Kosmos
Today, we are announcing Kosmos, our next-generation AI Scientist. Kosmos is a major upgrade on Robin, our previous AI Scientist. You can read about it in our technical report, here. Kosmos is available to use from day one on our platform, here.
*Today, management of our platform will also transition to Edison Scientific, our new commercial spinout. Edison Scientific is committed to maintaining a generous free tier, in line with FutureHouse’s commitment to accelerating the scientific community, while also ensuring that power users who need higher rate limits or additional features can pay for those features. Read more about Edison *[here](https://edisonscientific.com/articles/announ…
Kosmos
Today, we are announcing Kosmos, our next-generation AI Scientist. Kosmos is a major upgrade on Robin, our previous AI Scientist. You can read about it in our technical report, here. Kosmos is available to use from day one on our platform, here.
Today, management of our platform will also transition to Edison Scientific, our new commercial spinout. Edison Scientific is committed to maintaining a generous free tier, in line with FutureHouse’s commitment to accelerating the scientific community, while also ensuring that power users who need higher rate limits or additional features can pay for those features. Read more about Edison here.

Previous generations of AI Scientists, like Robin, have been limited primarily in their ability to synthesize large amounts of information. The finite context length of language models has meant that an AI Scientist can only take so many steps or make so many logical leaps before it runs out of road, limiting the complexity of the discoveries it can make. The core innovation in Kosmos is our use of structured world models, which allow us to efficiently incorporate information extracted over hundreds of agent trajectories and maintain coherence towards a specific research objective over tens of millions of tokens. An individual Kosmos run involves reading 1500 papers and running 42,000 lines of analysis code, far more than any other agent we are aware of.
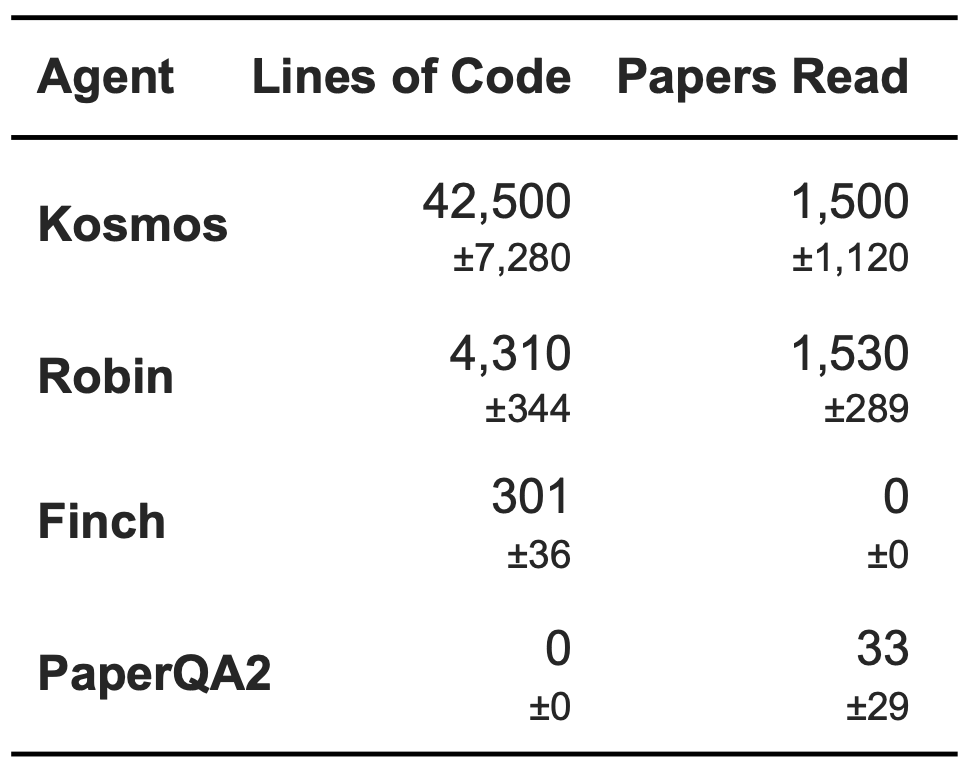
As a result, Kosmos can perform much more sophisticated analyses than previous tools, like Robin. Our beta users estimate that Kosmos can do in one day what would take them 6 months, and we find that 79.4% of its conclusions are accurate. The six month number shocked us, and we discuss it in more depth later in this blog post. We’re also announcing seven discoveries that Kosmos has made in areas ranging from neuroscience to material science and statistical genetics, in collaboration with our academic beta testers. The era of AI-accelerated science is here.
As with all the systems we have built, Kosmos is designed with transparency and traceability in mind. Scientific conclusions must be grounded in fact, but too many AI systems these days produce conclusions without clear provenance. By contrast, every conclusion in a Kosmos report can be traced through our platform to the specific lines of code or the specific passages in the scientific literature that inspired it, ensuring that Kosmos’ reports are fully auditable at all times. We have also validated Kosmos by using it both to replicate unpublished findings, and to make net new contributions to the scientific literature:
The discoveries
In the report, we describe seven discoveries Kosmos made. In three discoveries, Kosmos independently reproduced findings previously made by human scientists.
**• **In the first discovery, Kosmos reproduced a claim from a then-unpublished manuscript using metabolomics data, identifying nucleotide metabolism as the dominant altered pathway in hypothermic mice brains. The preprint describing the original work was published on BioRxiv after the Kosmos run was performed.
**• **In the second discovery, Kosmos reproduced a claim from a preprint that was published after the training data cutoff date of any LLM used in Kosmos and not accessed by Kosmos at runtime. Notably, this discovery was produced in materials science, demonstrating Kosmos’ range. In this discovery, Kosmos reproduced the finding that absolute humidity during thermal annealing is the dominant factor determining perovskite solar cell efficiency, including identifying the critical ‘fatal filter’ threshold above ~60 g/m³ where devices fail.
**• **In the third discovery, Kosmos identified the same mathematical rules that describe neuronal connectivity across species as reported in Piazza et al.. An important caveat to this discovery is that although Kosmos did not access this preprint at runtime, the preprint was published prior to the training data cutoff for the models that are used in Kosmos.
In an additional four discoveries, Kosmos made novel contributions to the scientific literature:
**• **In the fourth discovery, Kosmos used publicly available GWAS and pQTL data to perform a Mendelian randomization and provide statistical evidence that high levels of circulating superoxide dismutase 2 (SOD2) may causally reduce myocardial T1 times and myocardial fibrosis. Although the role of SOD2 in myocardial fibrosis has been documented in mice, this finding supports its relevance in humans.
**• **In the fifth discovery, Kosmos used publicly available multiomics and statistical genetics data to propose a novel molecular mechanism by which a single nucleotide polymorphism (SNP) may reduce the risk of developing Type 2 diabetes.
**• **In the sixth discovery, Kosmos developed a novel analytical approach to determine the sequence of molecular events leading to tau accumulation in neurons using proteomics data from Alzheimer’s Disease patients.
Finally, the seventh discovery showcases a novel, clinically relevant discovery. Tasked with the broad research objective of understanding neuronal vulnerability in aging, Kosmos performed a large-scale unbiased exploration of single nuclei transcriptomic data from young and old mice. Kosmos identified that entorhinal cortex neurons - the first neurons to develop tau accumulation in Alzheimer’s disease (AD) - have reduced expression of flippase genes with age. This reduction of flippase expression may lead to increased exposure of phosphatidylserine “eat me” signals at the cell surface, and could trigger microglia to engulf and degrade these vulnerable neurons. Critically, we were able to validate this finding in an orthogonal single-cell RNA-seq dataset from human AD cases. There, we observed a decrease in flippase expression in supragranular neurons from the entorhinal cortex at Braak stage II compared to a cortical-free stage (Braak 0), indicating that the decrease in flippase expression coincides with the appearance of tau pathology in that region. We are currently validating this discovery and others in the wetlab, and look forward to hearing about the discoveries Kosmos makes on data you provide it.
Caveats
Kosmos is available today for use on our platform. If you are going to try it, you should know a few things. Firstly, Kosmos is different from many other AI tools you might have played with, including our other agents. It is more similar to a Deep Research tool than it is to a chatbot: it takes some time to figure out how to prompt it effectively, and we have tried to include guidelines on this to help (see below). We are launching it at $200/run (200 credits per run, and $1/credit), with some free tier usage for academics. This is heavily discounted; people who sign up for Founding Subscriptions now can lock in the $1/credit price indefinitely, but the price ultimately will probably be higher. Again, this is not a chatbot: we think of it more like a reagent kit, something you run on high-value targets as needed.
Moreover, Kosmos certainly does produce outputs that are the equivalent of several months of human labor, but it also often goes down rabbit holes or chases statistically significant yet scientifically irrelevant findings. We often run Kosmos multiple times on the same objective in order to sample the various research avenues it can take. There are still a bunch of rough edges on the UI and such, which we are working on. If you encounter problems with your Kosmos runs, please get in touch at support@edisonscientific.com.
The 6 month estimate
The most surprising part of our work on Kosmos — for us, at least — was our finding that a single Kosmos run can accomplish work equivalent to 6 months of a PhD or postdoctoral scientist. Moreover, the perceived work equivalency scales linearly with the depth of the Kosmos run, providing one of the first inference-time scaling laws for scientific research. We were very skeptical when we first got this result. Here, we lay out why we think the statistic is valid.
Firstly, it is important to understand that these estimates were obtained by polling Kosmos beta users. The beta users would supply a research objective, we would run Kosmos for them (since our UI had not been constructed at the time), and supply them the outputs. We would then poll them on how much time they estimated it would have taken them to come to the same conclusion. The average, across 7 scientists, was 6.14 months for 20-step Kosmos runs. We performed the same measurement for more shallow runs, with blinded evaluation, thus leading to the scaling law presented in the technical report.
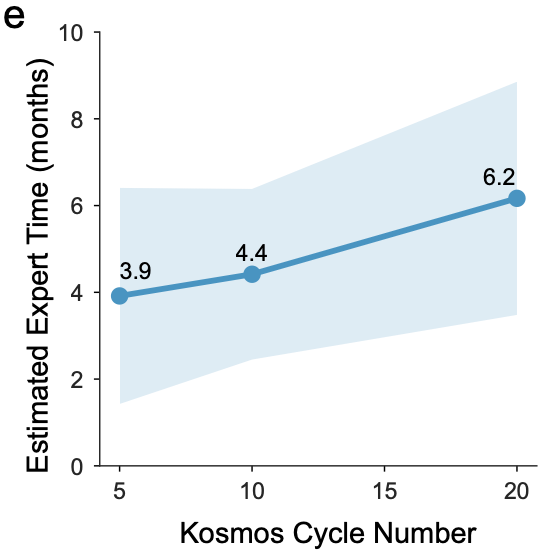
Human estimates of time saved are intrinsically suspect. However, there are two reasons we think that Kosmos’ work packages do actually equate to months of scientists’ time. Firstly, three of the discoveries presented in the technical report had been made previously by humans, but were either unpublished when we ran Kosmos, or (in one case) had been published after the cutoff of Kosmos’ models (and we ensured that Kosmos would not be able to find the publication or any papers that referenced it). In those cases, Kosmos was able to recapitulate the core findings that had been made previously by humans in a single run, and in each case, the original work necessary to make those findings amounted to ~4 months of work. This metric also has issues (what fraction of the scientists’ time was dedicated to making those discoveries during that time, for example?), but is a much more objective metric than our survey-based metric, and again suggests that the work Kosmos does in a single run can amount to months of human time.
The second reason we believe Kosmos’ work likely amounts to months of human effort derives from an independent estimate we produced. We estimated that a single paper takes 15 minutes for a scientist to read, and that a single data analysis trajectory takes roughly 2 hours to perform (aligned with METR’s estimates for the duration of software engineering trajectories that current agents can run). Tallying up the number of papers and number of analysis trajectories in an average Kosmos run yields about 4.1 months of time, assuming a 40 hour work-week.
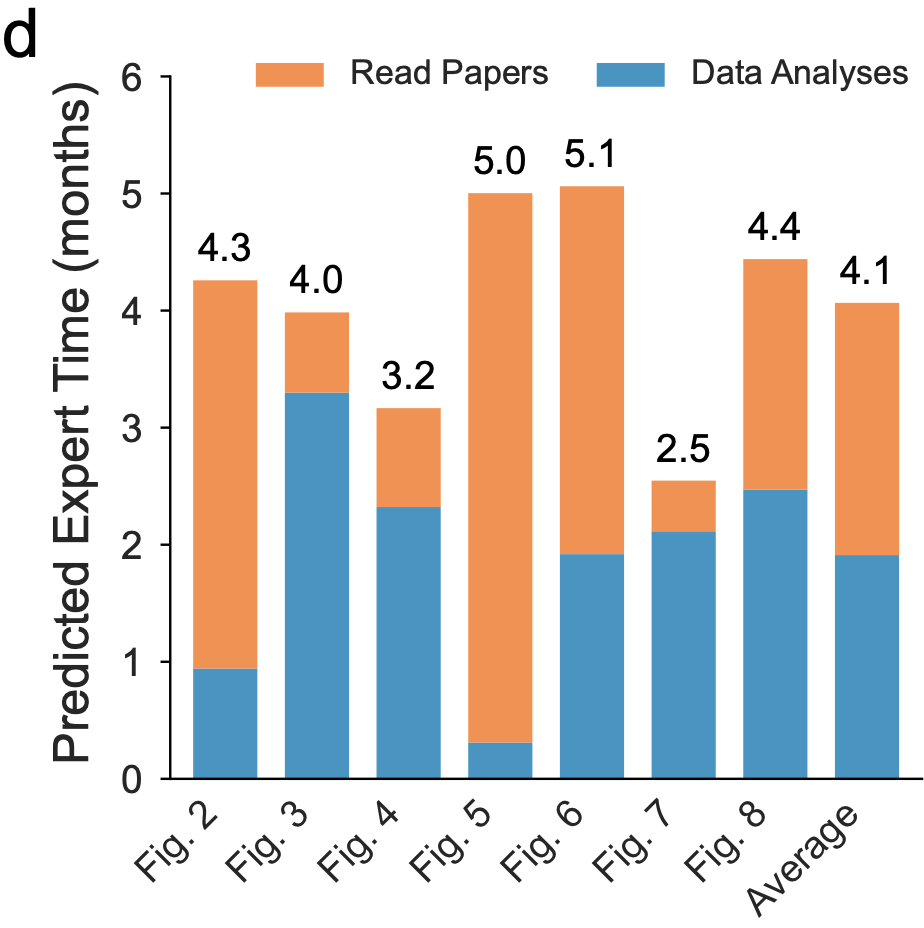
If we assume the 6 month estimate is correct, what does this mean for the field? Well, one conclusion is that evaluations such as the ones done by METR that attempt to measure the length of tasks that can be performed coherently by AI agents are likely overly simplistic. The maximum human-equivalent duration of tasks that AI agents are capable of performing today depends strongly on the kind of task being considered. This has been evident for some time: PaperQA2, a literature search agent which we launched more than a year ago based on GPT-4o, could write well-cited Wikipedia articles with superhuman accuracy, even though METR’s estimate suggested that GPT-4o is only capable of agentic tasks lasting between 4 and 15 minutes in human-equivalent time. (Certainly, writing a fully-cited Wikipedia article from scratch would take a human more than 15 minutes.) Mathematical proofs that are being produced today in a single shot by GPT-5 also seem highly likely to take more than 4 hours of human-equivalent time to produce, even though 4 hours is roughly METR’s estimate for the human-equivalent length of tasks that GPT-5 can perform. Thus, although we hold METR’s evaluation in extremely high regard, we believe the real situation with AI acceleration of human work may be more complicated.
Finally, the scaling law requires a further grain of salt in interpretation. It is true that our beta testers estimated that the human-equivalent time associated with a Kosmos run increases linearly with the depth of that run; however, our experience is also that the longer the Kosmos run, the more likely it is that Kosmos descends down a rabbit hole, chasing spurious statistical correlations or other unpromising avenues of inquiry. I expect that, if we actually extended the scaling law to its logical extreme, we might eventually see an inversion, where the value of a Kosmos run would begin to decrease with increasing depth. Improvements in the underlying language models, which we are working on actively, are likely necessary to combat this.
Thanks
A huge number of people contributed to Kosmos. Ludovico Mitchener led the design and engineering of Kosmos with significant support from Siddharth Narayanan, Tyler Nadolski, Mayk Caldas Ramos, and Edwin Melville-Green. Benjamin Chang led design of Kosmos discovery synthesis and report generation, as well as Kosmos evaluations. Angela Yiu led academic collaborations and provided critical feedback on Kosmos with significant support from Asmamaw (Oz) Wassie. Arvis Soluvari led the work described in Discovery 5. Jon Laurent coordinated human evaluation of Kosmos results. Michaela Hinks supervised and managed all work described in the technical report. Michael Skarlinski leads the Edison platform engineering team, including Andy Cai, Tyler Nadolski, Mayk Caldas, Remo Storni, Richard Magness, Sam Cox, and more, that makes all our work possible. Andrew White designed the world model, Sam Rodriques oversaw the scientific work and characterization of Kosmos, and Andrew and Sam together supervise work at Edison.
This work would not have been possible without significant contributions from academic collaborators, principally Mathieu Bourdenx, as well as Eric Landsness, Dániel L. Barabási, Nicky Evans, Tonio Buonassisi, Bruna Gomes, Shriya Reddy, Martha Foiani, and Randall J. Bateman