Large language models (LLMs) have dominated the AI landscape, defining what “intelligence” looks like in the age of GPT-4, Claude, and Gemini. However, a new position paper from NVIDIA researchers, “Small Language Models are the Future of Agentic AI” (June 2025), makes a surprising argument: the next real leap forward won’t come from models getting bigger. It’ll come from them getting smaller.

This article breaks down what the authors propose, why they think small language models (SLMs) may outperform giants in specific real-world AI systems, and what this shift could mean for the future of on-device and edge computing...
Large language models (LLMs) have dominated the AI landscape, defining what “intelligence” looks like in the age of GPT-4, Claude, and Gemini. However, a new position paper from NVIDIA researchers, “Small Language Models are the Future of Agentic AI” (June 2025), makes a surprising argument: the next real leap forward won’t come from models getting bigger. It’ll come from them getting smaller.
This article breaks down what the authors propose, why they think small language models (SLMs) may outperform giants in specific real-world AI systems, and what this shift could mean for the future of on-device and edge computing.
🚀 Sign up for The Replay newsletter
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it’s your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
What are small language models (SLMs)?
The paper defines SLMs not by their parameter count, but by their deployability, i.e. models that can run efficiently on consumer-grade devices with low latency. In other words, “small” doesn’t strictly mean fewer parameters; it means practically runnable without specialized datacenter hardware.
What qualifies as “small” is also relative to time and technology. As hardware performance continues to follow a Moore’s Law–like trajectory – where processing power and memory capacity roughly double every two years – the boundary between small and large shifts, as well.
The models we currently think of as heavyweight LLMs may soon become light enough to run on commodity GPUs, laptops, or even mobile devices. In that sense, “smallness” is a moving target, defined less by static size and more by what’s deployable at the current technological moment.
The case for going small
The authors put forth three central theses:
- Capability and autonomy: SLMs are already capable of most agentic tasks.
- Operational fit: SLMs are more operationally suitable within modular AI systems.
- **Cost efficiency: **SLMs are vastly more economical to deploy and maintain.
They argue that the current obsession with scale may actually slow down innovation in autonomous, tool-using AI agents.
Why smaller models make smarter agents
Agentic AI —systems that plan, reason, call tools, and collaborate with humans—doesn’t always need the encyclopedic knowledge of a trillion-parameter model.
Many of these agents operate in narrow, repetitive domains: summarizing documents, parsing emails, writing scripts, or managing workflows.
In such environments:
- Smaller models can be fine-tuned faster and specialized per task.
- Routing systems can dynamically choose which model handles which subtask.
- Local inference enables low-latency responses and better privacy.
In essence, the authors imagine an ecosystem of cooperating, lightweight specialists rather than one monolithic generalist.
Edge, not just cloud: The shift in deployment
One of the most striking implications of the paper is where AI will live: instead of every inference request traveling to a remote data center, the future could see much more reasoning happening on the edge—on laptops, desktops, and consumer GPUs.
The authors highlight developments such as:
- ChatRTX and similar local-execution frameworks showcase how small language models can run entirely on consumer GPUs, enabling real-time, offline AI interactions that preserve privacy and reduce dependency on cloud infrastructure.
- Efficient inference schedulers like NVIDIA’s Dynamo intelligently distribute model workloads across available hardware—cloud, edge, or local GPUs—optimizing for latency, throughput, and energy efficiency in hybrid AI systems.
While the paper doesn’t explicitly discuss running models inside browsers, its logic aligns with emerging WebGPU/Wasm inference trends. Browser-native SLMs may soon power offline assistants, embedded copilots, or secure enterprise workflows.
Of course, the paper is focused on NVIDIA products. But in a more general context, it’s clear that deploying on intelligent platforms to offload some of the work on local GPUs is an interesting avenue for research.
How to go from LLM to SLM: A roadmap
The researchers go beyond theory and outline a methodical process for transforming LLM-based systems into SLM-powered architectures. Their blueprint treats this as an engineering transition, not just a model swap. This is an interesting definition because it encompasses the deployment, and it’s not domain-specific.
- Collect task traces from an LLM-driven agent: Start by logging real-world interactions—inputs, outputs, and reasoning traces—from the LLM in production. These traces reveal how the model is being used, which tasks recur, and where general-purpose reasoning is actually unnecessary.
- Cluster and analyze these interactions to identify repetitive subtasks: By grouping similar prompts and responses, teams can discover distinct task clusters (e.g., summarization, tool invocation, code explanation). Many of these subtasks require narrow, predictable reasoning, making them ideal candidates for smaller models.
- Select or train SLMs specialized for those clusters: The paper suggests evaluating existing open SLMs—such as Phi, Mistral, or SmolLM—or fine-tuning new ones using the clustered data. Each specialized model becomes an “expert” in its subdomain, optimized for efficiency and reliability.
- Design a router that delegates to the right model at runtime: A lightweight orchestration layer can dynamically select which SLM to invoke based on the input type, context, or required capability. This routing logic effectively replaces the monolithic LLM with a modular swarm of smaller models.
- Iteratively refine the system based on performance and cost: Continuous feedback and monitoring close the loop. Usage data informs which tasks should remain local versus cloud-hosted, when to retrain specialists, and how to balance latency against cost and accuracy.
This approach reframes agentic AI as a distributed ecosystem rather than a single central intelligence. It also explains why this is an engineering approach more than a re-thinking of the LLMs usage. By decomposing complex workloads into specialized, reusable components, organizations can dramatically reduce inference costs, improve scalability, and bring intelligence closer to the edge—without compromising overall system quality.
On-device and in-browser AI
Looking ahead, the line between “local” and “cloud” intelligence may blur even further. With the rapid progress of WebGPU and WebAssembly, running small language models directly inside browsers is becoming technically feasible.
Imagine AI copilots that operate securely within your browser tab: no server round-trips, no data sharing, just instant, private reasoning. (Note: this is a different vision than OpenAI Atlas, which is just ChatGPT in the shell of a Chromium-based browser) For many everyday agentic tasks —summarizing pages, assisting with forms, coding help, or offline document reasoning, SLMs in the browser could deliver near-LLM capabilities while keeping computation and control entirely in the user’s hands.
Of course, this transition isn’t trivial.
- Economic inertia: Existing LLM infrastructure represents a massive sunk cost.
- Evaluation bias: Benchmarks still favor large models.
- Developer convenience: APIs for SLM orchestration aren’t as standardized yet.
Moreover, not every problem fits into a small model—especially tasks involving broad world knowledge or high-stakes reasoning.
Still, the authors suggest that the balance between scale and specialization is shifting fast.
Implications for dev leaders and organizations
For engineering leaders, the takeaway is that the real power of modern agentic AI architectures rarely comes from a single, monolithic LLM call. Instead, it emerges from orchestrating multiple models and prompts: a network of specialized components collaborating to complete complex workflows.
In this evolving ecosystem, SLMs can take on an increasingly strategic role. See the example in the image below.
Imagine a pipeline where large cloud-based models handle the heavy reasoning or data synthesis, and then an on-device SLM, running on the user’s GPU, refines, personalizes, and humanizes the output before delivery: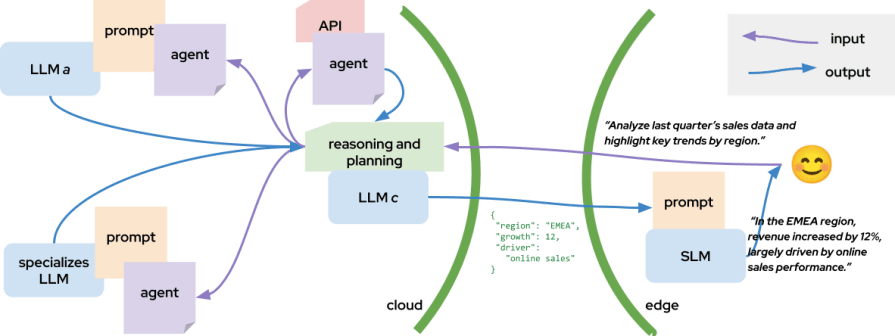
A reasonable example of this approach could be a system for enterprise data analysis and report generation. Imagine a business-intelligence assistant used by analysts in a large company to turn raw data into readable insights:
- **Cloud-based LLM service (reasoning and planning): **A powerful, general-purpose LLM hosted in the cloud receives the user’s high-level query, such as *“Analyze last quarter’s sales data and highlight key trends by region.” *The LLM interprets the request, breaks it down into subtasks, and generates an execution plan for downstream agents.
- **Classic agent accessing APIs (data retrieval): **The agent executes API calls to internal databases and dashboards, fetching relevant metrics, tables, and KPIs. It structures the information as JSON payloads following a predefined schema.
- **Fine-tuned LLM (domain specialist): **A smaller, fine-tuned model—trained specifically on the company’s sales and financial language—processes the raw JSON data. It enriches the payload with derived metrics, summaries, and recommended actions (e.g., “Revenue in EMEA grew 12%, driven by online channels”).
- SLM running on the edge (local GPU / device): Finally, an on-device Small language model receives this structured JSON. Running locally on the analyst’s workstation GPU, the SLM converts the machine-readable data into natural, human-friendly text — a personalized report in the analyst’s preferred tone and language.Example: The SLM translates the JSON returned by the orchestration:
{ "region": "EMEA", "growth": 12, "driver": "online sales" }into: “In the EMEA region, revenue increased by 12%, largely driven by online sales performance.”
This kind of hybrid cloud–edge collaboration not only reduces latency and cost but also enhances privacy and responsiveness, redefining how AI workloads are distributed across the stack.
Conclusion: The future of AI agents might be tiny
The NVIDIA team’s paper doesn’t just argue for smaller models—it calls for a rethinking of what “intelligence at scale” means.
Instead of centralizing all reasoning in giant black boxes, the future might be a federation of smaller, faster, privacy-friendly agents—running on the edge, in your browser, or even offline.
In a sense, the next frontier of AI isn’t about how big models can get.
It’s about how small they can go—and still think big.