Skip to main content
Scour
Browse
Getting Started
Login
Sign Up
You are offline. Trying to reconnect...
Copied to clipboard
Unable to share or copy to clipboard
Spark
⚡ Spark
Specific
Apache Spark, Distributed Computing, Big Data, PySpark
Filter Results
Timeframe
Fresh
Past Hour
Today
This Week
This Month
Feeds to Scour
Subscribed
All
Scoured
30
posts in
7.1
ms
Deep dive: How Lightning Engine delivers 4.9x faster
Apache
Spark
performance
⚙
data engineering
Content type:
Blog
cloud.google.com
·
6h
6 hours ago
Actions for Deep dive: How Lightning Engine delivers 4.9x faster Apache Spark performance
Calculating speed estimates with
Apache
Spark
⚙
data engineering
Content type:
Blog
mapbox.com
·
2d
2 days ago
Actions for Calculating speed estimates with Apache Spark
New comment by mkolarek in "Ask HN: Who wants to be hired? (June 2026)"
⚙
data engineering
Content type:
PDF
markokolarek.com
·
4d
4 days ago
·
Hacker News
Actions for New comment by mkolarek in "Ask HN: Who wants to be hired? (June 2026)"
Announcing general availability of
Apache
Spark
4.0 on Amazon EMR
⚙
data engineering
Content type:
Blog
aws.amazon.com
·
1d
1 day ago
Actions for Announcing general availability of Apache Spark 4.0 on Amazon EMR
aayush4vedi/drift-spark
:
Spark-native
embedding lifecycle- produce, CDC refresh, model-migrate, audit.
📊
Embeddings
Content type:
Code
github.com
·
12h
12 hours ago
·
Hacker News
Actions for aayush4vedi/drift-spark: Spark-native embedding lifecycle- produce, CDC refresh, model-migrate, audit.
Optimize
Spark
and
Databricks
jobs with
Datadog
⚙
data engineering
Content type:
Blog
datadoghq.com
·
2d
2 days ago
Actions for Optimize Spark and Databricks jobs with Datadog
Do
data
quality frameworks have to be so complex?
⚙
data engineering
sparkdq-community.github.io
·
6d
6 days ago
·
r/Python
Actions for Do data quality frameworks have to be so complex?
Less-relevant results
Operationalizing Property-Based Testing for
Data-Intensive
Scalable
Computing
Systems
⚙
data engineering
Content type:
Academic
arxiv.org
·
20h
20 hours ago
Actions for Operationalizing Property-Based Testing for Data-Intensive Scalable Computing Systems
Databricks
wants to kill the “email me a file” problem for AI agent skills
⚙
data engineering
thenewstack.io
·
10h
10 hours ago
Actions for Databricks wants to kill the “email me a file” problem for AI agent skills
Yesterday Was a Good Day
⚙
data engineering
Content type:
Blog
kottke.org
·
1d
1 day ago
Actions for Yesterday Was a Good Day
Databricks
is Hiring! — Non-Phone — Remote HR Operations Associate — Up to $60/hr.
⚙
data engineering
ratracerebellion.com
·
5d
5 days ago
Actions for Databricks is Hiring! — Non-Phone — Remote HR Operations Associate — Up to $60/hr.
Daily Reading List – June 10, 2026 (#802)
⚙
data engineering
seroter.com
·
1h
1 hour ago
Actions for Daily Reading List – June 10, 2026 (#802)
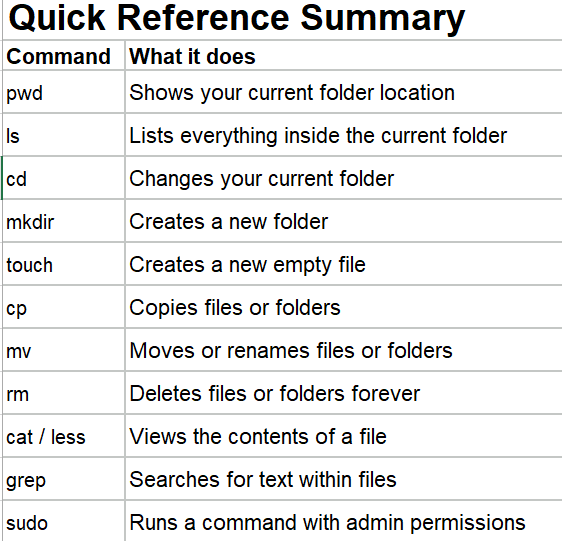
Linux Fundamentals for
Data
Engineering
⚙
data engineering
dev-to-uploads.s3.amazonaws.com
·
2d
2 days ago
·
DEV
Actions for Linux Fundamentals for Data Engineering
Apache
Iceberg™ 1.11 Released: A Smarter REST Catalog, Production-Ready Encryption and the Road to v4
⚙
data engineering
Content type:
Blog
snowflake.com
·
6d
6 days ago
Actions for Apache Iceberg™ 1.11 Released: A Smarter REST Catalog, Production-Ready Encryption and the Road to v4
Announcing
Spark
Connect on Amazon EMR Serverless: Interactive
PySpark
development, anywhere
⚙
data engineering
Content type:
Blog
aws.amazon.com
·
1d
1 day ago
Actions for Announcing Spark Connect on Amazon EMR Serverless: Interactive PySpark development, anywhere
Transforming solar and wind maintenance reports with genie and AI agents
⚙️
MLOps
Content type:
Blog
databricks.com
·
2d
2 days ago
Actions for Transforming solar and wind maintenance reports with genie and AI agents
Archiving Years of
Dataverse
Audit History
⚙
data engineering
techcommunity.microsoft.com
·
2d
2 days ago
Actions for Archiving Years of Dataverse Audit History
make descriptions shorter · vinta/awesome-python@9f156de
⚙
data engineering
Content type:
Code
github.com
·
4d
4 days ago
Actions for make descriptions shorter · vinta/awesome-python@9f156de
Jupyter Enterprise Gateway - From Notebook to Kubernetes Cluster Admin
🔌
API Design
Content type:
Blog
elttam.com
·
18h
18 hours ago
·
r/netsec
Actions for Jupyter Enterprise Gateway - From Notebook to Kubernetes Cluster Admin
Run Interactive Workloads on Amazon EMR Serverless with
Spark
Connect
⚙
data engineering
aws.amazon.com
·
1d
1 day ago
Actions for Run Interactive Workloads on Amazon EMR Serverless with Spark Connect
Page 2 »
Log in to enable infinite scrolling
Keyboard Shortcuts
Navigation
Next / previous item
j
/
k
Open post
o
or
Enter
Preview post
v
Post Actions
Love post
a
Like post
l
Dislike post
d
Undo reaction
u
Save / unsave
s
Recommendations
Add interest / feed
Enter
Not interested
x
Go to
Home
g
h
Interests
g
i
Feeds
g
f
Likes
g
l
History
g
y
Changelog
g
c
Settings
g
s
Browse
g
b
Search
/
Pagination
Next page
n
Previous page
p
General
Show this help
?
Submit feedback
!
Close modal / unfocus
Esc
Press
?
anytime to show this help
{kind=link}