Not too long ago aws suffered a large outage, which affected much of internet. I have heard of people trapped in sleeping pods, water dispenser displays showing http 503 “service unavailable”, people having to use the physical key to their smartlock, and even a bathroom that was shut down due to “aws outage”.11 Although I haven’t verified the sources, this seems plausible to me. Fermi estimation of the number of products sold that depend on DynamoDB directly or indirectly, and how many people use them, make weird reports less surprising.
aws published a summary where they concluded that
Customers experienced increased DynamoDB api error rates in the us-east-1 region. The root cause of this issue was a latent race condition in the DynamoDB …
Not too long ago aws suffered a large outage, which affected much of internet. I have heard of people trapped in sleeping pods, water dispenser displays showing http 503 “service unavailable”, people having to use the physical key to their smartlock, and even a bathroom that was shut down due to “aws outage”.11 Although I haven’t verified the sources, this seems plausible to me. Fermi estimation of the number of products sold that depend on DynamoDB directly or indirectly, and how many people use them, make weird reports less surprising.
aws published a summary where they concluded that
Customers experienced increased DynamoDB api error rates in the us-east-1 region. The root cause of this issue was a latent race condition in the DynamoDB dns management system.
One of the things I heard after the outage was
The race condition in the service updating dns records sounds obvious. I’m surprised no one caught it earlier.
This is classic hindsight bias. Once the issue has been brought to our attention, it is going to look obvious. But the dns management system, like any piece of software, is riddled with reliability issues. Some of them we happen to pay attention to, and others slide by unnoticed. We know some of the dns management system reliability issues have been caught earlier, because the summary report gives off subtle hints at which ones.
{kind=link}
The problem isn’t that the issues aren’t obvious. By the metric of “would I understand this is a problem if someone explained it to me”, almost all issues are obvious. The problem is one of directing our attention: we are not great at paying attention to all things that go on to become problems later.
The system-theoretic process analysis (stpa) is a somewhat mechanical set of steps that direct our attention to things that can turn into problems in the future.22 Originally stpa was created for safety-critical systems, but we can use it to prevent outages in less critical software systems too. Would applying stpa to the dns management system have uncovered the problems that caused the outage, even before the outage happened?
It turns out yes, even as an amateur outsider, I could perform stpa on limited public information and find that:
- stpa uncovers all problems that conspired to cause the outage.
- stpa additionally uncovers other problems that could cause an outage in the future.33 And which aren’t mentioned in the summary report.
- stpa is easy enough that we can perform a rough analysis in a couple of hours of our spare time.
Given how expensive this outage must have been, it seems like a clear win for applying stpa regularly during the development process, and not waiting until an outage occurs.
We will perform an STPA based on summary information
Here’s how we’ll learn the usefulness of stpa: We’ll take the description of the system as given in the aws summary report and perform a very light stpa on it. We’ll note which problems it uncovers, and see how well they map onto the timeline of the outage. Then we’ll see if there are problems uncovered by stpa that are not revealed by the summary report. We’ll try to avoid hindsight bias by applying the steps of stpa as mechanistically as possible.
This means what we’re producing in this article is not a post-mortem, but more of a pre-mortem. There are system-theoretic approaches to post-mortems as well (cast is the one I like), but a proper post-mortem would require access to people at aws to ask a bunch questions with potentially embarassing answers. I don’t have that kind of access.
We are still going to cheat a little and focus our analysis on the contributing components of the system, but that’s merely an optimisation to save time in reading and writing this article – it shouldn’t affect the outcome.44 In other words, we will not let our knowledge of the problem guide our search, but we will more aggressively prune branches of the search that we know will not lead toward the problem. This should improve the precision of the analysis without misrepresenting the recall of the method, to borrow terms from information retrieval.
I should also say that this analysis does not by any means attempt to fully model or specify the DynamoDB dns management system which is surely more complicated and interesting in reality. The purpose of this article is to illustrate the ways in which stpa can shine a light on failure modes that other analysis methods easily overlook.
STPA is about critically studying unsafe control actions
I want to eventually convince you that root cause analysis is a crap technique, and that analysis based on systems theory is a strict improvement. However, I haven’t been able to write a well-presented argument, so instead I’m going to slowly bombard you with vignettes until you submit.
The previous – and first – article was about hazardous states and accidents, where we explained that we avoid outages by staying out of hazardous states, and that we cannot set up an equation that fully explains how our system will stay out of hazardous states, but that it is a dynamic control problem. Read that article for some necessary context to this one.
Once we accept that safety is a dynamic control problem, stpa helps us find flaws in our control structure. By asking the questions stpa tells us to ask, we will find out about
- Missing controllers,
- Inadequate process models in existing controllers,
- Missing feedback paths,
- Problems that can arise if feedback is delayed,
- How conflicting goals affect system safety,
- etc.
The way stpa does this is by focusing on the control inputs, i.e. the things controllers do to keep the system clear of hazardous states. We systematically go through each control input and reason about typical ways in which it might contribute to entering a hazardous state.
This is a lightweight way to discover many problems – if we didn’t have to explain it in a blog post, the analysis in this article could be performed in maybe two hours. Compared to having an expensive outage, that seems like a good use of time to me.
Let’s get cracking!
STPA is made from four parts
On a high level, there are four parts to an stpa:
- Define purpose of analysis.
- Model the control structure.
- Identify unsafe control actions.
- Develop loss scenarios.
The first step means figuring out what it is we are dealing with and what the potential safety issues are. In this case, we are dealing with the dns management system for DynamoDB and the safety issues are bad dns records.
To model the control structure of the system means to sketch out which the controllers are, what feedback they receive, and which control inputs they can provide to steer the system clear of hazardous states. If you need a refresher on this, you should read the article on hazardous states and accidents.
After that, we identify what the unsafe control actions would be. An unsafe control action is when a controller either provides a control input that makes things worse (positive case), or when it withholds a control input that would be needed to steer clear of hazardous states (negative case). An example of the positive case is when fail2ban55 Firewall automation software that reads logs and tries to infer illegitimate users from their access patterns. prevents the server administrator from connecting. A typical example of a negative case is when anti-cheat software does not remove a player that is using game exploits to get an unfair advantage. Both the positive and negative cases are called unsafe control actions, even though in one case there is no control input at all and indeed that is the problem.
The fourth step is to go through a set of semi-standard ways in which these unsafe control actions can arise. This could obviously happen when system components malfunction, but it is important to also think of situations in which everything works as expected, but an unsafe control action still arises. This is extremely common in software systems, because software never really fails in the way a hardware component does; software always behaves exactly as designed, only sometimes the design is bad.
These four parts of stpa are normally explained as sequential steps, but in reality we will go back and forth between them as we think of things to add to earlier steps, or things turn out irrelevant and can be removed from earlier steps.
If you want more detail, the stpa Handbook66 stpa Handbook; Leveson and Thomas; self-published; 2018. Available online. is excellent. On to step one: figure out what sort of system we are dealing with.
System and accident description
Since we don’t work at aws, we’ll have to get our understanding of the system from the summary of the outage.
The DynamoDB dns management system is split across two independent components: the dns Planner and the dns Enactor.
The dns Planner monitors the health and capacity of the DynamoDB load balancers and periodically creates a new dns plan for each DynamoDB region. The plan consists of a set of load balancers and weights.
The dns Enactor operates redundantly and fully independently in three different availability zones. Each of the instances of the dns Enactor looks for new plans and attempts to update Route53 by replacing the current plan with a new plan using a Route53 transaction, assuring that each endpoint is updated with a consistent plan even when multiple dns Enactors attempt to update it concurretly.
The normal way things work, a dns Enactor picks up the latest plan and begins applying this plan to each of the DynamoDB regions one at a time. Before it begins to apply a new plan, the dns Enactor checks that its plan is newer than the currently active plan. Once a plan is applied, the dns Enactor runs a clean-up process, which deletes plans that are significantly older than the one it just applied.
As the dns Enactor makes its way through the list of endpoints, it is possible to encounter delays as it attempts a transaction and is blocked by another dns Enactor updating the same endpoint. In these cases, the dns Enactor will retry each endpoint until the plan is successfully applied to all endpoints.
We get additional information on how the system works from the outage timeline. It might seem like cheating to look at the outage timeline when we are trying to prove we would find the bug before the outage happened, but we will not use the timeline information to guide our safety analysis. We use the timeline only to reverse engineer the system from the outside. If we worked at aws, we would be able to build the model without reading any outage timelines.
- One Enactor experienced unusually high delays needing to retry its update on several of the dns endpoints.
- The Planner continued to run and produced many newer generations of plans.
- One of the other Enactors then began applying one of the newer plans and rapidly progressed through all of the endpoints, overtaking the delayed Enactor.
- At the same time that the clean-up process was invoked in the second enactor, the first Enactor caught up and applied its much older plan to dynamodb.us-east-1.amazonaws.com, overwriting the newer plan. The check that was made at the start of the plan application process, which ensures that the plan is newer than the previously applied plan, was stale by this time due to the unusually high delays in Enactor processing. Therefore, this did not prevent the older plan from overwriting the newer plan.
- The second Enactor’s clean-up process then deleted this older plan because it was many generations older than the plan it had just applied.
- As this plan was deleted, all ip addresses for the regional endpoint were immediately removed, which resulted in an incorrect empty dns record for dynamodb.us-east-1.amazonaws.com.
- Because the active plan was deleted, the system was left in an inconsistent state that prevented subsequent plan updates from being applied by any dns Enactors.
We will use this information to paint a picture of how the system might work.
Modeling the control structure
Because it provides a clear view of the system, we’ll start with the drawing of the control structure. We are only including two Enactors here because they are sufficient to show any interaction issues – a full analysis would include all three.77 Again, it might sound like cheating that we know we have to include multiple copies of the Enactors in our model, but multiple controllers that can issue conflicting control actions is typical of complex systems and definitely something we will account for in every stpa. Even the shallowest analysis will include at least two copies of replicated controllers.
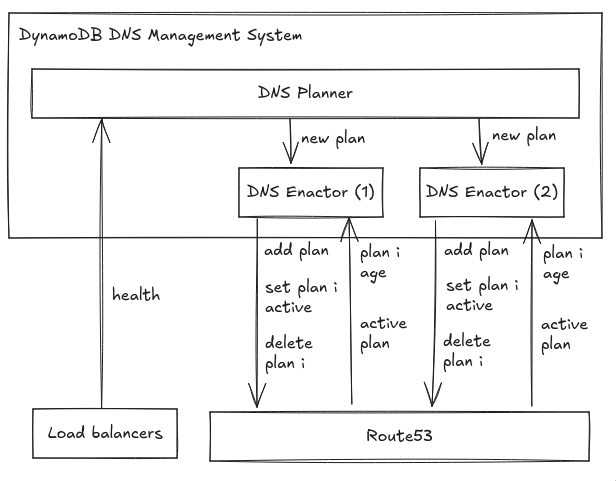
In a drawing like this, arrows pointing up indicate feedback, or flow of information:
- the Planner recieves health data from load balancers;
- the Enactors can query Route53 for which plan is active, as well as the age of plans (in order to delete ones that are significantly older than the just applied one.)
Arrows pointing down indicate control inputs, i.e. controllers asking lower-level components to make changes to enforce the safety constraints.
-
Technically, the Planner probably does not push new dns plans onto the Enactors, but rather write them to shared storage from which the Enactors read the most recent plan. This is good design because it decouples the Planner from the Enactors. However, from the perspective of the safety control structure, the Planner still effectively provides a control command to the Enactors by writing out a new dns plan to be applied.
-
The Enactors more directly push commands to Route53:
-
They can add new dns plans.
-
They can set any plan as the currently active plan.88 That’s an assumption on our part – otherwise it would make little sense to keep old plans around at all and not just replace the currently active plan wholesale.
-
They can delete any plan – including the currently active one, apparently!
These are things we have to assume based on the descriptions above. Someone working with this system would be able to make more accurate statements.
Definitions and hazards
Now that we know what sort of system we have, we’ll have to think about what the hazardous states are. Since the purpose of the system is to allow users to connect to DynamoDB, we will simplify for ourselves and talk about dns plans as being “good” or “not good”. We could define this more technically along the lines of “containing at least n load balancers, of which none are unhealthy”, but we’ll leave the specifics of these definitions up to the people who work with this system.99 dns plans can also be “better” or “worse” than each other, but these are generally efficiency concerns, not relating to safety. In terms of safety, we want to prevent plans that are not good, and if a plan that is not good is active, we have already failed.
When performing stpa, it’s important that the hazardous states are given at a high level. Christensen talks about the-job-to-be-done, and that’s the right level of abstraction for hazards too. Thus, the main hazard we want to avoid is that the currently active dns plan is not good. That will allow the system to fulfill its primary purpose.1010 The stickler will note that the-job-to-be-done is actually the dns lookup by the user, and we should phrase the hazardous state in terms of that instead. That would pull in a bunch of other systems into the analysis, which would be useful if we wanted to prevent outages, but not when we want to write a coherent article inspired by this outage.
The summary of the outage also hints at a second hazard: since an important function of the Enactor is clearing out old plans, we can assume that Route53 plan storage being near full is another hazard we need to avoid. This is not a high-level hazard, because it is actually a consequence of maintaining a good active dns plan, but we’ll be explicit about it, specifically, and not other derived component-level hazards, because it played a part in this outage.
The real system probably has more hazardous conditions it needs to control for, but they do not present themselves in the summary of the outage, so we will ignore them for now.
Identifying unsafe control actions
Now that we know what the hazards are, we start thinking about how control inputs interact with these hazards. There are five typical ways control actions can be unsafe:
- A control input is needed to prevent a hazard, but it is not provided.
- A control input is provided in a situation where it leads to a hazard.
- A control input is required and provided, but it is provided too early or too late.1111 In the case of multiple control inputs being provided together, it can help to think of them as being provided in the wrong order, even though it boils down to “too early” and “too late” for individual control inputs.
- A control input is required and provided, but it is stopped too soon or applied for too long.
- A control input is required and provided, but it is given with a parameter that is too low, or too high.
Note that any of these can occur when the system works perfectly fine as designed, only they’re situationally incorrect in the finer details. The fact that stpa provides us with these cues is very helpful.
To identify unsafe control actions, we look at each of the four control inputs that exist in the system, and go through the five ways they can become unsafe control actions.
For example, providing the control input to add a dns plan to Route53 is an unsafe control action if Route53 is nearly full – then that control input pushes it into a hazardous state. On the other hand not providing the same control input is an unsafe control action if Route53 currently has no good plans.
The table below is sectioned into control inputs, and circumstances under which they become unsafe control actions.
| Unsafe control actions | | | ––––––––––– | | | Control input | New plan (Planner) | | Not provided | Previous plan is not good | | Provided | New plan is no longer good | | Sequencing | | | Duration | n/a (transaction) | | Parameter | n/a (binary action) | | Control input | Add plan (Enactor) | | Not provided | There are no good plans | | | Special case: there are no plans at all | | Provided | Storage is nearly full | | Sequencing | | | Duration | n/a (transaction) | | Parameter | n/a (binary action) | | Control input | Set plan i active (Enactor) | | Not provided | The active plan is not good | | | Special case: there is no active plan | | Provided | Plan i is not good | | Sequencing | Before Plan i is added | | | Plan i has been deleted | | Duration | n/a (transaction) | | Parameter | n/a (binary action) | | Control input | Delete plan i (Enactor) | | Not provided | Storage is nearly full | | Provided | Plan i is active | | Sequencing | Plan i needs to be reinstated | | Duration | n/a (transaction) | | Parameter | n/a (binary action) |
From this table we can note some general tendencies, most of which are perhaps obvious.
- The safety of issuing a new plan depends mostly on whether the new or old plans are good.
- Adding a plan to Route53 is generally safe, and we should probably err on the side of adding too much rather than not enough.
- Setting a plan active is a dangerous operation which can go wrong in many different contexts.
- Deleting a plan is rarely necessary, and is generally safe – unless that plan is or will become active!
Normally we compress this table down into a list of unsafe control actions. Each is worded according to a standard format, like this:
- Planner does not issue a new plan to Enactors when the latest plan is not good.
- Planner issues a new plan to Enactors even when the plan is no longer good.
- Enactor does not add a plan to Route53 when there are no good plans in Route53.
- Enactor adds a plan to Route53 when storage is nearly full.
- Enactor does not activate plan i when the active plan is not good.
etc. These all represent excrement-meet-air-circulation-device situations, and so for each one, we want to ask “Why on Earth would this happen?” To help us figure that out, we can follow a semi-standardised set of cues that come with stpa, and doing so is the fourth step of stpa: developing loss scenarios.
Developing loss scenarios
We’ll have the following generic sketch in mind. It represents the relationship between the controller and the controlled system, as well as the things through which that relationship is mediated.
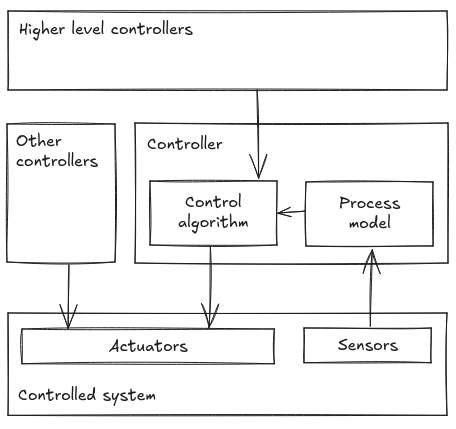
This highlights the ways in which unsafe control actions typically arise. These are divided into four classes:
- The unsafe control action happens despite the input to the controller being good. Typical reasons include inadequate control algorithm and incomplete process model.
- The controller provides an unsafe control action because its input indicated that was the right thing to do. This can happen when e.g. a higher level controller gives this controller an objective that is in conflict with providing the safe control action. The other main reason this happens is because the feedback is inadequate; either there’s not enough of it, not of the right kind, or it is delayed, or it contains measurement inaccuracies.
- The controller provides a safe control action, but the controlled system never receives it. This could also be caused by delays in the system, or by other controllers providing conflicting control inputs.
- The safe control action was received, but it never had the desired effect. This can happen because we run out of required resources, or the system chooses to ignore the command because it was designed to in that particular context, or indeed hardware failures.
The rest of this section will contain a subsection for each unsafe control action, and some notes on how it might arise, driven by the four classes of scenarios above.
New plan is not issued when the latest plan is not good
For the first unsafe control action, we’ll go into slightly more detail to clarify how this is done. Looking at the generic controller–controlled relationship sketch, we can be more specific in terms of this unsafe control action.
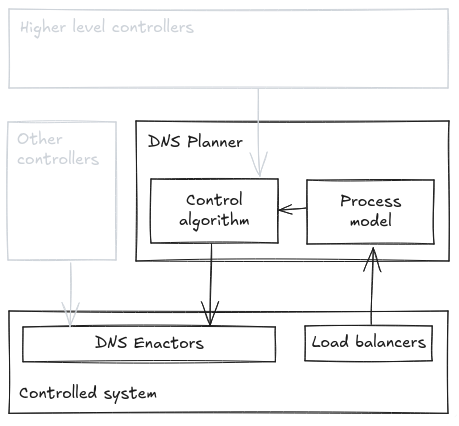
The controller from whose perspective we’ll start the analysis of this unsafe control action is the Planner. We are not made aware of any other controllers that can issue conflicting control actions, so we’re greying them out in the diagram.
While there surely are higher level controllers (at least sres and software engineers, as well as aws management, etc.) we will not model them here in order to get to our point faster. A fuller analysis would account for how they interact with the system too, because it’s not strange for human–computer interaction to contribute to outages.
The controlled system encompasses both the Enactors and the load balancers, since only the latter provide feedback.
As a reminder, the unsafe control action we are looking at now is
New plan is not issued when the latest plan is not good.
and the question is “Why would this happen?”
We break it up into the four classes above, starting with class 1: why would the Planner not issue a new plan, even though it is informed the latest plan received by the Enactors is not good? Oh, wait, it cannot know that! There’s no feedback path from Enactors to Planner. This might be a problem – if the Enactors encounter problems, they might want to apply backpressure to the Planner, or get the Planner to simplify its plans, etc. That would complicate the system, but it would provide a useful pressure release valve when there are problems updating Route53. We’ll count that as the first safety problem we discovered during this analysis.
Since the Planner receives no feedback on whether the latest plan is good or not, we can lump together classes 1 and 2 for developing these loss scenarios.
For example, unreachable load balancers, or slow load balancer health check responses could cause a plan to not be issued, even when one is needed. This is a real problem that can occur, and it’s why health check requests must come with timeouts. Let’s assume the aws engineers have accounted for this failure mode.
Could there be bugs in the algorithm that converts load balancer health readings into a dns plan? Sure! We should have sufficient automated test coverage of this process to be confident that it won’t go wrong when it encounters edge cases. Let’s assume the aws engineers have handled that too.
We move on to class 3 scenarios, which are where a new plan is issued, but it doesn’t reach the Enactors. We don’t know how this data is transmitted, so it’s hard to speculate on failure modes. Redundancy can deal with things like failed network links. We’ll assume aws engineers have done the right thing here.
What about class 4? Could dns plans be received by the Enactors but then ignored? Yeah, that probably happens plenty. The enactor ignores the plan if it thinks the currently active plan is newer. It might ignore the plan if it thinks storage is full. It will – at least temporarily – ignore the plan if it is busy applying an older plan. Are there situations in which these ignorations overlap with a desire to apply the plan? I think so. We’ll not dig into that here, though.
New plan is issued when it is no longer good.
Next up is the risk that the Planner issues a new plan even though the new plan is no longer good. This is a problem because the Enactors do not have access to health check data, so they blindly trust whatever plans they receive from the Planner. We’ll go through the four scenario classes a little faster this time, referencing the same controller–controlled relationship as before.
The Planner might issue a non-good dns plan despite good health check data, e.g. if construction takes a non-trivial amount of time and the Planner does not confirm the health status once the dns plan is constructed.
The obvious toctou1212 Time of check to time of use. condition also applies here: what if the set of healthy load balancers changes between when the health check is performed and when the plan is issued? Sometimes we cannot prevent this problem entirely, so we need to focus on maintaining speed to reduce the risk that something happens between health checks and plan issuance. If I designed this system, I’d dig deeper into the failure modes here, but we’ll brush past it.
Class 3 and 4 scenarios would be that the Planner does not issue a new plan (safe action provided) but a new non-good plan is received or effected anyway. It could be interesting to think about how this might happen, but it seems unlikely enough that we’ll move on.
Plan is not added when there are no good plans
Making the generic controller–controlled relationship sketch more specific for this control action (and indeed all that follow), we arrive at something like
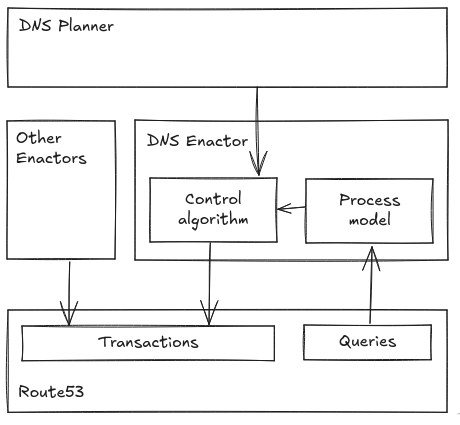
Right off the bat, I can think of two reasons the Enactor might not add a plan even though there are no good plans in Route53: it is designed to not do so when Route53 is full, but it is also designed not to do so when the active plan is newer, according to the description in the summary. That would be a real bug! If an Enactor happens to sit on a good plan and none of the plans in Route53 are good, then it should not matter that the currently active plan was added more recently by another Enactor.
Come to think of it, we have another problem: the Enactor, as modeled, has no way of knowing whether a plan it is holding is good or not. I think this is a part of the system that is underspecified in the summary of the outage, because in order for the Enactors to be able to fall back to older plans (which it sounds like they are capable of) they would have to be able to tell which older plans are still good, and we don’t know how they do that.
On the topic of feedback, what happens if Route53 does not answer queries, or if answers are delayed, or if they contain inaccurate data? I don’t know, but when building the system we’d need to consider it. Should the Enactor default to assuming its plan is newer or older than the currently active one? (You have to pick one, and you better document why you picked it!)
We have the typical problems of connectivity between components: when the Enactor adds a plan, we need a plan to be received by Route53. This comes down to more classical reliability through redundancy and dynamic routing and so on. We should also figure out which ways there are for Route53 to ignore new plans added by Enactors, but that depends on knowing more about Route53 than I do.
Plan is not added when there are no plans at all
This is an interesting case. Why might the Enactor not add its plan even though there are no plans at all? This would be relevant in case we need to cold start the system, which I suppose happens every now and then. Skipping very quickly over the scenario classes, we note that we’d have to think about, among other things,
- design reasons the Enactors avoid adding plans,
- reasons the Enactors might think there are plans even when there’s not,
- reasons the Planner might instruct the Enactors not to add plans even though there are none,
- reasons Route53 might reject plans when it is empty,
etc.
Plan is added when storage is nearly full
Left as an exercise for the reader.
Plan i is not activated when the active plan is not good
This unsafe control action overlaps partially with what we’ve already seen about why Enactors might not add plans even when the active plan is not good. It’s also difficult to analyse in more detail for us for the same reasons as that one: we don’t know how the Enactors find out about which plans are good and which are not.
Plan i is not activated when there is no active plan
We can split this up into multiple scenario classes, but eventually we’ll come to a question: what are ways in which the Enactor might try to activate a plan because there is no active plan, but this is not enacted by Route 53?
Wait, doesn’t that sound familiar? Oh, yeah, it’s straight out of the timeline of the outage.
Because the active plan was deleted, the system was left in an inconsistent state that prevented subsequent plan updates from being applied by any dns Enactors.
I don’t know the details of how the inconsistent state prevented applying updates, but I’m sure if the engineers at aws had asked the right question – which they would get from an stpa – they would have figured it out before it became a problem.
Plan i is activated when it is not good
Also here we are hampered by our lack of understanding of how Enactors find out whether plans are good or not, but I’m sure bugs could lurk here too. Scenario class 4 is still of interest: can a plan get activated even though no Enactor asks for it?
Plan i is activated when it has not been added
I’m not sure it’s meaningful to ask if an Enactor can activate a plan before it’s added, since it sounds like both things happen in a Route53 transaction when a plan is added.
Plan i is activated when it has been deleted
Note that this unsafe control action was not provided in the actual outage, but if it was provided, it would lead to very similar problems. What’s great about system-theoretic analysis is we are almost guaranteed to discover similar loss scenarios, whereas a root cause methodology would only uncover them if we get lucky and someone happens to think of them.
Plan i is not deleted when storage is nearly full
Left as an exercise for the reader.
Plan i is deleted when it is active
The first question is whether the Enactor can choose to delete an active plan despite knowing it is active. It seems, from the outage description, that the Enactor does not even verify whether a plan is active when deleting it. That feedback path is missing. So again we’d lump together classes 1 and 2, and ask if there is any way an Enactor can delete an active plan. Sure there is – the regular cleanup job deletes all plans significantly older than the one just added. If the active plan is significantly older than the one just added, it will get whooped into the rubbish bin.
Hrrm.
The second Enactor’s clean-up process then deleted this older plan because it was many generations older than the plan it had just applied.
The stpa scenario classes also asks us to specifically identify whether there is a way for another controller to issue a deletion command even when this controller correctly determines that the active plan should not be deleted, so it really nudges us in the direction of this feedback problem that caused the outage.
We should also, of course, consider ways that plans might get deleted despite no deletion being requested by any Enactor, but we won’t go into that because I don’t know Route53 well enough.
Plan i is deleted when it needs to be reinstated
We’re assuming here that the reason old plans are kept around is that they might be reinstated. Is it hazardous to delete a plan that will later need to be reinstated? Not sure. We can still ask how the Enactor knows whether a plan will need to be reinstated, and implicit in the outage summary is that they use age as a proxy. Maybe there could be something more useful to go by, but I don’t know.
Summary of loss scenarios and mitigation suggestions
We have discovered these reliability problems:
- The Planner that constructs new dns plans receives no feedback from the Enactors that try to apply them. When there are problems applying, the Planner maintains a high pressure which leads to large deltas in age between sequentially applied plans.
- Both Planner and Enactors suffer from toctou problems (despite using transactions in Route53).
- The Enactors are unable to apply new plans when there is no currently active plan – this is a big problem if we ever end up in a state with no active plan.
- Enactors do not receive feedback on which plan is active. As a consequence, Enactors can delete the active plan.
These problems all contributed to the outage, and we could find out about them through analysis before the problem occurred. If we scroll back up to the timeline, we’ll find that we uncovered all contributing causes through the stpa – which, as a reminder, could have been performed before the outage, thus preventing it.
We also learned about potential problems which could contribute to the next outage:
- The Planner does not simplify the plans when the Enactors have problems applying them.
- An Enactor might refuse to apply a new plan even when the currently active plan is not good, as long as the currently active plan is newer.
- An Enactor that is having problems applying a plan will continue to do so even if the plan has stopped being good, and a new, good plan is waiting to be applied.
- The Enactors might be sensitive to delayed or missing responses from Route53 queries.
- The system likely has problems performing a cold start, when there are no records at all in Route53.
- Enactors can possibly activate dns plans which are deleted by another Enactor.
We have also found out that it is unclear from the system description whether Planners have access to health check data to determine whether a plan is good or not, and if they don’t, how they decide to activate an older plan. Adding these feedback paths to the control model would probably reveal more failure modes.
There’s no human intervention in our system model, because the outage summary does not specify where humans typically intervene. It would be interesting to model such interventions too, along with the feedback paths that enable them. Human–computer interaction is a typical source of accidents.
Even with this limited view of the system, had we performed the stpa before the outage we would have proposed the following adjustments to the control structure, which would have prevented the outage.
- The planner should be made aware of the status of the Enactors, so it can slow down and perhaps even simplify its plans when the Enactors run into problems.1313 This can be made while retaining the current level of decoupling.
- The Planner should have a deadline for how long it can take to generate dns plans, so it doesn’t continue to operate on an outdated worldview. The Enactors should have a deadline for applying dns plans for the same reason.
- There should be a way to apply new plans when there is no active plan in the system.
- The Enactors need feedback on which the active plan is, and they should be designed to not delete the active plan.
To reiterate: these sound obvious now to anyone reading about the outage, but stpa is a mechanism that lets us come up with them before the outage happens.
Further conclusions
There you go – an incredibly fast, fragmented, and shallow system-theoretic process analysis of the DynamoDB dns management system. It did uncover all problems that conspired to cause the outage, it did uncover other problems that might cause a future outage, we were able to get it done in the space of a few thousand words, and, critically, we would have been able to do it before the outage occurred.
There are several ways we could improve this analysis:
- Talk to people who work at aws to get a more detailed model of the system.
- Broaden the hazard to a higher-level customer perspective, which would bring more systems into the analysis.
- Get into more details when considering unsafe control actions and loss scenarios.
These would make the analysis more complete and catch more problems, at the cost of spending more effort on it. One of the strengths of stpa is that we can perform it at the level of detail that is appropriate for the task at hand, and get useful results even with very little effort.
Acknowledgements
I am particularly grateful to John Thomas and Ruben Barroso, both associated with the mit Partnership for Systems Approaches to Safety and Security, for taking the time to review a draft of this article, and point out many ways in which it could be made stronger and more accurate. Any remaining faults with it are all of my own making.