Claude Code fundamentally changed how developers work. But it’s not just about writing code.
It’s about having an agent that can:
- Search precisely – ripgrep through thousands of files, no embeddings needed
- Think deeply – Claude’s reasoning applied to real data
- Generate code on demand – Python for Excel analysis, data visualization, complex computations
We saw this and thought: Office workers need the same capabilities.
Sales teams drown in meeting notes. Product managers search through scattered docs. The core insight is this: the goal is not to automate tasks, but to amplify human creativity. By handling the repetitive groundwork, the agent frees office workers to focus on what they do best—strategizing, innovating, and making meaningful decisions.
They don’t…
Claude Code fundamentally changed how developers work. But it’s not just about writing code.
It’s about having an agent that can:
- Search precisely – ripgrep through thousands of files, no embeddings needed
- Think deeply – Claude’s reasoning applied to real data
- Generate code on demand – Python for Excel analysis, data visualization, complex computations
We saw this and thought: Office workers need the same capabilities.
Sales teams drown in meeting notes. Product managers search through scattered docs. The core insight is this: the goal is not to automate tasks, but to amplify human creativity. By handling the repetitive groundwork, the agent frees office workers to focus on what they do best—strategizing, innovating, and making meaningful decisions.
They don’t need to write code. They need an agent that can search their team’s knowledge base with precision, think through complex problems, and deliver finished work.
The catch: Office work is collaborative. Claude Code works great for solo developers. But teams need shared context – the same files, same search results, same source of truth.
And it needs to work for multiple organizations simultaneously. Multi-tenant SaaS where each company has hundreds or thousands of employees.
So we spent 3 months building the infrastructure to bring Claude Code’s agentic capabilities to teams. Same intelligence. Built for multi-tenant collaboration.
The technical challenge: making this work at scale – multiple organizations, each with 1000+ office workers, all sharing the same infrastructure securely.
Here’s how we did it.
The core problem
Claude Code’s power comes from three things:
Agentic search: No embeddings. No indexes. The agent uses ripgrep, blob, find – actual file system tools. When you have 100,000 documents, you don’t need to build and maintain indexes. Just search.
Deep reasoning: Claude can think through complex problems with full context, not just answer surface-level questions.
Code generation for analysis: Need to analyze Excel data? The agent writes Python code on the fly. Deep analysis without manual work.

In the cloud for multiple organizations? All three become challenges.
File system access: Office workers need the same search quality developers get. ripgrep works when you have a real file system. Most cloud storage doesn’t support this.
Context retention: Office workers have conversations that span days. Where does that context live when containers are ephemeral?
Scale + Multi-tenancy: Not just supporting users – supporting multiple organizations, each with hundreds or thousands of employees. Each org needs isolated data, shared team workspaces, and independent security boundaries. All on shared infrastructure.
What we built
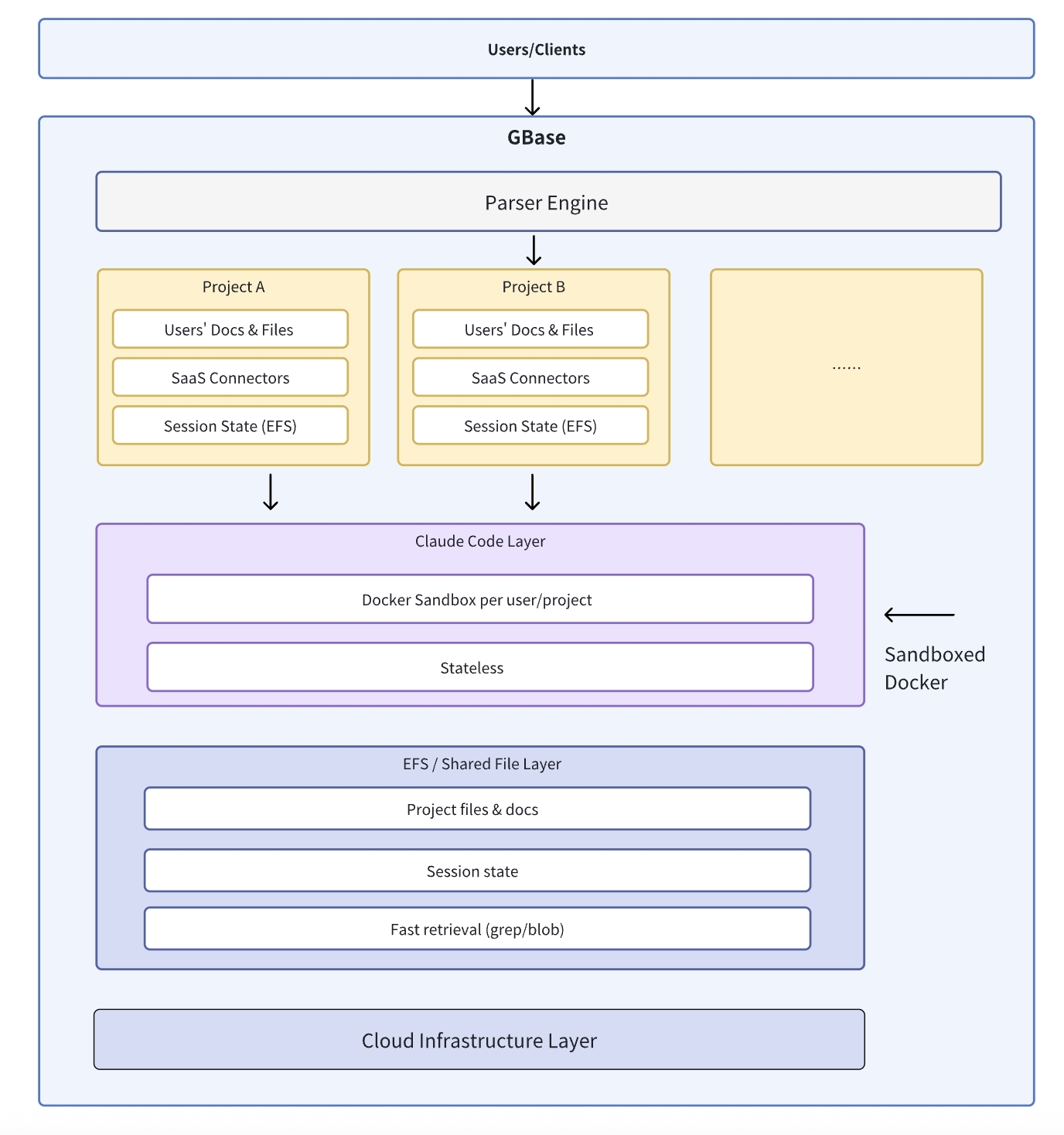
Docker sandboxes (the multi-tenant foundation)
Each user gets an isolated container. This is how we achieve true multi-tenancy – hundreds of organizations, thousands of users, all running on shared infrastructure with complete data isolation.
Current setup:
- Rootless containers for security
- cgroups v2 for CPU/memory limits
- Network policies: deny-all by default
- Per-organization + per-user isolation
- Ephemeral containers that die after use
Fast container spawning lets us handle burst traffic across multiple organizations simultaneously.
The key: Users never see the technical details. They just ask questions and get insights. The agent handles the complexity behind the scenes. And organizations never see each other’s data.
EFS: The multi-tenant collaboration breakthrough
This is what made everything click. We needed shared file systems that support Claude Code’s agentic search tools – ripgrep, blob, find, grep.
The architecture:
Each organization gets isolated workspaces on EFS. Within each org, teams can share projects. But Org A never sees Org B’s data.
Org A, Team Sales ─┐
├─→ EFS: /org-a/project-acme/
Org A, Team PM ────┘
Org B, Team Sales ─┐
├─→ EFS: /org-b/project-beta/
Org B, Team Eng ───┘
AWS EFS gives us POSIX-compliant file systems that any container can mount. Multi-tenant by design.
Why this is important? When a sales rep asks “show me all pricing discussions with Acme Corp”, Claude Code uses ripgrep to search their org’s workspace. No embeddings. No indexes to build or maintain. Just direct file system search.
Have 100,000 documents? No problem. The agent searches them as they are. Documents updated? No re-indexing needed.
The bonus: The agent can generate Python code to analyze Excel files deeply. Not just read them – actually compute, visualize, find patterns.
Performance: Low latency for reads, high throughput. Cost scales per-org, which is significant but this approach is fundamentally simpler than managing embeddings at scale.
S3 or traditional databases don’t support this kind of file system access that Claude Code needs.
Stateless containers
Here’s where it gets clever: The containers themselves store nothing.
All state lives in:
- EFS: Organization workspaces (isolated per org)
- PostgreSQL: Conversation history (partitioned by org)
- Redis: Active sessions
When a request comes in:
- Any container can handle any organization’s request
- Mount that org’s EFS workspace
- Load conversation history from their partition
- Execute, write to their isolated workspace
- Kill container
This means:
- Linear horizontal scaling across all organizations
- No org-specific infrastructure (true multi-tenancy)
- Teams see changes in real-time within their org
- Complete data isolation between orgs
Document parsing
Built our own parser using multimodal models when needed. This gives us much higher quality than off-the-shelf tools.
Key insight: Convert everything to text optimized for Claude Code’s text-based search. PDFs, Word, Excel, PowerPoint – all become searchable text that ripgrep can find instantly.
Multimodal models handle complex layouts, tables, charts. The output is clean text that preserves structure and meaning.
Result: A query for “Q3 revenue by region” retrieves the right content, whether it’s in a PDF report, Excel sheet, or PowerPoint slide.
The product: Meeting intelligence
Claude Code disrupted programming with precise search and deep reasoning. We’re applying that to office work.
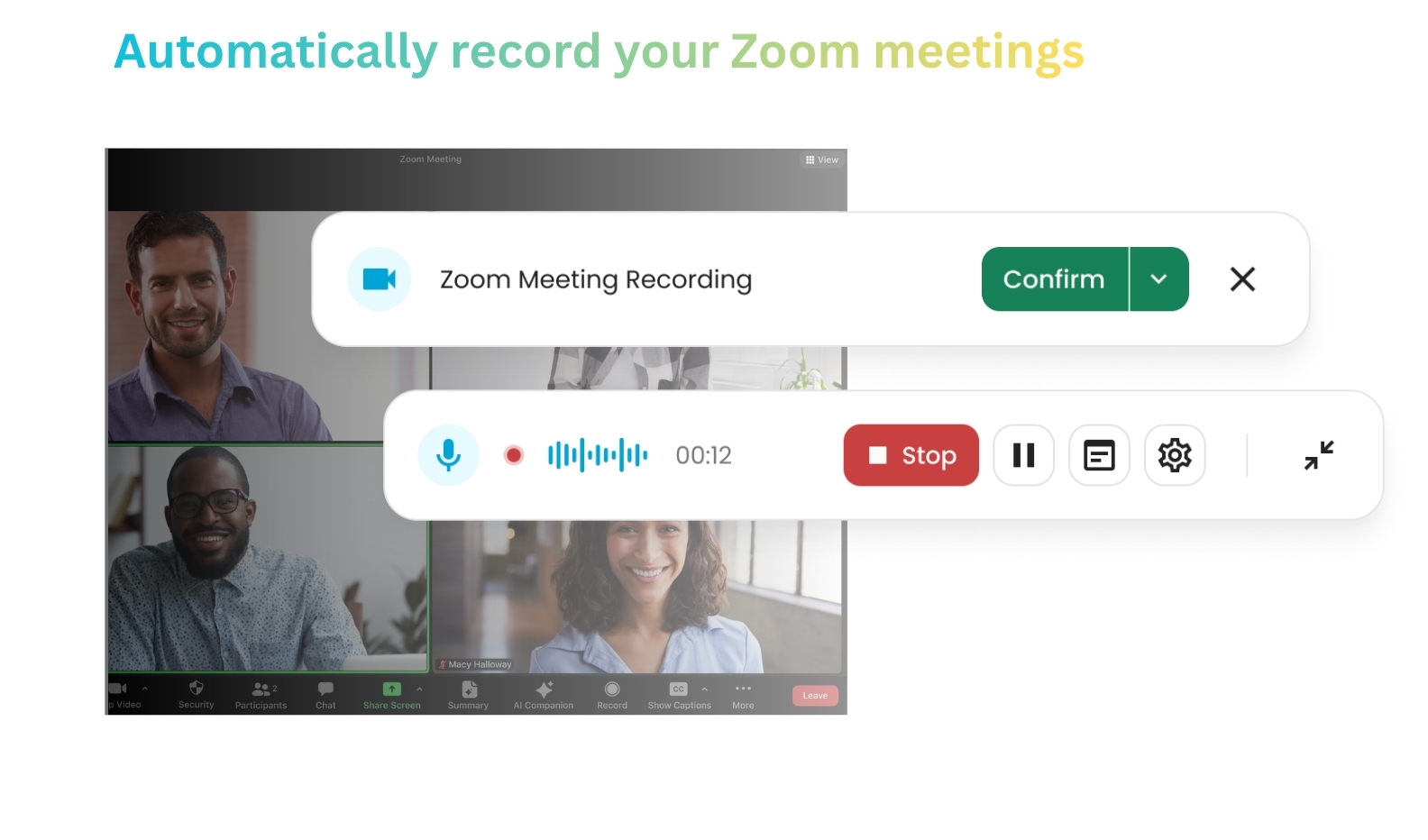
Our Mac/PC apps:
- Auto-detect when you’re in a meeting (monitors audio + calendar)
- Record and transcribe in real-time
- Extract structured insights (not just transcription)
- Link to related meetings, docs, clients
Why it’s different:
Most meeting tools just transcribe. We use Claude Code’s reasoning to analyze:
- What are the actual customer needs? (not just keywords)
- Which objections signal deal risk? (pattern recognition across meetings)
- What decisions were made and why? (causal reasoning)
Team value: When Alice meets a client, Bob can search “What pricing concerns did Acme raise?” and get insights from all team meetings, not just his own. The agent uses ripgrep to search the shared workspace – no embeddings, no indexes to maintain.
New meetings? Instantly searchable. No re-indexing delays.
Enterprise templates let companies define what matters:
# Sales call template
extract:
- customer_needs
- competitors_mentioned
- budget_discussed
- decision_timeline
- objections
The agent doesn’t just find these words. It understands context. “They mentioned budget concerns” vs “Budget is approved” – same keyword, different meaning.
Real workflow example:
Sales meeting ends. The agent has the transcript and extracted insights.
Now: “Generate a proposal for this client based on our product docs and past successful proposals.”
Claude Code searches the company’s document library, finds relevant content, understands the client’s specific needs from the meeting, and generates a high-quality proposal. Not a template. A thoughtful document tailored to this client.
This is the power: agentic search + deep reasoning + document generation. All in one workflow.
The parallel:
- Claude Code: Search codebase with ripgrep → reason about architecture → generate code to solve problems
- GBase: Search meetings with ripgrep → reason about patterns → generate Python to analyze data
Same agentic capabilities. Applied to business problems instead of code.
No embeddings. No RAG pipelines. Just direct file access + reasoning + code generation.
What’s next
We’re building three major capabilities:
Claude Code Marketplace
Every organization will get their own agent ecosystem. Not just one agent – a suite of specialized agents they can configure and deploy.
Think: Sales agent, research agent, analysis agent. Each optimized for specific workflows.
Skills system
Organizations can define their own workflows and methodologies as “skills”.
Example: “Our sales qualification process” or “How we conduct market research”
The agent learns these skills and applies them consistently across the team. Company knowledge becomes executable.
Batch subagent execution
Need to analyze 100 customers? Generate 50 reports? Run comparisons across multiple datasets?
Deploy subagents in parallel. Each handles one task. Results aggregated automatically.
This turns hours of repetitive work into minutes of parallel execution.
Try it
We’re in public beta: https://gbase.ai
Takes <30 seconds to sign up, no credit card. The demo shows meeting analysis and document search.
Questions for HN
I’m curious to hear from people working on similar problems:
- Multi-tenant agentic AI – How do you isolate data between organizations while maintaining shared infrastructure efficiency? Docker per-user vs per-org?
- Agentic search vs embeddings – Claude Code uses ripgrep/blob instead of vector databases. No indexes to build or maintain. Have you tried this approach at scale? How does it compare?
- Shared file systems at scale – EFS works but costs are brutal. What do you use for POSIX-compliant file systems serving multiple organizations? CephFS? GlusterFS?
- Cost optimization for SaaS – What strategies work for keeping infrastructure costs reasonable in multi-tenant environments? Curious about your approaches.
Our team (5 engineers in Tokyo) will be around for the next few hours to answer questions.