It’s been over three years since my last post on this blog and I have sometimes been asked, understandably, whether the project I announced in my previous post was actually happening. The answer is yes — the grant I received from the Astera Institute has funded several PhD students and a couple of postdocs, and we have been busy. In my previous post I suggested that I would be open to remote collaboration, but that has happened much less, partly because a Polymath-style approach would have been difficult to manage while also ensuring that my PhD students would have work that they could call their own to put in their theses.
In general I don’t see a satisfactory solution to that problem, but in this post I want to mention a subproject of the main project that is very much intended to be…
It’s been over three years since my last post on this blog and I have sometimes been asked, understandably, whether the project I announced in my previous post was actually happening. The answer is yes — the grant I received from the Astera Institute has funded several PhD students and a couple of postdocs, and we have been busy. In my previous post I suggested that I would be open to remote collaboration, but that has happened much less, partly because a Polymath-style approach would have been difficult to manage while also ensuring that my PhD students would have work that they could call their own to put in their theses.
In general I don’t see a satisfactory solution to that problem, but in this post I want to mention a subproject of the main project that is very much intended to be a large public collaboration. A few months ago, a call came out from Renaissance Philanthropies saying that they were launching a $9m AI for Math Fund to spend on projects in the general sphere of AI and mathematics, and inviting proposals. One of the categories that they specifically mentioned was creating new databases, and my group submitted a proposal to create a database of what we call “structured motivated proofs,” a piece of terminology that I will explain a bit more later in just a moment. I am happy to report that our proposal was one of the 29 successful ones. Since a good outcome to the project will depend on collaboration from many people outside the group, we need to publicize it, which is precisely the purpose of this post. Below I will be more specific about the kind of help we are looking for.
Why might yet another database of theorems and proofs be useful?
The underlying thought behind this project is that AI for mathematics is being held back not so much by an insufficient quantity of data as by the wrong kind of data. All mathematicians know, and some of us enjoy complaining about it, that it is common practice when presenting a proof in a mathematics paper or even textbook, to hide the thought processes that led to the proof. Often this does not matter too much, because the thought processes may be standard ones that do not need to be spelt out to the intended audience. But when proofs start to get longer and more difficult, they can be hard to read because one has to absorb definitions and lemma statements that are not obviously useful, are presented as if they appeared from nowhere, and demonstrate their utility only much later in the argument.
A sign that this is a problem for AI is the behaviour one observes after asking an LLM to prove a statement that is too difficult for it. Very often, instead of admitting defeat, it will imitate the style of a typical mathematics paper and produce rabbits out of hats, together with arguments later on that those rabbits do the required job. The problem is that, unlike with a correct mathematics paper, when one scrutinizes the arguments carefully, one finds that they are wrong. However, it is hard to distinguish between an incorrect rabbit and an incorrect argument justifying that rabbit (especially if the argument does not go into full detail) and a correct one, so the kinds of statistical methods used by LLMs do not have an easy way to penalize the incorrectness.
Of course, that does not mean that LLMs cannot do mathematics at all — they are remarkably good at it, at least compared with what I would have expected three years ago. How can that be, given the problem I have discussed in the previous paragraph?
The way I see it (which could change — things move so fast in this sphere), the data that is currently available to train LLMs and other systems is very suitable for a certain way of doing mathematics that I call guess and check. The rough idea is that you do routine parts of an argument without any fuss (and an LLM can do them too because it has seen plenty of similar examples), but if the problem as a whole is not routine, then at some point you have to stop and think, often because you need to construct an object that has certain properties (I mean this in a rather general way — the “object” might be a lemma that will split up the proof in a nice way) and it is not obvious how to do so. The guess-and-check approach to such moments is what it says: you make as intelligent a guess as you can and then see whether it has the properties you wanted. If it doesn’t, you make another guess, and you keep going until you get lucky.
The reason an LLM might be tempted to use this kind of approach is that the style of mathematical writing I described above makes it look as though that is what we as mathematicians do. Of course, we don’t do that, but we often omit to mention all the failed guesses we made and how we carefully examined why they failed, modifying them in appropriate ways in response, until we finally converged on an object that worked. We also don’t mention the reasoning that often takes place before we make the guess, saying to ourselves things like “Clearly an Abelian group can’t have that property, so I need to look for a non-Abelian group.”
Intelligent guess and check works well a lot of the time, particularly when carried out by an LLM that has seen many proofs of many theorems. I have often been surprised when I have asked an LLM a problem of the form 


If the above picture of what LLMs can do is correct (the considerations for reinforcement-learning-based systems such as AlphaProof are not identical but I think that much of what I say in this post applies to them too for slightly different reasons), then the likely consequence is that if we pursue current approaches, then we will reach a plateau: broadly speaking they will be very good at answering a question if it is the kind of question that a mathematician with the right domain expertise and good instincts would find reasonably straightforward, but will struggle with anything that is not of that kind. In particular, they will struggle with research-level problems, which are, almost by definition, problems that experts in the area do not find straightforward. (Of course, there would probably be cases where an LLM spots relatively easy arguments that the experts had missed, but that wouldn’t fundamentally alter the fact that they weren’t really capable of doing research-level mathematics.)
But what if we had a database of theorems and proofs that did not hide the thought processes that lay behind the non-obvious details of the proofs? If we could train AI on a database of accounts of proof discoveries and if, having done so, we then asked it to provide similar accounts, then it would no longer resort to guess-and-check when it got stuck, because the proof-discovery accounts it had been trained on would not be resorting to it. There could be a problem getting it to unlearn its bad habits, but I don’t think that difficulty would be impossible to surmount.
The next question is what such a database might look like. One could just invite people to send in stream-of-consciousness accounts of how they themselves found certain proofs, but that option is unsatisfactory for several reasons.
- It can be very hard to remember where an idea came from, even a few seconds after one has had it — in that respect it is like a dream, the memory of which becomes rapidly less vivid as one wakes up.
- Often an idea will seem fairly obvious to one person but not to another.
- The phrase “motivated proof” means different things to different people, so without a lot of careful moderation and curation of entries, there is a risk that a database would be disorganized and not much more helpful than a database of conventionally written proofs.
- A stream-of-consciousness account could end up being a bit too much about the person who finds the proof and not enough about the mathematical reasons for the proof being feasibly discoverable. To deal with these kinds of difficulties, we plan to introduce a notion of a structured motivated proof, by which we mean a proof that is generated in a very particular way that I will partially describe below. A major part of the project, and part of the reason we needed funding for it, is to create a platform that will make it convenient to input structured motivated proofs and difficult to insert the kinds of rabbits out of hats that make a proof mysterious and unmotivated. In this way we hope to gamify the task of creating the database, challenging people to input into our system proofs of certain theorems that appear to rely on “magic” ideas, and perhaps even offering prizes for proofs that contain steps that appear in advance to be particularly hard to motivate. (An example: the solution by Ellenberg and Gijswijt of the cap-set problem uses polynomials in a magic-seeming way. The idea of using polynomials came from an earlier paper of Croot, Lev and Pach that proved a closely related theorem, but in that paper it just appears in the statement of their Lemma 1, with no prior discussion apart from the words “in the present paper we use the polynomial method” in the introduction.)
What is a structured motivated proof?
I wrote about motivated proofs in my previous post, but thanks to many discussions with other members of the group, my ideas have developed quite a lot since then. Here are two ways we like to think about the concept.
1. A structured motivated proof is one that is generated by standard moves.
I will not go into full detail about what I mean by this, but will do so in a future post when we have created the platform that we would like people to use in order to input proofs into the database. But the basic idea is that at any one moment one is in a certain state, which we call a proof-discovery state, and there will be a set of possible moves that can take one from the current proof-discovery state to a new one.
A proof-discovery state is supposed to be a more formal representation of the state one is in when in the middle of solving a problem. Typically, if the problem is difficult, one will have asked a number of questions, and will be aware of logical relationships between them: for example, one might know that a positive answer to Q1 could be used to create a counterexample to Q2, or that Q3 is a special case of Q4, and so on. One will also have proved some results connected with the original question, and again these results will be related to each other and to the original problem in various ways that might be quite complicated: for example P1 might be a special case of Q2, which, if true would reduce Q3 to Q4, where Q3 is a generalization of the statement we are trying to prove.
Typically we will be focusing on one of the questions, and typically that question will take the form of some hypotheses and a target (the question being whether the hypotheses imply the target). One kind of move we might make is a standard logical move such as forwards or backwards reasoning: for example, if we have hypotheses of the form 
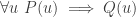
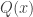
- We have in our list of hypotheses the fact that a function
is given by the formula
, where
is a polynomial, and our goal is to prove that there exists
such that
. Without really thinking about it, we are conscious that
matches well the conclusion of the intermediate-value theorem. So the intermediate-value theorem comes naturally to mind and we add it to our list of available hypotheses. In practice we wouldn’t necessarily write it down, but the system we wish to develop is intended to model not just what we write down but also what is going on in our brains, so we propose a move that we call library extraction (closely related to what is often called premise selection in the literature). Note that we have to be a bit careful about library extraction, since we don’t want the system to be allowed to call up results from the library that appear to be irrelevant but then magically turn out to be helpful, since those would count as rabbits out of hats. So we want to allow extraction of results only if they are obvious given the context. It is not easy to define what “obvious” means, but there is a good rule of thumb for it: a library extraction is obvious if it is one of the first things ChatGPT thinks of when given a suitable non-cheating prompt. For example, I gave it the prompt, “I have a function
- We have a goal of the form
. If this were a Lean proof state, the most common way to discharge a goal of this form would be to input a choice for
and our new goal would be
. However, as with library extraction, we have to be very careful about instantiation if we want our proof to be motivated, since we wish to disallow highly surprising choices of
and change the goal to
, which we can think of as saying “I’m going to start trying to prove
that
is easier than the original problem.”
- We cannot see how to answer the question we are focusing on so we ask a related question. Two very common kinds of related question (as emphasized by Polya) are generalization and specialization. Perhaps we don’t see why a hypothesis is helpful, so we see whether the result holds if we drop that hypothesis. If it does, then we are no longer distracted by an irrelevant hypothesis. If it does not, then we can hope to find a counterexample that will help us understand how to use the hypothesis. Or perhaps we are trying to prove a general statement but it is not clear how to do so, so instead we formulate some special cases, hoping that we can prove them and spot features of the proofs that we can generalize. Again we have to be rather careful here not to allow “non-obvious” generalizations and specializations. Roughly the idea there is that a generalization should be purely logical — for example, dropping a hypothesis is fine but replacing the hypothesis “
2. A structured motivated proof is one that can be generated with the help of a point-and-click system.
This is a surprisingly useful way to conceive of what we are talking about, especially as it relates closely to what I was talking about earlier: imposing a standard form on motivated proofs (which is why we call them “structured” motivated proofs) and gamifying the process of producing them.
The idea is that a structured motivated proof is one that can be generated using an interface (which we are in the process of creating — at the moment we have a very basic prototype that has a few of the features we will need, but not yet the more interesting ones) that has one essential property: the user cannot type in data. So what can they do? They can select text that is on their screen (typically mathematical expressions or subexpressions), they can click buttons, choose items from drop-down menus, and accept or reject “obvious” suggestions made to them by the interface.
If, for example, the current goal is an existential statement 
Broadly speaking, the way the prototype works is to get an LLM to read a JSON object that describes the variables, hypotheses and goals involved in the proof state in a structured format, and to describe (by means of a fairly long prompt) the various moves it might be called upon to do. Thus, the proofs generated by the system are not formally verified, but that is not an issue that concerns us in practice since there will be a human in the loop throughout to catch any mistakes that the LLM might make, and this flexibility may even work to our advantage to better capture the fluidity of natural-language mathematics.
There is obviously a lot more to say about what the proof-generating moves are, or (approximately equivalently) what the options provided by a point-and-click system will be. I plan to discuss that in much more detail when we are closer to having an interface ready, the target for which is the end of this calendar year. But the aim of the project is to create a database of examples of proofs that have been successfully generated using the interface, which can then be used to train AI to play the generate-structured-motivated-proof game.
How to get involved.
There are several tasks that will need doing once the project gets properly under way. Here are some of the likely ones.
- The most important is for people to submit structured motivated (or move-generated) proofs to us on the platform we provide. We hope that the database will end up containing proofs of a wide range of difficulty (of two kinds — there might be fairly easy arguments that are hard to motivate and there might be arguments that are harder to follow but easier to motivate) and also a wide range of areas of mathematics. Our initial target, which is quite ambitious, is to have around 1000 entries by two years from now. While we are not in a position to accept entries yet, if you are interested in participating, then it is not too early to start thinking in a less formal way about how to convert some of your favourite proofs into motivated versions, since that will undoubtedly make it easier to get them accepted by our platform when it is ready.
- We are in the process of designing the platform. As I mentioned earlier, we already have a prototype, but there are many moves we will need it to be able to do that it cannot currently do. For example, the current prototype allows just a single proof state, which consists of some variable declarations, hypotheses, and goals. It does not yet support creating subsidiary proof states (which we would need if we wanted to allow the user to consider generalizations and specializations, for example). Also, for the moment the prototype gets an LLM to implement all moves, but some of the moves, such as applying modus ponens, are extremely mechanical and would be better done using a conventional program. (On the other hand, moves such as “obvious library extraction” are better done by an LLM.) Thirdly, a technical problem is that LaTeX is currently rendered as images, which makes it hard to select subexpressions, something we will need to be able to do in a non-clunky way. And the public version of the platform will need to be web-based and very convenient to use. We will want features such as being able to zoom out and look at some kind of dependency diagram of all the statements and questions currently in play, and then zoom in on various nodes if the user wishes to work on them. If you think you may be able (and willing) to help with some of these aspects of the platform, then we would be very happy to hear from you. For some, it would probably help to have a familiarity with proof assistants, while for others we would be looking for somebody with software engineering experience. The grant from the AI for Math Fund will allow us to pay for some of this help, at rates to be negotiated. We are not yet ready to specify in detail what help we need, but would welcome any initial expressions of interest.
- Once the platform is ready and people start to submit proofs, it is likely that, at least to start with, they will find that the platform does not always provide the moves they need. Perhaps they will have a very convincing account of where a non-obvious idea in the proof came from, but the system won’t be expressive enough for them to translate that account into a sequence of proof-generating moves. We will want to be able to react to such situations (if we agree that a new move is needed) by expanding the capacity of the platform. It will therefore be very helpful if people sign up to be beta-testers, so that we can try to get the platform to a reasonably stable state before opening it up to a wider public. Of course, to be a beta-tester you would need to have a few motivated proofs in mind.
- It is not obvious that every proof submitted via the platform, even if submitted successfully, would be a useful addition to the database. For instance, it might be such a routine argument that no idea really needs to have its origin explained. Or it might be that, despite our best efforts, somebody finds a way of sneaking in a rabbit while using only the moves that we have provided. (One way this could happen is if an LLM made a highly non-obvious suggestion that happened to work, in which case the rule of thumb that if an LLM thinks of it, it must be obvious, would have failed in that instance.) For this reason, we envisage having a team of moderators, who will check entries and make sure that they are good additions to the database. We hope that this will be an enjoyable task, but it may have its tedious aspects, so we envisage paying moderators — again, this expense was allowed for in our proposal to the AI for Math Fund. If you think you might be interested in any of these roles, please feel free to get in touch. Probably the hardest recruitment task for us will be identifying the right people with the right mixture of to help us turn the platform into a well-designed web-based one that is convenient and pleasurable to use. If you think you might be such a person, or if you have a good idea for how we should go about finding one, we would be particularly interested to hear from you.
In a future post, I will say more about the kinds of moves that our platform will allow, and will give examples of non-motivated proofs together with how motivated versions of those proofs can be found, and entered using the platform (which may involve a certain amount of speculation about what the platform will end up looking like).
How does this relate to use of tactics in a proof assistant?
In one way, our “moves” can be regarded as tactics of a kind. However, some of the moves we will need are difficult to implement in conventional proof assistants such as Lean. In parallel with the work described above, we hope to create an interface to Lean that would allow one to carry out proof-discovery moves of the kind discussed above but with the proof-discovery states being collections of Lean proof states. Members of my group have already been working on this and have made some very interesting progress, but there is some way to go. However, we hope that at some point (and this is also part of the project pitched to the AI for Math Fund) that we will have created another interface that will have Lean working in the background, so that it will be possible to generate motivated proofs that will be (or perhaps it is better to say include) proofs in Lean at the same time.
Another possibility that we are also considering is to use the output of the first platform (which, as mentioned above, will be fairly formal, but not in the strict sense of a language such as Lean) to create a kind of blueprint that can then be autoformalized automatically. Then we would have a platform that would in principle allow mathematicians to search for proofs while working on their computers, without having to learn a formal language, and with their thoughts being formalized as they go.
Tags: ai, automatic-theorem-proving, mathematics
This entry was posted on September 22, 2025 at 11:04 pm and is filed under Computing, Demystifying proofs, News. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.