October 27, 2025 18 minute read
There is a lot of excitement about applying AI to VLSI design as well as a lot of concern that Large Language Models (LLMs) will generate expansive hardware descriptions riddled with hard-to-find bugs. While software is experiencing a renaissance in AI-assistance, hardware semantics and its un-patchable nature mean that we need to find ways to leverage AI to help build with a high level of focus on correctness as we design hardware if we expect to see similar gains in productivity.
A methodology that is synergistic with using AI to boost correctness while accelerating design is agile hardware design, which borrows the precepts of test-driven, always-alive, and feature-by-feature design evolution, endemic in the software world. Focusing on abstraction,…
October 27, 2025 18 minute read
There is a lot of excitement about applying AI to VLSI design as well as a lot of concern that Large Language Models (LLMs) will generate expansive hardware descriptions riddled with hard-to-find bugs. While software is experiencing a renaissance in AI-assistance, hardware semantics and its un-patchable nature mean that we need to find ways to leverage AI to help build with a high level of focus on correctness as we design hardware if we expect to see similar gains in productivity.
A methodology that is synergistic with using AI to boost correctness while accelerating design is agile hardware design, which borrows the precepts of test-driven, always-alive, and feature-by-feature design evolution, endemic in the software world. Focusing on abstraction, components, modularity, and reuse is especially synergistic with the way LLMs retain and apply knowledge in a limited context window. At the heart of this approach is the recognition that the perfect specification does not exist, and that design is an evolution of discovery and implementation – and AI is perfect for accelerating both! In this methodology, therefore, there is no push-button design – the designer is in the loop directing the next evolution of the design, whether it is fixing a problem or adding a new feature, to reach the intended behavior and performance of the hardware design.
In this blog, we will describe our experiences in applying AI to help accelerate design of a ROHD-HCL component. The ROHD framework provides some key advantages for using AI to accelerate agile hardware design. As Dart is a popular programming language, LLMs are well-trained in Dart and able to take advantage of a lot of the software abstractions we use in ROHD. A big innovation is the AI coding agents like Dart MCP servers for bridging between AI agents and Dart coding IDEs and are automatically enabled in VS Code Copilot.
By keeping to highly modular and flexible components, we raise the abstraction of design and narrow the amount of context the LLM (and the human!) have to keep around. The ROHD framework has a very rapid edit/simulate loop due to its built-in simulator, providing an LLM with a very fast way to experiment with tests and learn what went wrong. We found this to be absolutely critical in converging hardware design by specifying tests to quickly resolve key ambiguities in our first specification.
We also have a detailed video demonstration of the AI-accelerated design evolution of this component: AI-Accelerated Agile Design Demo.
AI Challenge: Build a New Caching Request/Response Channel
An interesting component for use with communication channels is a request/response channel where we send an address request to a downstream agent, and we receive data back over a response channel, using ready/valid protocols. The specific channel we want to build is one that would cache address/data pairs to speed up future address/data requests.

Designing this component using an agile hardware design methodology, this blog will illustrate how we employ AI in an interactive design loop, where we specify incremental outcomes and let AI run in the ROHD framework assisting the designer, accessing the interactive ROHD simulator, and testing given scenarios, in order to jointly discover and fix problems in the design.
Design the API First
The problem of designing a good component starts with defining a good API, and we realized we could define a small family of request/response channels and familiarize ourselves and the LLM with how to assemble and test these channels.
Here is the prompt we used to generate a primitive form of our component, simple forwarding, before we build the caching form. This helped drive the correct API first, as well as set up simple testing frameworks, as a warm-up for the LLM, and in our case we used Claude Sonnet 4.
Please create a future memory ROHD component called RequestResponseChannel that has an upstream pair of interfaces, one for request and then response, and a mirror set of downstream request and response interfaces. The component will forward an upstream request to the downstream request, and forward a downstream response to the upstream response interface. As it will eventually have subcomponents, please add required clk and reset signal to the component.
These interfaces will be based on the ReadyValidInterface class in lib/src/interface/ready_valid_interface.dart, derived from PairInterface which connects internal ports using pairConnectIO.
A request would be comprised of an id and address, and the response would have an id and data.
Initially the component will simply forward the requests and responses.
The LLM was able to understand our request for structuring the Logic signals by creating a pair of structures for request and response like this one for the RequestStructure:
class RequestStructure extends LogicStructure {
/// The transaction ID field.
Logic get id => elements[0];
/// The address field.
Logic get addr => elements[1];
/// Creates a [RequestStructure] with the specified [idWidth] and [addrWidth].
RequestStructure({required int idWidth, required int addrWidth})
: super([
Logic(width: idWidth, name: 'id', naming: Naming.mergeable),
Logic(width: addrWidth, name: 'addr', naming: Naming.mergeable),
], name: 'requestStructure');
/// Private constructor for cloning.
RequestStructure._fromStructure(LogicStructure original, {String? name})
: super(original.elements.map((e) => e.clone()).toList(),
name: name ?? original.name);
@override
RequestStructure clone({String? name}) =>
RequestStructure._fromStructure(this, name: name);
}
And here is the generated API of the abstract base class of the component:
RequestResponseChannelBase({
required Logic clk,
required Logic reset,
required ReadyValidInterface<RequestStructure> upstreamRequestIntf,
required ReadyValidInterface<ResponseStructure> upstreamResponseIntf,
required ReadyValidInterface<RequestStructure> downstreamRequestIntf,
required ReadyValidInterface<ResponseStructure> downstreamResponseIntf,
super.name = 'requestResponseChannelBase',
super.reserveName,
super.reserveDefinitionName,
String? definitionName,
}) : super(
definitionName: definitionName ??
'RequestResponseChannelBase'
'_ID${upstreamRequestIntf.data.id.width}'
'_ADDR${upstreamRequestIntf.data.addr.width}'
'_DATA${upstreamResponseIntf.data.data.width}') {
// Add clock and reset as inputs.
this.clk = addInput('clk', clk);
this.reset = addInput('reset', reset);
// Clone and connect upstream request interface (consumer role).
upstreamRequest = upstreamRequestIntf.clone()
..pairConnectIO(this, upstreamRequestIntf, PairRole.consumer,
uniquify: (original) => 'upstream_req_$original');
...
// Clone and connect downstream response interface (consumer role).
downstreamResponse = downstreamResponseIntf.clone()
..pairConnectIO(this, downstreamResponseIntf, PairRole.consumer,
uniquify: (original) => 'downstream_resp_$original');
// Call subclass-defined logic.
buildLogic();
}
And here is the simplest implementation of the channel.
class RequestResponseChannel extends RequestResponseChannelBase {
/// Creates a [RequestResponseChannel] that directly forwards requests
/// and responses.
RequestResponseChannel({
...
}) : super(
...
);
@override
void buildLogic() {
// Forward upstream request to downstream request.
downstreamRequest.data <= upstreamRequest.data;
downstreamRequest.valid <= upstreamRequest.valid;
upstreamRequest.ready <= downstreamRequest.ready;
// Forward downstream response to upstream response.
upstreamResponse.data <= downstreamResponse.data;
upstreamResponse.valid <= downstreamResponse.valid;
downstreamResponse.ready <= upstreamResponse.ready;
}
}
A Caching Request Response Channel
Our LLM was also able to quickly build a buffered form of the RequestResponseChannel, inserting FIFOs where the wires are. It learned the basics of ready/valid interface testing using this component and was well-prepared to move on to the more complex caching form shown here.
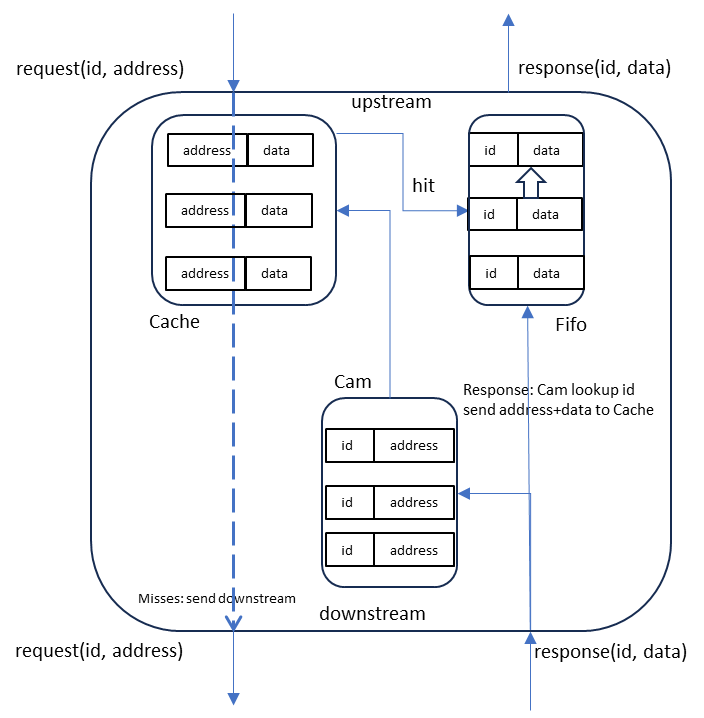
The caching form has fairly simple rules for data flow, and we captured them in as short an English language description as we thought necessary to cover all data flow.
Upstream address requests that miss the cache are passed downstream and stored in a CAM. Request hits are stored in the response FIFO to send as an upstream response. Downstream responses are paired with their matching address based on id lookup in the CAM to store in the cache and are also added to the response FIFO.
This description was the starting point for our first prompt for the LLM (below) after which we used directed tests to iron out any corner conditions that were not clearly understood, or where our own understanding evolved after seeing first attempts by the LLM.
At all times we had a running implementation: the LLM was quite good at creating correct syntax on both implementation and testing side, and made minor mistakes on semantics, like when to sample a combinational signal in a test. Very few iterations were needed to correct the LLM and drive new features without redirecting the LLM on basics.
Here is the prompt we used to generate an initial form of our component, after which we used a sequence of prompts to test the component and resolve ambiguities in the specification until the component can pass the tests we proposed.
This is a ROHD component that inherits from the RequestResponseChannelBase and caches address requests.
Internally this component would check if the upstream request address is in an address/data Cache and if so, it would add an entry to a response ReadyValidFifo that comprises the id and data to eventually return through the upstream response.
If the address is not in the cache, It would store the request in a FullyAssociativeCache (or Cam) with id as tag and the address as data and forward the request to the downstream request interface. The upstream request blocks on a hit if either the FIFO is not ready or the downstream response is valid and needs to store the response in the FIFO. On a miss it blocks if the downstream FullyAssociativeCache is full.
The downstream response interface blocks if the response FIFO is not ready. Once the downstream response interface is valid, its response id is tag-matched in the FullyAssociativeCache (or Cam) to find the address associated with the id. It would pair that with the data on the response interface and store that in the cache. It would also push an entry onto the response Fifo containing the id and data from downstream.
Initial LLM generated Tests
As part of its debugging process, the LLM generated simple tests to check if the component it created was matching our specification, or to resolve its own understanding of simulation semantics by simulating its own pieces of code.
For example, the first test to pass was this simple 1-miss, then 1-hit which sends the (id,address)=(1,a) request which transits to the downstream which responds with (id,data)= (1,d) at clock cycle 5, which gets sent as an upstream response at clock cycle 6 of (1,d). Then at clock cycle 7, a second request (id,address)=(2,a) is sent in which is accepted and hits as there is no downstream propagation. At clock cycle 8, the upstream response receives (id,data)=(2,d).

A second test to pass was similarly simple: a sequence of three misses (id,address)=[(1,a),(2,b),(3,c)] at cycles 3,5,7, which get transmitted downstream as misses with data returns at cycles 9,10,11 as (id,data)=[(1,d),(2,d),(3,b)]. These data responses are returned upstream at cycles 10,11, and 12, respectively. At cycles 15, 17, and 19, new requests to the same addresses are made (id,address)=[(b,a),(c,b),(d,c)], which hit, and are returned as upstream data responses (id,data)=[b,d),(c,c),(d,b)] at cycles 16, 18, and 20 (one cycle later) respectively.

The LLM generated other tests that we noticed were insufficient to drive fixes to problems that appeared, like blocking misses upstream when the response FIFO was full. So we created more careful prompts to drive specific edge cases without ambiguity.
Directed Testing Prompts
Considering the microarchitecture, there are only a few paths that should be blocking due to capacity, so we created directed tests for filling the response FIFO and filling the CAM.
The first was directed at the response FIFO:
Please create a test case for our CachedRequestResponseChannel where we send a series of unique address requests whose downstream responses fill up the response FIFO and end up back-pressuring the downstream response interface, as well as the upstream request interface but only for hits (on an address from a previous request) not further misses on unique address requests.
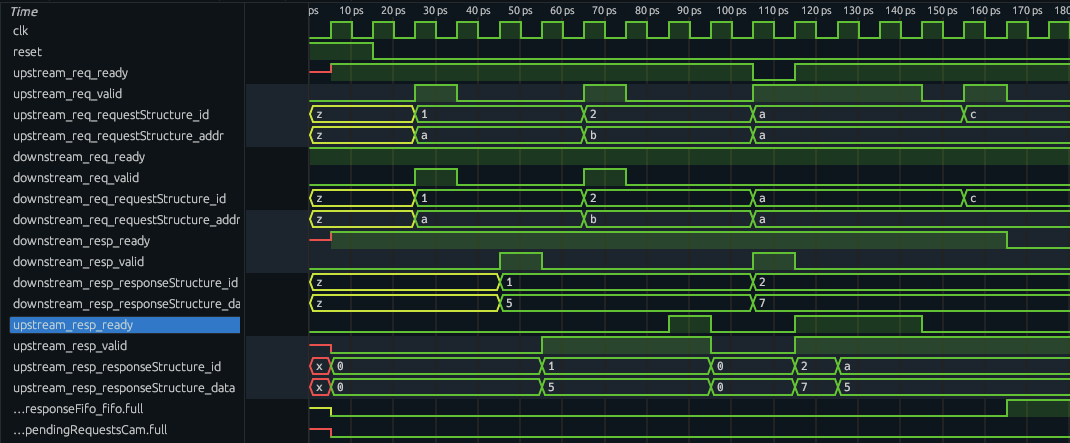
In this test you can see data responses (id,data)=[(1,1),(2,2),(3,3)] starting at cycle 13 responding to upstream address requests (id,address)=[(1,a),(2,b),(3,c)] starting at cycle 3. At cycle 14, with the (3,3) data response, the response FIFO becomes full which blocks the upstream request at cycle 20 (id,address)=(a,a) because the address a would be a hit. The next cycle 21, (id,address)=(b,f) is a miss and propagates to the downstream request even though the response FIFO remains full. At cycle 24, the upstream response is ready which starts clearing the response FIFO, and we see responses (id,data)=[(1,1),(2,2),(3,3)] accepted. The response FIFO is no longer full starting at cycle 25.

This test was directed at timing an upstream hit and downstream response to land at the response FIFO at the same time.
Please create a test case where we have an upstream request with an address that, if accepted, would hit in our cache at the same time as a downstream response is coming back and needs to be stored in the response FIFO. Demonstrate that the upstream request is back pressured and not accepted until the downstream response is stored in the FIFO.
In this case, you see that at cycle 5, a downstream response (id,data)=(1,5) lands in the cache. Then at cycle 110, a data response (id,data)=(2,7) is arriving along with an upstream request (id,address)=(a,a). Since address a would be a hit, we can see the upstream request ready is dropped to block this request.
A third path to consider is how the CAM filling up would block upstream address miss requests.
Create a test-case where the pendingRequestCam fills up and back-pressures the upstream request.
In this case there was no way to create a failing case and the LLM reported a struggle in finding any convincing case that back-pressure could occur.
It was at this point that we realized we had not built a CAM with back-pressure yet, we only had a fully associative cache that would simply keep pushing out older ids as we did more miss fills. We need a CAM with back-pressure! When we insisted this test pass, the LLM inserted occupancy tracking in the component around the CAM. But this was starting to look fragile, as entries in the CAM were allowed to be evicted as they aged instead of by intent and this would require more careful testing with ordering to make sure no live id was accidentally evicted. It would be better to make the CAM component smarter and handle its own back-pressure.
CAM with Back-pressure
In realizing we needed a CAM with back-pressure, we used AI to drive this feature into the existing component. We broke this up into two sub-features: first, we wanted to support the case that if the CAM were full and a tag-match was happening at the same time as a fill, it would not block the fill (in this case our address miss). One way to accomplish this is to perform a read and invalidate of the entry. Then the second sub-feature was to keep track of the count of valid entries. But to do both of these required fairly invasive changes to the logic around the tag RegisterFile inside the CAM.
Read with Invalidate
We drove this feature into the CAM using the following prompts:
Please create a separate state for the valid bit of the tag rather than storing it with the tag so that we can update the tag valid bit without having to use a write port on the register file.
AI made this modification by running existing tests to make sure this refactoring did not break existing functionality.
Please add a boolean option on the
ValidDataPortInterfaceto allow for a readWithInvalidate signal to be passed in with to the read ports; this option would not be available for writes and should be checked that it is not enabled.
The AI agent worked much the same way, but also created tests for the readWithInvalidate flag set, testing that a second read would miss.
Create logic to do readWithInvalidate: make sure a cache tag match checks that the corresponding valid bit is true, and upon a cache hit, return the hit data, but also set the valid bit of the entry to false.
Occupancy Tracking
We had two examples of occupancy tracking at our fingertips: first was the tracking that AI had inserted into our component, but the second was the tracking we did for our Fifo component. We chose to drive with the latter because it reused things like our Count component and works with multi-ported access.
Now add optional occupancy logic to our FullyAssociativeCache, using a similar API as the Fifo for full/empty. Use a key test that a fill simultaneously with a readWithInvalidate on a full cache should be possible, just like a read and write on a full Fifo is possible.
Integration of New CAM
As we had our stress test, we could simply ask AI to insert the new component replacing the existing occupancy logic and retest.
Adapt the CachedRequestResponseChannel to use the new CAM feature.
Please replace the occupancy logic of the CacheRequestResponse Channel by using this new generateOccupancy feature of the FullyAsssociativeCache.
Retrying to Backpressure from Full CAM
Now we reused our prompt for creating a backpressure test-case for the CAM, but were a bit more precise in the corner conditions we wanted to see tested.
Create a test-case where the pendingRequestCam fills up and backpressures the upstream request.
While the CAM is full, we should try an address request miss, then an address request hit, then an address request miss, but with a simultaneous downstream data response that clears an entry in the CAM.
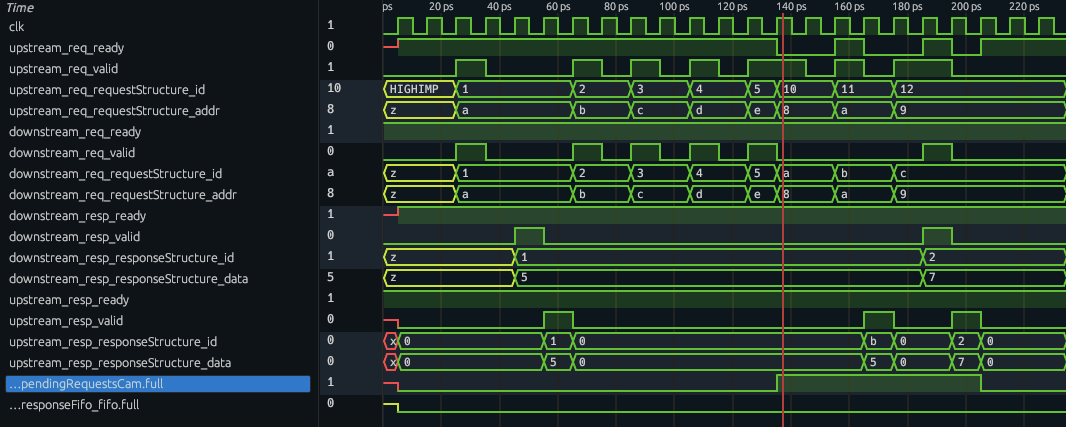
Here is the resulting test output of our CachedReqeuestResponseChannel with the new CAM. At cycle 7, we see a sequence of upstream address requests (id,address)=[(2,b),(3,c),(4,d),(5,e0)] which miss the CAM and are sent downstream, with the CAM getting full at cycle 14. At cycle 15, we see the request (id,address)=(10,8) which would be a miss, not be accepted (request ready is low) due to back-pressure from the CAM. Then at cycle 16, the hit (11,a) request is accepted. At cycle 18, the request (12,9) which is a miss, is rejected, but when a downstream response (2,7) comes in cycle 19, the (12,9) request is accepted with the ready and valid on the upstream request going high, indicating our CAM is able to process a miss fill and a read invalidate simultaneously and stay full.
CachedRequestResponseChannel Implementation
Generalized API
Using patterns in the ROHD-HCL library, the LLM was able to clean up and generalize the API of our component, allowing for arbitrary Caches to be used for the data-address cache and arbitrary ReplacementPolicy for the CAM along with the usual depth and way parameters of the memories.
class CachedRequestResponseChannel extends RequestResponseChannelBase {
...
/// Function to create the address/data cache instance.
final Cache Function(
Logic clk,
Logic reset,
List<ValidDataPortInterface> fills,
List<ValidDataPortInterface> reads) cacheFactory;
/// Function to create the replacement policy for the CAM.
final ReplacementPolicy Function(
Logic clk,
Logic reset,
List<AccessInterface> hits,
List<AccessInterface> allocs,
List<AccessInterface> invalidates,
{int ways,
String name}) camReplacementPolicy;
...
CachedRequestResponseChannel({
...,
required this.cacheFactory,
this.camReplacementPolicy = PseudoLRUReplacement.new,
this.responseBufferDepth = 16,
this.camWays = 8,
super.name = 'cachedRequestResponseChannel',
super.reserveName,
super.reserveDefinitionName,
String? definitionName,
}) : super(
...
The core instantiation is straightforward with the three main components of address/data cache, response FIFO, and pending response CAM.
@override
void buildLogic() {
final idWidth = upstreamRequest.data.id.width;
final addrWidth = upstreamRequest.data.addr.width;
final dataWidth = upstreamResponse.data.data.width;
// Create cache interfaces.
cacheReadPort = ValidDataPortInterface(dataWidth, addrWidth);
cacheFillPort = ValidDataPortInterface(dataWidth, addrWidth);
// Create CAM interfaces - stores ID as tag, address as data.
// Enable readWithInvalidate for atomic read+invalidate operations.
camReadPort =
ValidDataPortInterface(addrWidth, idWidth, hasReadWithInvalidate: true);
camFillPort = ValidDataPortInterface(addrWidth, idWidth);
// Create address/data cache using the factory function.
addressDataCache =
cacheFactory(clk, reset, [cacheFillPort], [cacheReadPort]);
// Create pending requests CAM - ID as tag, address as data.
pendingRequestsCam = FullyAssociativeCache(
clk, reset, [camFillPort], [camReadPort],
ways: camWays,
replacement: camReplacementPolicy,
generateOccupancy: true,
name: 'pendingRequestsCam');
// Create internal response interface for FIFO input.
internalResponseIntf = ReadyValidInterface(
ResponseStructure(idWidth: idWidth, dataWidth: dataWidth));
// Create response FIFO.
responseFifo = ReadyValidFifo<ResponseStructure>(
clk: clk,
reset: reset,
upstream: internalResponseIntf,
downstream: upstreamResponse,
depth: responseBufferDepth,
name: 'responseFifo');
// Build the main cache logic.
_buildCacheLogic();
}
Here is the internal logic connecting the address/data cache, response FIFO and pending response CAM:
void _buildCacheLogic() {
final cacheHit = Logic(name: 'cacheHit');
final camHit = Logic(name: 'camHit');
cacheReadPort.en <= upstreamReq.valid;
cacheReadPort.addr <= upstreamReq.data.addr;
cacheHit <= cacheReadPort.valid;
camReadPort.en <= downstreamResp.valid;
camReadPort.addr <= downstreamResp.data.id;
camReadPort.readWithInvalidate <= downstreamResp.valid;
camHit <= camReadPort.valid;
final respFromCache = upstreamReq.valid & cacheHit;
final respFromDownstream = downstreamResp.valid & camHit;
final camSpaceAvailable = ~pendingRequestsCam.full! | respFromDownstream;
upstreamReq.ready <=
(cacheHit & internalRespIntf.ready & ~respFromDownstream) |
(~cacheHit & downstreamReq.ready & camSpaceAvailable);
final forwardMissDownstream =
upstreamReq.valid & ~cacheHit & downstreamReq.ready & camSpaceAvailable;
downstreamReq.valid <= forwardMissDownstream;
downstreamReq.data <= upstreamReq.data;
camFillPort.en <= forwardMissDownstream;
camFillPort.valid <= forwardMissDownstream;
camFillPort.addr <= upstreamReq.data.id;
camFillPort.data <= upstreamReq.data.addr;
cacheFillPort.en <= respFromDownstream;
cacheFillPort.valid <= respFromDownstream;
cacheFillPort.addr <= camReadPort.data; // Address from CAM.
cacheFillPort.data <= downstreamResp.data.data; // Response data.
internalRespIntf.valid <=
respFromDownstream | (respFromCache & ~respFromDownstream);
final responseId = Logic(width: internalRespIntf.data.id.width);
final responseData = Logic(width: internalRespIntf.data.data.width);
Combinational([
If.block([
Iff(respFromDownstream, [
responseId < downstreamResp.data.id,
responseData < downstreamResp.data.data,
]),
Else([
responseId < upstreamReq.data.id, // Cache hit case
responseData < cacheReadPort.data,
])
])
]);
internalRespIntf.data.id <= responseId;
internalRespIntf.data.data <= responseData;
downstreamResp.ready <= internalRespIntf.ready;
}
All LLM-generated code and tests, including a lot of the debugging and learning Dart files that the LLM used, are available in AI-generated CachedRequestResponseChannel.
AI-accelerated Agile Design for the Win
Our experiences in using AI in an interactive agile design environment show that using AI to assist the design in an iterative, test-driven, always-alive and feature-by-feature design flow is an amazingly synergistic methodology. Having a working design and running tests helps keep an LLM understanding the targets of the design while expanding the feature set or focusing on fixing the counter-examples. Building features from tests is even easier and more natural when an LLM is implementing the design than when a human is: tests can be described at a higher, more goal-oriented level to drive toward the conditions you want explored as a designer. At no point in this experience were we forced to debug a very low, bit-level problem or fence post error, but rather we simply asked AI to help resolve detailed problems on its own using abstract challenge prompts.
Another synergy between agile design and employing an LLM within the design loop is the idea of starting from a working design, breaking it with a new feature and then driving toward a full fix for the current feature and previous tests. AI lets the designer be far more assertive in making large changes – witness our refactoring of our tag array to isolate out the valid bit and add read+invalidate, a feature that took minutes to try with an LLM to build a working version and tests for what started out as a high level direction. This allowed us to break a currently working design and quickly restore it adding new functionality and verification tests with confidence.
Overall, AI-accelerated hardware design is a very effective and satisfying way to achieve very high levels of productivity without the fear of changing too much hardware too quickly to back out of suboptimal design choices in the search of design improvements or advanced features.