Decreasing code editing failures by 38% with output normalization
• November 03, 2025
We’re building a better coding agent for JetBrains.
Editing code is the most error-prone step in any coding agent. Here’s how we decreased the error rate of string replace in our JetBrains coding agent by 38%.
How Coding Agents Work
For those unfamiliar, coding agents work by taking a user request and repeatedly calling tools to complete it.
Tools are functions where the LLM provides the arguments and the agent (or harness) executes the function with those arguments.
For example, if you want an LLM to check stock prices, you would first want to implement a tool to fetch the stock price (by calling the correct api).
Then the LLM can provide the correct args to “check_stock”:…
Decreasing code editing failures by 38% with output normalization
• November 03, 2025
We’re building a better coding agent for JetBrains.
Editing code is the most error-prone step in any coding agent. Here’s how we decreased the error rate of string replace in our JetBrains coding agent by 38%.
How Coding Agents Work
For those unfamiliar, coding agents work by taking a user request and repeatedly calling tools to complete it.
Tools are functions where the LLM provides the arguments and the agent (or harness) executes the function with those arguments.
For example, if you want an LLM to check stock prices, you would first want to implement a tool to fetch the stock price (by calling the correct api).
Then the LLM can provide the correct args to “check_stock”:
Here’s an example of tool calling in a coding agent.
The LLM calls the read_file tool and then our harness reads and returns the file contents:
This allows the LLM to generate tests by calling the create_file tool.
Then the LLM can run the unit tests or ask if the user would like to make additional changes.
How LLMs Edit Code
Surprisingly, most errors in coding agents occur when editing files. This involves the LLM reading the latest state of a file and expressing some form of “edit”.
Each LLM has its own preferred tool for editing files. GPT-5 performs best when using (which looks like a unified diff), while Claude models like to call a tool called string replace.
What is String Replace?
involves specifying the old string that the LLM wants to change and the new string to replace the old string with.
For example, if I asked Claude to rename my function from to it would express the edit like this:
The function name should look like this after the edit:
Why String Replace Fails
Why do LLMs struggle at this?
When we looked at production error rates, we noticed that str_replace was by far the tool with the most errors. It had at an error rate of ~13%, while a tool like “read_file” or “search” would have sub 1% error rate.
77% of str_replace failures occurred because the code the agent tried to replace didn’t exist in the file (the “old_string” couldn’t be found). This happens in two main scenarios:
- LLM hallucination: The model generates code that doesn’t exist in the file, or remembers it slightly differently than the actual file state.
- State drift: The file changes between when the agent reads it and when it tries to edit it.
Here’s a concrete example of state drift: Suppose I ask the agent to rename to . The agent reads the file and sees:
But before the agent can apply its edit, I manually change the parameter name from to . Now the file contains:
When the agent tries to replace with , the edit fails because the old_string no longer matches what’s in the file.
While some level of failure is expected in these scenarios, a 10% overall failure rate was higher than we anticipated. So we dug deeper to understand what was causing so many mismatches.
An Invisible State Drift
This was due to an interaction between the JetBrains IDE and Claude models.
A lesser known feature of JetBrains IDEs is that saving will remove any trailing whitespaces in the file. 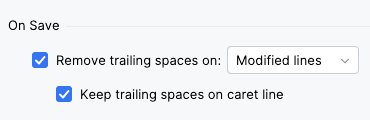
This is enabled for ALL IDEs by default. This shouldn’t cause any issues if LLMs wrote nicely formatted code.
The actual problem occurs because Claude loves adding trailing whitespace between newlines. I asked Claude to generate this script in claude.ai, and it added trailing whitespace between each of the newlines: 
This causes a problematic sequence of events when using Claude as a coding agent:
- Claude generates a new function. Let’s call this string
- The agent harness inserts this code into the IDE.
- The IDE auto-formats -> (deleting all trailing indentation). Claude doesn’t see this.
- Claude tries to make a new edit -> , but no longer exists in the file (only does).
The edit will fail because the state has drifted, forcing Claude to re-read the file and retry the edit. This wastes developer time, burns through tokens, and bloats the context window with redundant tool calls.
Preventing state drift
There are a couple of ways to fix state drift. The most direct solution is prompting - we could add instructions like “don’t generate trailing indentation”, which would fix most cases.
However, this approach has two significant drawbacks:
1. Enforcing formatting reduces model intelligence
Requiring the model to follow strict formatting rules adds cognitive overhead that can degrade output quality. This has been documented by Aider (LLMs are bad at returning code in JSON ), and we can observe subtle differences even in simple tasks.
To illustrate this I tested two prompts with Claude (click to see the responses):
The first response (without formatting) contains a longer and higher quality explanations, while the second response contains a slight error in its comment.
The second response’s comment incorrectly uses an equals sign when the first response uses approximation (≈).
These subtle degradations happen because formatting constraints shift Claude away from its natural output distribution. The model’s training distribution represents its “best” responses - forcing it to generate different token sequences (like instead of ) can degrade the quality of the actual logic and explanations.
2. Prompt adherence degrades over long conversations
Even with explicit formatting instructions, models struggle to maintain adherence over extended interactions.
We can see that language model performance can break down as responses get longer. For example, in the GPT-5 prompting guide https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide, they mention this:
Occasionally, adherence to Markdown instructions specified in the system prompt can degrade over the course of a long conversation. In the event that you experience this, we’ve seen consistent adherence from appending a Markdown instruction every 3-5 user messages.
This wouldn’t be a deterministic solution. There are other solutions to state drift. We could store the state, or disabling formatting - but we found a simple solution that works without prompt engineering or tracking state!
Output normalization: formatting without prompting
When we use Claude via the API we can pass back arrays of messages where each message has a role (user or assistant).
Most coding agents only modify the latest user response, but by modifying the assistant messages, we can generate code that’s both in-distribution and avoid state drift bugs.
Here’s how it works:
- Claude generates code normally. Claude produces and as usual (no prompting changes). The can contain trailing whitespaces.
- We apply output normalization by modify in-place to trim all trailing whitespaces. This preempts the IDE’s auto-formatting and the code gets inserted “pre-formatted”.
- When we apply the change, it looks like Claude never generated trailing whitespaces at all.
- Future edits then use the normalized output. When we pass this back to Claude, it sees the properly formatted code in its history. This means future edits will reference the corrected ouput instead of the actual generation.
The implementation is straightforward:
Let’s say Claude wants to add a new function to a file. Here’s what happens:
-
Claude generates trailing whitespace.
-
We then delete these trailing spaces using our regex method.
-
We update the messages we send back to Claude with the correct format ( instead of ).
When Claude tries to edit this function later it will reference the version without trailing whitespace, preventing the state drift issue entirely.
Interestingly, this approach keeps Claude mostly on-distribution. While we’re technically modifying Claude’s conversation history, we found that history modifications have much less impact on output quality compared to system prompt changes. In fact even after we normalize the history, Claude continues to generate trailing whitespaces in new code, indicating it’s still following its natural training distribution.
Results
After rolling out output normalization, our code editing error rate dropped 38% from 13% to 8%. Users reported that the agent was faster, more cost-efficient, and more accurate.
Modifying assistant output is an uncommon but powerful technique for improving LLM performance. We’ve incorporated a lot of ideas like these into Sweep to make it the best coding agent for JetBrains. If you like JetBrains, check out Sweep!