![]() Skyulf
Skyulf
Own Your
ML Pipeline Locally.
The privacy-first MLOps workspace. Ingest data, engineer features visually, and train models without your data ever leaving your infrastructure.
Focus on the model, not the infrastructure.
Built for teams who want to focus on models, not glue code.
Visual Canvas
Drag, drop, and connect nodes to clean data and engineer features. No more spaghetti code in notebooks.
Background Training
Run heavy training jobs in the background. Powered by Polars for high-speed processing and Celery for robust task management.
One-Click Deploy
Go from experiment to production instantly. Serve predictions via a built-in REST API.
DATA INGESTION
Load your data.
Keep it…
![]() Skyulf
Skyulf
Own Your
ML Pipeline Locally.
The privacy-first MLOps workspace. Ingest data, engineer features visually, and train models without your data ever leaving your infrastructure.
Focus on the model, not the infrastructure.
Built for teams who want to focus on models, not glue code.
Visual Canvas
Drag, drop, and connect nodes to clean data and engineer features. No more spaghetti code in notebooks.
Background Training
Run heavy training jobs in the background. Powered by Polars for high-speed processing and Celery for robust task management.
One-Click Deploy
Go from experiment to production instantly. Serve predictions via a built-in REST API.
DATA INGESTION
Load your data.
Keep it on your machine.
Import CSV, Parquet, or SQL datasets directly. Powered by Polars, Skyulf auto-detects column types and caches everything for fast, repeatable experiments.
- ** Smart column type detection
- ** Built-in dataset caching
- ** No data leaves your network
EXPLORATORY DATA ANALYSIS
Understand your data.
Before you train.
Automated profiling, outlier detection, and causal discovery. Spot data quality issues instantly with our high-performance Polars-based engine.
- Decision Trees: Extract human-readable rules (e.g., "IF Age > 30...") to find key segments.
- Causal Discovery: Discover hidden cause-effect relationships using the PC Algorithm.
- Decomposition Trees: Interactively drill down into metrics across multiple dimensions.
- Interactive Plots: 3D PCA, Time Series decomposition, and Geospatial maps.
FEATURE ENGINEERING
Stop writing boilerplate.
Start designing pipelines.
The Feature Canvas lets you visualize your data transformations. Handle missing values, encode categories, scale features, and more—all with drag-and-drop nodes.
- ** 25+ Built-in processing nodes
- ** Real-time schema validation
- ** Reproducible pipeline exports
EXPERIMENT TRACKING
Compare runs.
Pick the winner.
Don’t guess which model is better. Track every hyperparameter, metric, and artifact. Visualize performance with interactive charts.
ROC
Curve Analysis
F1
Score Tracking
Acc
Model Accuracy
MAE
Error Metrics
DEPLOYMENT
Test your models
instantly.
Once you’re happy with a model, deploy it to a local inference endpoint. Verify predictions immediately with the built-in JSON editor before moving to production.
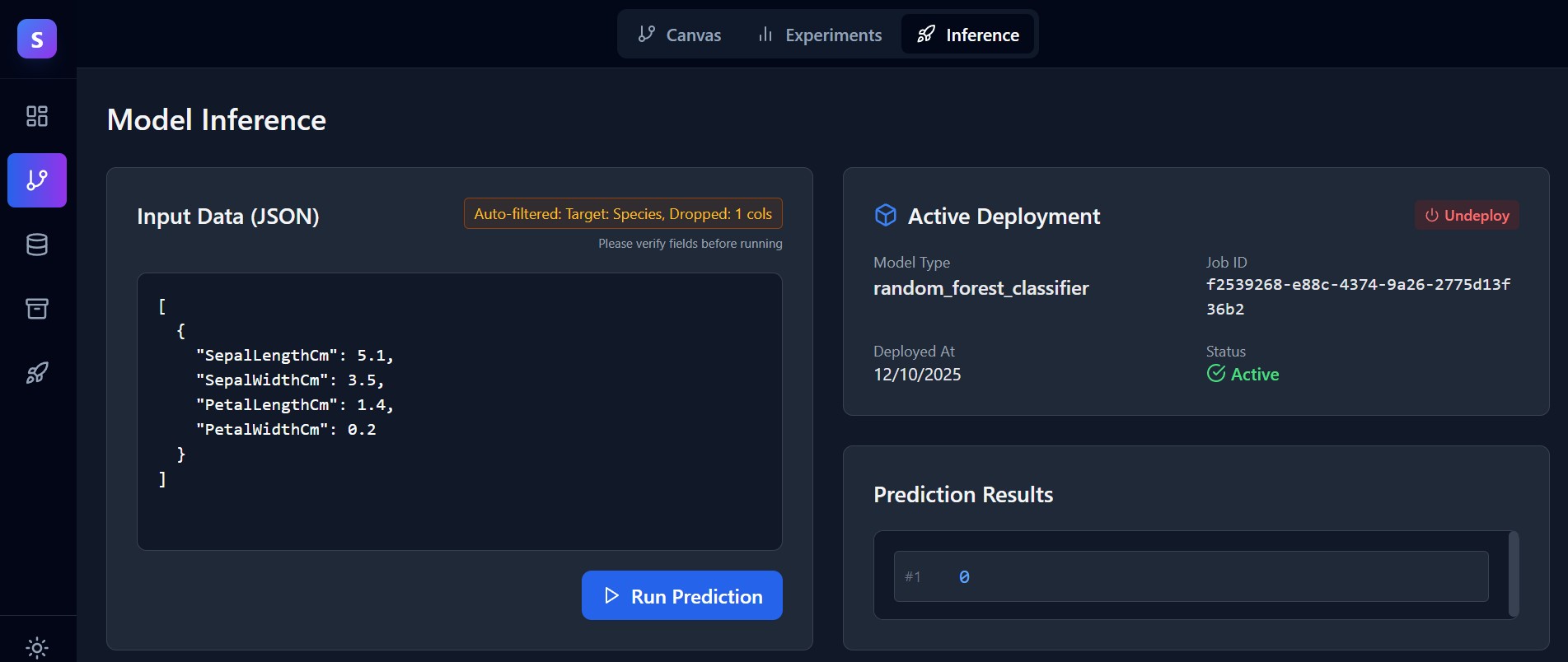
LOCAL INFERENCE
Validate models
before production.
Spin up a local API endpoint to test your model against real data. Debug inputs and outputs in real-time without deploying to a remote environment.
- ** Instant local API endpoints
- ** Interactive JSON request builder
- ** Rapid debugging cycle
MONITORING
Detect Drift.
Maintain Performance.
Continuous monitoring of your deployed models. Detect data drift, concept drift, and prediction anomalies in real-time to ensure model reliability.
- Drift Detection: Automatically compare production data against training baselines.
- Feature Analysis: Visualize distributions to pinpoint exactly which features are drifting.
- Automated Reports: Generate comprehensive HTML reports for stakeholders.
Who is this for?
Teams working with sensitive data who can’t upload to cloud services.
Healthcare & Research
Train models on patient data or research datasets that can’t leave your infrastructure due to GDPR or institutional policies.
- HIPAA and GDPR friendly workflows
- 100% on-premise processing
Government & Public Sector
Municipalities and public institutions working with citizen data that must stay on-premises for privacy and compliance.
- GDPR-compliant processing
- Full audit trails
SMEs & Startups
Small teams who need ML tooling but want to avoid expensive SaaS subscriptions and keep data under their own control.
- Zero-config SQLite start
- No per-user fees
Frequently Asked Questions
Everything you need to know about the platform and how it works.
Product tour
See Skyulf in action
From ingestion to deployment, Skyulf keeps your experiments reproducible and private. Here’s a snapshot of how a local-first team moves from raw data to a deployed model.
1
Load your data
Point to CSV, Parquet, or SQL sources. Schema gets detected automatically.
2
Build your pipeline
Drag nodes around the canvas to wire up transforms. Preview stats at each step.
3
Train & Deploy
Launch training runs in the background. Deploy the best model to a local API.
Powered by modern open source
Ready to build?
Join the local-first MLOps revolution. Open source and free forever for local use.