Large Language Models (LLMs) are powerful, but their performance can be bottlenecked by the immense NVIDIA GPU memory footprint of the Key-Value (KV) Cache. This cache, crucial for speeding up LLM inference by storing Key (K) and Value (V) matrices, directly impacts context length, concurrency, and overall system throughput. Our primary goal is to maximize the KV Cache hit ratio by intelligently expanding NVIDIA GPU High Bandwidth Memory (HBM) with a tiered node-local storage solution.
Our collaboration with the LMCache team (Kuntai Du, Jiayi Yao, and Yihua Cheng from Tensormesh) has led to the development of an innovative solution on Google Kubernetes Engine (GKE).
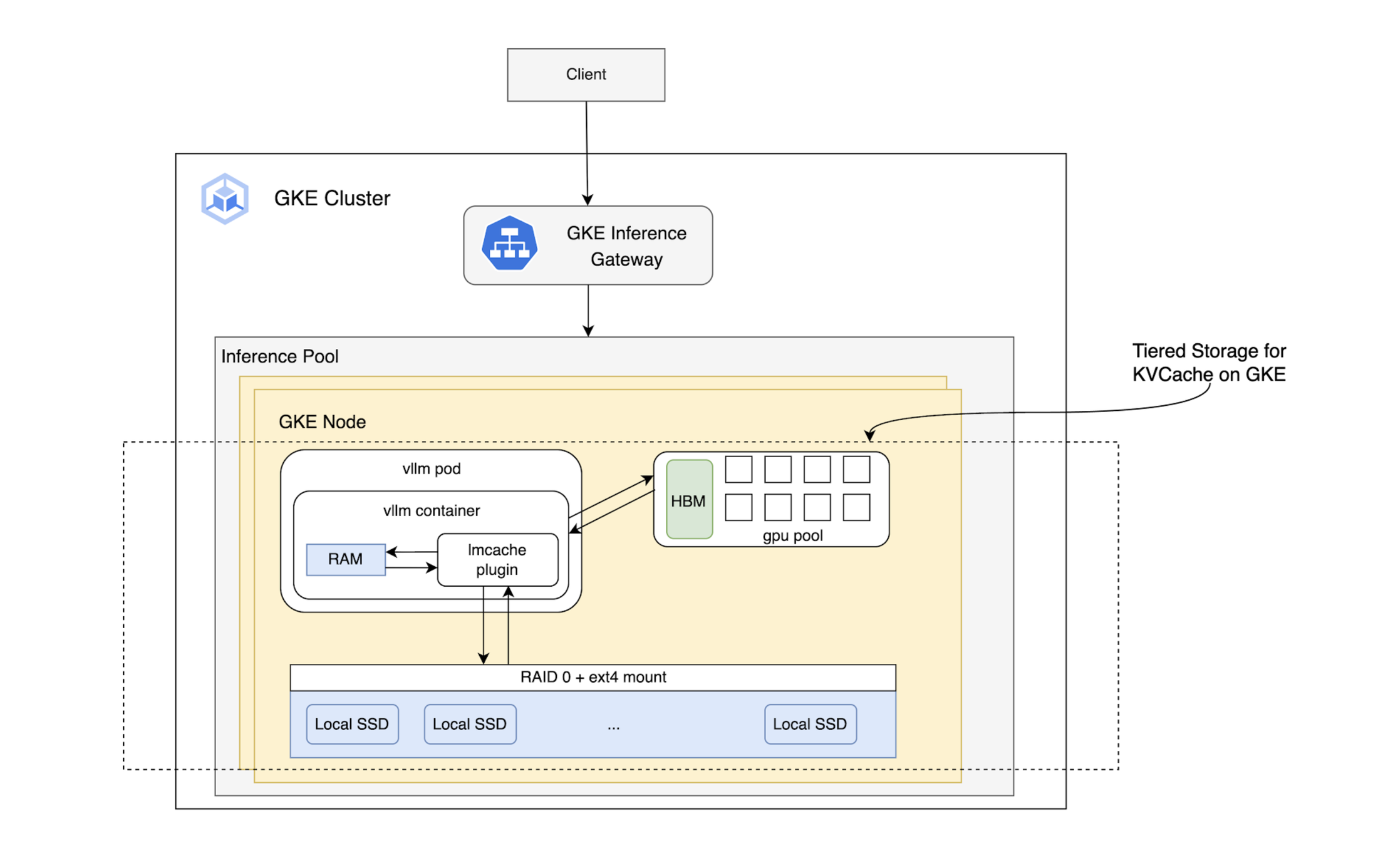
Tiered Storage: Expanding the KV Cache Beyond HBM
LMCache extends the KV Cache from the NVIDIA GPU’s …
Large Language Models (LLMs) are powerful, but their performance can be bottlenecked by the immense NVIDIA GPU memory footprint of the Key-Value (KV) Cache. This cache, crucial for speeding up LLM inference by storing Key (K) and Value (V) matrices, directly impacts context length, concurrency, and overall system throughput. Our primary goal is to maximize the KV Cache hit ratio by intelligently expanding NVIDIA GPU High Bandwidth Memory (HBM) with a tiered node-local storage solution.
Our collaboration with the LMCache team (Kuntai Du, Jiayi Yao, and Yihua Cheng from Tensormesh) has led to the development of an innovative solution on Google Kubernetes Engine (GKE).
Tiered Storage: Expanding the KV Cache Beyond HBM
LMCache extends the KV Cache from the NVIDIA GPU’s fast HBM (Tier 1) to larger, more cost-effective tiers like CPU RAM and local SSDs. This dramatically increases the total cache size, leading to a higher hit ratio and improved inference performance by keeping more data locally on the accelerator node. For GKE users, this means accommodating models with massive context windows while maintaining excellent performance.
Performance Benchmarking and Results
We designed tests to measure the performance of this tiered KV Cache by configuring workloads to fill each storage layer (HBM, CPU RAM, Local SSD). We benchmarked these configurations using various context lengths (1k, 5k, 10k, 50k, and 100k tokens), representing diverse use cases such as:
1k - 5k tokens: High-fidelity personas and complex instructions
10k tokens: Average user prompts (small RAG) or web page/article content
50k tokens: Prompt stuffing
100k tokens: Content equivalent to a long book
Our primary performance indicators were Time to First Token (TTFT), token input throughput, and end-to-end latency. The results highlight the best-performing storage setup for each KV Cache size and the performance improvements achieved.
Experiment Setup
We deployed a vLLM server on an A3 mega machine, leveraging local SSD for ephemeral storage via emptyDir.
Hardware: 8 × nvidia-h100-mega-80gb NVIDIA GPUs
Model: Llama-3.3-70B-Instruct
LMCache version: v0.3.3
Cache Configuration:
HBM only
HBM + CPU RAM
HBM + CPU RAM + Local SSD
Storage Resources: HBM: 640Gi, CPU RAM: 1Ti, Local SSD: 5Ti
Benchmark Tool: SGLang bench_serving
Requests: Tests were conducted with system prompt lengths of 1k, 5k, 10k, 50k, and 100k tokens. Each system prompt provided a shared context for a batch of 20 inference requests, with individual requests consisting of a unique 256-token input and generating a 512-token output.
Example Command:
Benchmark Results
Our tests explored different total KV Cache sizes. The following results highlight the optimal storage setup for each size and the performance improvements achieved:
Test 1: Cache (1.1M - 1.3M tokens) fits entirely within HBM
Results: In this scenario, adding slower storage tiers provided no advantage, making an HBM-only configuration the optimal setup.
Test 2: Cache (4.0M - 4.3M tokens) exceeds HBM capacity but fits within HBM + CPU RAM
| System Prompt Length | Best-performing Storage Setup | Mean TTFT (ms) Change (%) vs. HBM only | Input Throughput Change (%) vs. HBM only | Mean End-to-End Latency Change (%) vs. HBM only |
| 1000 | HBM | 0% | 0% | 0% |
| 5000 | HBM + CPU RAM | -18% | +16% | -14% |
| 10000 | HBM + CPU RAM | -44% | +50% | -33% |
| 50000 | HBM + CPU RAM + Local SSD | -68% | +179% | -64% |
| 100000 | HBM + CPU RAM + Local SSD | -79% | +264% | -73% |
Test 3: Large cache (12.6M - 13.7M tokens) saturates HBM and CPU RAM, spilling to Local SSD
| System Prompt Length | Best-performing Storage Setup | Mean TTFT (ms) Change (%) vs. HBM only | Input Throughput Change (%) vs. HBM only | Mean End-to-End Latency Change (%) vs. HBM only |
| 1000 | HBM + CPU RAM | +5% | +1% | -1% |
| 5000 | HBM + CPU RAM | -6% | +27% | -21% |
| 10000 | HBM + CPU RAM | +121% | +23% | -19% |
| 50000 | HBM + CPU RAM + Local SSD | +48% | +69% | -41% |
| 100000 | HBM + CPU RAM + Local SSD | -3% | +130% | -57% |
Summary
These results clearly demonstrate that a tiered storage solution significantly improves LLM inference performance by leveraging node-local storage, especially in scenarios with long system prompts that generate large KV Caches.
Optimizing LLM inference is a complex challenge requiring the coordinated effort of multiple infrastructure components (storage, compute, networking). Our work is part of a broader initiative to enhance the entire end-to-end inference stack, from intelligent load balancing at the Inference Gateway to advanced caching logic within the model server.
We are actively exploring further enhancements by integrating additional remote storage solutions with LMCache.
Next Steps
Get started with the same setup mentioned above on GKE.
Keep up to date on the LLM-D Inference Stack.
Posted in