The only Python IDE you need.
10 Smart Performance Hacks For Faster Python Code
This is a guest post from Dido Grigorov, a deep learning engineer and Python programmer with 17 years of experience in the field.

In the rapidly evolving domain of software development, Python has established itself as a premier language, renowned for its simplicity, readability, and versatility. It underpins a vast range of applications, from web development to artificia…
The only Python IDE you need.
10 Smart Performance Hacks For Faster Python Code
This is a guest post from Dido Grigorov, a deep learning engineer and Python programmer with 17 years of experience in the field.
In the rapidly evolving domain of software development, Python has established itself as a premier language, renowned for its simplicity, readability, and versatility. It underpins a vast range of applications, from web development to artificial intelligence and data engineering. However, beneath its elegant syntax lies a potential challenge: performance bottlenecks that can transform otherwise efficient scripts into noticeably sluggish processes.
Whether the task involves processing large datasets, developing real-time systems, or refining computational efficiency, optimizing Python code for speed can be a decisive factor in achieving superior results.
This guide presents 10 rigorously tested performance-enhancement strategies. Drawing upon Python’s built-in capabilities, efficient data structures, and low-level optimization techniques, it offers practical methods to accelerate code execution without compromising the language’s characteristic clarity and elegance. Supported by empirical benchmarks and illustrative code examples, these techniques demonstrate how incremental improvements can yield substantial performance gains – empowering developers to transition from proficient practitioners to true experts in high-performance Python programming.
Let’s dive in and turbocharge your Python prowess!
Hack 1: Leverage sets for membership testing
When you need to check whether an element exists within a collection, using a list can be inefficient – especially as the size of the list grows. Membership testing with a list (x in some_list) requires scanning each element one by one, resulting in linear time complexity (O(n)):
big_list = list(range(1000000))
big_set = set(big_list)
start = time.time()
print(999999 in big_list)
print(f"List lookup: {time.time() - start:.6f}s")
start = time.time()
print(999999 in big_set)
print(f"Set lookup: {time.time() - start:.6f}s")
Time measured:
- List lookup: ~0.015000s
- Set lookup: ~0.000020s
In contrast, sets in Python are implemented as hash tables, which allow for constant-time (O(1)) lookups on average. This means that checking whether a value exists in a set is significantly faster, especially when dealing with large datasets.
For tasks like filtering duplicates, validating input, or cross-referencing elements between collections, sets are far more efficient than lists. They not only speed up membership tests but also make operations like unions, intersections, and differences much faster and more concise.
By switching from lists to sets for membership checks – particularly in performance-critical code – you can achieve meaningful speed gains with minimal changes to your logic.
Hack 2: Avoid unnecessary copies
Copying large objects like lists, dictionaries, or arrays can be costly in both time and memory. Each copy creates a new object in memory, which can lead to significant overhead, especially when working with large datasets or within tight loops.
Whenever possible, modify objects in place instead of creating duplicates. This reduces memory usage and improves performance by avoiding the overhead of allocating and populating new structures. Many built-in data structures in Python provide in-place methods (e.g. sort, append, update) that eliminate the need for copies.
numbers = list(range(1000000))
def modify_list(lst):
lst[0] = 999
return lst
start = time.time()
result = modify_list(numbers)
print(f"In-place: {time.time() - start:.4f}s")
def copy_list(lst):
new_lst = lst.copy()
new_lst[0] = 999
return new_lst
start = time.time()
result = copy_list(numbers)
print(f"Copy: {time.time() - start:.4f}s")
Time measured:
- In-place: ~0.0001s
- Copy: ~0.0100s
In performance-critical code, being mindful of when and how objects are duplicated can make a noticeable difference. By working with references and in-place operations, you can write more efficient and memory-friendly code, particularly when handling large or complex data structures.
Hack 3: Use __slots__ for memory efficiency
By default, Python classes store instance attributes in a dynamic dictionary (__dict__), which offers flexibility but comes with memory overhead and slightly slower attribute access.
Using __slots__ allows you to explicitly declare a fixed set of attributes for a class. This eliminates the need for a __dict__, reducing memory usage – which is especially beneficial when creating many instances of a class. It also leads to marginally faster attribute access due to the simplified internal structure.
While __slots__ does restrict dynamic attribute assignment, this trade-off is often worthwhile in memory-constrained environments or performance-sensitive applications. For lightweight classes or data containers, applying __slots__ is a simple way to make your code more efficient.
class Point:
__slots__ = ('x', 'y')
def __init__(self, x, y):
self.x = x
self.y = y
start = time.time()
points = [Point(i, i+1) for i in range(1000000)]
print(f"With slots: {time.time() - start:.4f}s")
Time measured:
- With
__slots__: ~0.1200s - Without
__slots__: ~0.1500s
Hack 4: Use math functions instead of operators
For numerical computations, Python’s math module provides functions that are implemented in C, offering better performance and precision than equivalent operations written in pure Python.
For example, using math.sqrt() is typically faster and more accurate than raising a number to the power of 0.5 using the exponentiation (**) operator. Similarly, functions like math.sin(), math.exp(), and math.log() are highly optimized for speed and reliability.
These performance benefits become especially noticeable in tight loops or large-scale calculations. By relying on the math module for heavy numerical work, you can achieve both faster execution and more consistent results – making it the preferred choice for scientific computing, simulations, or any math-heavy code.
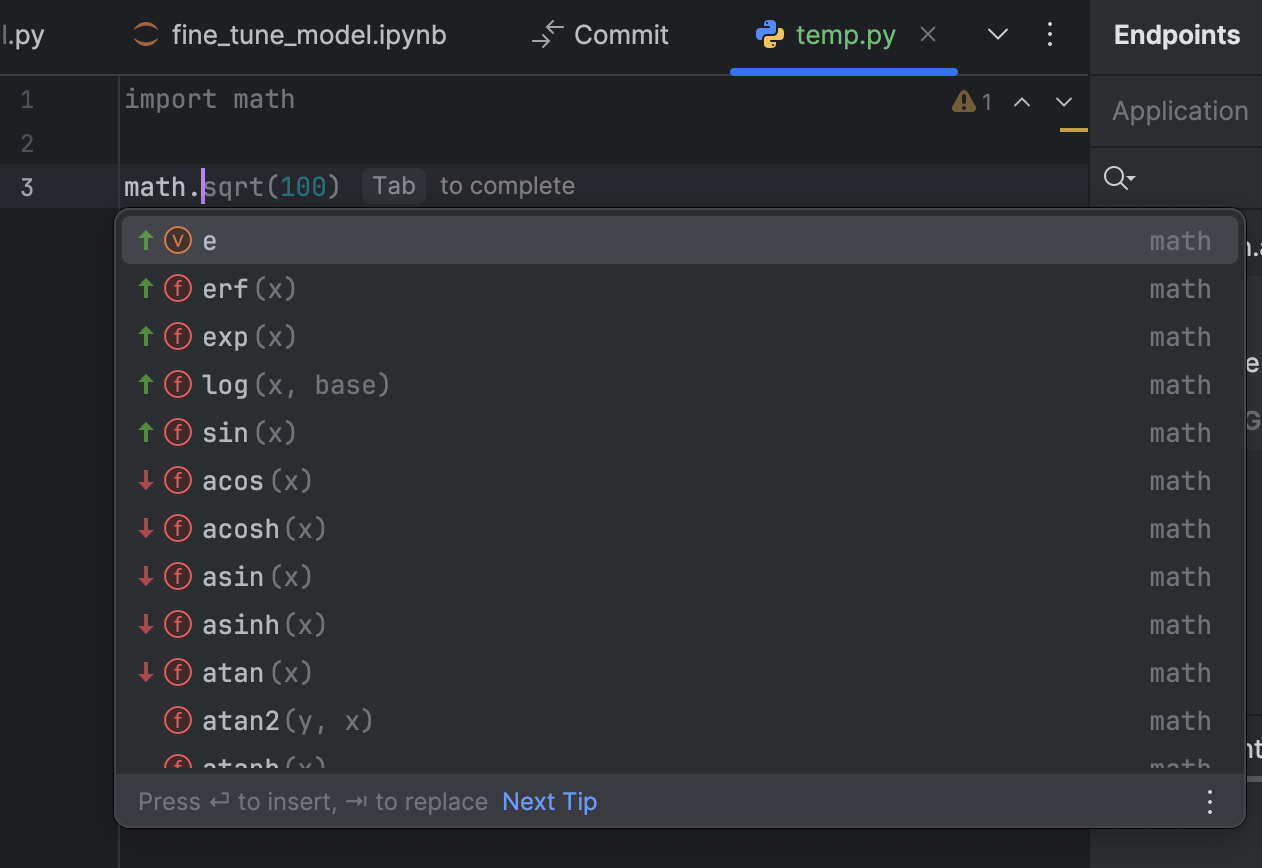
PyCharm makes it even easier to take advantage of the math module by providing intelligent code completion. Simply typing math. triggers a dropdown list of all available mathematical functions and constants – such as sqrt(), sin(), cos(), log(), pi, and many more – along with inline documentation.
This not only speeds up development by reducing the need to memorize function names, but also encourages the use of optimized, built-in implementations over custom or operator-based alternatives. By leveraging these hints, developers can quickly explore the full breadth of the module and write cleaner, faster numerical code with confidence.
import math
numbers = list(range(10000000))
start = time.time()
roots = [math.sqrt(n) for n in numbers]
print(f"Math sqrt: {time.time() - start:.4f}s")
start = time.time()
roots = [n ** 0.5 for n in numbers]
print(f"Operator: {time.time() - start:.4f}s")
Time measured:
math.sqrt: ~0.2000s- Operator: ~0.2500s
Hack 5: Pre-allocate memory with known sizes
When building lists or arrays dynamically, Python resizes them in the background as they grow. While convenient, this resizing involves memory allocation and data copying, which adds overhead – especially in large or performance-critical loops.
If you know the final size of your data structure in advance, pre-allocating memory can significantly improve performance. By initializing a list or array with a fixed size, you avoid repeated resizing and allow Python (or libraries like NumPy) to manage memory more efficiently.
This technique is particularly valuable in numerical computations, simulations, and large-scale data processing, where even small optimizations can add up. Pre-allocation helps reduce fragmentation, improves cache locality, and ensures more predictable performance.
start = time.time()
result = [0] * 1000000
for i in range(1000000):
result[i] = i
print(f"Pre-allocated: {time.time() - start:.4f}s")
start = time.time()
result = []
for i in range(1000000):
result.append(i)
print(f"Dynamic: {time.time() - start:.4f}s")
Time measured:
- Pre-allocated: ~0.0300s
- Dynamic: ~0.0400s
Hack 6: Avoid exception handling in hot loops
While Python’s exception handling is powerful and clean for managing unexpected behavior, it’s not designed for high-frequency use inside performance-critical loops. Raising and catching exceptions involves stack unwinding and context switching, which are relatively expensive operations.
In hot loops – sections of code that run repeatedly or process large volumes of data – using exceptions for control flow can significantly degrade performance. Instead, use conditional checks (if, in, is, etc.) to prevent errors before they occur. This proactive approach is much faster and leads to more predictable execution.
Reserving exceptions for truly exceptional cases, rather than expected control flow, results in cleaner and faster code – especially in tight loops or real-time applications where performance matters.
numbers = list(range(10000000))
start = time.time()
total = 0
for i in numbers:
if i % 2 != 0:
total += i // 2
else:
total += i
print(f"Conditional: {time.time() - start:.4f}s")
start = time.time()
total = 0
for i in numbers:
try:
total += i / (i % 2)
except ZeroDivisionError:
total += i
print(f"Exception: {time.time() - start:.4f}s")
Time measured:
- Conditional: ~0.3000s
- Exception: ~0.6000s
Hack 7: Use local functions for repeated logic
When a specific piece of logic is used repeatedly within a function, defining it as a local (nested) function – also known as a closure – can improve performance and organization. Local functions benefit from faster name resolution because Python looks up variables more quickly in local scopes than in global ones.
In addition to the performance gain, local functions help encapsulate logic, making your code cleaner and more modular. They can also capture variables from the enclosing scope, allowing you to write more flexible and reusable inner logic without passing extra arguments.
This technique is particularly useful in functions that apply the same operation multiple times, such as loops, data transformations, or recursive processes. By keeping frequently used logic local, you reduce both runtime overhead and cognitive load.
Hint: Use AI Assistant’s Suggest Refactoring
If you’re using PyCharm (or any JetBrains product) with the AI Assistant plugin, one particularly powerful tool is Suggest Refactoring. With it, you can select a segment of code, invoke the AI Assistant, and ask it to propose cleaner or more efficient alternatives – all in one go.
The assistant shows you a “refactored” version of your code, lets you view the diff (what would change), and you can accept either selected snippets or the whole block. This helps maintain consistency, enforce best practices, and catch opportunities for improvement you might otherwise miss.
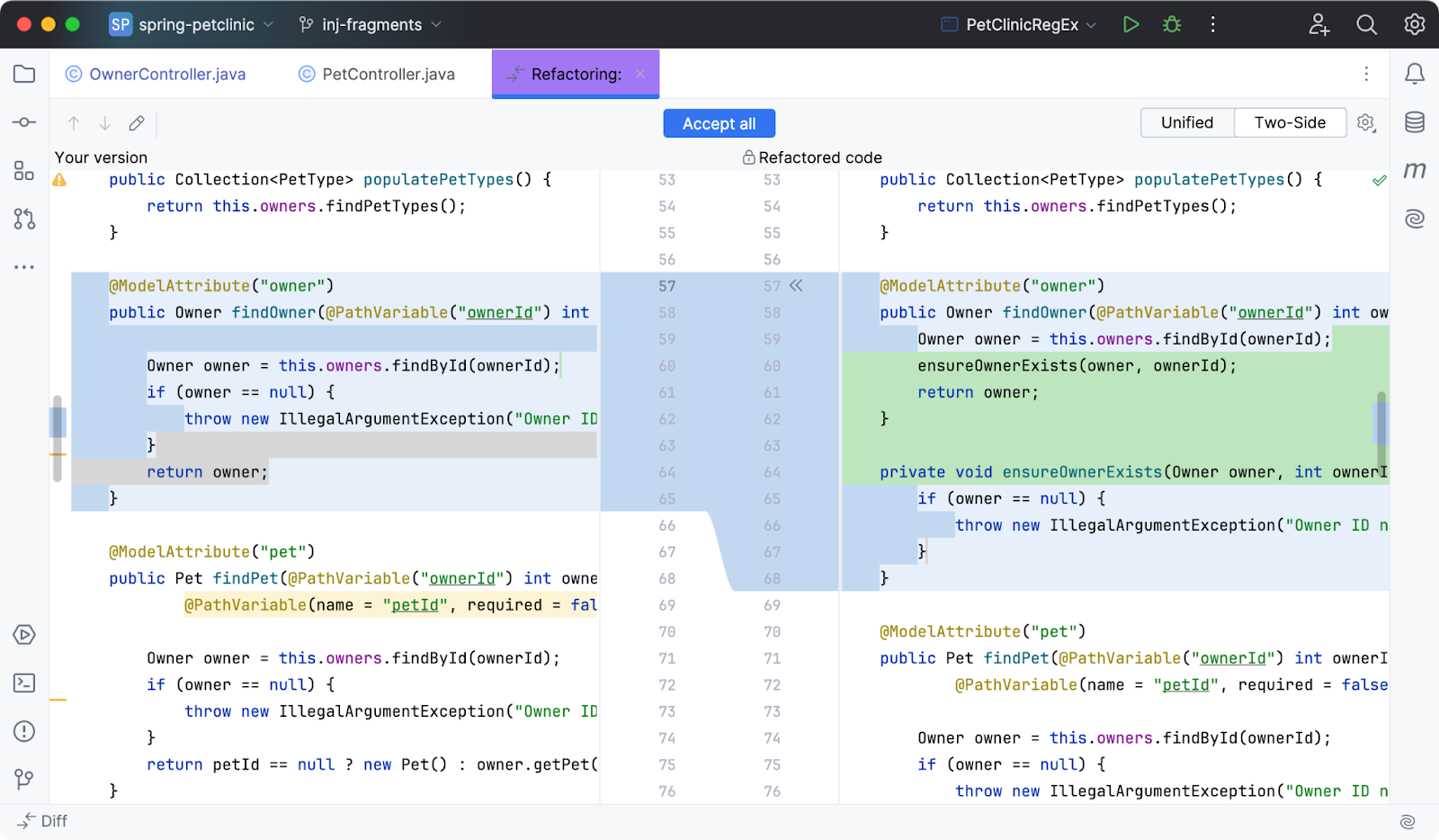
**How to use **Suggest Refactoring
Here are step-by-step instructions (as per JetBrains’ documentation) on how to use this feature:
- Select the code fragment you want to refactor.
- When the popup appears (e.g. small lightbulb or context menu), click the AI Assistant icon.
- Choose Suggest Refactoring in the menu.
- The AI Chat pane then opens with its proposed refactorings. In it, you can:
- Click Show Diff to compare the original against the proposed code.
- Or if you prefer, you can select Apply Immediately to skip the diff and apply the suggestion directly.
- If you like the suggested changes, click Accept on individual snippets (in the gutter) or *Accept All *to replace the entire selected fragment.
- If you don’t like the suggestions, you can always close the diff or dialog without applying.
def outer():
def add_pair(a, b):
return a + b
result = 0
for i in range(10000000):
result = add_pair(result, i)
return result
start = time.time()
result = outer()
print(f"Local function: {time.time() - start:.4f}s")
def add_pair(a, b):
return a + b
start = time.time()
result = 0
for i in range(10000000):
result = add_pair(result, i)
print(f"Global function: {time.time() - start:.4f}s")
Time measured:
- Local function: ~0.4000s
- Global function: ~0.4500s
Hack 8: Use itertools for combinatorial operations
When dealing with permutations, combinations, Cartesian products, or other iterator-based tasks, Python’s itertools module provides a suite of highly efficient, C-optimized tools tailored for these use cases.
Functions like product(), permutations(), combinations(), and combinations_with_replacement() generate elements lazily, meaning they don’t store the entire result in your computer’s memory. This allows you to work with large or infinite sequences without the performance or memory penalties of manual implementations.
In addition to being fast, itertools functions are composable and memory-efficient, making them ideal for complex data manipulation, algorithm development, and problem-solving tasks like those found in simulations, search algorithms, or competitive programming. When performance and scalability matter, itertools is a go-to solution.
from itertools import product
items = [1, 2, 3] * 10
start = time.time()
result = list(product(items, repeat=2))
print(f"Itertools: {time.time() - start:.4f}s")
start = time.time()
result = []
for x in items:
for y in items:
result.append((x, y))
print(f"Loops: {time.time() - start:.4f}s")
Time measured:
itertools: ~0.0005s- Loops: ~0.0020s
Hack 9: Use bisect for sorted list operations
When working with sorted lists, using linear search or manual insertion logic can be inefficient – especially as the list grows. Python’s bisect module provides fast, efficient tools for maintaining sorted order using binary search.
With functions like bisect_left(), bisect_right(), and insort(), you can perform insertions and searches in O(log n)time, as opposed to the O(n) complexity of a simple scan. This is particularly useful in scenarios like maintaining leaderboards, event timelines, or implementing efficient range queries.
By using bisect, you avoid re-sorting after every change and gain a significant performance boost when working with dynamic, sorted data. It’s a lightweight and powerful tool that brings algorithmic efficiency to common list operations.
import bisect
numbers = sorted(list(range(0, 1000000, 2)))
start = time.time()
bisect.insort(numbers, 75432)
print(f"Bisect: {time.time() - start:.4f}s")
start = time.time()
for i, num in enumerate(numbers):
if num > 75432:
numbers.insert(i, 75432)
break
print(f"Loop: {time.time() - start:.4f}s")
Time measured:
bisect: ~0.0001s- Loop: ~0.0100s
Hack 10: Avoid repeated function calls in loops
Calling the same function multiple times inside a loop – especially if the function is expensive or produces the same result each time – can lead to unnecessary overhead. Even relatively fast functions can accumulate significant cost when called repeatedly in large loops.
To optimize, compute the result once outside the loop and store it in a local variable. This reduces function call overhead and improves runtime efficiency, particularly in performance-critical sections of code.
This technique is simple but effective. It not only speeds up execution but also enhances code clarity by signaling that the value is constant within the loop’s context. Caching function results is one of the easiest ways to eliminate redundant computation and make your code more efficient.
def expensive_operation():
time.sleep(0.001)
return 42
start = time.time()
cached_value = expensive_operation()
result = 0
for i in range(1000):
result += cached_value
print(f"Cached: {time.time() - start:.4f}s")
start = time.time()
result = 0
for i in range(1000):
result += expensive_operation()
print(f"Repeated: {time.time() - start:.4f}s")
Time measured:
- Cached: ~0.0010s
- Repeated: ~1.0000s
In summary
From leveraging the inherent efficiency of Python’s built-in functions and high-performance libraries such as NumPy to employing memory-conscious techniques with __slots__ and generators, these fifteen Python performance strategies provide a comprehensive set of tools for enhancing execution speed.
The methods explored include optimizing iterative processes with comprehensions, utilizing sets for rapid membership checks, avoiding unnecessary data copies and exception handling overhead, and applying bitwise operations as arithmetic shortcuts.
Specialized modules such as itertools, bisect, and collections further streamline complex tasks, while adherence to best practices – such as minimizing the use of global variables, pre-allocating memory, and implementing caching – ensures lean, efficient code execution. Empirical benchmarks demonstrate that even minor adjustments can yield significant time savings in large-scale operations, reinforcing the principle that effective optimization does not necessitate a complete code rewrite.
Whether refining a standalone script or scaling a production-level application, these techniques, when applied judiciously, can significantly enhance performance while conserving system resources. Ultimately, the most effective optimizations strike a balance between speed and clarity.
About the author

Dido Grigorov
Dido is a seasoned Deep Learning Engineer and Python programmer with an impressive 17 years of experience in the field. He is currently pursuing advanced studies at the prestigious Stanford University, where he is enrolled in a cutting-edge AI program, led by renowned experts such as Andrew Ng, Christopher Manning, Fei-Fei Li and Chelsea Finn, providing Dido with unparalleled insights and mentorship.
Dido’s passion for Artificial Intelligence is evident in his dedication to both work and experimentation. Over the years, he has developed a deep expertise in designing, implementing, and optimizing machine learning models. His proficiency in Python has enabled him to tackle complex problems and contribute to innovative AI solutions across various domains.
Subscribe to PyCharm Blog updates
