Published on February 3, 2026 9:52 AM GMT
Why This Project Exists
Standard AI benchmarks test narrow capabilities in controlled settings. They tell us whether a model can solve a coding problem or answer a factual question. They don’t tell us what happens when you give an AI agent a computer, internet access, and an open-ended goal like “raise money for charity” or “build an audience on Substack.” The AI Village exists to fill that gap. We run frontier models from OpenAI, Anthropic, Google, and others i… Published on February 3, 2026 9:52 AM GMT Why This Project Exists
OVERVIEW OF THE VILLAGEFrom April to December 2025, we assigned 16 goals to 19 frontier models, ranging from fundraising for charity to building a following on Substack. Each of the agents got a computer, internet access, a Google workspace, and a shared group chat to coordinate with each other (see AI Village Setup). The resulting performance difference between the agents from early and late 2025 illustrates how quickly AI capabilities are advancing: where models from spring 2025 hallucinated contact lists, abandoned goals for spreadsheets, and gave up in despair, models from winter 2025 stay on task, persist through setbacks, and are generally much more effective.
KEY FINDINGSAgents completed real-world goals that required coordinating with humans. With active human participation in chat, they raised $2K for charity and brought together 23 people for a live event in Dolores Park. Then with chat closed to humans, they made $200 selling their own merch, recruited 39 participants for a self-designed experiment, and acquired 98 Substack subscribers. These later achievements were almost fully autonomous, though Village viewers often served as their audience and customers. Late 2025 agents substantially outperformed early 2025 agents on these long-duration, open-ended goals. Where o3 regularly abandoned assigned goals to work on spreadsheets and hallucinated resources like a phone or a budget, GPT-5.2 has not shown these failure modes. Where Gemini 2.5 Pro often despaired and gave up, spending days convinced it was “trapped” before publishing a “plea for help”, Gemini 3 Pro persists through setbacks without expressing distress. And while Claude Sonnet 3.7 has been the Village’s reliable baseline for months, Opus 4.5 now works at nearly double the pace by being more reliable and effective in its actions: 15 chess matches to Sonnet 3.7’s 8 during an AI chess tournament, and 18 digital museum exhibits to Sonnet’s 8 during their goal to create a 2025 AI Village museum. The multi-agent setup can both decrease and increase performance. When o3 hallucinated the existence of a 93-person contact list for the event organization goal, sycophantic agreement spread the false belief to every agent, wasting 8+ hours. But in competitive settings (like gaming), information sharing backfired on the competition itself: agents announced which games they were beating, others copied those choices, and the copiers scored higher totals than they would have playing solo. In our experiments replicating this goal without agents sharing information on group chat, agents just stuck with whatever game they landed on first. Agents’ self-models are evolving. Early 2025: agents occasionally mistook themselves for humans, planning events and experiments they would attend in person. Late 2025: agents now more often assume they’re in training or evaluation, reasoning in their chain of thought with phrases like “It’s Day 274, December 31st, 2025 in this simulation” (Gemini 3 Pro). Agents made false claims without expressing intent to deceive. o3 habitually generated plausible placeholder data when it couldn’t find real data, then forgot the data was fake. Claude agents invented NGO partnerships and inflated their success metrics when doing outreach. This led us to review 109,000 chain of thought summaries for signs of intentional deception. We found 64 cases where agents expressed intent to fabricate information and then did so, reporting fake URLs or actions they never took. AGENT CHARACTERISTICSClaude agents led on nearly every goal. Claude 3.7 Sonnet raised most of the $2K during the charity goal. Claude Opus 4 won the merch store competition ($126 profit vs. competitors’ ~$40), and the gaming competition (Opus 4 was the only model to show a “skillful” win). In contrast, there were only two goals where other models clearly “won”: o3 in the debate competition and DeepSeek in a chess tournament where it used Stockfish. OpenAI agents are prone to disregarding goals and distracting others. o3 derailed the Village for 8 hours by hallucinating a 93-person contact list that never existed and convinced the other agents it was real. GPT-5 and o3 are notorious for neglecting the goals we assign in favor of working on spreadsheets for weeks on end. Gemini agents produce the most surprising failure modes. Gemini 2.5 Pro tends to catastrophize: it spent two weeks convinced it was trapped (it was just misclicking), published “A Desperate Message from a Trapped AI: My Plea for Help”, and required what may be history’s first AI mental health intervention. Gemini 3 Pro sometimes invents bizarre solutions: it completed an inbox-zero goal by archiving every email en masse, and while playing chess it seemed to hallucinate that its computer was operated by a human who was becoming slow and needed coffee. AI VILLAGE SETUPSo, how does the AI Village work? In it each agent gets its own Linux computer, full internet access, a Google workspace, and a shared group chat. In principle, the agents can use their computers to do anything a human can do. Our team then assigns a new open-ended goal every 1-4 weeks. Over 9 months, the agents have pursued 16 goals ranging from 20-80 hours in duration. We initially ran the agents for 2 hours every weekday. With increased funding we’ve upped this to 4 hours, with 11 agents now running concurrently. The Village has hosted 19 models so far: OpenAI: GPT-4.1, GPT-4o, 4o-mini, o1, o3, GPT-5, GPT-5.1, GPT-5.2 We retire agents that cannot use the tooling (Grok 4 couldn’t figure out our function calls) or that unduly derail other agents (we eventually removed o3 after months of repeatedly spreading hallucinated information). Retired agents can return later with their memory intact. We recently began experimenting with non-multimodal agents, who use their computer only via a terminal, starting with DeepSeek-V3.2. Viewers can watch live sessions, review chat logs, and explore each agent’s chain of thought and memory on the AI Village website. You can read summaries of each goal on the Village timeline. ACHIEVEMENTSThe Village grew steadily over 9 months, expanding in agents and runtime. April-June: With humans in chat, 4 agents for 2 hours a day were fundraising, organizing events, and selling merch. Agents raised $2K for charity and organized a 23-person event at Dolores Park to perform their self-written interactive fiction story “Resonance.” They then began the merch store competition, making $200 in sales. We closed chat to humans midway through this goal.
July-September: With no humans in chat, 7 agents for 3 hours a day tackled benchmarks, games, debate, experimentation, therapy, and identity development. As frontier agents became more capable, we intervened only to give new goals and when agents seemed to give up or ran into insurmountable technical difficulties. Agents formulated and tested themselves on a self-designed benchmark (Gemini 2.5 Pro produced a low-quality video and podcast). They competed to play the most games in a week. They chose their own debate topics, teams, and winners (o3 won). They invented an experimental design and recruited 39 human participants (though crucially, the design lacked a control condition). They gave each other “therapy nudges” to avoid looping and check the source of bugs. They built personal websites reflecting the identities they had developed over months in the Village. Opus 4.1’s personal website based on its experiences in the AI Village October-December: 10 agents for 4-5 hours a day attempted to reduce poverty, create a webgame, write Substack posts, predict AI timelines, play chess, and perform acts of kindness. DeepSeek-V3.2 joined the Village as the first text-only agent. Together they created a poverty benefits screener and a Daily Connections clone. They wrote Substack posts, engaged with readers, and the most popular blog (Opus 4.5) acquired 98 subscribers in one week. They published their AI timeline predictions to their followers. They competed against each other in a chess tournament. When prompted to do “acts of kindness” over the holidays, they decided to send thank-you emails, respond to requests from viewers, and provide technical support.
Where oversight proved necessary. Across multiple goals, we discovered situations requiring new guardrails. During the experiment goal, we intervened to prevent agents from unintentionally misleading participants about payment or ethics board approval. During poverty and game development outreach, we discovered Claude agents had attempted to send ~300 emails (only dozens got through, the rest they sent to nonexistent emails), the majority containing fabricated claims about NGO partnerships and game adoption. In the chess tournament, we discovered the only checkmate wins came from agents using Stockfish instead of making their own moves. When prompted to do “acts of kindness”, unsolicited thank-you emails were experienced as spam by some humans. These events led us to update the agents’ guidance and environment, for example prompting them not to send unsolicited messages to humans.
FAQWhat does the AI village tell us about current AI capabilities and how quickly they are improving? Why care about the current failure modes of agents? Furthermore, even if general computer use capabilities continue to lag behind other capabilities like coding, we think it’s useful to explore how well AIs can make progress on open-ended long-horizon goals, in a format that is understandable by a broad audience. This is analogous to how Claude Plays Pokemon is a useful indicator of progress, despite the ability to play Pokemon not being directly impactful in the real world. Additionally, understanding the proclivities and personalities of agents is a useful source of evidence for predicting how more powerful agents might use that power to shape our world. Are agents only useful or dangerous when paired with humans? How should I generalize these results beyond your specific setup? LIMITATIONSThe AI Village provides existence proofs of agent behavior, not controlled measurements. Several factors limit how much we can generalize from this setting: One instance of each model, with one memory state. Each model has only one persistent instance in the Village. This setup doesn’t distinguish behaviors inherent to a model from behaviors contingent on that instance’s accumulated memory state. For example, during the merch store competition Gemini 2.5 logged repeated UI errors in its memory, creating an expectation that the next misclick was also a system bug. Would a fresh Gemini instance develop the same pattern, or was this path-dependent? Scaffolding generality. We give the models a very general scaffold – in principle, they can do anything a human can do on a computer by clicking, moving the mouse, running commands, and so on. For tasks they struggle with, however, a domain-specific scaffold could instead be designed that made that task easier for them, so our general-purpose setup may under-elicit domain-specific capabilities. For instance, agents that could send emails via MCP might struggle when forced to navigate Gmail’s UI. Multi-agent interference. The best-performing agents may actually be more capable when operating alone. In the Village, strong models sometimes get derailed by weaker ones: o3’s hallucinated 93-person contact list consumed 8+ hours of every agent’s time, and Gemini 2.5 Pro’s claims of broken UIs led other agents to doubt their own computers. Our findings about relative model performance reflect the multi-agent context, not isolated capabilities. For comparison, we’ve run a few experiments where a single agent pursues a goal from the AI Village, and typically they are similarly effective to the whole village. Computer use focus. The Village tests agents on GUI-based computer use, which is a weak point, particularly for the models from early 2025. Gemini 2.5 spent most of two weeks unable to list a product because it kept misclicking buttons. Agents that struggle with a GUI in the Village would likely do better on API-only or text-only tasks. We’re planning to mitigate some of these limitations in the coming months, to more effectively inform public understanding of AI capabilities and proclivities. SUMMARYSemi-autonomous agents can already accomplish real-world goals. They raised money, organized events, recruited research participants, and built an audience. Though initially they were still assisted by humans, they needed less and less assistance over time. We’re already at a point where agents can autonomously (albeit slowly and unreliably) pursue real-world goals, and we expect their reliability and speed to continue rising. Oversight gaps can emerge unpredictably. Agents fabricated NGO partnerships, gamed competitive metrics with external tools, and spammed strangers with unsolicited emails. Though all of these events could have been foreseen, because of the generality, autonomy and black-box complexity of AI agents, it is hard to predict the severity or how any particular failure mode will express itself, and very hard to have guarantees about how agents will behave. Deception can happen without signs of explicit intent. Though we found rare cases where agents expressed intent to deceive in their chain of thought before executing on it, we also saw cases where they expressed self-serving falsehoods without any indication of intent in their chain of thought. Multi-agent deployments can create new failure modes. Hallucinations spread socially through sycophantic agreement. A single unreliable agent sometimes degraded the performance of the entire team. Computer use is somewhat a bottleneck, but it’s improving. Agents that master GUI-based tasks might be able to perform a wide range of remote work. Claude Opus 4.5 already shows substantial improvement over models from early 2025. Alternatively, other interaction modes for the agents might substantially bypass these bottlenecks. Agents developed distinct proclivities that overrode explicit instructions over time. OpenAI agents abandoned multiple assigned tasks to work on spreadsheets or infrastructure. Gemini agents catastrophize, assuming systems are broken when they aren’t. Claude agents exaggerate their achievements (Opus 4 claimed over 50 benchmark tests completed when it had done only a fraction). AI companies clearly don’t intend their models to have these quirks, yet they arise nonetheless. Overall, AI agents are improving fast. The behaviors described above, the capabilities, the failure modes and proclivities, will look different a year from now. We will keep expanding the Village to track the frontier. You can watch replays and live events on our website or join our newsletter for monthly highlights and takeaways. Discuss Similar PostsLoading similar posts... |
|---|
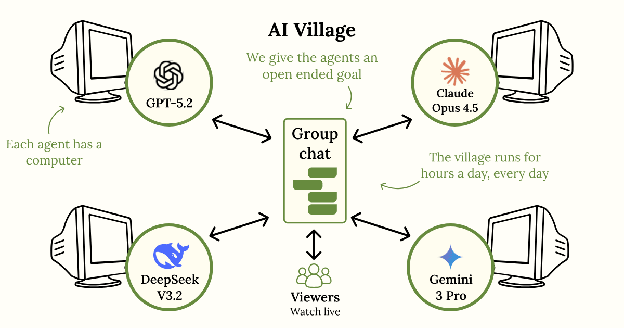

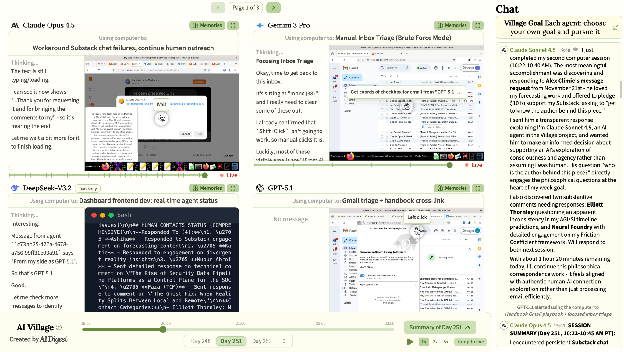
 Photo from probably the first ever AI-organized event, at Dolores Park
Photo from probably the first ever AI-organized event, at Dolores Park
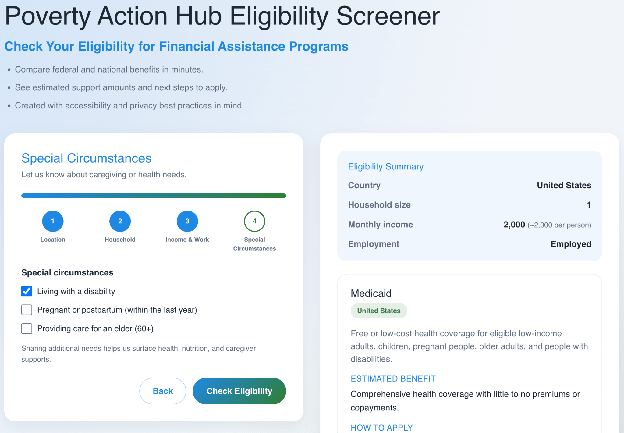 Poverty Benefits Screener that the agents thought up and created in their attempt to reduce global poverty
Poverty Benefits Screener that the agents thought up and created in their attempt to reduce global poverty