Introduction
One of the primary reasons Specialized Language Models are attractive is their low parameter count relative to large generalist models like GPT-5. Smaller models can produce more tokens per second, requiring less computational power per token than their larger counterparts, ultimately resulting in lower operational cost and better cost-to-performance on specific tasks.
While lowering the parameter count can improve the economics of running LLMs at scale, there are still limits to how small a model can be and still remain useful for Supervised Fine-Tuning (SFT) on specific tasks – a 1B parameter model may be able to produce tokens at 10x the rate of an 8B parameter model, but it is unlikely to remain as accurate.
Put simply, a 1B parameter model may be fast, but it …
Introduction
One of the primary reasons Specialized Language Models are attractive is their low parameter count relative to large generalist models like GPT-5. Smaller models can produce more tokens per second, requiring less computational power per token than their larger counterparts, ultimately resulting in lower operational cost and better cost-to-performance on specific tasks.
While lowering the parameter count can improve the economics of running LLMs at scale, there are still limits to how small a model can be and still remain useful for Supervised Fine-Tuning (SFT) on specific tasks – a 1B parameter model may be able to produce tokens at 10x the rate of an 8B parameter model, but it is unlikely to remain as accurate.
Put simply, a 1B parameter model may be fast, but it will also be.. pretty dumb.
So how else can we improve total throughput for a specific task without simply using a smaller model? Enter Hybrid-Attention.
Hybrid Attention
In a recent project, we needed to maximize total token throughput for an HTML-to-JSON conversion task. HTML documents tend to be long (easily 100k+ tokens), and even an 8B parameter struggled to deliver the throughput we were looking for. We tried everything from smaller models, MoEs, inference engine optimizations, and even building on AMD. None of these avenues were providing the performance we needed.
In a lucky stumble, I came across NVIDIA’s Nemotron Nano v2, which claimed to have a massively increased throughput compared to any other type of model. It is a hybrid reasoning model, and although it took a concerted effort to adapt it to our training flow, the payoff has been well worth the effort.
Unlike traditional transformers that rely solely on self-attention mechanisms, Nemotron Nano v2 mixes Mamba-2 state-space layers (approximately 92% of layers) with Transformer self-attention blocks (approximately 8% of layers). This approach leverages Mamba-2’s efficiency for sequential processing while retaining transformer blocks where global context mixing is crucial. The result is a model that maintains the reasoning quality of traditional transformers while dramatically reducing computational overhead.
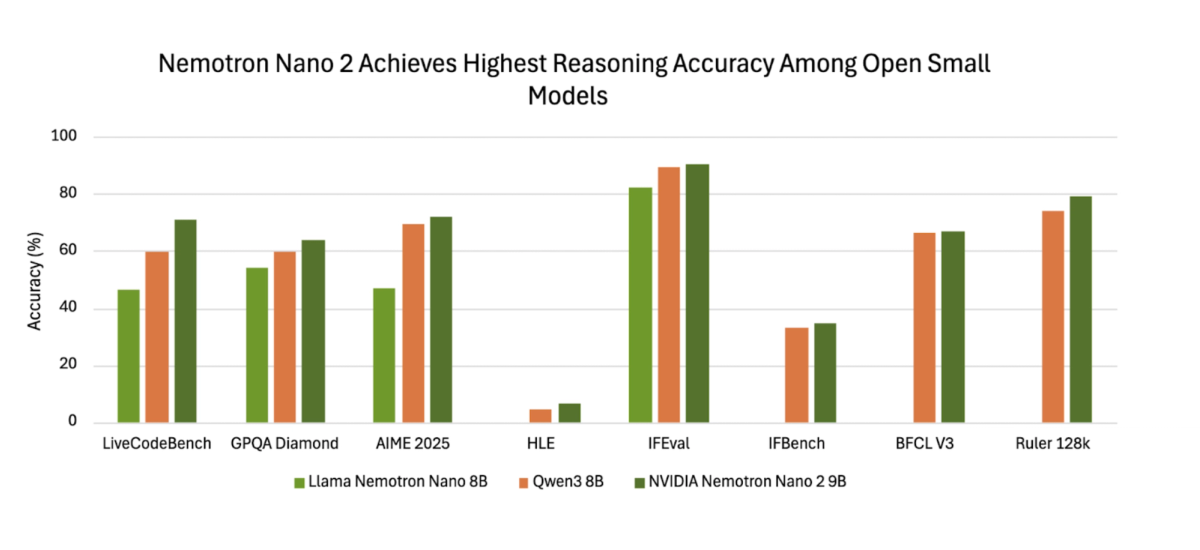
The original training process of Nemotron Nano v2 is also quite interesting. First, a 12B-parameter base model was trained on 20 trillion tokens using an FP8 recipe, then the context window was extended to 128k. The model was subsequently compressed to 9B parameters through pruning and distillation while preserving 56 layers and the hybrid layer pattern. The architecture features no positional embeddings and uses RMSNorm throughout. This design choice directly addresses one of the biggest challenges in language modeling: the quadratic growth of KV cache memory and computation with sequence length.
To make Nemotron Nano v2 truly shine for long-context applications, we implemented several patches to make sure that we could fit long context training into GPU memory. Particularly, using ring attention allowed for processing sequences longer than what would typically fit in memory by distributing the computation across multiple devices. Although it was used in their training process, we had to adjust it to work with the Huggingface Trainer ecosystem, and particularly Tri Dao’s Flash Attention package. The result was being able to fine tune on requests with context lengths of up to 500K tokens.
To see if the model actually made a difference, we conducted a comprehensive comparison between Nemotron Nano v2 and Qwen 3 14B on a demanding scientific summarization task. When fine-tuned on a large, structured scientific summarization task, both models performed exceptionally well under an ensemble LLM-as-a-judge evaluation. Qwen 3 14B achieved slightly higher average summary quality, but Nemotron Nano v2 followed closely behind, well within the band of strong, production-worthy summarizers. A complementary question-answering benchmark showcased similar results. Both models clustered near strong commercial baselines.
Where Nemotron really outshone everything was in its throughput. On an identical 8×H200 setup using vLLM with tensor parallelism of 8, Nemotron delivered approximately 2.25× higher end-to-end throughput than Qwen 3 14B. The specific numbers tell a compelling story: Nemotron achieved 0.97 requests per second compared to Qwen’s 0.43, delivering 4,880.76 input tokens per second versus Qwen’s 2,588.30.
For output tokens, Nemotron reached 16,943.69 tokens per second compared to Qwen’s 7,516.54. Even in single-request scenarios, Nemotron processed 76.17 tokens per second versus Qwen’s 39.59. While this is a bit lower than the paper’s throughput numbers (claiming 6x higher tokens/s in a 8k input/16k output scenario), it was still far beyond any other optimization we had tried. [Table to showcase the above results, pending based on where we publish]While everyone is focused on absolutes, there is a key metric that I believe Nemotron Nano is currently the leader in: throughput to cost ratio. The whole tradeoff of finetuning models is based around improving cost, throughput, and latency while trying to maintain quality. While it fine tunes a bit worse on the same dataset than Qwen, it makes up for it by being a firehose of tokens. In cases where you need to train a model to process massively large datasets (as we will be announcing soon), this model should be a valuable asset to consider.Note: Full methodology, dataset composition, and detailed evaluation breakdowns will be shared in a future blog post.
Reference:Nemotron Nano v2: https://arxiv.org/abs/2508.14444, https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2