Software projects have different evolving needs and requirements. Some have said that software is never finished, merely abandoned. Some software projects are small and others are large with complex integrations. Some have dependencies on external projects, while others are self-contained. Regardless of the size and complexity, the need to validate and ensure functionality remains paramount.
CI/CD pipelines can help with the challenge of building and validating software projects consistently, but, much like the software itself, these pipelines can become complex with many dependencies. This is where ideas like parent-child pipelines and data exchange in CI/CD setups become incredibly important.
…
Software projects have different evolving needs and requirements. Some have said that software is never finished, merely abandoned. Some software projects are small and others are large with complex integrations. Some have dependencies on external projects, while others are self-contained. Regardless of the size and complexity, the need to validate and ensure functionality remains paramount.
CI/CD pipelines can help with the challenge of building and validating software projects consistently, but, much like the software itself, these pipelines can become complex with many dependencies. This is where ideas like parent-child pipelines and data exchange in CI/CD setups become incredibly important.
In this article, we will cover common CI/CD data exchange challenges users may encounter with parent-child pipelines in GitLab — and how to solve them. You’ll learn how to turn complex CI/CD processes into more manageable setups.
Using parent-child pipelines
The pipeline setup in the image below illustrates a scenario where a project could require a large, complex pipeline. The whole project resides in one repository and contains different modules. Each module requires its own set of build and test automation steps.
One approach to address the CI/CD configuration in a scenario like this is to break down the larger pipeline into smaller ones (i.e., child pipelines) and keep a common CI/CD process that is shared across all modules in charge of the whole orchestration (i.e., parent pipeline).
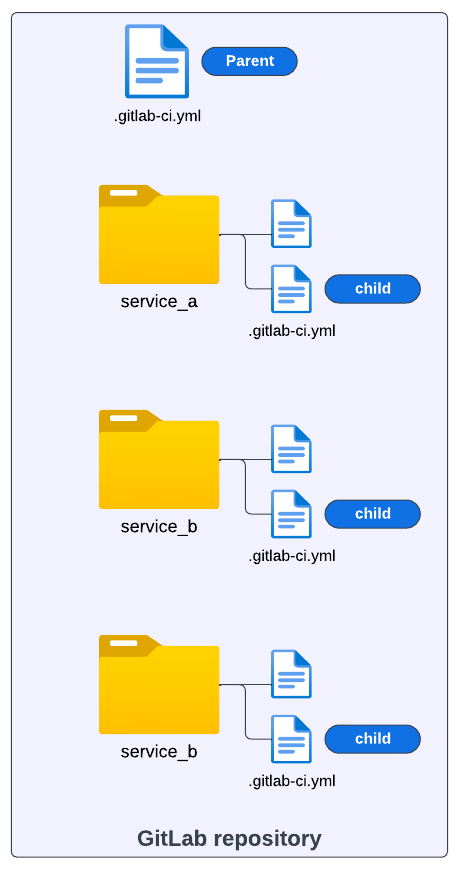
The parent-child pipeline pattern allows a single pipeline to orchestrate one or many downstream pipelines. Similar to how a single pipeline coordinates the execution of multiple jobs, the parent pipeline coordinates the running of full pipelines with one or more jobs.
This pattern has been shown to be helpful in a variety of use cases:
Breaking down large, complex pipelines into smaller, manageable pieces
Conditionally executing certain pipelines as part of a larger CI/CD process
Executing pipelines in parallel
Helping manage user permissions to access and run certain pipelines
GitLab’s current CI/CD structure supports this pattern and makes it simple to implement parent-child pipelines. While there are many benefits when using the parent-child pipeline pattern with GitLab, one question we often get is how to share data between the parent and child pipelines. In the next sections, we’ll go over how to make use of GitLab variables and artifacts to address this concern.
Sharing variables
There are cases where it is necessary to pass the output from a parent pipeline job to a child pipeline. These outputs can be shared as variables, artifacts, and inputs.
Consider a case where we create a custom variable var_1 during the runtime of a job:
stages:
- build
- triggers
# This job only creates a variable
create_var_job:
stage: build
script:
- var_1="Hi, I'm a Parent pipeline variable"
- echo "var_1=$var_1" >> var.env
artifacts:
reports:
dotenv: var.env
Notice that the variable is created as part of the script steps in the job (during runtime). In this example, we are using a simple string "Hi, I'm a Parent pipeline variable" to illustrate the main syntax required to later share this variable with a child pipeline. Let’s break down the create_var_job and analyze the main steps from this GitLab job
First, we need to save var_1 as dotenv:
script:
- var_1="Hi, I'm a pipeline variable"
- echo "var_1=$var_1" >> var.env
After saving var_1 as var.env, the next important step is to make this variable available as an artifact produced by the create_var_job. To do that, we use the following syntax:
artifacts:
reports:
dotenv: var.env
Up to this point, we have created a variable during runtime and saved it as a dotenv report. Now let’s add the job that should trigger the child pipeline:
telco_service_a:
stage: triggers
trigger:
include: service_a/.gitlab-ci.yml
rules:
- changes:
- service_a/*
The goal of telco_service_a job is to find the .gitlab-ci.yml configuration of the child pipeline, which is defined in this case as service_a, and trigger its execution. Let’s examine this job:
telco_service_a:
stage: triggers
trigger:
include: service_a/.gitlab-ci.yml
We see it belongs to another stage of the pipeline named triggers.This job will run only after create_var_job from the first stage successfully finishes and where the variable var_1 we want to pass is created.
After defining the stage, we use the reserved words trigger and include to tell GitLab where to search for the child pipeline configuration, as illustrated in the YAML below:
trigger:
include: service_a/.gitlab-ci.yml
Our child-pipeline YAML configuration is under service_a/.gitlab-ci.yml folder in the GitLab repository, for this example.
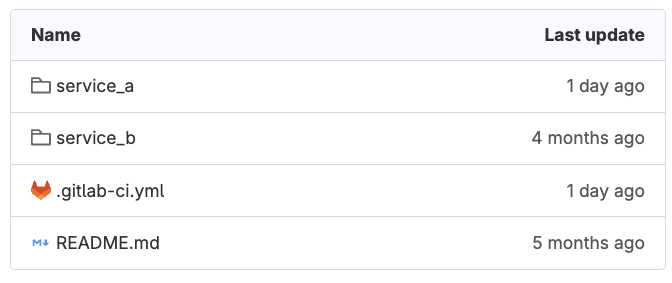
Child pipelines folders with configurations
Take into consideration that the repository structure depicted above can vary. What matters is properly pointing the triggers: include properties at the location of your child-pipeline configuration in your repository.
Finally, we use rules: changes to indicate to GitLab that this child pipeline should be triggered only if there is any change in any file in the service_a/.gitlab-ci.yml directory, as illustrated in the following code snippet:
rules:
- changes:
- service_a/*
Using this rule helps to optimize cost by triggering the child pipeline job only when necessary. This approach is particularly valuable in a monorepo architecture where specific modules contain numerous components, allowing us to avoid running their dedicated pipelines when no changes have been made to their respective codebases.
Configuring the parent pipeline
Up to this point, we have put together our parent pipeline. Here’s the full code snippet for this segment:
# Parent Pipeline Configuration
# This pipeline creates a custom variable and triggers a child pipeline
stages:
- build
- trigger
create_var_job:
stage: build
script:
- var_1="Hi, I'm a Parent pipeline variable"
- echo "var_1=$var_1" >> var.env
artifacts:
reports:
dotenv: var.env
telco_service_a:
stage: triggers
trigger:
include: service_a/.gitlab-ci.yml
rules:
- changes:
- service_a/*
When GitLab executes the YAML configuration in the GitLab UI, the parent pipeline gets rendered as follows:
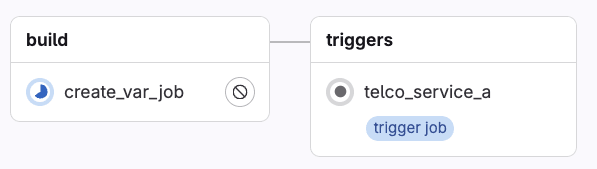
Notice the label “trigger job,” which indicates this job will start the execution of another pipeline configuration.
Configuring the child pipeline
Moving forward, let’s now focus on the child pipeline configuration, where we expect to inherit and print the value of the var_1 created in the parent pipeline.
The pipeline configuration in service_a/.gitlab_ci.yml has the following definition:
stages:
- build
build_a:
stage: build
script:
- echo "this job inherits the variable from the Parent pipeline:"
- echo $var_1
needs:
- project: gitlab-da/use-cases/7-4-parent-child-pipeline
job: create_var_job
ref: main
artifacts: true
Like before, let’s break down this pipeline and highlight the main parts to achieve our goal. This pipeline only contains one stage (i.e., build) and one job (i.e., build_a). The script in the job contains two steps:
build_a:
stage: build
script:
- echo "this job inherits the variable from the Parent pipeline:"
- echo $var_1
These two steps print output during the execution. The most interesting one is the second step, echo $var_1, where we expect to print the variable value inherited from the parent pipeline. Remember, this was a simple string with value: "Hi, I'm a Parent pipeline variable."
Inheriting variables using needs
To set and link this job to inherit variables from the parent pipeline, we use the reserved GitLab CI properties needs as depicted in the following snippet:
needs:
- project: gitlab-da/use-cases/7-4-parent-child-pipeline
job: create_var_job
ref: main
artifacts: true
Using the “needs” keyword, we define dependencies that must be completed before running this job. In this case, we pass four different values. Let’s walk through each one of them:
Project: The complete namespace of the project where the main gitlab-ci.yml containing the parent pipeline YAML is located. Make sure to include the absolute path.
Job: The specific job name in the parent pipeline from where we want to inherit the variable.
Ref: The name of the branch where the main gitlab-ci.yml containing the parent pipeline YAML is located.
Artifacts: Where we set a boolean value, indicating that artifacts from the parent pipeline job should be downloaded and made available to this child pipeline job.
Note: This specific approach using the needs property is only available to GitLab Premium and Ultimate users. We will cover another example for GitLab community users later on.
Putting it all together
Now let’s assume we make a change to any of the files under service_a folder and commit the changes to the repository. When GitLab detects the change, the rule we set up will trigger the child job pipeline execution. This gets displayed in the GitLab UI as follows:
Clicking on the telco_service_a will take us to the jobs in the child pipeline:
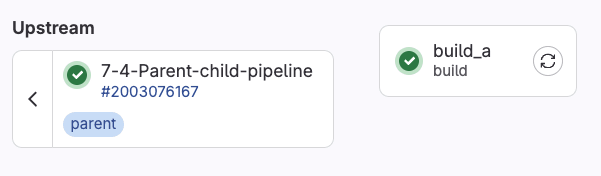
We can see the parent-child relationship, and finally, by clicking on the build_a job, we can visually verify the variable inheritance in the job execution log:
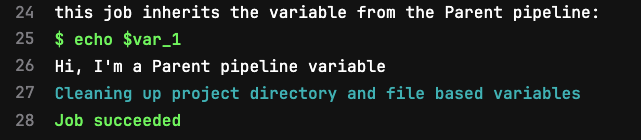
This output confirms the behavior we expected. The custom runtime variable var_1 created in the parent job is inherited in the child job, unpacked from the dotenv report, and its value accessible as can be confirmed in Line 26 above.
This use case illustrates how to share custom variables that can contain any value between pipelines. This example is intentionally simple and can be extrapolated to more realistic scenarios. Take, for instance, the following CI/CD configuration, where the custom variable we need to share is the tag of a Docker image:
# Pipeline
build-prod-image:
tags: [ saas-linux-large-amd64 ]
image: docker:20.10.16
stage: build
services:
- docker:20.10.16-dind
script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker build -t $PRODUCTION_IMAGE .
- docker push $PRODUCTION_IMAGE
- echo "UPSTREAM_CONTAINER_IMAGE=$PRODUCTION_IMAGE" >> prodimage.env
artifacts:
reports:
dotenv: prodimage.env
rules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: always
- when: never
And use the variable with the Docker image tag, in another job that updates a Helm manifest file:
update-helm-values:
stage: update-manifests
image:
name: alpine:3.16
entrypoint: [""]
before_script:
- apk add --no-cache git curl bash yq
- git remote set-url origin https://${CI_USERNAME}:${GITOPS_USER}@${SERVER_PATH}/${PROJECT_PATH}
- git config --global user.email "[email protected]"
- git config --global user.name "GitLab GitOps"
- git pull origin main
script:
- cd src
- echo $UPSTREAM_CONTAINER_IMAGE
- yq eval -i ".spec.template.spec.containers[0].image |= \"$UPSTREAM_CONTAINER_IMAGE\"" store-deployment.yaml
- cat store-deployment.yaml
- git pull origin main
- git checkout -B main
- git commit -am '[skip ci] prod image update'
- git push origin main
needs:
- project: gitlab-da/use-cases/devsecops-platform/simply-find/simply-find-front-end
job: build-prod-image
ref: main
artifacts: true
Mastering how to share variables between pipelines while maintaining the relationship between them enables us to create more sophisticated workflow orchestration that can meet our software building needs.
Using GitLab Package Registry to share artifacts
While the needs feature mentioned above works great for Premium and Ultimate users, GitLab also has features to help achieve similar results for Community Edition users. One suggested approach is to store artifacts in the GitLab Package Registry.
Using a combination of the variables provided in GitLab CI/CD jobs and the GitLab API, you can upload artifacts to the GitLab Package Registry from a parent pipeline. In the child pipeline, you can then access the uploaded artifact from the package registry using the same variables and API to access the artifact. Let’s take a look at the example pipeline and some supplementary scripts that illustrate this:
gitlab-ci.yml (parent pipeline)
# Parent Pipeline Configuration
# This pipeline creates an artifact, uploads it to Package Registry, and triggers a child pipeline
stages:
- create-upload
- trigger
variables:
PACKAGE_NAME: "pipeline-artifacts"
PACKAGE_VERSION: "$CI_PIPELINE_ID"
ARTIFACT_FILE: "artifact.txt"
# Job 1: Create and upload artifact to Package Registry
create-and-upload-artifact:
stage: create-upload
image: alpine:latest
before_script:
- apk add --no-cache curl bash
script:
- bash scripts/create-artifact.sh
- bash scripts/upload-to-registry.sh
rules:
- if: $CI_PIPELINE_SOURCE == "push"
# Job 2: Trigger child pipeline
trigger-child:
stage: trigger
trigger:
include: child-pipeline.yml
strategy: depend
variables:
PARENT_PIPELINE_ID: $CI_PIPELINE_ID
PACKAGE_NAME: $PACKAGE_NAME
PACKAGE_VERSION: $PACKAGE_VERSION
ARTIFACT_FILE: $ARTIFACT_FILE
rules:
- if: $CI_PIPELINE_SOURCE == "push"
child-pipeline.yml
# Child Pipeline Configuration
# This pipeline downloads the artifact from Package Registry and processes it
stages:
- download-process
variables:
# These variables are passed from the parent pipeline
PACKAGE_NAME: "pipeline-artifacts"
PACKAGE_VERSION: "$PARENT_PIPELINE_ID"
ARTIFACT_FILE: "artifact.txt"
# Job 1: Download and process artifact from Package Registry
download-and-process-artifact:
stage: download-process
image: alpine:latest
before_script:
- apk add --no-cache curl bash
script:
- bash scripts/download-from-registry.sh
- echo "Processing downloaded artifact..."
- cat $ARTIFACT_FILE
- echo "Artifact processed successfully!"
upload-to-registry.sh
#!/bin/bash
set -e
# Configuration
PACKAGE_NAME="${PACKAGE_NAME:-pipeline-artifacts}"
PACKAGE_VERSION="${PACKAGE_VERSION:-$CI_PIPELINE_ID}"
ARTIFACT_FILE="${ARTIFACT_FILE:-artifact.txt}"
# Validate required variables
if [ -z "$CI_PROJECT_ID" ]; then
echo "Error: CI_PROJECT_ID is not set"
exit 1
fi
if [ -z "$CI_JOB_TOKEN" ]; then
echo "Error: CI_JOB_TOKEN is not set"
exit 1
fi
if [ -z "$CI_API_V4_URL" ]; then
echo "Error: CI_API_V4_URL is not set"
exit 1
fi
if [ ! -f "$ARTIFACT_FILE" ]; then
echo "Error: Artifact file '$ARTIFACT_FILE' not found"
exit 1
fi
# Construct the upload URL
UPLOAD_URL="${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/${PACKAGE_NAME}/${PACKAGE_VERSION}/${ARTIFACT_FILE}"
# Upload the file using curl
response=$(curl -w "%{http_code}" -o /tmp/upload_response.json \
--header "JOB-TOKEN: $CI_JOB_TOKEN" \
--upload-file "$ARTIFACT_FILE" \
"$UPLOAD_URL")
if [ "$response" -eq 201 ]; then
echo "Upload successful!"
else
echo "Upload failed with HTTP code: $response"
exit 1
fi
download-from-regsitry.sh
#!/bin/bash
set -e
# Configuration
PACKAGE_NAME="${PACKAGE_NAME:-pipeline-artifacts}"
PACKAGE_VERSION="${PACKAGE_VERSION:-$PARENT_PIPELINE_ID}"
ARTIFACT_FILE="${ARTIFACT_FILE:-artifact.txt}"
# Validate required variables
if [ -z "$CI_PROJECT_ID" ]; then
echo "Error: CI_PROJECT_ID is not set"
exit 1
fi
if [ -z "$CI_JOB_TOKEN" ]; then
echo "Error: CI_JOB_TOKEN is not set"
exit 1
fi
if [ -z "$CI_API_V4_URL" ]; then
echo "Error: CI_API_V4_URL is not set"
exit 1
fi
if [ -z "$PACKAGE_VERSION" ]; then
echo "Error: PACKAGE_VERSION is not set"
exit 1
fi
# Construct the download URL
DOWNLOAD_URL="${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/${PACKAGE_NAME}/${PACKAGE_VERSION}/${ARTIFACT_FILE}"
# Download the file using curl
response=$(curl -w "%{http_code}" -o "$ARTIFACT_FILE" \
--header "JOB-TOKEN: $CI_JOB_TOKEN" \
--fail-with-body \
"$DOWNLOAD_URL")
if [ "$response" -eq 200 ]; then
echo "Download successful!"
else
echo "Download failed with HTTP code: $response"
exit 1
fi
In this example, the parent pipeline uploads a file to the GitLab Package Registry by calling a script named upload-to-registry.sh. The script gives the artifact a name and version and constructs the API call to upload the file to the package registry. The parent pipeline is able to authenticate using a $CI_JOB_TOKEN to push the artifact.txt file to the registry.
The child pipeline operates the same as the parent pipeline by using a script to construct the API call to download the artifact.txt file from the package registry. It also is able to authenticate to the registry using the $CI_JOB_TOKEN.
Since the GitLab Package Registry is available to all GitLab users, it helps to serve as a central location for storing and versioning artifacts. It is a great option for users working with many kinds of artifacts and needing to version artifacts for workflows even beyond CI/CD.
Using inputs to pass variables to a child pipeline
If you made it this far in this tutorial, and you have plans to start creating new pipeline configurations, you might want to start by evaluating if your use case can benefit from using inputs to pass variables to other pipelines.
Using inputs is a recommended way to pass variables when you need to define specific values in a CI/CD job and have those values remain fixed during the pipeline run. Inputs might offer certain advantages over the method we implemented before. For example, with inputs, you can include data validation through options (i.e., values must be one of these: [‘staging’, ‘prod’]), variable descriptions, type checking, and assign default values before the pipeline run.
Configuring CI/CD inputs
Consider the following parent pipeline configuration:
# .gitlab-ci.yml (main file)
stages:
- trigger
trigger-staging:
stage: trigger
trigger:
include:
- local: service_a/.gitlab-ci.yml
inputs:
environment: staging
version: "1.0.0"
Let’s zoom in at the main difference between the code snippet above and the previous parent pipeline examples in this tutorial:
trigger:
include:
- local: service_a/.gitlab-ci.yml
inputs:
environment: staging
version: "1.0.0"
The main difference is using the reserved word “inputs”. This part of the YAML configuration can be read in natural language as: “trigger the child pipeline defined in service_a.gitlab-ci.yml and make sure to pass ‘environment: staging’ and ‘version:1.0.0’ as input variables that the child pipeline will know how to use.
Reading CI/CD inputs in child pipelines
Moving to the child pipeline, it must contain in its declaration a spec that defines the inputs it can take. For each input, it is possible to add a little description, a set of predefined options the input value can take, and the type of value it will take. This is illustrated as follows:
# target pipeline or child-pipeline in this case
spec:
inputs:
environment:
description: "Deployment environment"
options: [staging, production]
version:
type: string
description: "Application version"
---
stages:
- deploy
# Jobs that will use the inputs
deploy:
stage: deploy
script:
- echo "Deploying version $[[ inputs.version ]] to $[[ inputs.environment ]]"
Notice from the code snippet that after defining the spec, there is a YAML document separator “—” followed by the actual child pipeline definition where we access the variables $[[ inputs.version ]] and $[[ inputs.environment ]]" from the defined inputs using input interpolation.
Get hands-on with parent-child pipelines, artifacts, and more
We hope this article has helped with navigating the challenge of sharing variables and artifacts in parent-child pipeline setups.
To try these examples for yourself, feel free to view or fork the Premium/Ultimate and the GitLab Package Registry examples of sharing artifacts.
You can also sign up for a 30-day free trial of GitLab Ultimate to experience all the features GitLab has to offer. Thanks for reading!