Previously: Models of (Dependent) Type Theory.
There is a deep connection between mathematics and programming. Computer programs deal with such mathematical objects as numbers, vectors, monoids, functors, algebras, and many more. We can implement such structures in most programming languages. For instance, here’s the definition of natural numbers in Haskell:
data Nat where
Z :: Nat -- zero
S :: Nat -> Nat -- successor
There is a problem, though, with encoding the laws that they are supposed to obey. These laws are expressed using equalities. But not or equalities are created equal. Take, for instance, this definition of addition:
plus :: Nat -> Nat -> Nat
plus Z n = n
plus (S n...Previously: Models of (Dependent) Type Theory.
There is a deep connection between mathematics and programming. Computer programs deal with such mathematical objects as numbers, vectors, monoids, functors, algebras, and many more. We can implement such structures in most programming languages. For instance, here’s the definition of natural numbers in Haskell:
data Nat where
Z :: Nat -- zero
S :: Nat -> Nat -- successor
There is a problem, though, with encoding the laws that they are supposed to obey. These laws are expressed using equalities. But not or equalities are created equal. Take, for instance, this definition of addition:
plus :: Nat -> Nat -> Nat
plus Z n = n
plus (S n) m = S (plus n m)
The first clause tells us that 


In traditional mathematics equality is treated as a relation. Two things are either equal or not. In type theory, on the other hand, equality is a type. It’s a type of proofs of equality. When you postulate that two things are equal, you specify the type of proofs that you are willing to accept.
Equality is a dependent type, because it depends on the values that are being compared. For a pair of values of the type 


(In this notation, assumptions are listed above the horizontal line.)
You’ll also see 


When two values are not equal, this type is uninhabited. Otherwise it’s inhabited by proofs, or witnesses, of equality. This is consistent with the propositions as types interpretation of type theory.
For the identity type to be useful, we have to have a way to populate it with values — proofs of equality. We do that by providing an introduction rule:

The constructor 


At first sight it doesn’t seem like we have gained anything by turning equality into a type. Indeed, if 
But first, let’s consider the identity elimination rule: the mapping out of the identity type. What data do we need to provide in order to define a function from a path 
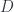


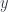

Our goal is to define a 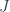

The trick is to realize that there is only one family of constructors of the identity type, 


This is very similar to constructing a mapping out of a Boolean by specifying its action on the two constructors, 

This is enough information to uniquely determine the action of

This procedure for defining mappings out of identity types is called path induction.
Categorical Model
We’ll build a categorical interpretation of identity types making as few assumptions as possible. We’ll model

The introduction rule asserts the existence of the arrow:

For any given 

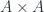
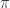


In other words, there is a factorization of the diagonal arrow.
The elimination rule starts with defining a dependent type 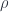

We provide a dependent function 



Given these assumptions, there exists a mapping:

which is interpreted as a section 

This mapping is unique if we assume that it agrees with

Consequently, we can illustrate the path induction rule using a single commuting diagram:
If the outer square commutes then there is a unique diagonal arrow that makes the two triangles commute. The similarity to the lifting property of homotopy theory is not accidental, as we’ll see next.
Next: Modeling Identity Types.