July 7, 2025
5 min read
In February 2024, Kong became the first API platform to launch a dedicated AI gateway, designed to bring production-grade performance, observability, and policy enforcement to GenAI workloads.
At its core, Kong’s AI Gateway provides a universal API to enable platform teams to centrally secure and govern traffic to LLMs, AI agents, and MCP servers. Additionally, as AI adoption in your organization begins to skyrocket, so do AI usage costs. With Kong, teams are able to keep their AI costs in check with several techniques, including applying token rate limiting per consumer, caching responses to redundant prompts, and automatically routing requests to the best model…
July 7, 2025
5 min read
In February 2024, Kong became the first API platform to launch a dedicated AI gateway, designed to bring production-grade performance, observability, and policy enforcement to GenAI workloads.
At its core, Kong’s AI Gateway provides a universal API to enable platform teams to centrally secure and govern traffic to LLMs, AI agents, and MCP servers. Additionally, as AI adoption in your organization begins to skyrocket, so do AI usage costs. With Kong, teams are able to keep their AI costs in check with several techniques, including applying token rate limiting per consumer, caching responses to redundant prompts, and automatically routing requests to the best model for the prompt.
In the latest 3.11 release, Kong continues to help customers deliver production-ready GenAI projects with comprehensive support for multi-modal and agentic use cases.
From playground to production: The real test for AI gateways
Experimenting with AI is easy, but when it comes to safely and efficiently rolling out AI projects into production, this is a far greater challenge. Many new AI gateways can handle basic GenAI use cases, but most have never been tested under the demanding, high-throughput conditions enterprises require. Additionally, once your organization begins working with natural language processing (NLP), embeddings, and unstructured data like images, performance isn’t optional — it’s critical.
Kong stands apart by extending its battle-tested API infrastructure to power modern AI workloads. Kong AI Gateway is built on the same highly performant runtime — Kong Gateway — that already supports mission-critical APIs across the world’s largest organizations.
In this blog post, we’ll share performance benchmark results comparing Kong AI Gateway to newer offerings like Portkey and LiteLLM. We’ll walk through the test setup, execution, and what the data reveals about each offering’s performance at scale.
Benchmark architecture
The benchmark tests were executed in AWS. The server infrastructure ran on an Amazon Elastic Kubernetes Service (EKS) cluster, 1.32. In order to have better control over the AI Gateways and remove the native LLM infrastructure variables, such as latency time and throughput, we mocked an LLM with WireMock to expose OpenAI-based endpoints. WireMock is an open-source tool used to simulate API responses.
The AI Gateways were exposed to the consumers through a Network Load Balancer (NLB) to protect them from external interference. Similarly, the mocking LLM was exposed with an NLB. In order to not compete for the same hardware (HW) resources, the AI Gateways and WireMock ran in their own EKS Nodes based on the c5.4xlarge instance type with 16 vCPUs and 32GiB of memory.
Lastly, K6 played the load generator role, running on an EC2 instance deployed in the same VPC as the EKS Cluster.
Here’s a diagram illustrating the benchmark architecture:
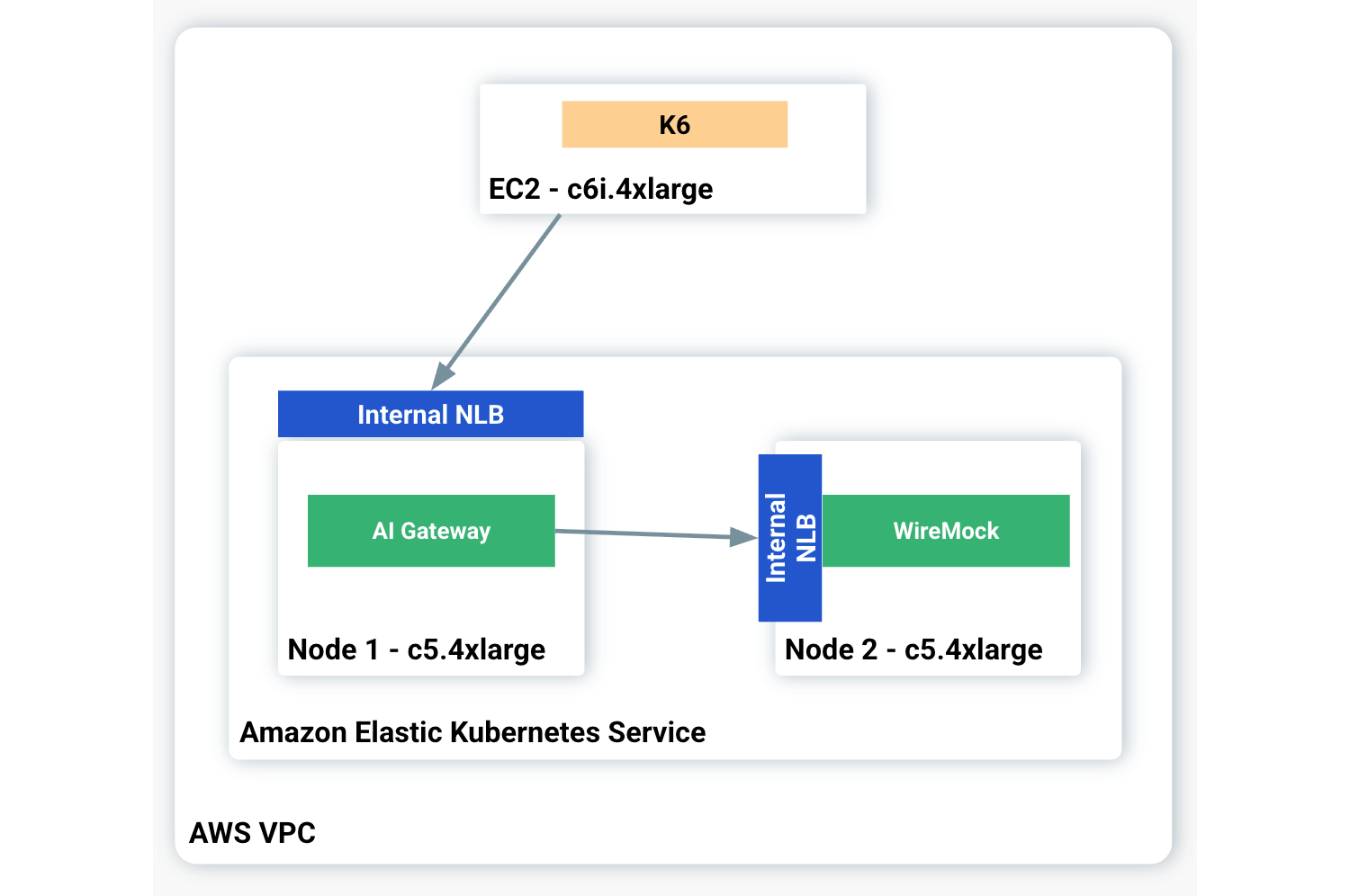
The following versions were used for the benchmark tests:
- Kong Gateway 3.10
- Portkey OSS 1.9.19
- LiteLLM 1.63.7
This Kong’s GitHub repository presents all instructions and artifacts necessary for creating the same environment used in the performance tests.
Baseline
The tests took the WireMock results as the baseline. WireMock was deployed in a single Pod with a configuration to consume all resources available in the EKS Node.
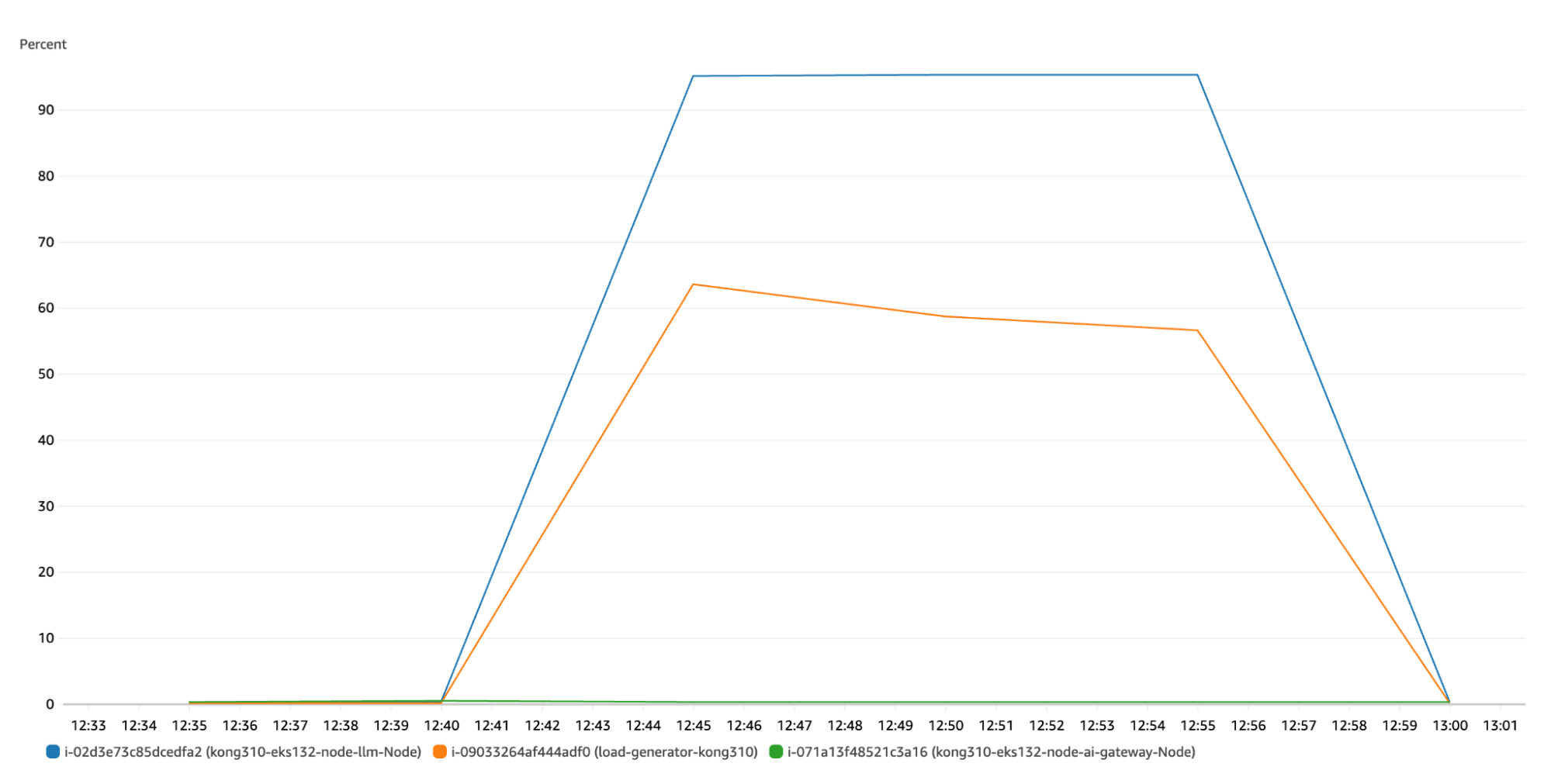
By submitting the WireMock EKS node to the same throughput, we were able to achieve the following results:
- 29005.51 RPS
- P95 of 24.07ms
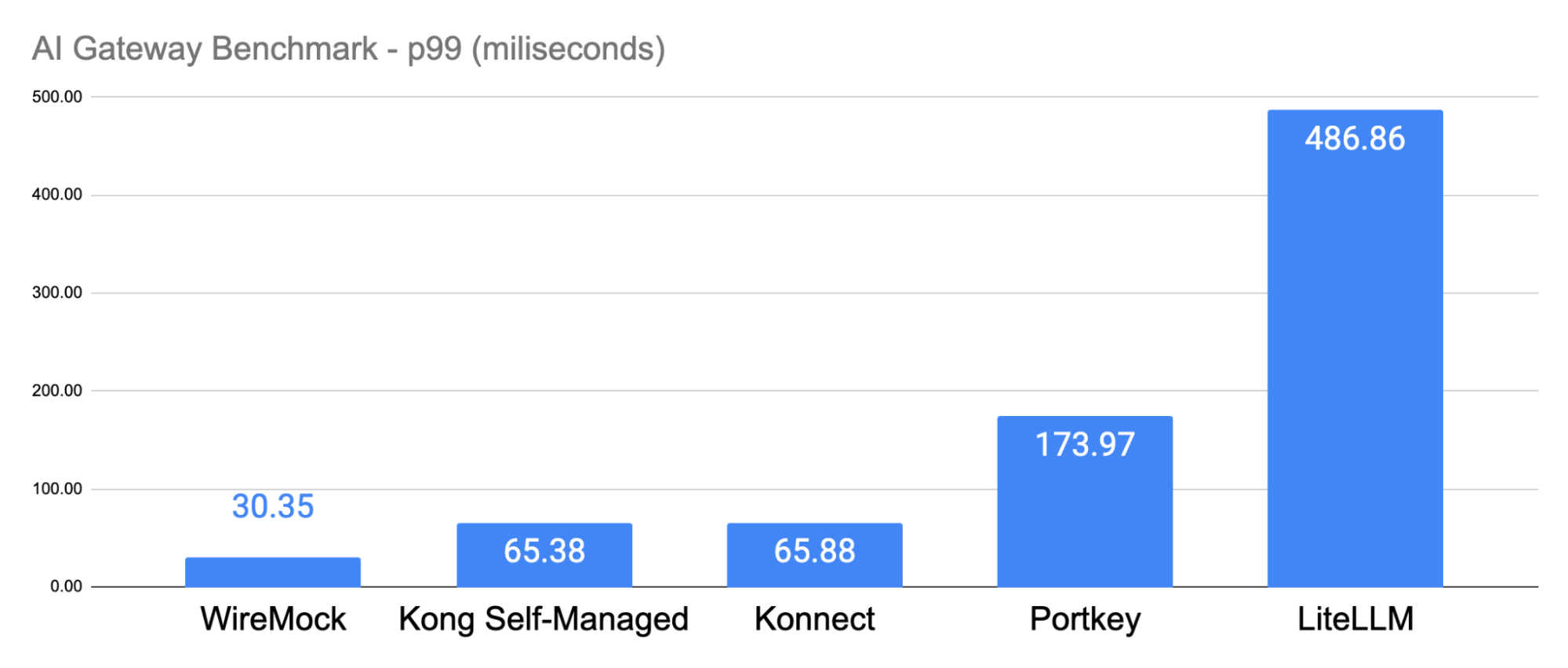
- P99 of 30.35ms
Here’s an AWS CloudWatch picture, during a 10-minute run, showing CPU utilization. The orange line is K6’s EC2 as the blue line is WireMock EKS Node. As you can see, we were able to stress WireMock while K6 still had some resources available. That’s important to make sure that WireMock does not become a bottleneck during the actual AI gateway runs.
AI gateway consumption and policies
The main goal was to compare the AI gateways in similar scenarios consuming the same resources. All deployments had the resource configuration with an upper limit of 12 CPUs.
For the comparison tests, all gateways were configured to play the proxy role only, meaning no policies, like caching or API key-based authentication mechanisms, were configured. As we start adding policies, we expect to see new and different results.
For all benchmark tests, K6 ran for 3 minutes and always injected the same throughput to all AI Gateways with 400 VUs (each VU representing a consumer) sending requests with 1000 prompt tokens.
Requests per second
The benchmark results presented the following results for RPS (requests per second).
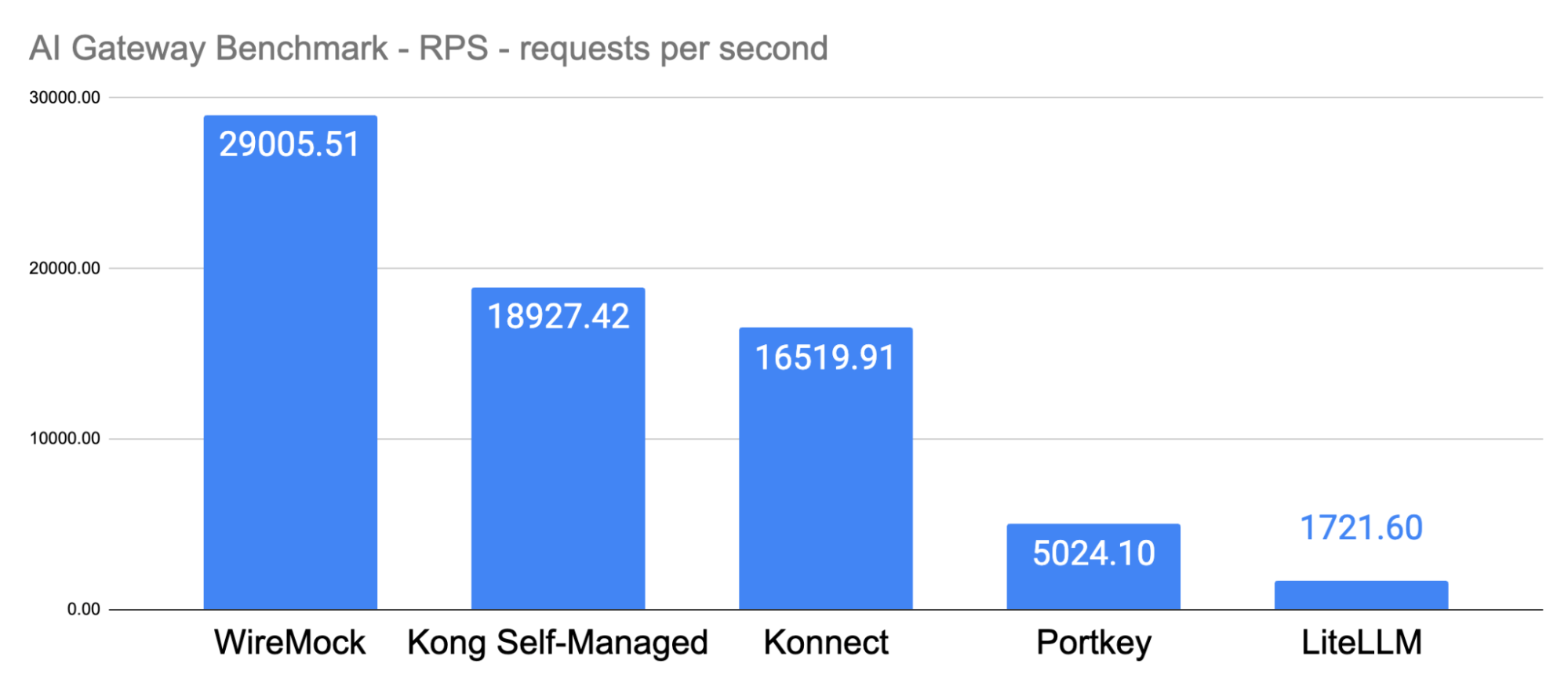
Observations:
-
For Kong, we had two deployments:
-
Self-managed Kong Enterprise, with Control Plane and Data Plane separation, fully deployed in EKS.
-
Kong Data Plane deployed in EKS connected to a Konnect Control Plane running in Kong Cloud.
Kong Konnect Data Planes showed a performance increase of over 200% when compared to PortKey, and over 800% against LiteLLM.
p95 and p99
Here are the p95 latency times:
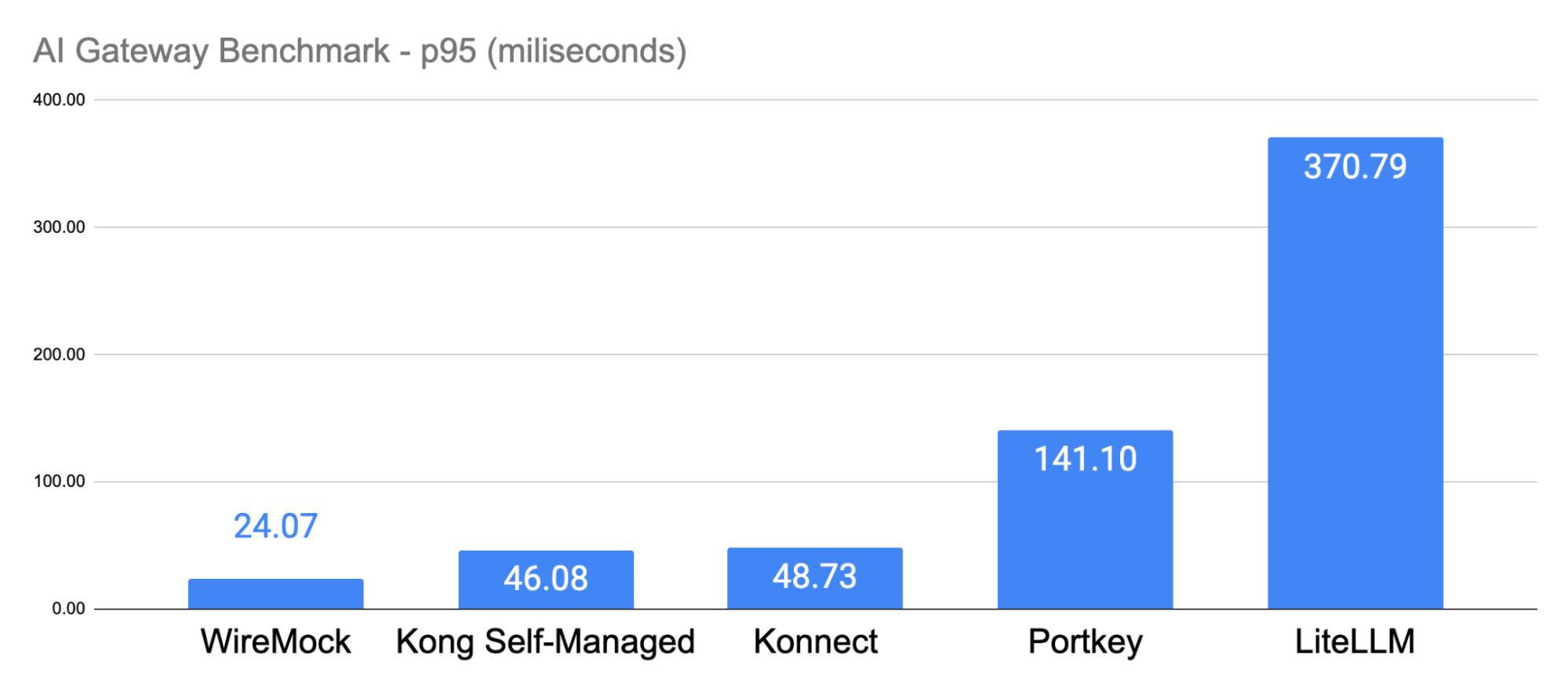
The p99 latency times had proportional similarities:
EKS nodes consumption
For a visual representation of the gateways, here are the CloudWatch screenshots for each one of them during a 10-minute run:
- Orange line: K6’s EC2
- Blue line: WireMock EKS Node
- Green line: AI Gateway EKS Node
The most notable aspect is that Kong was not just able to consume the HW resources provided, but was also capable of stressing the LLM layer implemented by WireMock. The same behaviour was not observed with LiteLLM or Portkey. Note that all AI Gateways, as they had a maximum of 12 CPUs for allocation settings, showed a rate of 70–80% for CPU usage.

Conclusion
This blog post has presented a benchmark scenario comparing Kong AI Gateway with Portkey and LiteLLM.
With all AI Gateways allocating the same amount of 12 CPUs, the results demonstrated that Kong Konnect Data Planes were over 228% faster than Portkey and 859% faster than LiteLLM. At the same time, Kong had 65% lower latency compared to Portkey and 86% lower latency than LiteLLM.
This was a basic comparison where AI Gateway played the proxy role only, with no policies defined to implement Rate Limiting or Authentication, for example.
It’s important to keep in mind that although AI gateways are effective for managing core GenAI use cases, APIs are also a critical part of the equation. APIs are the connective tissue that power agentic workflows. This means that implementing robust API infrastructure is not just important, but that API infrastructure is mission-critical for enabling secure and scalable AI experiences.
Kong is able to unify API and AI management in a single platform, giving platform teams the control, visibility, and automation they need to scale AI-driven workloads. With 100+ enterprise-grade capabilities, teams can apply authentication, token quotas, and observability to LLM traffic, just as they would with APIs. A self-service portal and catalog are also available to enable developers and agents to discover and subscribe to services
Finally, the architectural flexibility of Kong’s infrastructure enables customers to choose between fully self-hosted deployments, hybrid deployments, dedicated cloud gateways, or serverless gateways. All of this can be done within monolithic, microservices, Kubernetes, or multi-cloud environments.
You can discover all the features available on the Kong AI Gateway product page.

Topics
Claudio Acquaviva
Principal Architect, Kong
AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It’s natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
The AI Governance Wake-Up Call
Companies are charging headfirst into AI, with research around agentic AI in the enterprise finding as many as 9 out of 10 organizations are actively working to adopt AI agents. LLMs are being deployed, agentic workflows are getting created left
Taylor Hendricks
Kong AI Gateway and the EU AI Act: Compliance Without the Rewrites
The Requirement : Article 10 of the EU AI Act mandates strict data governance for high-risk AI systems. This includes error detection, bias monitoring, and arguably most critically for enterprise use — ensuring that sensitive personal data (PII) is
Jordi Fernandez Moledo
Streamline AI Usage with Token Rate-Limiting & Tiered Access in Kong
As organizations continue to adopt AI-driven applications, managing usage and costs becomes more critical. Large language models (LLMs), such as those provided by OpenAI, Google, Anthropic, and Mistral, can incur significant expenses when overused.
Jason Matis
Insights from eBay: How API Ecosystems Are Ushering In the Agentic Era
APIs have quietly powered the global shift to an interconnected economy. They’ve served as the data exchange highways behind the seamless experiences we now take for granted — booking a ride, paying a vendor, sending a message, syncing financial rec
Amit Dey
Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva