Share
Introduction
This is the second blog in a two-part series that describes how Uber adopted MySQL® Group Replication to improve MySQL cluster uptime. In the first part, we explored the architectural shift that took place within Uber’s MySQL infrastructure—from a reactive, externally-driven failover system to an internal consensus-based architecture powered by MGR (MySQL Group Replication).
We introduced the concept of a three-node consensus group running in single-primary mode, explained the advantages of Paxos-based elections, and discussed how this setup addresses the core reliability challenges we previously faced.
.
We introduced the concept of a three-node consensus group running in single-primary mode, explained the advantages of Paxos-based elections, and discussed how this setup addresses the core reliability challenges we previously faced.
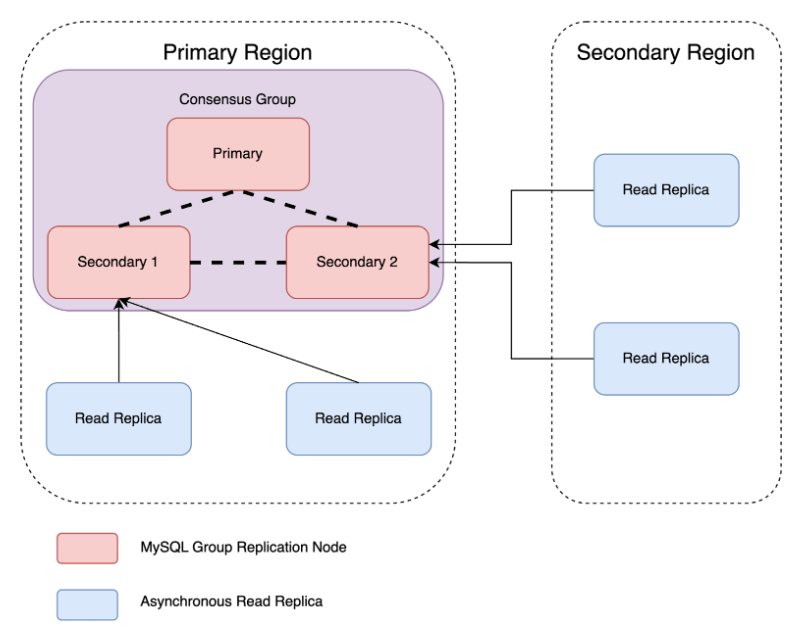 Figure 1: Architecture of a consensus-based MySQL cluster.
Figure 1: Architecture of a consensus-based MySQL cluster.
In this part, we take this story further: How did we build this system in a scalable, operationally sound way? How do we safely onboard and offboard clusters? What happens when a node fails or is replaced?
Let’s dive into the implementation, automation, failover logic, and benchmarking that made MGR viable at Uber’s scale.
Automated Operations: Onboarding, Offboarding, and Rebalancing
To manage these clusters, we developed a control plane that orchestrates all the key operations. These processes are fully automated, allowing us to run a complex, large-scale environment with minimal manual intervention.
Onboarding a Cluster to Consensus
Moving an existing MySQL cluster to the new highly-available setup is a multi-step process. We automated these steps into a workflow, making the onboarding a one-click workflow that follows the standard MGR setup guide.
- Our automated control plane selects a single, healthy node to become the bootstrap node for the new consensus group.
- The other two nodes are then automatically added to the group. These new nodes automatically sync up with the bootstrap node to ensure they have all the data.
- After all three nodes are part of the consensus group and are in a healthy, *ONLINE *state, the original replication process turns off, and the new setup becomes the primary source of truth.
The MGR group has three nodes, and runs with the single primary mode along with the following configurations set:
-
group_replication_paxos_single_leader**: **ON
-
Ensures that MGR runs in single-primary mode.
-
group_replication_member_expel_timeout: 0
-
Controls how soon a suspected member is kicked out of the group.
-
group_replication_unreachable_majority_timeout: 1 second
-
** **Ensures that when a minority of the group is partitioned, they’ll automatically leave the group after 1 second. This setting prevents any split-brain scenarios due to the partitioned members creating a separate group.
Offboarding a Cluster from Consensus
The process of taking a cluster out of the highly available setup is the reverse.
- Our control plane gracefully removes each node from the consensus group one by one, starting with the secondary nodes.
- Once the nodes are out of the group, they’re automatically reconfigured to work in a standard asynchronous replication setup, similar to our previous architecture.
By following this structured workflow approach, we ensure that the process of onboarding/offboarding a node from the consensus group is performed systematically, minimizing disruption and maintaining the integrity of the cluster.
Rebalancing a Consensus Cluster
To maintain optimal performance and stability of our MySQL clusters, we implemented a Rebalance HA Cluster workflow. This workflow ensured that the HA (High Availability) consensus group was always in a steady and stable state by performing these steps:
- **Analyze the current HA consensus state. Evaluate the number of nodes currently running HA consensus and in the ONLINE state.
- Determine the cluster state. Based on the number of online nodes in the consensus group, the workflow identifies the current cluster state and takes appropriate actions.
- Steady state (three nodes). If there are exactly three online nodes in the consensus group, the cluster is considered in a steady state. No action is required.
- Excess nodes (more than three nodes). If there are more than three online nodes in the consensus group, the workflow identifies and offboards one of the secondary nodes. This ensures optimal resource utilization and minimizes potential performance overhead.
- Insufficient nodes (less than 3 nodes). If there are fewer than three online nodes in the consensus group, the workflow identifies a suitable candidate node for onboarding. This action helps maintain the desired level of redundancy and fault tolerance.
- **Replica topology correction. **Evaluate the replication topology of the MySQL cluster and maintain an efficient and balanced replication topology, contributing to the high availability and reliability of our MySQL infrastructure by ensuring the following:
- Verify replication sources. Only the secondary nodes of the consensus group are replicating directly from the primary node of the consensus group. No other members should have a direct replication link to the primary node.
- Balance read replicas. Read replicas should be evenly distributed between the two secondary nodes of the consensus group. This balancing act ensures load distribution, preventing any single node from becoming a bottleneck and enhancing overall system performance.
- Continuous monitoring and action. This trigger conditions for this workflow are evaluated repeatedly within the Technology Controller loop, continuously monitoring the state of the HA consensus.
By taking the appropriate actions based on the consensus group’s analysis, the workflow ensures that the HA consensus state in any MySQL cluster remains balanced, steady, and stable. By implementing this Rebalance HA Cluster workflow, we can dynamically manage the HA consensus group, addressing imbalances promptly and maintaining high availability and reliability of our MySQL clusters.
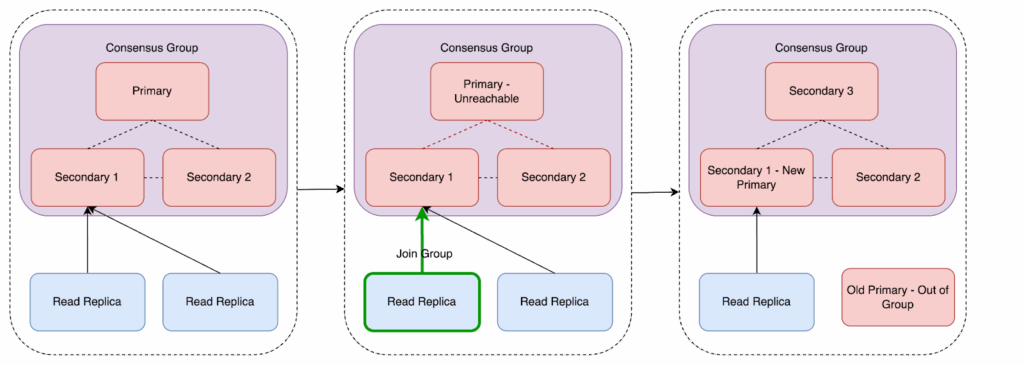 Figure 2: Rebalance consensus cluster workflow.
Figure 2: Rebalance consensus cluster workflow.
One benefit of this workflow is automated cluster management. The workflow automates the process of maintaining an optimal number of nodes within the consensus group, reducing manual intervention and the risk of human error. Another is enhanced fault tolerance. By maintaining a minimum number of nodes in the consensus group, the workflow ensures continued availability in the case of node failures.
Handling Deletion of a Node Running HA Consensus
During the deletion process for a node participating in the HA consensus group, we propose introducing an additional step of calling the offboard node from the consensus workflow before proceeding with the actual deletion. This step ensures data consistency and minimizes disruption to the remaining consensus group members.
The offboard node from HA consensus workflow results in downstream replica repointing and consensus termination. The offboarding process identifies any downstream replica nodes replicating data from the node being deleted. These replicas are then repointed to the primary node of the consensus group. This ensures continued data consistency and availability for replicas, even after the node’s deletion. During consensus termination, the node’s role transitions from participant to replica. This action effectively stops consensus from running on the node.
Once offboarding of the node from consensus completes, the deletion process proceeds as usual for removing a standard replica node from the current setup. This simplifies the overall deletion workflow.
Handling the Replacement of a Node Running HA Consensus
During the graceful replacement of an SOADB MySQL node, the stateful container platform follows a two-step process: first, it adds a new node with the same goal state as the node being replaced, and then it deletes the old node. To manage this transition seamlessly, we implemented the following changes.
We initialize a new node as a read replica in the post-add node hook. Upon adding a new node, the post-add node hook is modified to ensure that the new node comes up as a normal read replica. This step is crucial for maintaining continuity and data consistency.
We also handle the node deletion impact on the HA consensus group. When the old node is deleted, the HA consensus group temporarily has only two ONLINE nodes. This reduction in the number of nodes triggers the Rebalance HA Cluster workflow, which corrects the HA cluster topology by onboarding a suitable node as a participant in the consensus group. This process ensures that the consensus group quickly returns to its optimal state with three ONLINE nodes.
By incorporating these changes, we ensure a smooth and reliable replacement process for SOADB MySQL nodes, while maintaining the stability and availability of the HA consensus group throughout the transition.
During the ungraceful replacement of an SOADB MySQL node, the stateful container platform follows a different sequence: it first deletes the node being replaced and then adds a new node with the same goal state as the deleted node. This process involves the following steps and considerations:
- Node deletion impact. The immediate deletion of the node results in the HA consensus group temporarily having only two ONLINE nodes.
- Automatic cluster rebalancing. Due to the reduction in the number of ONLINE nodes, the Rebalance HA Cluster workflow is triggered. This workflow is designed to quickly address such scenarios. The workflow onboards a suitable node into the HA consensus group, restoring the group to its optimal state of three ONLINE nodes. This ensures that the HA cluster remains stable and resilient.
- New node initialization. With the updated post-add node hook, the replacement node comes up as a normal read replica. This ensures the new node is integrated into the cluster seamlessly, maintaining data consistency and read capacity.
One of the significant advantages of the HA setup is that, if the existing primary leaves the group, whether voluntarily or unexpectedly, a new primary is elected automatically. This mechanism is completely abstracted out by the MySQL Group Replication plugin. Let’s briefly look at the detection of primary failure and the leader election process.
To detect leader failure, all nodes continuously monitor the health of the current primary (leader). Nodes periodically exchange heartbeat messages. If a node fails to receive heartbeats from the primary within a specified timeout period, it considers the primary to have failed.
When a node detects that the primary has failed (missed heartbeats), it triggers the leader election process. The detecting node sends an election message to other nodes in the group to initiate the election process.
The election protocol consists of three phases:
- **Prepare phase. **Nodes that detect the failure may declare themselves as candidates to become the new leader. Each candidate node sends a prepare request to a majority of nodes in the group. Recipient nodes respond to the prepare request. If they haven’t already responded to another candidate, they acknowledge the request and promise not to accept proposals from other candidates for a certain term.
- **Voting phase. **Each node votes for the candidate it received the prepare request from. Nodes can only vote once per election term. The candidate collects votes from a majority of the nodes. If the candidate receives votes from a majority, it becomes the new leader.
- **Leader announcement. **The new leader announces its leadership to the entire group. Nodes acknowledge the new leader and update their internal state to reflect the change. The new leader resumes handling write transactions, and the system returns to normal operation.
Consistency Guarantees During Primary Failover
In a single-primary group, in the event of a primary failover when a secondary is promoted to primary, the new primary can either be made available to application traffic immediately, regardless of how large the replication backlog is, or alternatively, access to it can be restricted until the backlog has been applied.
With the first approach, the group takes the minimum time possible to secure a stable group membership after a primary failure by electing a new primary and then allowing data access immediately while it’s still applying any possible backlog from the old primary. But in this approach, we lose an important consistency guarantee that we discussed above regarding reading from the primary node. The RO transactions should have strict external consistency when reads are initiated on primary.
With the second alternative, the system secures a stable group membership after the primary failure and elects a new primary in the same way as the first alternative, but in this case the group then waits until the new primary applies all backlog and only then does it permit data access. This approach guarantees strict external consistency for RO transactions on primary, but with a minimal loss of availability during promotion.
This is controlled by the parameter group_replication_consistency. The default value is EVENTUAL, which achieves the first approach, sacrificing consistency. We override this default value in our deployment to BEFORE_ON_PRIMARY_FAILOVER to achieve strict external consistency on the primary. BEFORE_ON_PRIMARY_FAILOVER blocks new operations on the primary until all the backlog applies. Group Replication’s flow control mechanism, which minimizes the difference between fast and slow members, reduces the chances of an extended availability loss if it’s activated and properly tuned.
Key Learnings
In our journey to implement MySQL Group Replication at scale, we encountered some important considerations and established key best practices. These learnings are crucial for anyone looking to adopt this technology in a production environment.
Increased Memory Utilization with MGR
One of the first things we noticed when running the MGR plugin was an increase in memory utilization. This is because the plugin maintains a state and buffers transactions in memory before they are applied. While this is a small overhead, it’s an important factor to consider when sizing your database servers. We closely monitor memory usage using the performance schema memory/group_replication instruments, which provides detailed insights into the memory footprint of the plugin. This proactive monitoring helps us ensure our nodes have enough memory to handle peak workloads without performance degradation. You can find more details on this topic in theMySQL documentation on Group Replication memory monitoring.
Being Cautious with group_replication_bootstrap_group
The command SET GLOBAL group_replication_bootstrap_group=ON;** **is a powerful tool for starting a new consensus group. However, using it incorrectly can lead to a dangerous split-brain scenario where two different nodes in the same cluster believe they’re the primary, leading to data inconsistencies and major issues.
To prevent this, we have a very cautious and controlled approach to bootstrapping a group. Our automated workflow follows a strict, two-step decision process:
- Is this the first node? We confirm that the node we’re about to bootstrap is indeed the very first node in the new group and not part of an existing one.
- Does the routing layer confirm this? Our routing layer, which directs traffic to the correct primary, must also confirm that this specific node is the intended primary.
This two-step confirmation process ensures that a bootstrap is only performed when absolutely necessary and that the rest of the system is aware of the change, preventing split-brain scenarios and maintaining the integrity of our data.
Conclusion
Rolling out MySQL Group Replication at scale wasn’t just a technical change—it was a shift in how we think about reliability and operations. With automated workflows for onboarding, rebalancing, and node replacements, we’ve built a system that can take care of itself, recover quickly from failures, and stay stable with minimal manual effort. The automatic leader election ensures that failovers happen fast, and our benchmarking showed that the small performance cost is well worth the big improvements in availability and consistency. Most importantly, this setup has removed the need for engineers to jump in during every failure. The system detects problems, takes action, and recovers—all on its own. As our systems continue to grow, this architecture gives us confidence that our MySQL infrastructure is ready—reliable, scalable, and built to handle real-world demands.
Java and MySQL are registered trademarks of Oracle® and/or its affiliates.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.