Technique 1: Inverted File (Clustering)
Instead of one large graph, IVPQ clusters vectors into groups:
1 billion vectors → 10,000 clusters (via K-means)
Each cluster centroid: [0.12, 0.87, -0.34, ...]
Each cluster contains: ~100,000 similar vectors
Search process:
- Calculate distance from query to 10,000 centroids (fast)
- Select the closest 10 clusters
- Search only within those clusters (10 × 100K = 1M vectors instead of 1B)
This reduces the search space by 1,000×.
Technique 2: Product Quantization (Compression)
Each 768-dimension vector occupies 3,072 bytes (768 × 4 bytes per float). Product quantization compresses this to 8 bytes:
- Split the vector into 8 subvectors (96 dimensions each)
- Train a codebook with 256 entries for each subvector position
- Replace each subvector with its nearest codebook entry ID (1 byte)
Result: 3,072 bytes → 8 bytes (384× compression)
Memory comparison:
| Component | HNSW | IVPQ |
|---|---|---|
| Vectors | 2.9TB | 8GB (compressed) |
| Index structure | 7TB | 400GB |
| Total | ~10TB | ~500GB |
The tradeoff: IVPQ achieves 92% recall compared to HNSW’s 95% recall. This 3% accuracy loss is acceptable given the 20× memory reduction and ability to run on a single server.
Optimization: Skip the Index for Small Result Sets
After filtering, hybrid search often reduces candidates to under 50,000 documents. At this scale, ByteDance discovered that brute-force distance calculation outperforms index lookup.
Why brute force wins on small sets:
20,000 vectors × 768 dimensions × 4 bytes = 61MB of data
Modern CPUs have 30-50MB of L3 cache. Sequential reads through 61MB approach cache efficiency. The CPU prefetches data at 100GB/sec.
Index lookup, by contrast, requires random memory access (jumping between graph nodes) and decompression overhead. Random access is 10× slower than sequential.
Benchmark comparison:
| Approach | Steps | Time |
|---|---|---|
| Index lookup | Decompress → Navigate clusters → Calculate approximate distances | 90ms |
| Brute force | Load 61MB sequentially → Calculate exact distances | 30ms |
Brute force is 3× faster and returns exact distances (no compression error).
Decision rule:
if candidates_remaining < 50,000:
use brute_force() # Faster and more accurate
else:
use_index() # Necessary for large sets
Production Results
ByteDance deployed hybrid search on 1 billion resumes, handling high query volume.
Example query: "Senior ML engineer in Beijing with NLP experience"
Latency Breakdown
| Stage | Operation | Time |
|---|---|---|
| Structured filter | location + seniority | 50ms |
| Keyword search | ML, NLP terms via BM25 | 200ms |
| Vector search | Semantic matching on filtered set | 100ms |
| Reranking | Combine scores | 50ms |
| Total | 400ms (p95) |
Comparison to Alternatives
| Approach | Memory | Servers | Latency | Recall |
|---|---|---|---|---|
| Pure HNSW | 10TB | 20-30 | 2.8s | 95% |
| Hybrid (IVPQ) | 500GB | 1 | 400ms | 92% |
Accuracy by Approach (nDCG@10)
| Approach | Score | Limitation |
|---|---|---|
| Pure keyword | 0.65-0.70 | Misses semantic matches |
| Pure vector | 0.80-0.85 | Misses exact keywords |
| Hybrid | 0.85-0.90 | Best combination |
Summary
For ByteDance, pure vector search fails at billion-scale due to three problems:
- Semantic confusion loses exact matches: "San Francisco" returns Seattle results
- Unstable rankings change when segments merge: users lose trust
- Memory explosion requires 10TB for 1B vectors: needs 20+ servers
ByteDance used hybrid search in Apache Doris to solve each problem:
- Progressive filtering applies exact-match filters before semantic search → 58% to 94% relevance
- Table-level statistics calculate BM25 globally → stable rankings across segment merges
- IVPQ compression reduces memory 20× → single-server deployment
The counter-intuitive insight: hybrid search is not a compromise. It outperforms both keyword and vector approaches individually. Progressive filtering makes vector search faster by shrinking the candidate set. Combining scores makes results more accurate through exact and semantic matching together. Compression makes deployment cheaper with 20× less memory.
For search at billion-scale, hybrid is the standard approach.
Ready to build production-grade search? Start Hybrid Search with VeloDB today.
Further Reading
- BM25: Robertson & Zaragoza (2009): "The Probabilistic Relevance Framework"
- IVPQ: Jégou et al. (2011): "Product Quantization for Nearest Neighbor Search"
- HNSW: Malkov & Yashunin (2018): "Efficient and robust approximate nearest neighbor search"
- Faiss library: https://github.com/facebookresearch/faiss
- BM25 in Apache Doris: https://doris.apache.org/docs/dev/ai/text-search/scoring
Acknowledgments: Thanks to the ByteDance Data Platform team for sharing production metrics from their billion-scale deployment.