Introduction
In the world of digital services, accurate extraction of information from user-submitted documents such as identification (ID) cards, driver’s licenses, and registration certificates is a critical first step for processes like electronic know-your-customer (eKYC). This task is especially challenging in Southeast Asia (SEA) due to the diversity of languages and document formats.
We began this journey to address the limitations of traditional Optical Character Recognition (OCR) systems, which struggled with the variety of document templates it had to process. While powerful proprietary Large Language Models (LLMs) were an option, they often fell short in understanding SEA languages, produced errors, hallucinations, and had high latency. On the other hand, open…
Introduction
In the world of digital services, accurate extraction of information from user-submitted documents such as identification (ID) cards, driver’s licenses, and registration certificates is a critical first step for processes like electronic know-your-customer (eKYC). This task is especially challenging in Southeast Asia (SEA) due to the diversity of languages and document formats.
We began this journey to address the limitations of traditional Optical Character Recognition (OCR) systems, which struggled with the variety of document templates it had to process. While powerful proprietary Large Language Models (LLMs) were an option, they often fell short in understanding SEA languages, produced errors, hallucinations, and had high latency. On the other hand, open-sourced Vision LLMs were more efficient but not accurate enough for production.
This prompted us to fine-tune and ultimately develop a lightweight, specialized Vision LLM from the ground up. This blog is our account of the entire process.
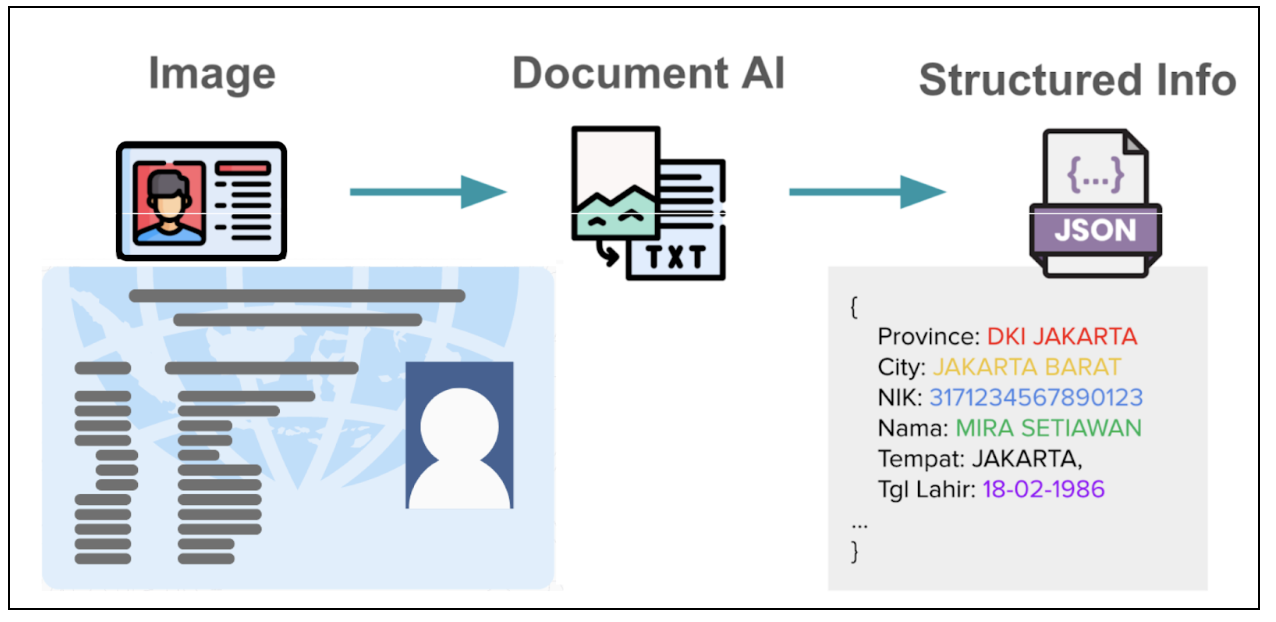 Figure 1: Simplified overview of how Vision LLM works.
Figure 1: Simplified overview of how Vision LLM works.
Background
What is a Vision LLM?
You’ve likely heard of LLMs that process text. You give the LLM a text prompt, and it responds with a text output. A Vision LLM takes this a step further by allowing the model to understand images. The basic architecture involves three key components:
- Image encoder: This component ‘looks’ at an image and converts it into a numerical (vectorized) format.
- Vision-language projector: It acts as a translator, converting the image’s numerical format into a representation that the language model can understand.
- Language model: The familiar text-based model that processes the combined image and text input to generate a final text output.
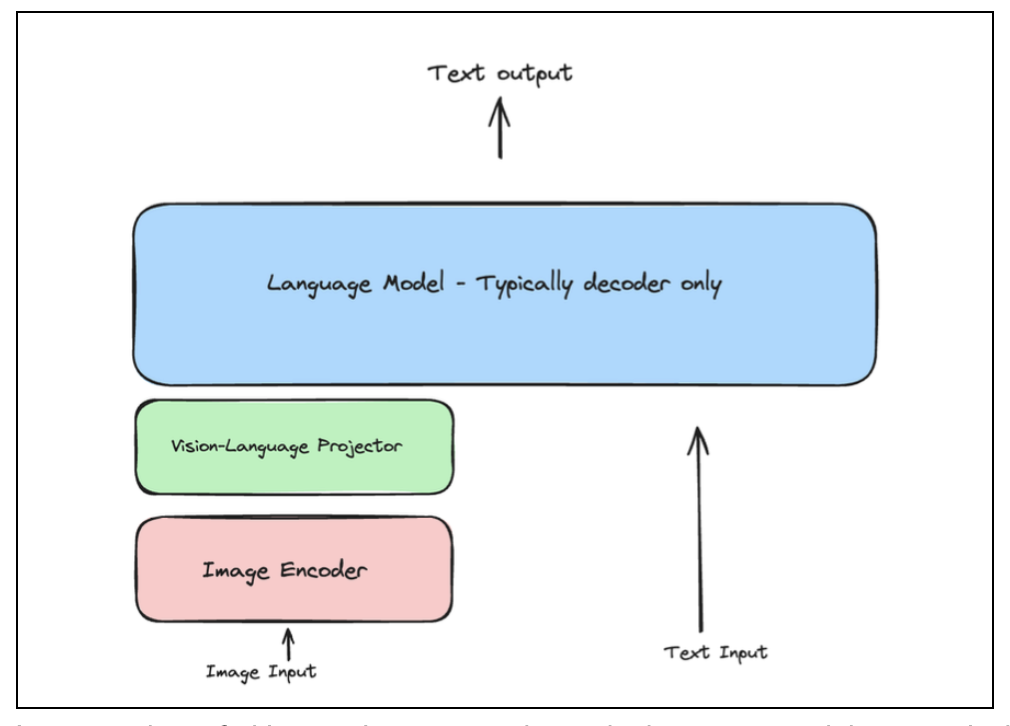 Figure 2: Vision LLM basic architecture.
Figure 2: Vision LLM basic architecture.
Choosing our base Vision LLM model
We evaluated a range of LLMs capable of performing OCR and Key Information Extraction (KIE). Our exploration of open-source options—including Qwen2VL, miniCPM, Llama3.2 Vision, Pixtral 12B, GOT-OCR2.0, and NVLM 1.0—led us to select Qwen2-VL 2B as our base multimodal LLM. This decision was driven by several critical factors:
- Efficient size: It is small enough for full fine-tuning on GPUs with limited VRAM resources.
- SEA language support: Its tokenizer is efficient for languages like Thai and Vietnamese, indicating decent native vocabulary coverage.
- Dynamic resolution: Unlike models that require fixed-size image inputs, Qwen2-VL can process images in their native resolution. This is crucial for OCR tasks as it prevents the distortion of text characters that can happen when images are resized or cropped.
We benchmarked Qwen2VL and miniCPM on Grab’s dataset. Our initial findings showed low accuracy, mainly due to the limited coverage of SEA languages. This motivated us to fine-tune the model to improve OCR and KIE accuracy. Training the LLM can be a very data-intensive and GPU resource-intensive process. Due to this, we had to address these two concerns before progressing further:
- Data: How do we use open source and internal data effectively to train the model?
- Model: How do we customize the model to reduce latency but keep high accuracy?
Training dataset generation
Synthetic OCR dataset
We extracted the SEA languages text content from a large online text corpus—Common Crawl (internet dataset). Then, we used an in-house synthetic data pipeline to generate text images by rendering SEA text contents in various fonts, backgrounds and augmentations.
The dataset contains text in Bahasa Indonesia, Thai, Vietnamese, and English. Each image has a paragraph of random sentences extracted from the dataset as shown in Figure 3.
 Figure 3: Two synthetic sample images in Thai language used for model training.
Figure 3: Two synthetic sample images in Thai language used for model training.
Documint: AI-powered, auto-labelling framework
Our experiments showed that applying document detection and orientation correction significantly improves OCR and information extraction. Now that we have an OCR dataset, we needed to generate a pre-processing dataset to further improve model training.
Documint is an internal platform developed by our team that creates an auto‑labelling and pre‑processing framework for document understanding. It prepares high‑quality, labelled datasets. Documint utilizes various submodules to effectively execute the full OCR and KIE task. We then used a pipeline with the large amount of Grab collected cards and documents to extract training labels. The data was further refined by a human reviewer to achieve high label accuracy.
Documint has four main modules:
- Detection module: Detect the region from the full picture.
- Orientation module: Gives correction angle (e.g. if document is upside down, 180 degrees).
- OCR module: Returns text values in unstructured format.
- KIE module: Returns JSON values from unstructured text.
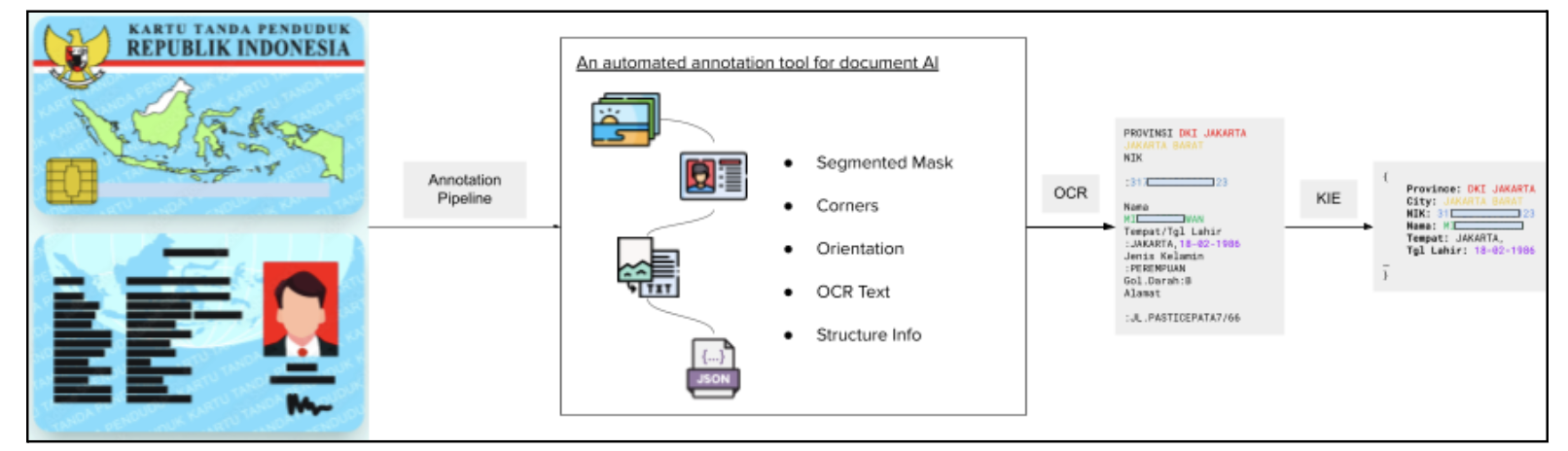 Figure 4: Pipeline overview of Documint.
Figure 4: Pipeline overview of Documint.
Experimentation
Phase 1: The LoRA experiment
Our first attempt in fine-tuning a Vision LLM involved fine-tuning an open-source model Qwen2VL, using a technique called Low-Rank Adaptation (LoRA). LoRA is efficient because it allows lightweight updates to the model’s parameters, minimizing the need for extensive computational resources.
We trained the model on our curated document data, which included various document templates in multiple languages. The performance was promising for documents with Latin scripts. Our experiment of LoRA fine-tuned Qwen2VL-2B achieved high field-level of accuracy for Indonesian documents.
However, the fine-tuned model still struggled with:
- Documents containing non-Latin scripts like Thai and Vietnamese.
- Unstructured layouts with small, dense text.
Phase 2: The power of full fine-tuning
Our experiments revealed a key limitation. While open-source Vision LLMs often have extensive multi-lingual corpus coverage for the LLM decoder’s pre-training, they lack visual text in SEA languages during vision encoder and joint training. This insight drove our decision to pursue full parameter fine-tuning for optimal results.
Drawing from the Large Language and Vision Assistant (LLAVA) methodology, we implemented a two-stage training approach illustrated in Figure 5.
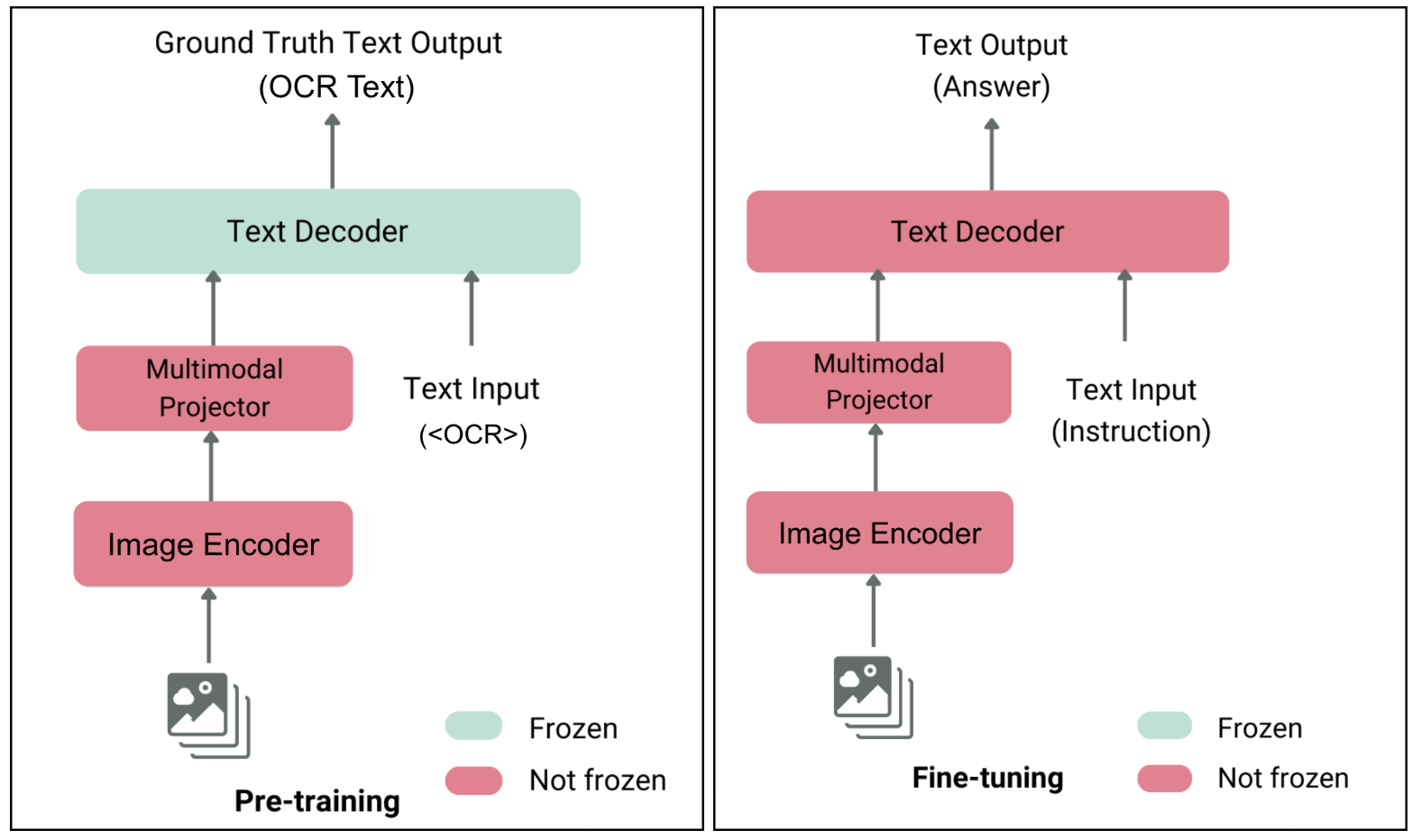 Figure 5: From left to right—two-stage training process.
Figure 5: From left to right—two-stage training process.
Stage 1 - Continual pre-training: We first trained the vision components of the model using synthetic OCR datasets that we created for Bahasa Indonesia, Thai, Vietnamese, and English. This helps the model to learn the unique visual patterns of SEA scripts.
Stage 2 - Full-parameter fine-tuning: We then fine-tuned the entire model—vision encoder, projector, and language model—using our task-specific document data.
Results:
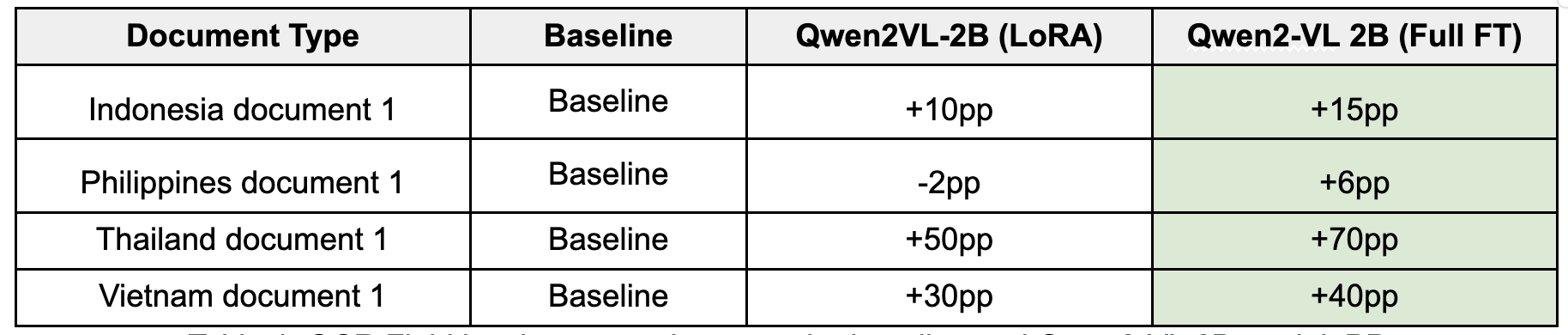 Table 1: OCR Field level accuracy between the baseline and Qwen2-VL 2B model. (pp: percentage points).
Table 1: OCR Field level accuracy between the baseline and Qwen2-VL 2B model. (pp: percentage points).
The fully fine-tuned Qwen2-VL 2B model delivered significant improvement, especially on documents that the LoRA model struggled with.
- Thai document accuracy increased +70pp from baseline.
- Vietnamese document accuracy rose +40pp from baseline.
Phase 3: Building a lightweight 1B model from scratch
While the Qwen2VL-2B model was a success, the full fine-tuning pushed the limits of GPUs. To optimize resources used and to create a model perfectly tailored to our needs, we decided to build a lightweight Vision LLM (~1B parameters) from scratch.
Our strategy was to combine the best parts of all models:
- We took the powerful vision encoder from the larger Qwen2-VL 2B model.
- We paired it with the compact and efficient language decoder from the Qwen2.5 0.5B model.
- We connected them with an adjusted projector layer to ensure they could work together seamlessly.
This created a custom ~1B parameter Vision LLM optimized for training and deployment.
Four stages in training our custom model
We trained our new model using a comprehensive four-stage process as shown in Figure 6.
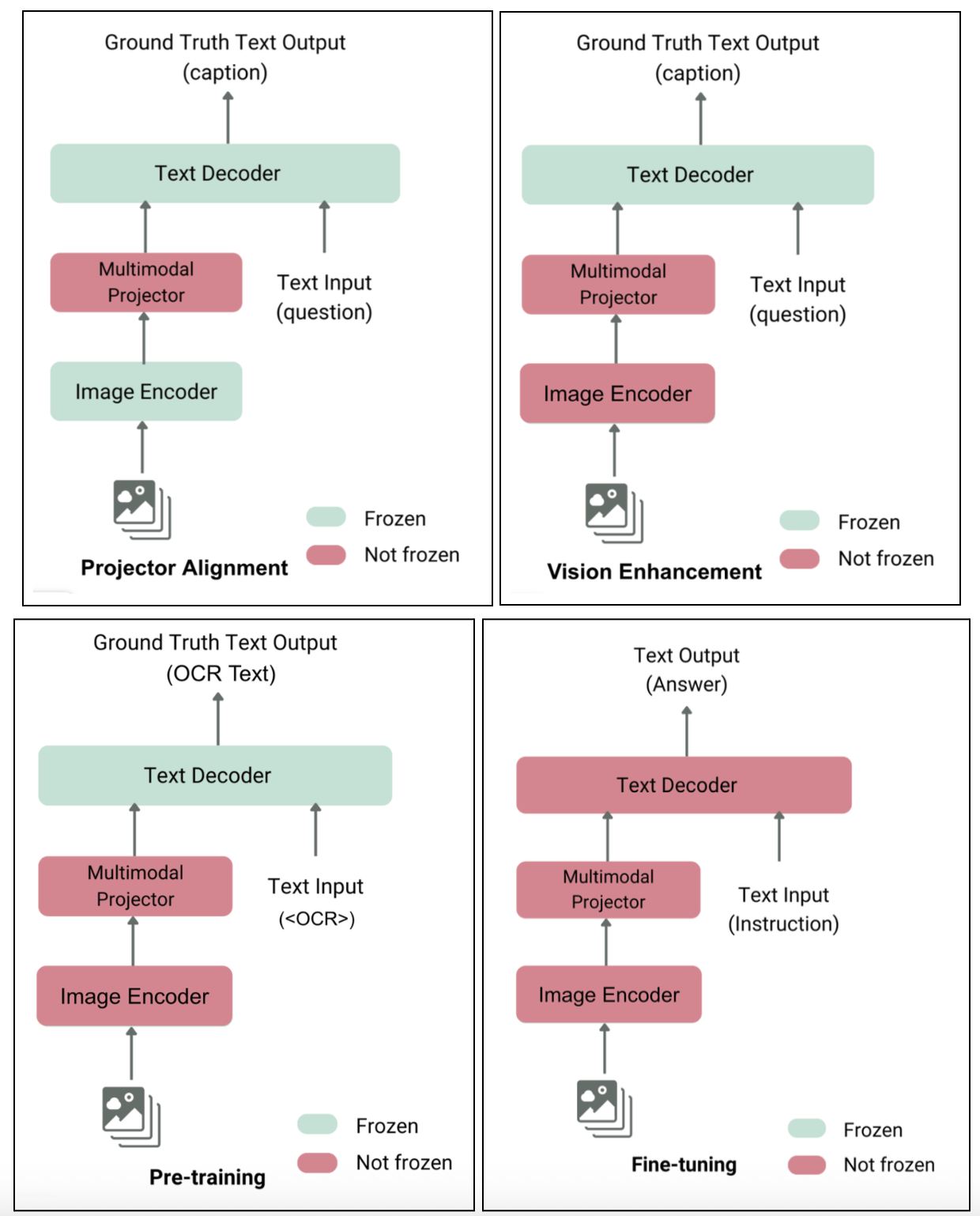 Figure 6: From left to right— four stages of model training.
Figure 6: From left to right— four stages of model training.
Stage 1 - Projector alignment: The first step was to train the new projector layer to ensure the vision encoder and language decoder could communicate effectively.
Stage 2 - Vision tower enhancement: We then trained the vision encoder on a vast and diverse set of public multimodal datasets, covering tasks like visual Q&A, general OCR, and image captioning to improve its foundational visual understanding.
Stage 3 - Language-specific visual training: We trained the model on two types of synthetic OCR data. Without this stage, performance on non-Latin documents dropped by as much as 10%.
Stage 4 - Task-centric fine-tuning: Lastly, we performed full-parameter fine-tuning on our custom 1B model using our curated document dataset.
The final results are as follow:
Accuracy:
- It achieved performance comparable to the larger 2B model, staying within a 3pp accuracy gap across most document types. The model also maintained strong generalization when trained on quality-augmented datasets.
Latency:
- The latency of our model far outperforms the 2B model, as well as traditional OCR models, as well as external APIs like chatGPT or Gemini. One of the biggest weaknesses we identified with external APIs was the P99 latency, which can easily be 3 to 4x the P50 latency, which would not be acceptable for Grab’s large scale rollouts.
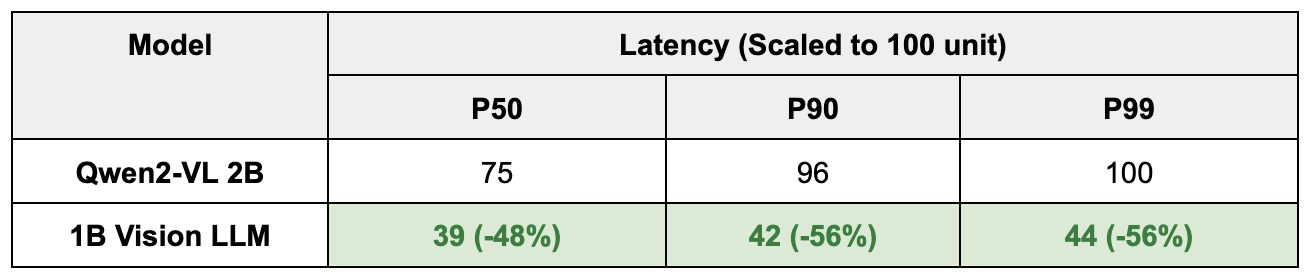 Table 2: Performance comparison between Qwen2-VL 2B and 1B sized Vision LLM.
Table 2: Performance comparison between Qwen2-VL 2B and 1B sized Vision LLM.
Key takeaways
Our work demonstrates that strategic training with high-quality data enables smaller, specialized models to achieve remarkable efficiency and effectiveness. Here are the critical insights from our extensive experiments:
- Full fine-tuning is superior: For specialized, non-Latin script domains, full-parameter fine-tuning dramatically outperforms LoRA.
- Lightweight models are effective: A smaller model (~1B) built from scratch and trained comprehensively can achieve near state-of-the-art results, validating the custom architecture.
- Base model matters: Starting with a base model that has native support for your target languages is crucial for success.
- Data is king: Meticulous dataset preprocessing and augmentation plays a critical role in achieving consistent and accurate results.
- Native resolution is a game changer: A model that can handle dynamic image resolutions preserves text integrity, dramatically improves OCR capabilities.
Our journey demonstrates that specialized Vision LLMs can effectively replace traditional OCR pipelines with a single, unified, highly accurate model—opening new possibilities for document processing at scale.
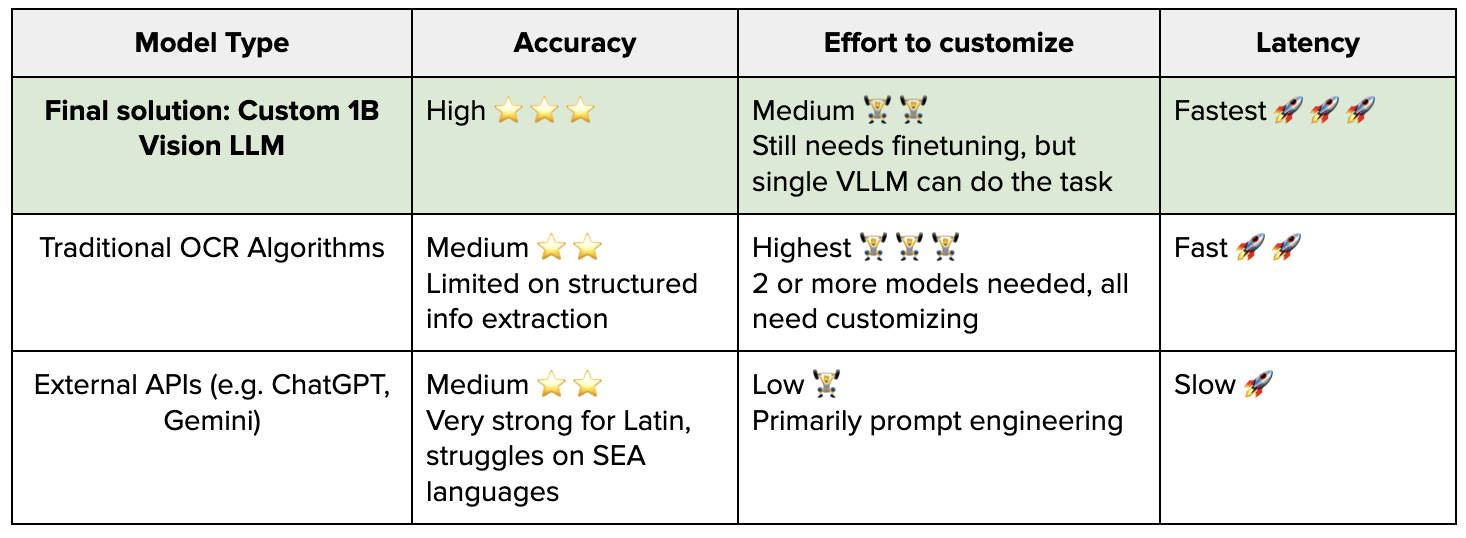 Table 3: Comparison of model types .
Table 3: Comparison of model types .
What’s next?
As we continue to enhance our Vision LLM capabilities, exciting developments are underway:
Smarter, more adaptable models: We’re developing Chain of Thought-based OCR and KIE models to strengthen generalisation capabilities and tackle even more diverse document scenarios.
Expanding across Southeast Asia: We’re extending support to all Grab markets, bringing our advanced document processing to Myanmar, Cambodia, and beyond.
References
- Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution: https://doi.org/10.48550/arXiv.2409.12
- Improved Baselines with Visual Instruction Tuning: https://doi.org/10.48550/arXiv.2310.03744
- SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models: https://doi.org/10.48550/arXiv.2107.09313
- LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models: https://doi.org/10.48550/arXiv.2403.13372
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!