Calculating Insider, Sniper, DEV, and Top Holder Metrics with VeloDB
Time is money, and in crypto trading and Web3, milliseconds can mean the difference between profits and losses in millions. Real-time data is critical in fast-moving markets like cryptocurrency trading.
For Web3 builders building on-chain analytics platforms, using traditional databases like PostgreSQL often can’t meet the high-throughput writes of blockchain data (5,000-10,000 TPS across multiple chains) and the high-concurrency query demands of real-time dashboards serving thousands of users.
This article walks through how VeloDB, a real-time data warehouse powered by Apache Doris, can help build a real-time on-chain analytics platform. We will discuss how to use VeloDB to calculate critical **on-chain …
Calculating Insider, Sniper, DEV, and Top Holder Metrics with VeloDB
Time is money, and in crypto trading and Web3, milliseconds can mean the difference between profits and losses in millions. Real-time data is critical in fast-moving markets like cryptocurrency trading.
For Web3 builders building on-chain analytics platforms, using traditional databases like PostgreSQL often can’t meet the high-throughput writes of blockchain data (5,000-10,000 TPS across multiple chains) and the high-concurrency query demands of real-time dashboards serving thousands of users.
This article walks through how VeloDB, a real-time data warehouse powered by Apache Doris, can help build a real-time on-chain analytics platform. We will discuss how to use VeloDB to calculate critical on-chain metrics, such as insider wallets, sniping bots, DEV holdings, and top-10 holder concentration, all in real time. We will also provide code for the technical implementation, including schema design, data ingestion, and query optimization, demonstrating how VeloDB achieves millisecond-level latency for vital Web3 analytics.
Key Web3 On-Chain Metrics
1. Insider Wallets: Refers to tokens acquired by project insiders (e.g., developers, early investors) at little to no cost before the token is publicly available on a DEX. A high concentration of insider-held tokens indicates an unfair launch, putting public buyers at an immediate disadvantage. These insiders can dump their tokens at any time, causing a sudden price crash.
2. Sniping Bots: Automated programs that execute buys at the exact moment a token launch occurs, often within the same block, to secure the lowest possible entry price. This bot activity instantly drives up the price, forcing regular users to buy at inflated prices. Snipers typically sell immediately for a quick profit, causing the first major price dump and trapping users who bought the top.
3. Developer (DEV) Holdings: The share of tokens held by the project’s founding or development team. If the DEV’s tokens are locked or subject to a vesting schedule, it signals a long-term commitment. However, if the DEV wallet begins selling tokens shortly after launch, it is a major red flag for a potential rug pull.
4. Top 10 Holders: The percentage of the total token supply held by the top 10 wallet addresses. This metric is a key indicator of decentralization and risk. A low concentration (e.g., <20%) is generally healthier, while a high concentration (e.g., >40%) is a significant risk, as these few holders can easily manipulate the price.
From PostgreSQL to VeloDB: Architecture of Real-Time On-Chain Analytics
Below is a diagram illustrating a traditional, batch-oriented Web3 data processing pipeline:
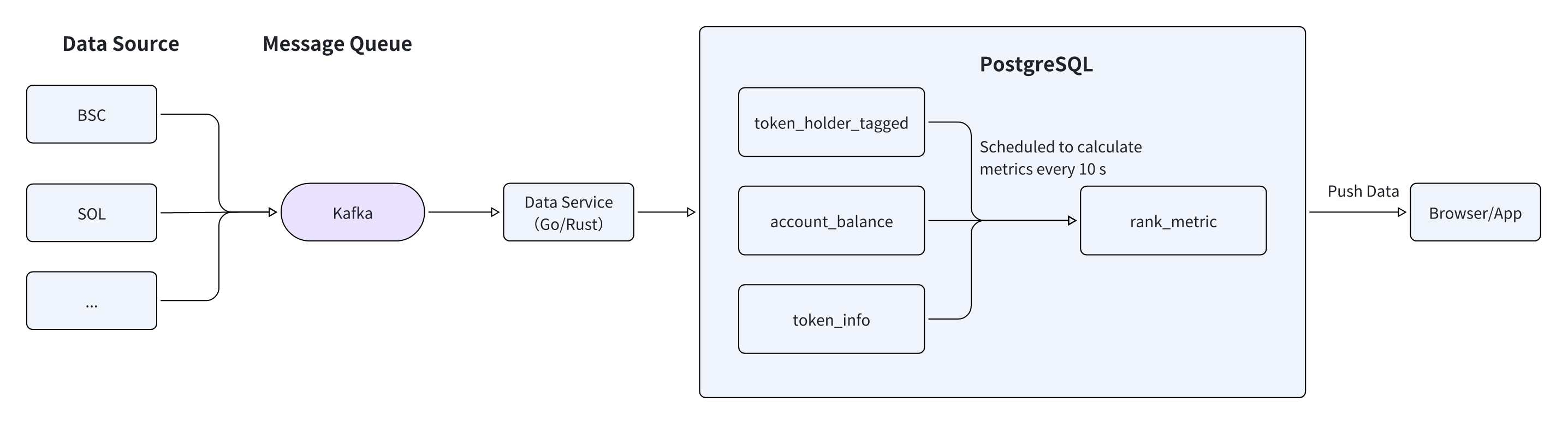
- Raw blockchain transaction data flows from various data sources into Kafka, which acts as a message queue and streaming platform to buffer the high-volume transaction streams.
- The Data Service layer, typically implemented in Go or Rust, consumes messages from Kafka and processes them in scheduled batches (often every 10+ seconds). This service performs initial data transformations and metric calculations before writing the results to PostgreSQL, a traditional relational database that serves as the central data warehouse.
- Finally, the Data Application layer queries PostgreSQL to retrieve the processed metrics and display them to end users through dashboards and interfaces.
This architecture suffers from several drawbacks:
1. Limited Ingestion Throughput: Popular chains like BSC (Binance Smart Chain) and Solana can generate 5,000 to 10,000 transactions per second. When an application needs to monitor 50 or more chains simultaneously, the database becomes a bottleneck, leading to high write latency.
2. Latency in Metric Calculation: Calculating metrics on a 10-second or longer schedule means the data displayed to users is already stale, failing to keep up with fast-moving crypto market movements.
3. Query Concurrency Limitations: Analytics dashboards often serve thousands of concurrent users (QPS). Traditional databases struggle to handle this query load, resulting in slow response times.
The Solution: Build Real-Time, On-Chain Analytics with VeloDB
Below is a diagram illustrating a real-time Web3 data architecture with VeloDB, Kafka, and Redis.
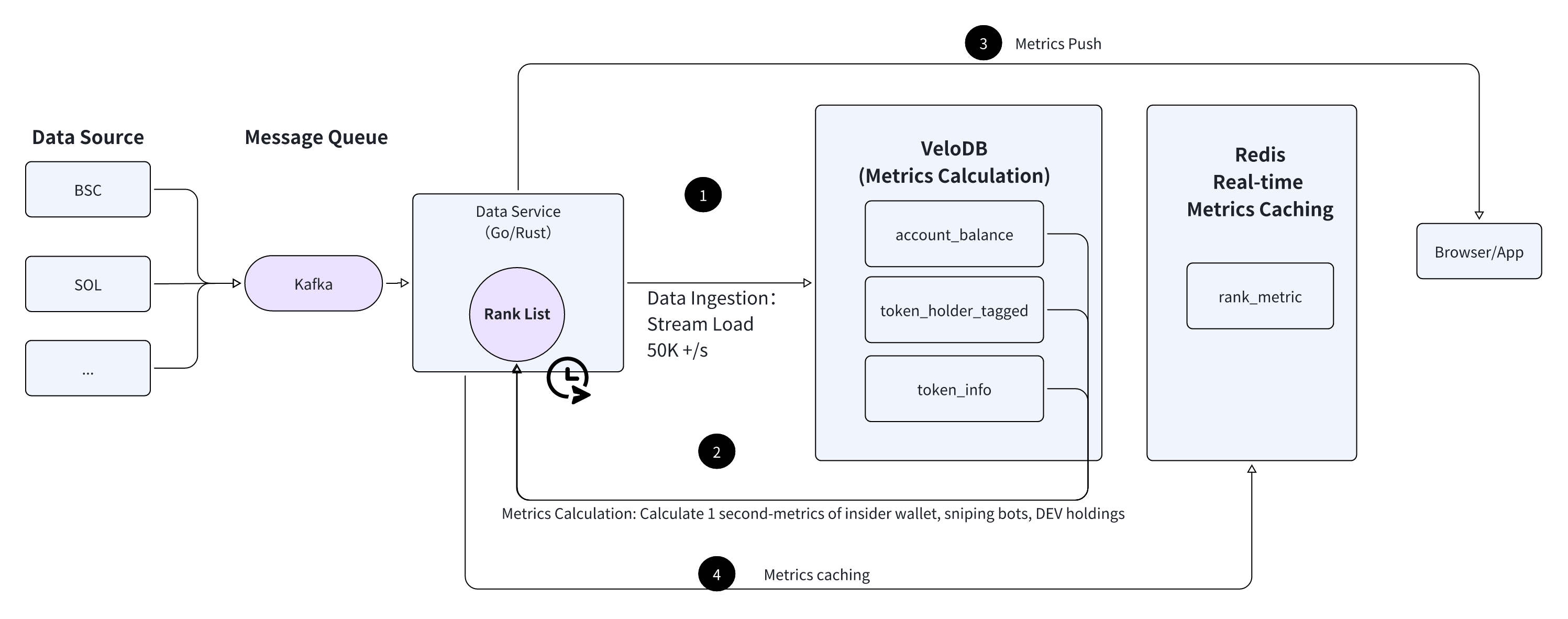
- Blockchain transaction data from multiple chains flows directly into VeloDB through its high-throughput Stream Load capability, which can ingest 50,000+ records per second with write completion in under 500 milliseconds, eliminating the need for intermediate batch processing layers.
- VeloDB serves as both the ingestion engine and the analytical query engine, utilizing advanced features like partitioning, bucketing, inverted indexes, and vectorization to deliver fast concurrent queries.
- The Data Service layer (implemented in Go/Rust) directly queries VeloDB to calculate real-time metrics such as insider holdings, sniper bot activity, DEV concentrations, and top holder distributions, with query responses returning in 50-150ms for point lookups and 0.3-0.5 seconds for batch analytics across 200 tokens.
- These calculated metrics are then pushed to the Data Application frontend for immediate display, with optional caching in Redis for high-traffic API endpoints.
With VeloDB as the core of the real-time data warehouse, this architecture achieves a 1-3 second refresh rate for dashboard metrics compared to the 10+ second delays of traditional systems, while simultaneously handling higher ingestion rates and serving more concurrent users.
In a real-world test on the BSC (Binance Smart Chain), a single VeloDB cluster on an 8-core, 64GB machine easily met the following requirements:
- Ingestion: Supported 5,000 to 50,000 on-chain records written per second.
- Point Queries: Handled over 200 QPS for Top 10 holder calculations and total supply lookups.
- Batch Analytics: Calculated insider, sniper, and DEV metrics for a list of 200 tokens in approximately 1 second.
Tech Implementation
Follow the guides below to see how we implement VeloDB in the real-time, on-chain architecture demonstrated above.
1. Server Configuration
- CPU: 8 Cores
- Memory: 64 GB
2. Database Schema Design
This table, bsc_account_balance, stores the token balance for each holder’s address. For a chain like BSC, this table can grow to over 1.5 billion rows.
CREATE TABLE bsc_account_balance (
token_address VARCHAR NOT NULL, /* Token's contract address */
balance DECIMAL NULL, /* Token balance */
account_address VARCHAR NOT NULL, /* Token holder's wallet address */
balance_block_number BIGINT NULL, /* Block number of the last balance update */
balance_event_id BIGINT NULL, /* Event position within the block */
updated_at DATETIME NULL, /* Timestamp of the write or update */
INDEX idx_token_address (`token_address`) USING INVERTED
)
UNIQUE KEY(`token_address`, `balance`, `account_address`)
DISTRIBUTED BY HASH(`token_address`) BUCKETS 32
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Design Notes:
- We use a
UNIQUE KEYon (token_address,balance,account_address) to prevent duplicate records. - Since all metric analysis is performed at the token level, we use
token_addressas the distribution key for bucketing, which co-locates data for the same token and improves query performance.
This table, bsc_token_holder_tagged_tmp, tags wallet addresses with specific types, such as insider, sniper, or DEV.
CREATE TABLE bsc_token_holder_tagged_tmp (
token VARCHAR NOT NULL, -- Token's contract address
address VARCHAR NOT NULL, -- Holder's wallet address
type INT NULL -- Wallet type: 16=Insider, 19=Sniper, 25=DEV
)
UNIQUE KEY(`token`, `address`)
DISTRIBUTED BY HASH(`token`) BUCKETS 2
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
Design Notes:
- A
UNIQUE KEYensures that each address is tagged only once per token. - The table is also distributed by
tokento align with thebsc_account_balancetable.
Sample Data:
token,address,type
0x89aba1453f58ab08056da973163a67efed95a432,0x0000000000000000000000000000000000000020,16
0x5f1888fd00066394e31861a176cbe067a63a4b47,0x0000000000000000000000000000000000001000,16
0x311ddf4d5fe1a1af170238367eb674352f57f9c3,0x000000000000000000000000000000000000dead,16
This table,token_info, stores metadata for each token, such as total supply.
CREATE TABLE token_info (
token VARCHAR NOT NULL, -- Token's contract address
chain VARCHAR NOT NULL, -- Chain name
total DECIMAL NULL, -- Total supply
burn_amount DECIMAL NULL, -- Burned amount
other_amount DECIMAL NULL
)
UNIQUE KEY(`token`, `chain`)
DISTRIBUTED BY HASH(`token`) BUCKETS 2
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"store_row_column" = "true" -- Enable row storage for high-concurrency point lookups
);
Design Notes:
- To support high-concurrency lookups of total supply, we enable VeloDB’s row storage mode (
"store_row_column" = "true") for this table.
Sample Data:
"token","chain","total","burn_amount","other_amount"
"0xb520507bc8ef26e484c30af84ed9f0f701d054f7","bsc",10000000,0,0
"0xa11ce0a112a0e8c6e3975cdaad1497e45dad2043","bsc",1488000000,0,0
"0x137060dec0bf9636e2410eefc716254c16e35478","bsc",1000000,0,0
3. Real-Time Data Ingestion
VeloDB’s Stream Load feature enables high-throughput data ingestion with sub-second latency. On our 8-core server, we achieved a sustained ingestion rate of over 50,000 records per second, with writes completing in under 1 second. This ensures that our on-chain data is always fresh.
Our stress test shows that 50,000 records inaccount_balancecan be ingested in just 476 milliseconds:
{
"TxnId": 19469353156442112,
"Label": "34afa61b-af63-4c50-9174-c45db4d1b2af",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 50000,
"NumberLoadedRows": 50000,
"LoadBytes": 6119482,
"LoadTimeMs": 476,
"WriteDataTimeMs": 403,
"CommitAndPublishTimeMs": 49
}
4. Real-Time, On-Chain Metric Calculation
A. Total Supply Lookup
The data service performs a simple point lookup to fetch the total supply for a given token. VeloDB can handle tens of thousands of QPS for this type of query with ~100ms latency.
SELECT total FROM token_info WHERE token = '...';
B. Insider, Sniper, and DEV Holder Balance Calculation
For a list of tokens displayed on a dashboard, the data service can calculate the holdings for all three wallet types in a single batch query.
SELECT
a.token_address,
h.type,
SUM(balance)
FROM bsc_account_balance AS a
LEFT JOIN bsc_token_holder_tagged_tmp AS h
ON a.account_address = h.address AND a.token_address = h.token
WHERE a.token_address IN ('0xf4ed363144981d3a65f42e7d0dc54ff9eef559a1', ...)
AND h.type IN (16, 19, 25) -- 16:Insider, 19:Sniper, 25:DEV
GROUP BY a.token_address, h.type;
For a more real-time approach, we can create micro-batches of tokens that have seen recent swap or transfer events and re-calculate their metrics every second.
Our benchmark, using 3 concurrent threads to query 200 tokens (each with ~5,000 holders), returned results in about 0.5 seconds.
Starting concurrent MySQL command execution (max 3)...
Task started: token_address_aa.sql
Task started: token_address_ab.sql
Task started: token_address_ac.sql
real 0m0.489s
user 0m0.000s
sys 0m0.009s
Task started: token_address_ad.sql
The query performance remains fast even as the number of holders per token grows:
| Holders per Token | Tokens Queried | Query Time (s) | Concurrency |
|---|---|---|---|
| 5,000 | 200 | 0.3 ~ 0.5 | 3 |
| 10,000 | 200 | 0.2 ~ 0.4 | 1 |
| 100,000 | 200 | 0.7 ~ 2.0 | 1 |
| 1,000,000 | 1 | 1.5 ~ 2.0 | 1 |
| 2,000,000 | 1 | 2.0 ~ 3.0 | 1 |
| 5,000,000 | 1 | 2.0 ~ 4.0 | 1 |
As the table shows:
- For typical tokens with up to 10,000 holders, VeloDB can query over 200 tokens in under 0.5 seconds, fast enough for real-time dashboards.
- For extremely popular tokens with millions of holders, VeloDB can still calculate the metrics for a single token in 2–4 seconds, which is perfectly acceptable for detailed, on-demand analysis.
+--------------------------------------------+------+----------------------+
| token_address | type | sum(balance) |
+--------------------------------------------+------+----------------------+
| 0x4ae4edc2785260bbfb2f2c5f5da7d71ded4d6666 | 16 | 9345177454.269308744 |
| 0x4ae4edc2785260bbfb2f2c5f5da7d71ded4d6666 | 19 | 738946340.479114142 |
| 0x4ae4edc2785260bbfb2f2c5f5da7d71ded4d6666 | 25 | 66.422247677 |
+--------------------------------------------+------+----------------------+
real 0m2.643s
user 0m0.007s
sys 0m0.000s
C. Top 10 Holder Percentage Calculation
We leverage VeloDB’s fast point queries to calculate the Top 10 holder concentration.
SELECT SUM(balance) / {total_supply}
FROM (
SELECT balance
FROM bsc_account_balance
WHERE token_address = '0x89aba1453f58ab08056da973163a67efed95a432'
ORDER BY balance DESC
LIMIT 10
) AS top_holders;
Using JMeter to simulate 200 concurrent users, we observed an average latency of 50ms ~ 150ms for this query, easily meeting our real-time requirements.
Performance remains strong even for tokens with a large number of holders:
| Holders per Token | Concurrency | Query Time (s) |
|---|---|---|
| 5,000 | 200 | 0.1 |
| 1,000,000 | 1 | 0.25 |
| 2,000,000 | 1 | 0.5 ~ 0.7 |
| 5,000,000 | 1 | 0.7 ~ 1.0 |
5. Final Steps: Aggregation and Push
Finally, the calculated balances for insiders, snipers, DEV, and Top 10 holders are divided by the token’s total supply to get the final percentage metrics. These results are then pushed to the frontend application for display and can also be cached in Redis to serve high-traffic API endpoints.
Conclusion
By leveraging VeloDB, we successfully built a high-performance analytics platform that delivers critical on-chain metrics in near real-time. The combination of high-throughput data ingestion via Stream Load and low-latency, high-concurrency queries enables a user experience that is simply not possible with traditional, batch-oriented data warehouses.
For any Web3 application that requires real-time insights, from DEX dashboards and token monitoring to on-chain wallet profiling, VeloDB provides a powerful and scalable foundation. If you want more details on how to build VeloDB into your Web3 pipeline, contact the VeloDB team.