This benchmark investigates whether the Prefill–Decode worker ratio needs to be managed dynamically at runtime, or if a fixed split can deliver the same performance with simpler orchestration. We evaluate different ratios across workload profiles and concurrency levels to measure their impact on TTFT, ITL, and throughput, and to see whether fixing the ratio in advance is a practical alternative to dynamic adjustment.

Introduction¶
What is Prefill–Decode disaggregation?¶
LLM inference has two distinct phases: prefill and decode. Prefill processes all prompt tokens in parallel and is compute-intensive. …
This benchmark investigates whether the Prefill–Decode worker ratio needs to be managed dynamically at runtime, or if a fixed split can deliver the same performance with simpler orchestration. We evaluate different ratios across workload profiles and concurrency levels to measure their impact on TTFT, ITL, and throughput, and to see whether fixing the ratio in advance is a practical alternative to dynamic adjustment.
Introduction¶
What is Prefill–Decode disaggregation?¶
LLM inference has two distinct phases: prefill and decode. Prefill processes all prompt tokens in parallel and is compute-intensive. Decode generates tokens one by one, repeatedly accessing the KV-cache, making it memory- and bandwidth-intensive. DistServe (Zhong et al., 2024 ) introduced prefill–decode disaggregation to separate these phases across dedicated workers, reducing interference and enabling hardware to be allocated more efficiently.
What is the prefill–decode ratio?¶
The ratio of prefill to decode workers determines how much capacity is dedicated to each phase. DistServe showed that for a workload with ISL=512 and OSL=64, a 2:1 ratio met both TTFT and TPOT targets. But this example does not answer how the ratio should be chosen more generally, or whether it needs to change at runtime.
Reasoning model example
In the DeepSeek deployment (LMSYS, 2025 ), the ratio was 1:3. This decode-leaning split reflects reasoning workloads, where long outputs dominate. Allocating more workers to decode reduces inter-token latency and keeps responses streaming smoothly.
Dynamic ratio¶
Dynamic approaches, such as NVIDIA’s SLA-based and Load-based planners, adjust the ratio at runtime according to SLO targets or load. However, they do this in conjunction with auto-scaling, which increases orchestration complexity. This raises the question: does the prefill–decode ratio really need to be dynamic, or can a fixed ratio be chosen ahead of time and still provide robust performance?
Benchmark purpose¶
The aim of this benchmark is to test whether the prefill–decode ratio must be adjusted dynamically at runtime, or if a fixed split can perform just as well.
If a fixed ratio works across workload profiles and concurrency levels, it would mean the ratio can be chosen ahead of time, simplifying orchestration by removing the need for runtime ratio management.
We evaluate different ratios across workload types (prefill-heavy, decode-heavy, balanced) and concurrency levels to see how each affects TTFT, ITL, and throughput.
Methodology¶
To test this, we benchmarked different fixed prefill–decode ratios under varying workload profiles and concurrency levels. The experiments were run on a single node with 8xH200 GPUs, using SGLang to serve the model.
We compared three ratios—3:1, 2:2, and 1:3—at both low and high concurrency across three workload types:
- Prefill-heavy (ISL > OSL) — e.g., summarization: long inputs, short outputs.
- Decode-heavy (ISL < OSL) — e.g., reasoning: short inputs, long chains of thought.
- Balanced (ISL ≈ OSL) — e.g., translation, paraphrasing. Lower concurrency highlights intrinsic trade-offs (prefill-leaning improves TTFT; decode-leaning improves ITL and throughput). Higher concurrency reveals the true bottleneck. In real deployments, success means meeting TTFT/ITL SLOs and sustaining throughput for cost efficiency, so we evaluate both.
To evaluate performance, we measured TTFT, ITL, and throughput to capture both latency and efficiency.
Why these metrics matter
- TTFT (Time to First Token) captures perceived responsiveness—crucial for interactive experiences (e.g., support bots, code assistants).
- ITL (inter-token latency) captures streaming smoothness—critical for long, reasoning-style outputs.
- Throughput (tokens/sec) reflects cost efficiency. Prefill-heavy tasks (e.g., summarization of long docs) stress prefill; reasoning tasks stress decode. Maintaining high throughput ensures the under-stressed phase doesn’t leave GPUs idle. If a fixed ratio consistently performs well across these metrics, it would indicate that the ratio can be chosen ahead of time, without requiring runtime adjustment.
Benchmark setup¶
- GPU: NVIDIA 8xH200 (SXM5)
- CPU: Intel Xeon Platinum 8468
- Model:
openai/gpt-oss-120b - Backend: SGLang For full steps and raw data, see the GitHub repo .
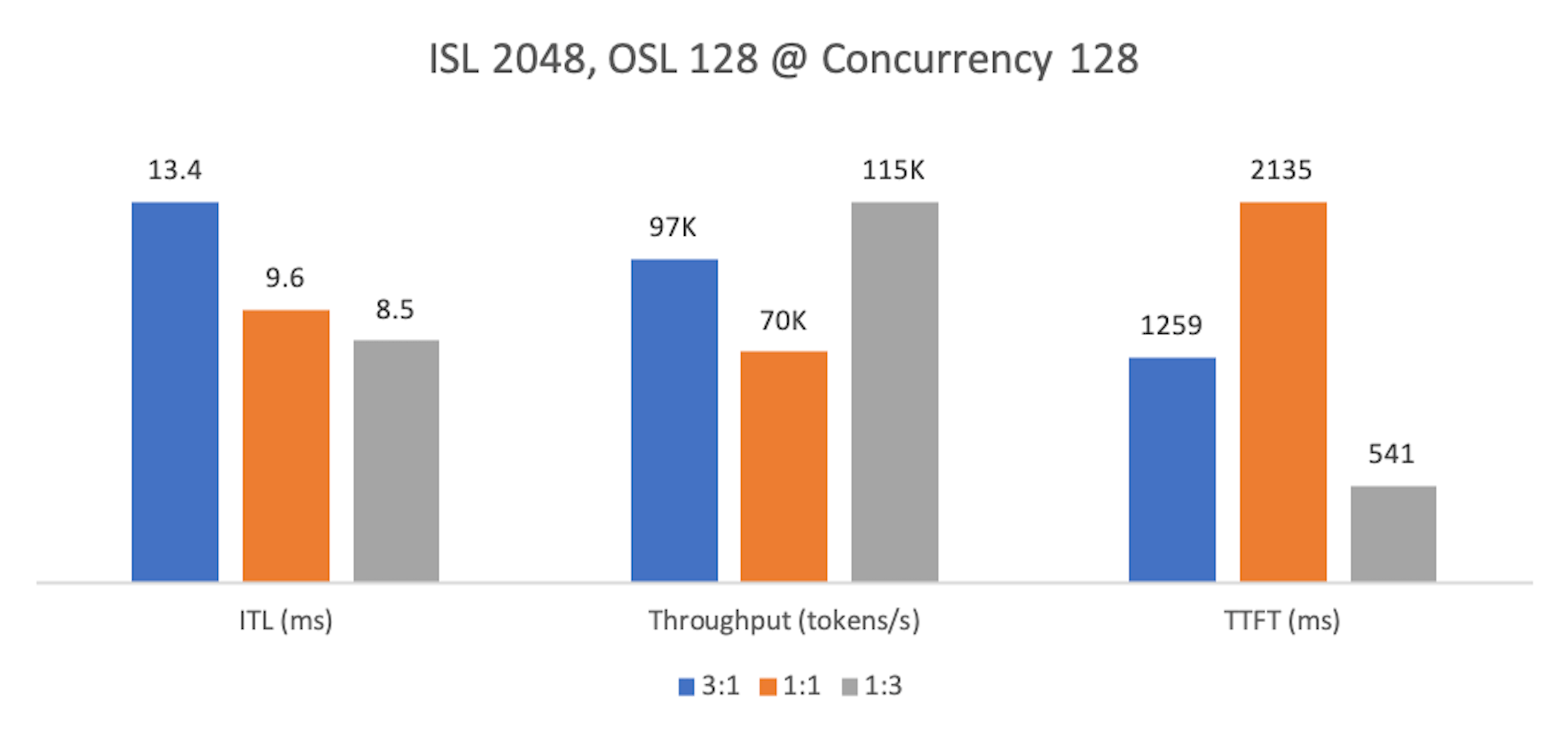
Finding 1: Prefill-heavy workloads¶
At lower concurrency, 1:3 yields the best ITL and throughput but the worst TTFT. Ratios 3:1 and 2:2 improve TTFT because more prefill capacity clears prompts faster. However, with 3:1, a single decode worker becomes a chokepoint—queues build up, ITL rises, and overall throughput drops.
At higher concurrency, 1:3 wins across all metrics. Because TTFT = prefill time + waiting at decode + time to first token, ample decode capacity trims the waiting component, improving TTFT even on prefill-heavy inputs.
In practice, summarization rarely has tight TTFT SLOs—users expect some delay after uploading long documents. Throughput and ITL dominate cost and experience, making 1:3 the recommended split for prefill-heavy workloads at both low and high concurrency.
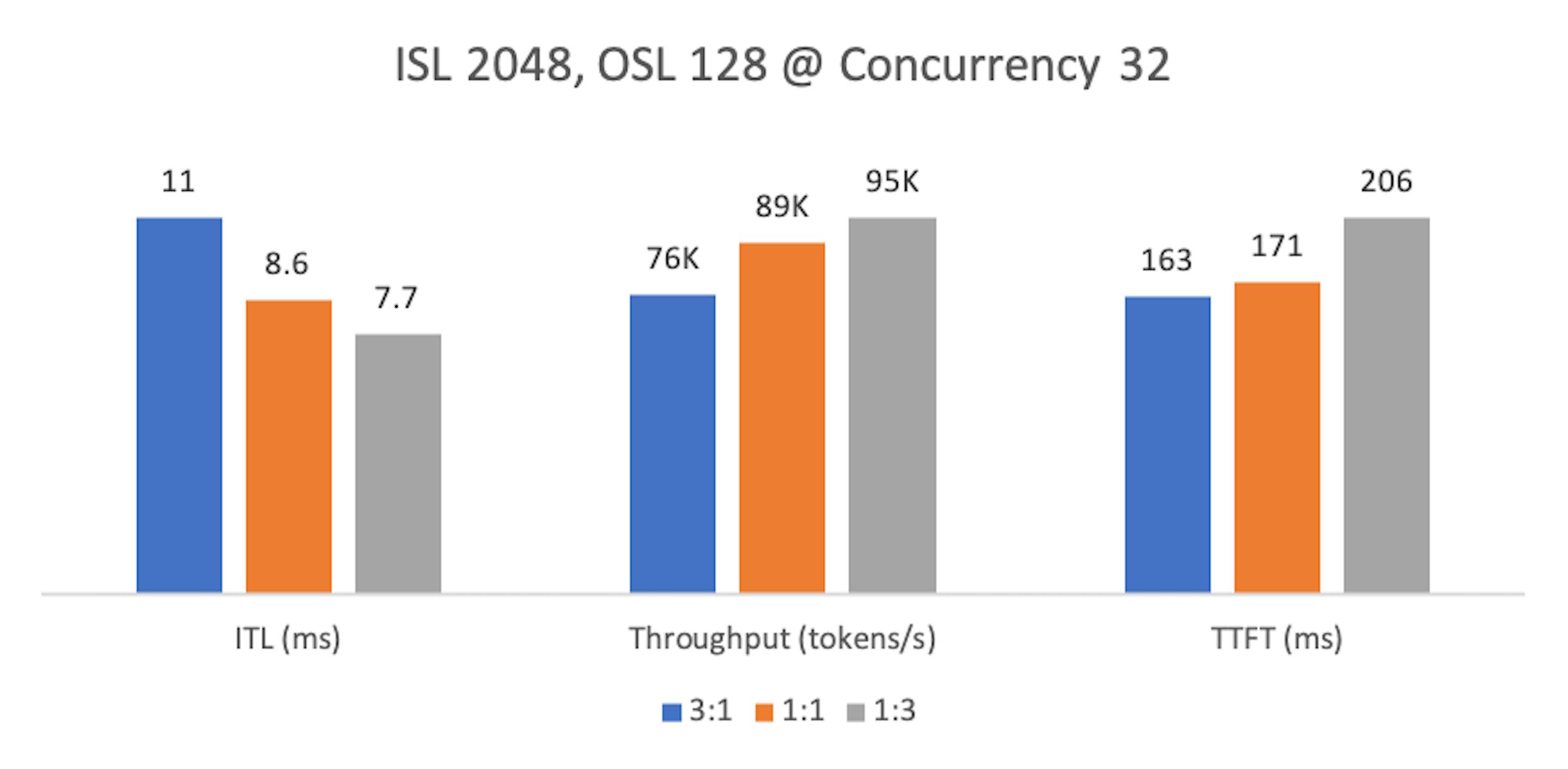
Metrics are normalized per chart: the best value for each metric is 100%; others are percentages of that maximum. Lower is better for ITL/TTFT; higher is better for Throughput.
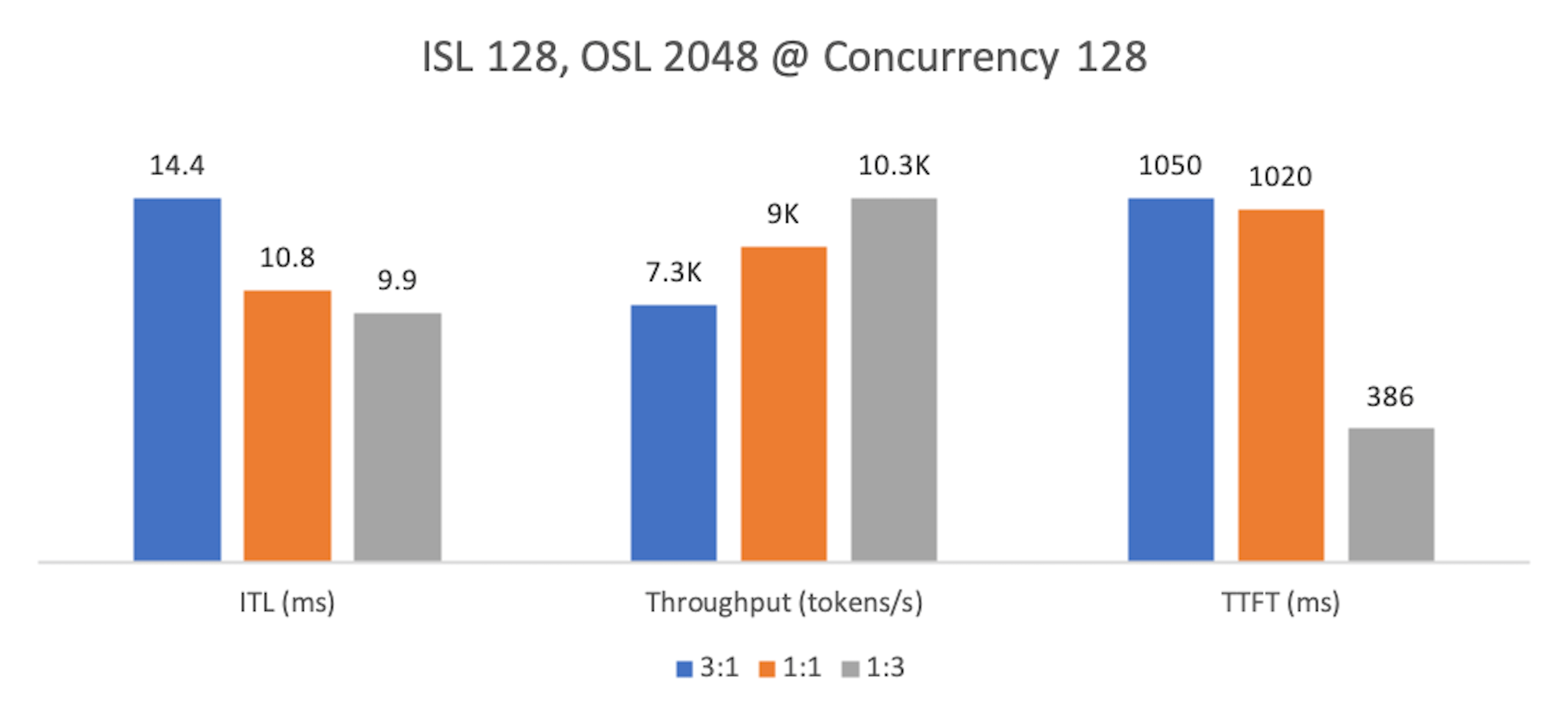
Finding 2: Decode-heavy workloads¶
As with prefill-heavy cases, at lower concurrency a 1:3 split delivers the best ITL and throughput, at the cost of higher TTFT. Ratios 3:1 and 2:2 improve TTFT but degrade streaming smoothness and throughput.
At higher concurrency, 1:3 again leads across all metrics.
For reasoning tasks, ITL is usually the tightest SLO—smooth, uninterrupted token streaming drives user experience. We recommend 1:3 for decode-heavy workloads at both low and high concurrency.
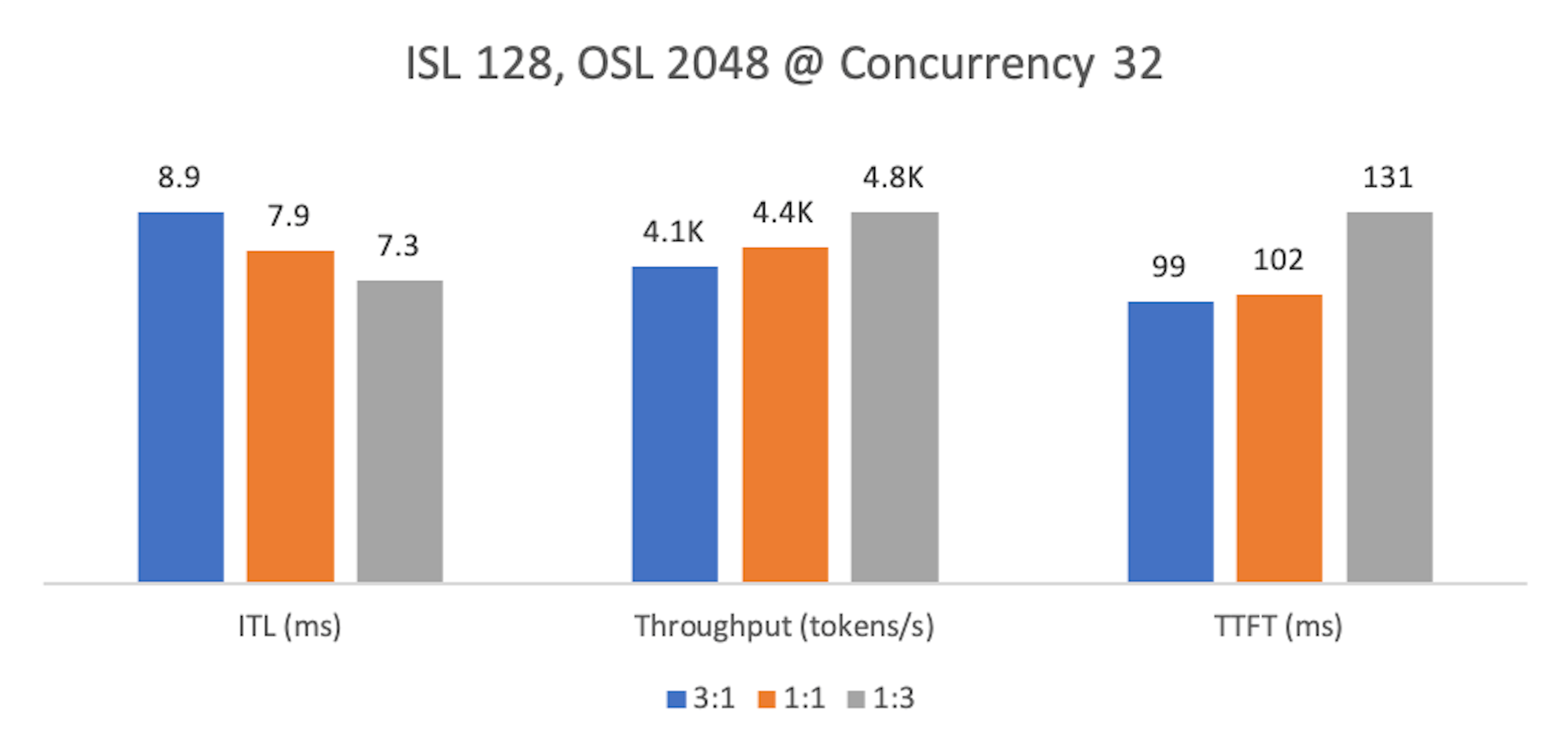
Metrics normalized as above. Lower is better for ITL/TTFT; higher is better for Throughput.
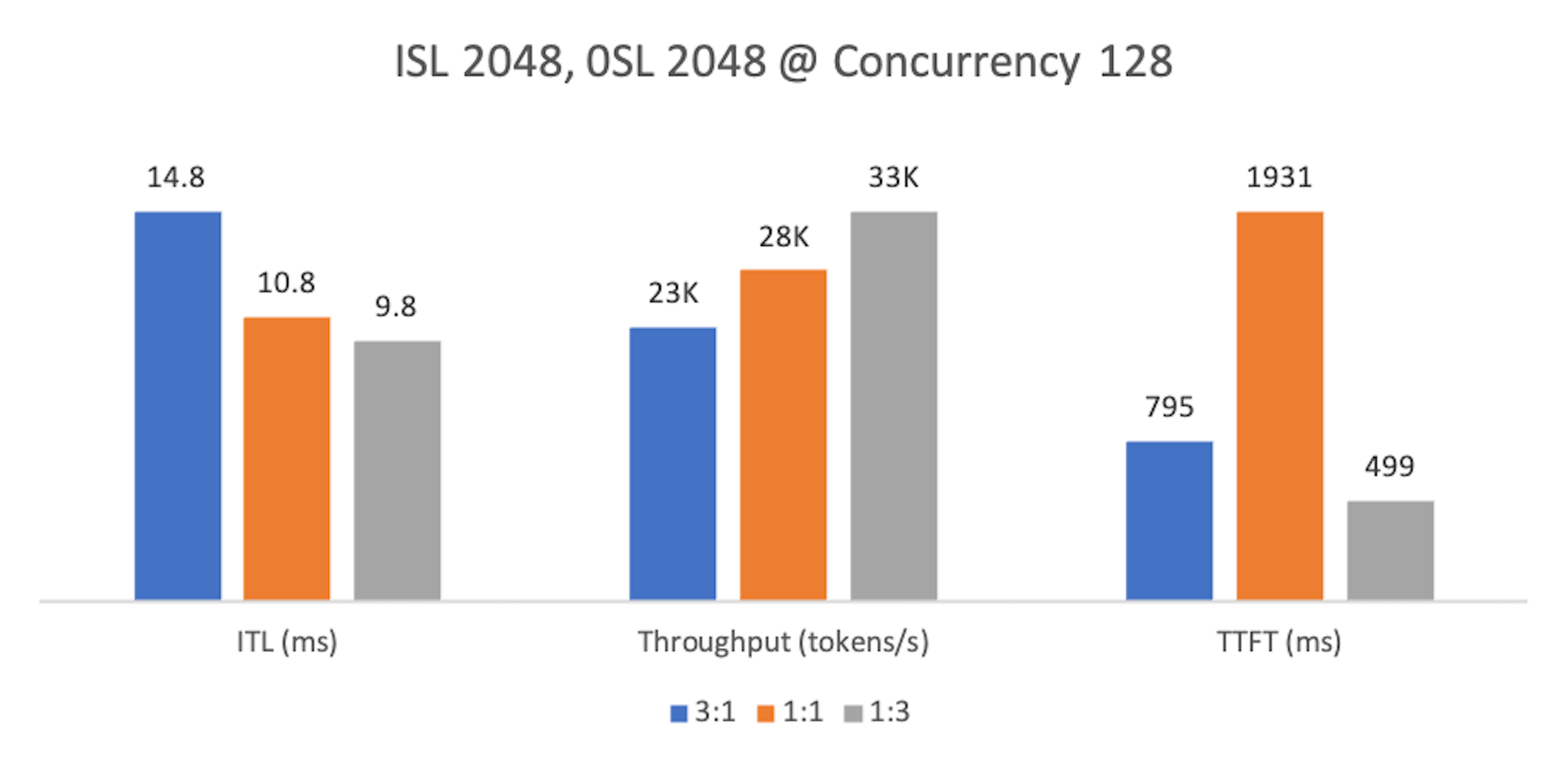
Finding 3: Balanced workloads¶
At lower concurrency, 1:1 provides the most balanced profile: better TTFT than the other ratios, with only modest trade-offs in ITL and throughput versus 1:3.
At higher concurrency, 1:3 regains the lead across metrics, while 1:1 sees TTFT degrade as decode pressure grows.
Since 1:1 becomes limiting under load, 1:3 is the safer default for balanced workloads—1:1 can offer slightly lower TTFT at light load, but 1:3 scales better and sustains higher throughput.
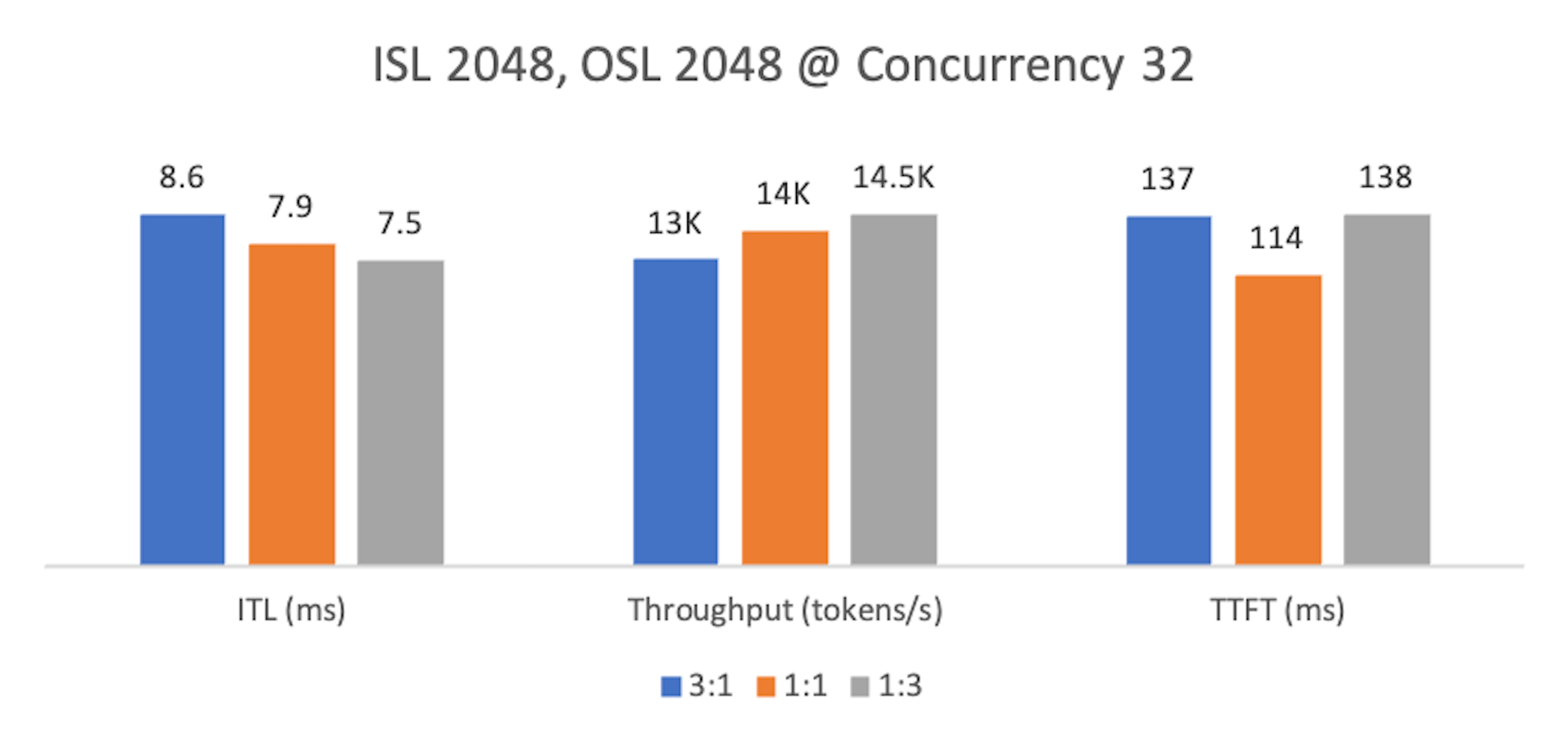
Metrics normalized as above. Lower is better for ITL/TTFT; higher is better for Throughput.
Conclusion¶
Across all workload profiles and concurrency levels, a fixed ratio delivered robust performance. This suggests that while dynamic planners (e.g., SLA- and load-based) provide a flexible framework for worker allocation, in many cases a fixed ratio combined with standard autoscaling can achieve similar outcomes with simpler orchestration.
A fixed ratio therefore serves as a practical baseline for Prefill–Decode disaggregation. Dynamic adjustment remains valuable when workloads are highly unpredictable, but when profiles are understood, setting the ratio in advance can reduce operational complexity without sacrificing performance.
Limitations¶
- This benchmark does not provide a method for determining the fixed ratio.
- The benchmark evaluated only a limited set of ratios: 3:1, 2:2, and 1:3.
- The benchmark does not directly validate whether dynamic ratio adjustment (e.g., NVIDIA’s planners) delivers better or worse performance compared with a fixed-ratio approach.
- The benchmark only considers tensor parallelism and not data parallelism, e.g. to assess how other forms of model parallelism interact with PD and affect latency/throughput trade-offs. Overall, more study on how the optimal ratio is found and what factors it depends on is required to ensure there is a simple and robust framework, ideally without overcomplicating orchestration.