Moonshot’s Kimi K2 recently launched in preview on GroqCloud and developers keep asking us: how is Groq running a 1-trillion-parameter model this fast?
Legacy hardware forces a choice: faster inference with quality degradation, or accurate inference with unacceptable latency. This tradeoff exists because GPU architectures optimize for training workloads. The LPU–purpose-built hardware for inference–preserves quality while eliminating architectural bottlenecks which create latency in the first place.
Accuracy Without Tradeoffs: TruePoint Numerics
Traditional accelerators achieve speed through aggressive quantization, forcing models into INT8 or lower precision numerics that introduce cumulative errors throughout the computation pipeline and lead to loss of quality.
We use TruePoi…
Moonshot’s Kimi K2 recently launched in preview on GroqCloud and developers keep asking us: how is Groq running a 1-trillion-parameter model this fast?
Legacy hardware forces a choice: faster inference with quality degradation, or accurate inference with unacceptable latency. This tradeoff exists because GPU architectures optimize for training workloads. The LPU–purpose-built hardware for inference–preserves quality while eliminating architectural bottlenecks which create latency in the first place.
Accuracy Without Tradeoffs: TruePoint Numerics
Traditional accelerators achieve speed through aggressive quantization, forcing models into INT8 or lower precision numerics that introduce cumulative errors throughout the computation pipeline and lead to loss of quality.
We use TruePoint numerics, which changes this equation. TruePoint is an approach which reduces precision only in areas that do not reduce accuracy. Coupled with our LPU architecture, this allows for the preservation of quality with high precision numerics. TruePoint format stores 100 bits of intermediate accumulation - sufficient range and precision to guarantee lossless accumulation regardless of input bit width. This means we can store weights and activations at lower precision while performing all matrix operations at full precision – then selectively quantize outputs based on downstream error sensitivity.
Our compiler applies precision strategically:
- FP32 for attention logits where 1-bit errors propagate
- Block Floating Point for Mixture-of-experts (MoE) weights where robustness studies show no measurable degradation
- FP8 storage for activations in error-tolerant layers
This level of control yields a 2-4× speedup over BF16 with no appreciable accuracy loss on benchmarks like MMLU and HumanEval. The industry is following suit with formats such as MXfp4 to reduce model footprint as the need for AI inference, and hardware, increases exponentially. We’re not trading quality for speed - we’re eliminating the architectural constraints that force that tradeoff.
Memory Architecture: SRAM as Primary Storage
Traditional accelerators inherit memory hierarchies designed for training: DRAM and HBM as primary storage with complex cache systems. Both DRAM and HBM introduce significant latency on each weight fetch - hundreds of nanoseconds per access. This works for high-batch training where temporal locality is predictable and arithmetic intensity is high, but inference presents sequential layer execution with a much lower arithmetic intensity exposing the latency penalty incurred by DRAM and HBM.
The LPU integrates hundreds of megabytes of on-chip SRAM as primary weight storage, not cache, which results in significantly lower access latency. This design allows compute units to pull in weights at full speed, enabling tensor parallelism by splitting a single layer across multiple chips. This becomes a practical advantage for fast, scalable inference.
Execution Model: Static Scheduling
GPU architectures rely on dynamic scheduling - hardware queues, runtime arbitration, and software kernels that introduce non-deterministic latency. During collective operations, when hundreds of cores must synchronize activation tensors, any delay propagates through the entire system.
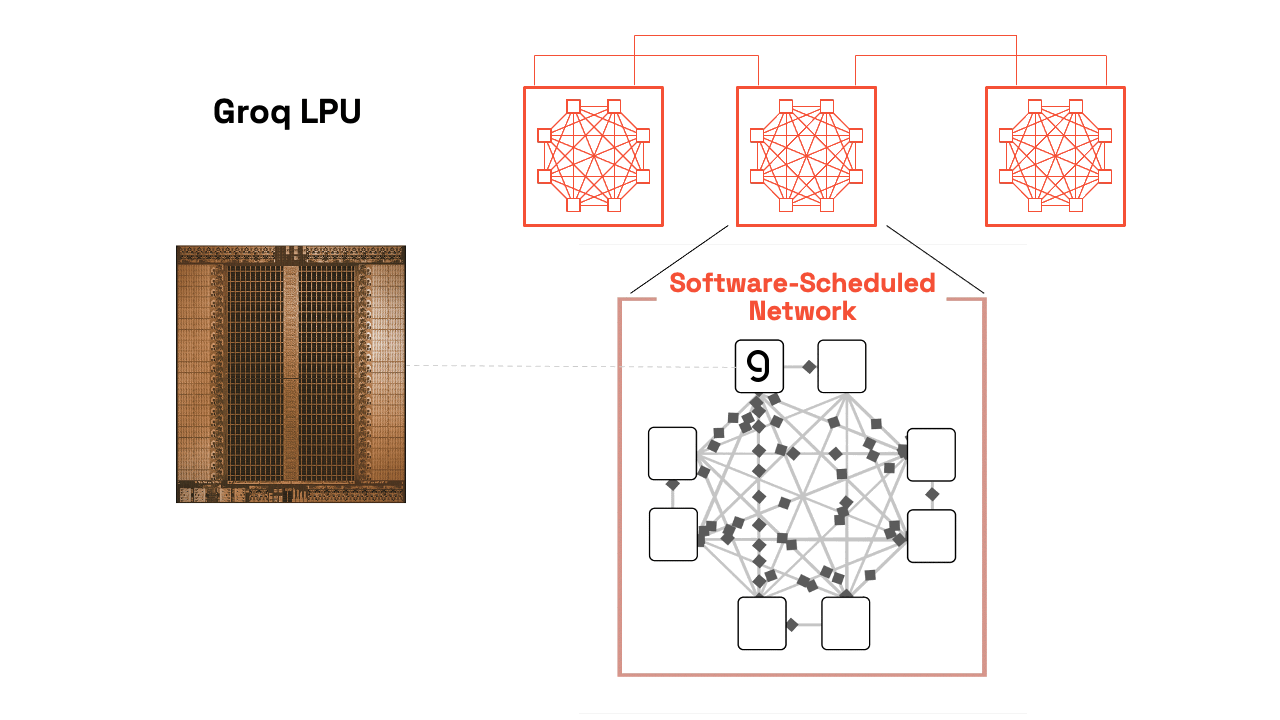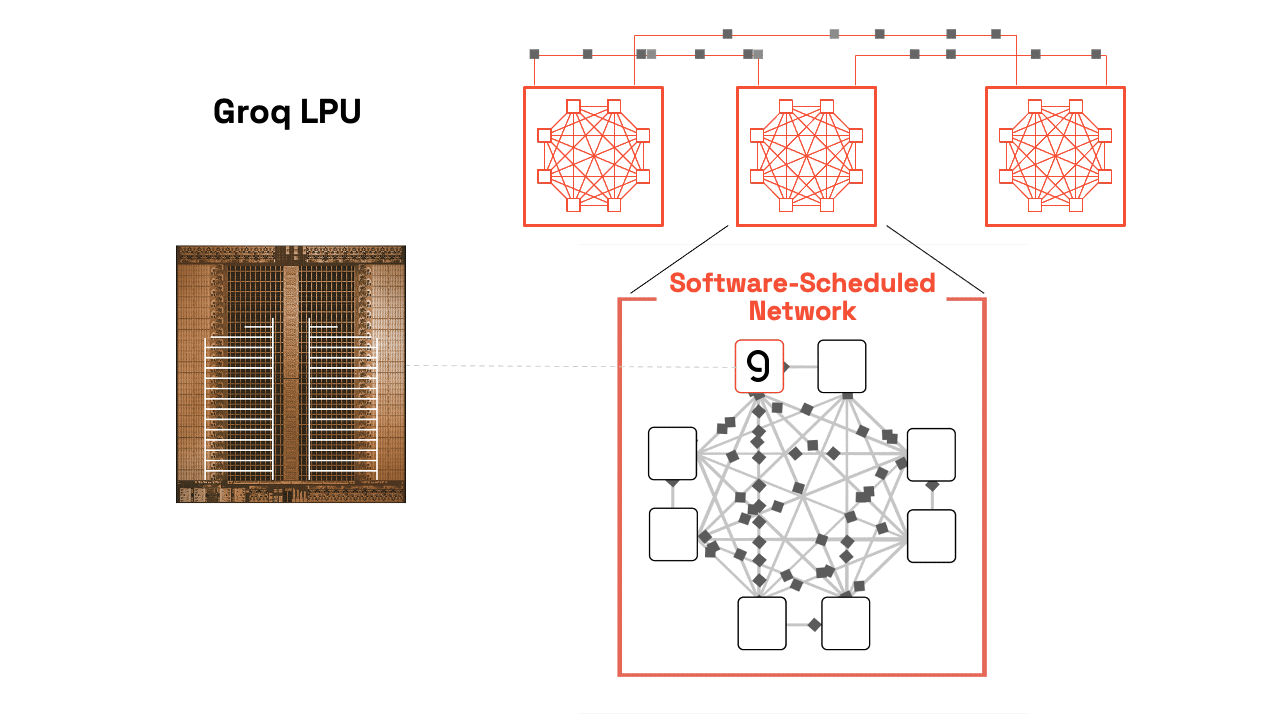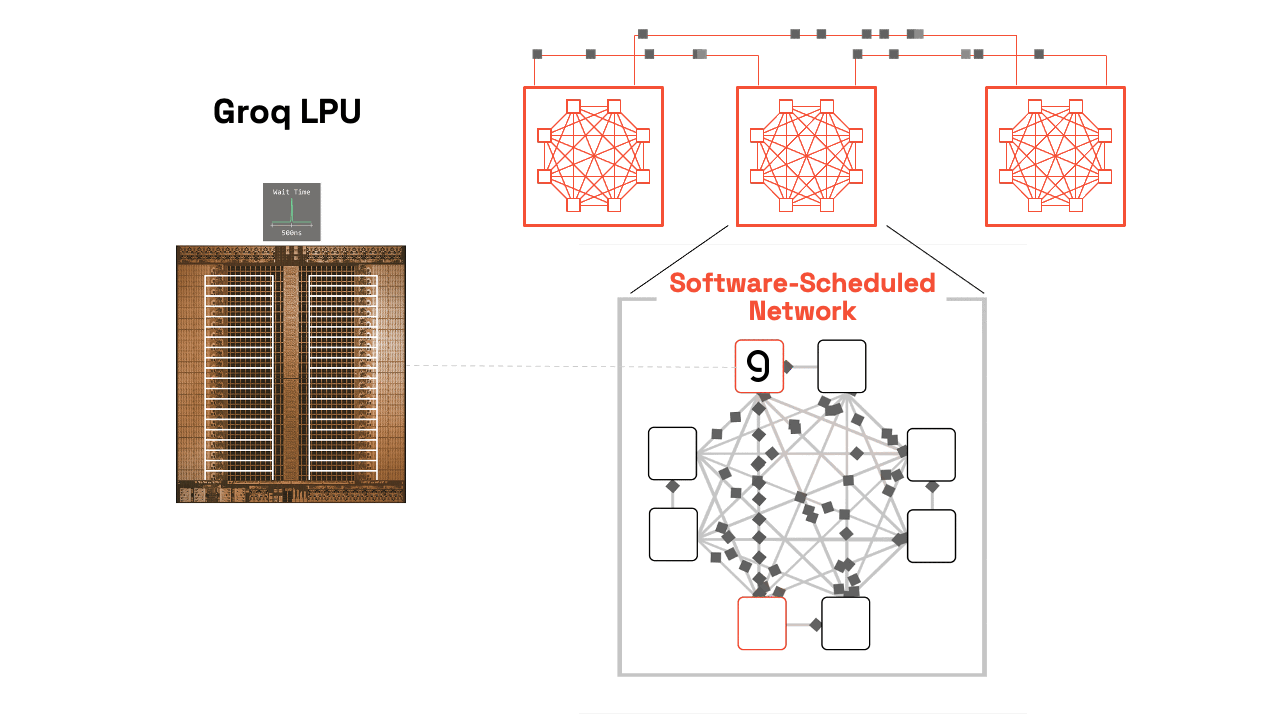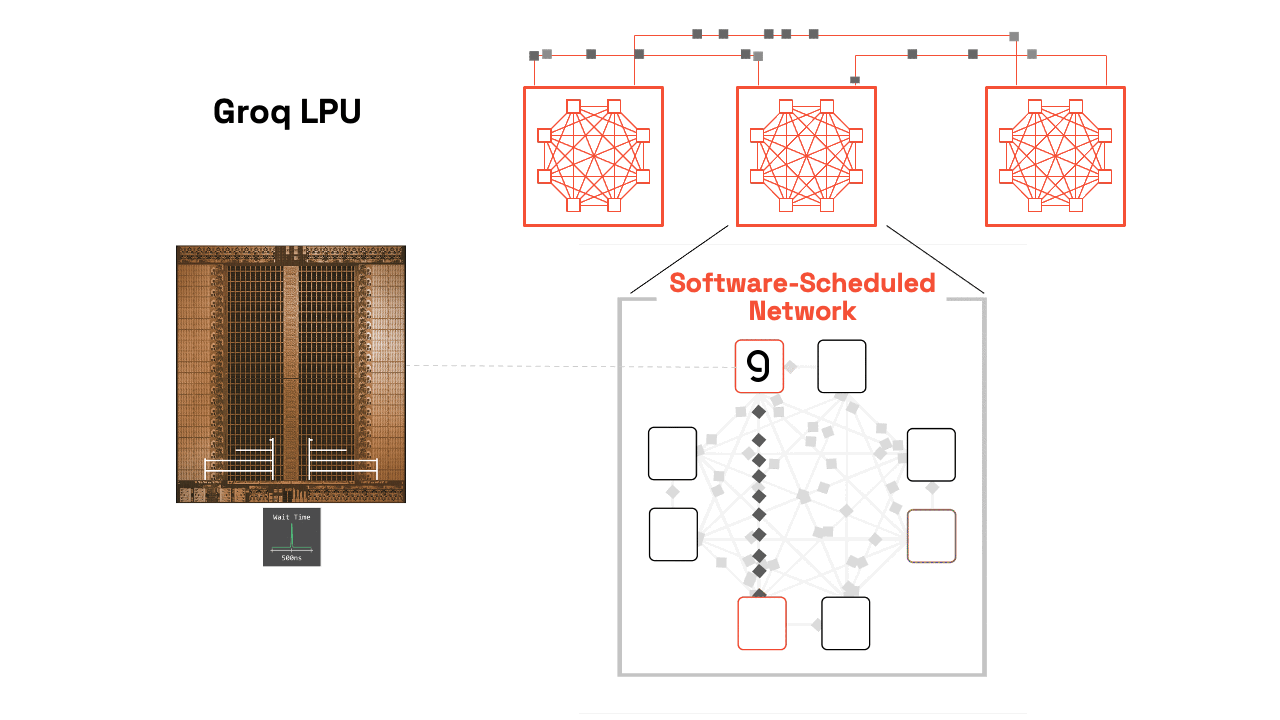
Our compiler pre-computes the entire execution graph, including inter-chip communication patterns, down to the individual clock cycles. This static scheduling eliminates:
- Cache coherency protocols
- Reorder buffers
- Speculative execution overhead
- Runtime coordination delays
Deterministic execution enables two critical optimizations impossible on dynamically scheduled systems:
- Tensor parallelism without tail latency: Each layer distributes across multiple chips with guaranteed synchronization, eliminating delays that plague GPU collective operations.
- Pipeline parallelism atop tensor parallelism: Layer N+1 begins processing inputs while Layer N continues computation, a feat GPUs struggle with due to dynamic scheduling and inability to balance pipeline stages efficiently.
Parallelism Strategy: Latency-Optimized Distribution
Data parallelism scales throughput by running multiple model instances. GPUs scale well with data parallelism – running many copies of the same model on different inputs. This boosts throughput, but doesn’t help if you’re waiting on a single response.
Tensor parallelism reduces latency by distributing individual operations across processors. For real-time applications, tensor parallelism is the critical optimization. Our LPU architecture is purpose-built for tensor parallelism. We partition each layer across multiple LPUs so single forward passes complete faster rather than processing more requests in parallel. This architectural choice is why Moonshot AI’s Kimi K2, for example, generates tokens in real-time despite its trillion-parameter size.
Speculative Decoding: Execution on Tensor-Parallel Hardware
Speculative decoding is a technique that uses a smaller, faster “draft” model to predict a sequence of future tokens, which are then verified in a single batched forward pass of the larger target model. While this approach can provide speedups, the verification step often becomes memory-bandwidth-bound on traditional hardware like GPUs, which can limit performance gains.
Our LPUs are designed with an architecture that can handle the verification of speculative token batches more efficiently with pipeline parallelism, which allows for faster processing of these verification steps and enables multiple tokens (often 2-4) to be accepted per pipeline stage. Combined with fast draft models that leverage tensor parallelism, this delivers a compound performance boost for inference.
Software-Scheduled Network: RealScale Chip-to-Chip Interconnect
Groq uses a plesiosynchronous, chip-to-chip protocol to cancel natural clock drift and align hundreds of LPUs to act as a single core. The SW compiler then can predict exactly when data will arrive, so developers can reason about timing. Periodic software sync adjusts for crystal-based drift, enabling not just compute scheduling but also network scheduling. This lets Groq operate like a single-core supercluster, sidestepping complex coordination problems found in traditional architectures by starting with the compiler.
Benchmarks: How Groq Stacks Up
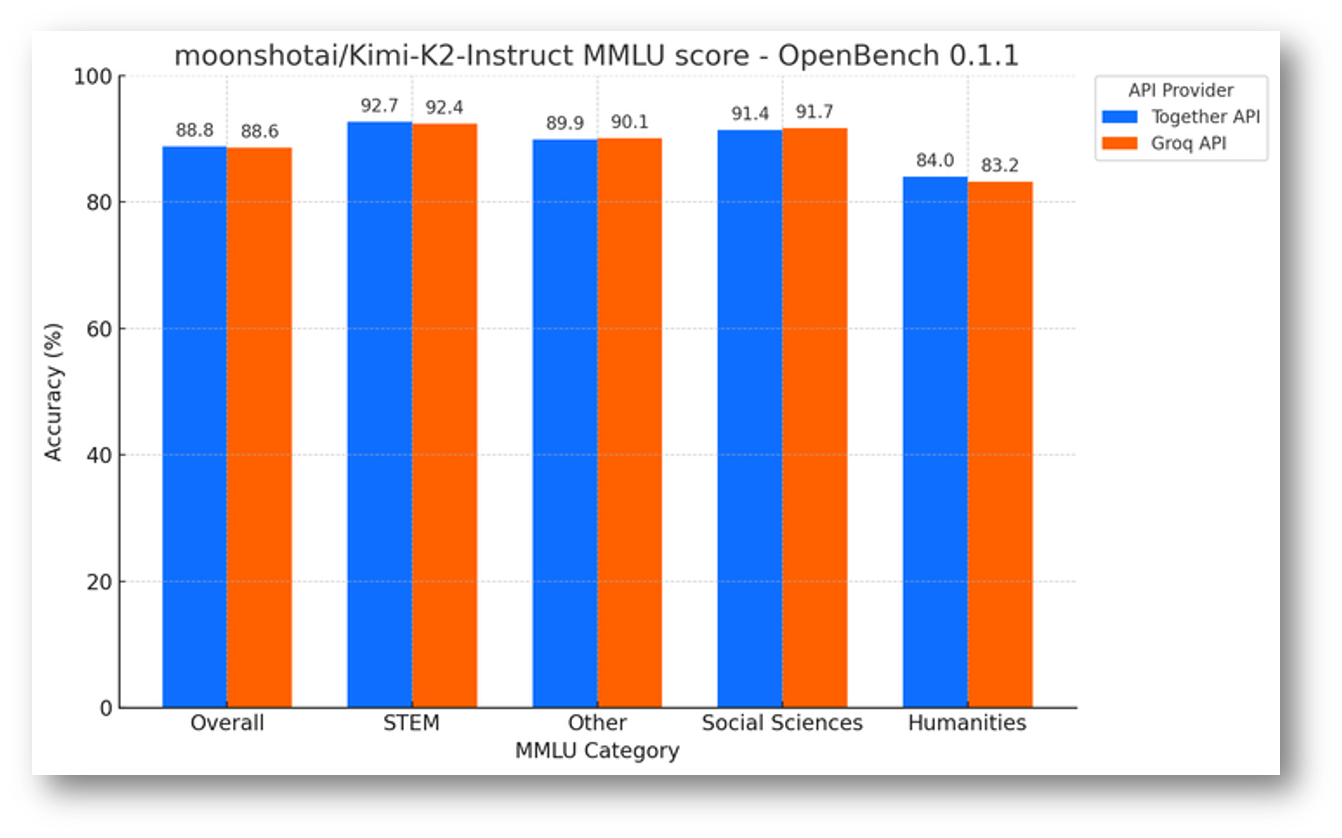
We take model quality seriously. Yesterday, we released OpenBench–our provider-agnostic, open evaluation framework for LLMs. We ran OpenBench 0.1.1’s MMLU implementation on Kimi-K2-Instruct on Groq and a GPU based API provider, and you can see here that accuracy scores are strong – demonstrating the capability of Groq’s stack. Learn more about OpenBench and reproduce these benchmarks yourself.
The Bottom Line
Groq isn’t tweaking around the edges. We build inference from the ground up for speed, scale, reliability and cost-efficiency. That’s how we got Kimi K2 running at 40× performance in just 72 hours. Our first generation LPU – introduced in 2019 – is delivering these results on a 14nm process technology. We care deeply about developer feedback and real-world performance, combining this with industry-leading design and rigorous technical benchmarks to deliver the ultimate AI inference experience. We’ll continue to accelerate the hardware and software so developers can do what they do best: build fast.