Building tenets: Intelligent Context Aggregation for AI Pair Programming
Uncanny AI coding assistants
I work often with AI pair programming tools - CoPilot Chat, Cursor, Codex, Claude Code, aider, Windsurf (not so much anymore). They all have access to your Git repos and basic terminal commands (if you give it to them, though from anecdotes on the web and my personal experiences as well, it’s clear that permissions unfortunately isn’t exactly deterministic in these tools, but this is a way different discussion) like ls and grep, and of course nano or rmv.
An incredibly strange thing with LLMs is you will tell them something very specific, like: “logic in the summarizer is lo…
Building tenets: Intelligent Context Aggregation for AI Pair Programming
Uncanny AI coding assistants
I work often with AI pair programming tools - CoPilot Chat, Cursor, Codex, Claude Code, aider, Windsurf (not so much anymore). They all have access to your Git repos and basic terminal commands (if you give it to them, though from anecdotes on the web and my personal experiences as well, it’s clear that permissions unfortunately isn’t exactly deterministic in these tools, but this is a way different discussion) like ls and grep, and of course nano or rmv.
An incredibly strange thing with LLMs is you will tell them something very specific, like: “logic in the summarizer is looping twice because the batch processor isn’t clearing the processed_chunks var, fix it”, which is not a great prompt but gets things started, and then you’ll see the tool calling commands running:
# First attempt - literal string matching
grep -r "batch processor isn't clearing the processed_chunks"
grep -r "looping twice"
then maybe:
# Second attempt - basic word stemming
grep -r "summar\(y\|izer\|ies\|ize\|ization\)"
grep -r "loop\(ing\|ed\|s\)\?\s*twice\|double\|duplicate"
grep -r "clear\(ing\|ed\|s\)\?\s*\(the\s*\)\?\(batch\|chunks\?\|buffer\)"
grep -r "batch\s*process\(or\|er\|ing\)\?"
and maybe then:
# Third attempt - finally looking for actual variable names
grep -r "processed_chunks\|process_chunks\|chunk_process\|chunks_processed"
grep -r "self\.processed_chunks"
Usually it’ll find it after like 1-2 attempts after the first failed honestly, it’s not such a hindrance you find it to be a real issue.
The example’s exaggerated to demonstrate a symptom of a larger issue at play interacting with LLMs, cause I guess what really gets me is the first step always (at the moment) seems to be, query the exact phrase the user’s looking for in every file. That is dumb, even for a first move, even for a LLM. Then of course it has graceful escalation from there, regexing multiple synonyms or breaking down the phrase into manageable chunks.
What’s also strange is the LLM has full access to your files (read at least) but they won’t go too exploratory in the process of finding and collecting the data (even after you give them permission!). LLMs won’t (importantly it’s won’t not can’t) even recursively walk a directory and at least check for file names (reading contents is too much to ask for) to build a tree structure to understand what the codebase actually looks like; at most it’ll look at the imports in a relevant file or two and trace some key methods. Claude Opus at this point oftentimes just tries to read the first 100 lines or so before it stops, hoping it’s gotten enough.
This is insanely weak for document similarity, a problem with a lot of innovated on solutions already, and something that’s a foundational utility of AI programming assistants.
And we’re not even going to think about the costs of additional LLM calls when static tools could do the job, especially when conversations get larger and LLMs start summarizing with more LLMs (just extractive summarization algorithms or something like BERT, though BERT’s significantly slower, work great if not better since they are more deterministic, which in code, absolutely you do not want paraphrasing).
We’ll see AI platforms insist on LLMs ingesting and outputting every solution, which does makes sense sometimes, and other times seems stubborn and backwards. And more often than not these sort of barriers are intended consequences stemming from safeguards or system instructions to optimize token windows.
What is
tenets is a Python library that intelligently navigates repos (or any directory of files) to match, analyze, summarize, and aggregate the most relevant context based on speed, accuracy, and token limits. It uses deterministic algorithms (regex, BM25, cosine similarity) with optional ML embeddings for semantic understanding, and extractive summarization as well as optional LLM summarization that takes into account hierarchy in high-level metadata (how many times a function is referenced, how complex a function may be, etc.), imports / dependencies, and other metrics for heuristics for a total of [10 ranking factors](## Multi-Signal Ranking).
None of tenets’s functionality costs API credits - all processing is done locally. There are optional LLM integrations for summarizing, but the recommended route is using the built-in summarizer algorithms first.
tenets is able to perform its full distillation (aggregation of context, without ML embeddings) functionality on complex repos with hundreds of source files typically in 30-40 seconds, making it usable as a programmatic API for pair programming tools like aider or Claude CLI (which is intended as one of its end goals).
And yes, at some late midway point in tenet’s development, I dogfooded the tool to help it build itself. Tenets was built with the help of Copilot Chat (GPT-5) and Claude Opus / Sonnet.
Features in Action
Context Building
When you run tenets distill "add mistral api to summarizer", tenets analyzes your codebase.
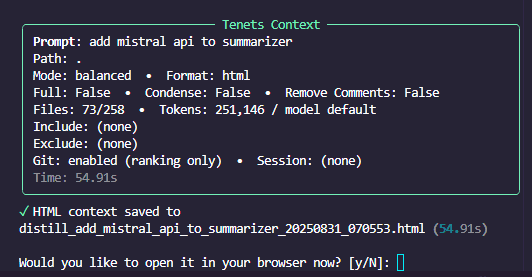
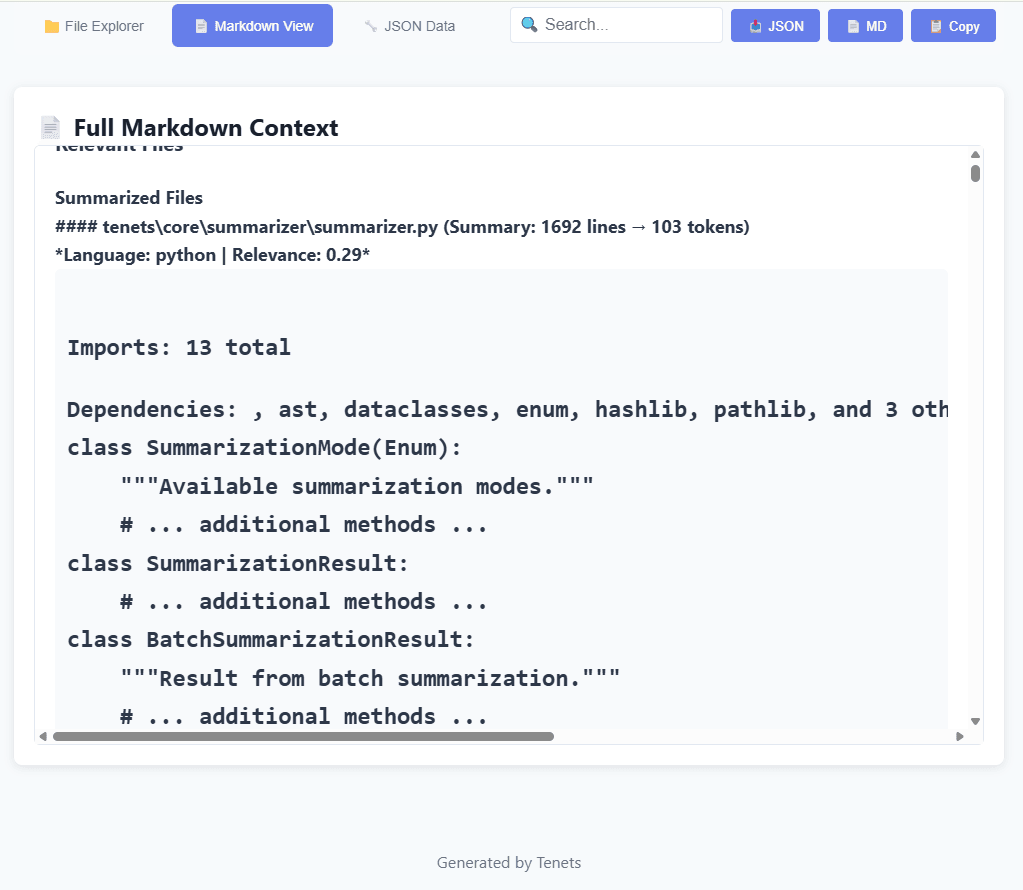
You can also provide GitHub issue or Jira links in a query and tenets will fetch and extract those contents and consider them in the rankings of the files as well as contents to output in the final distillation.
We use regex and keyword matching to classify different programming intents in the inputs, for things like documentation, testing, bug fixing, feature creation, refactoring, etc. Naturally, this is a tricky thing to capture correctly when not using models trained for intents (which might be reserved for future versions as an optional step), and as such, a weighted system is in place, and classifications are only a partial factor in the rankings.
We also use the same system to match temporal patterns for time, and factor all that into the analysis / ranking (you can ask about changes from a few days ago and it will rank recently changed files higher).
File Ranking
tenets rank "fix summarizing truncation bug" --tree
![]()
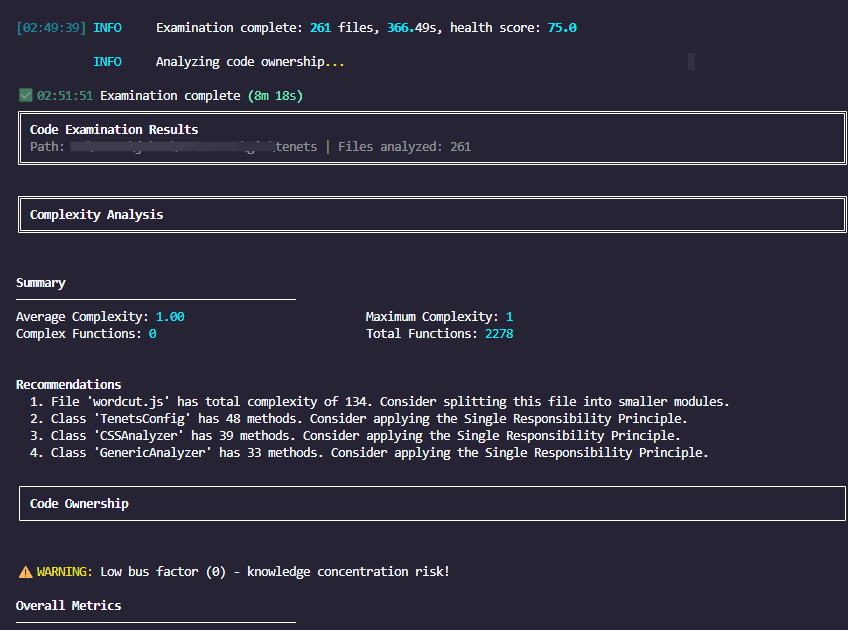
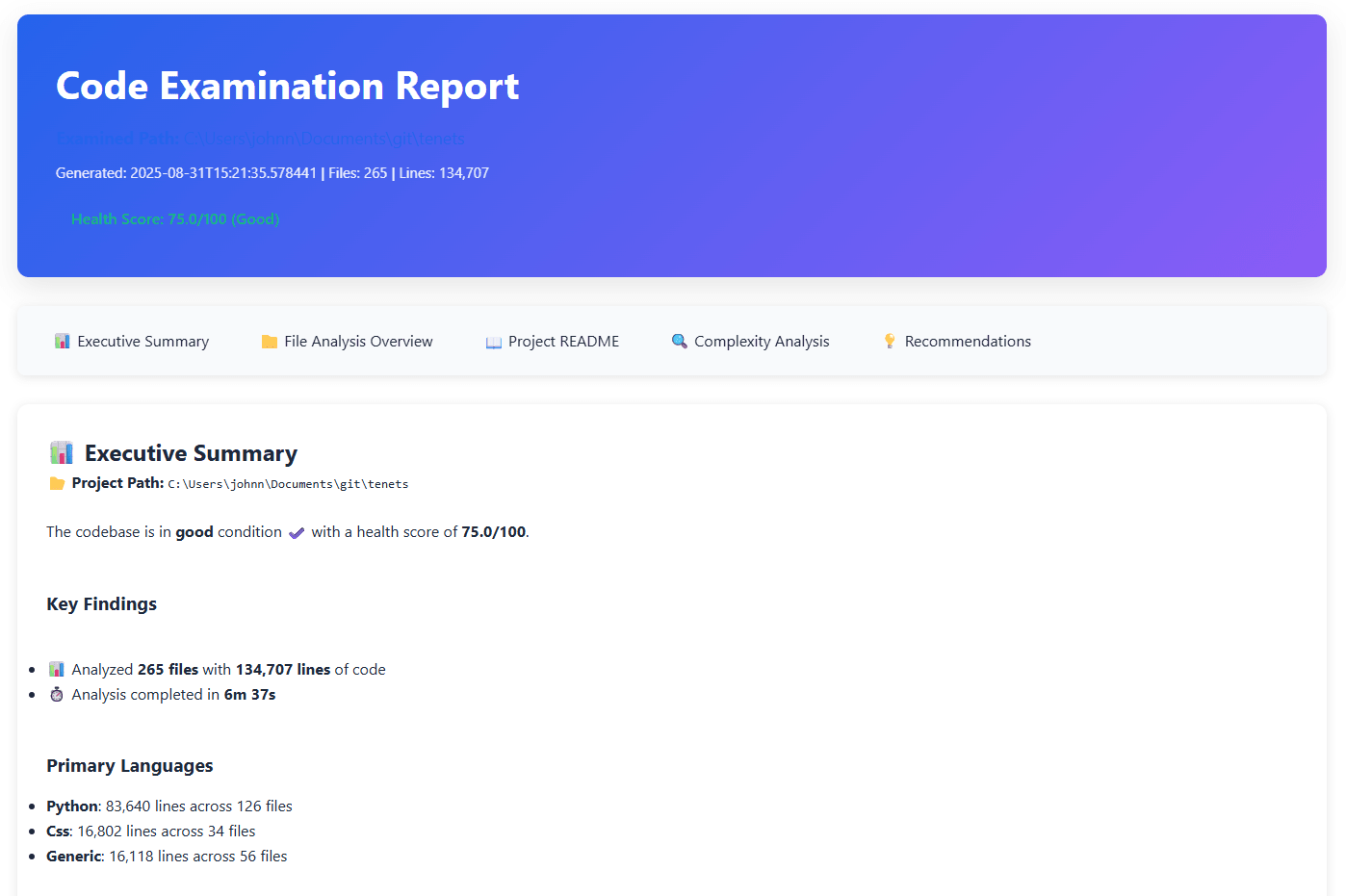
Code Analysis & Quality Metrics
tenets examine . --complexity --hotspots --ownership
Session Management
Sessions maintain context across multiple interactions.

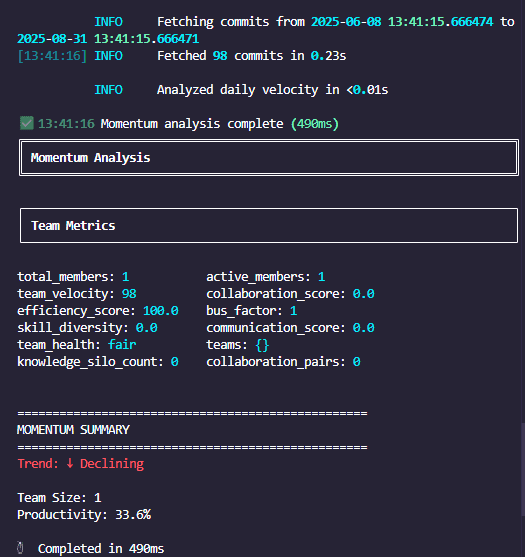
Team Velocity & Visualization

Technical Design
Tenets operates in 3 modes, fast, balanced, and thorough. Balanced is about 1.5x slower than fast, and thorough is about 4x slower. Thorough utilizes ML embeddings for semantic searching and matching.
Ranking / similarity
BM25 is a probabilistic ranking algorithm that scores documents for relevancy. Since code files vary from 10 to 10,000+ lines, length shouldn’t bias relevance too much. BM25 adds term saturation (diminishing returns for repeated terms) and document length normalization.
For each term:
score = IDF(term) × [TF × (k1 + 1)] / [TF + k1 × (1 - b + b × docLength/avgDocLength)]
Code is inherently redundant. A test file with 50 instances of assert response.status == 200 shouldn’t dominate searches for “response”. BM25’s term saturation prevents this.
We also support tf-idf analysis with sparse cosine similarity (though this is less recommended as it does not account as well for issues like what we just mentioned).
# BM25: Stores raw tokens, calculates scores on-the-fly
doc_tokens = ["Summarizer", "summary", "summarize", "tenets", ...]
doc_tf = Counter(doc_tokens) # Sparse: {'Summarizer': 3, 'summary': 5, ...}
# Sparse vector comparison for tf-idf cuts down memory usage by multiple 10x factors
def sparse_cosine_similarity(vec1, vec2):
common = set(vec1.keys()) & set(vec2.keys())
dot_product = sum(vec1[t] * vec2[t] for t in common)
norm1 = math.sqrt(sum(v**2 for v in vec1.values()))
norm2 = math.sqrt(sum(v**2 for v in vec2.values()))
return dot_product / (norm1 * norm2)
No stemming or lemmatization, normalizing text so all word forms become base words only; the difference between summary() method and Summary() class, or summarize method versus summarized var matters greatly in code, not so much in something like academic research. Using tenets for querying against research papers over source code would technically work but result in poorly matched results.
It’s important to note that I advertise thorough mode of tenets as being the best at exploring and discovering relationships between code, not necessarily finding the most accurate context for your prompts, hence calling it thorough over accurate.
In thorough mode, embeddings see process_batch() and handle_batch() as semantically similar when you may need or want exact matches. Usually balanced is exactly what a day-to-day user of tenets would need.
Configurable output with smart truncating
tenets can preserve complete methods or intelligently truncate.
# Never truncate - full methods only
tenets distill "refactor auth" --no-truncate --preserve-structure
# Smart truncation within token budget
tenets distill "refactor auth" --smart-summary --max-tokens 4000
With --no-truncate, we select whole methods by relevance.
def extract_methods_smart(file, token_budget):
methods = parse_ast(file)
# Score each method
for method in methods:
method.score = calculate_relevance(method, query)
method.tokens = count_tokens(method.body)
# Greedy selection - highest value first
selected = []
remaining_tokens = token_budget
for method in sorted(methods, key=lambda m: m.score, reverse=True):
if method.tokens <= remaining_tokens:
selected.append(method)
remaining_tokens -= method.tokens
return selected # Complete methods only
Smart truncation preserves structure while condensing.
def smart_truncate(method, max_tokens):
# Always keep signature + docstring
essential = extract_signature(method) + extract_docstring(method)
# Prioritize: errors > control flow > implementation
for line in method.body:
if is_error_handling(line):
priority = 3
elif is_control_flow(line):
priority = 2
else:
priority = 1
# Take highest priority lines within budget
Note: For our core modes (fast and balanced) keyword extraction we are not considering any ML-related dependencies, relying on statistical algorithms since this will be the basis of our search / ranking systems. Only in thorough mode do we consider embeddings.
| Algorithm | Speed | Quality | Memory | Python 3.13 | How It Works |
|---|---|---|---|---|---|
| RAKE | Fast | Good | Minimal | ✅ Yes | Degree/frequency scoring |
| YAKE | Moderate | Better | Low | ❌ No | Statistical features + position |
| TF-IDF | Fast | Basic | Medium | ✅ Yes | Needs corpus |
RAKE is primary because it’s simpler, predictable, and has no external dependencies beyond stopwords.
RAKE analyzes word co-occurrence to find multi-word phrases.
text = "Python web framework Django handles authentication"
# Split by stopwords → candidate phrases
candidates = ["Python web framework Django", "handles authentication"]
# Calculate word scores (degree/frequency)
# "Python" appears with 3 other words (degree=4), appears once (freq=1)
# Score = 4/1 = 4.0
# Score phrases (sum of word scores)
"Python web framework Django" = 4.0 + 4.0 + 4.0 + 4.0 = 16.0
BM25 can’t extract keywords from a single prompt because it needs corpus statistics. RAKE/YAKE work on single documents by analyzing internal structure without needing a corpus.
Intricate ranking with multiple weighted signals
tenets combines 10 different factors with configurable weights:
class RankingFactors:
keyword_match: float # 0.20 - Direct keyword presence
bm25_score: float # 0.25 - BM25 relevance (primary)
path_relevance: float # 0.15 - Path/filename matching
import_centrality: float # 0.10 - How often file is imported
git_recency: float # 0.05 - Recent changes
git_frequency: float # 0.05 - Change frequency
semantic_similarity: float # 0.10 - Embedding similarity (if ML)
code_patterns: float # 0.05 - Domain patterns
complexity_relevance: float # 0.03 - Cyclomatic complexity
ast_relevance: float # 0.02 - AST structure matching
Import centrality is a metric to identify which files are most important to a codebase, which we use to figure out core abstractions.
We count how many files import each file (incoming) and how many it imports (outgoing), with a default 70-30 ratio of weight.
def calculate_import_centrality(file, import_graph):
imported_by = sum(1 for deps in import_graph.values() if file in deps)
imports_others = len(import_graph.get(file, set()))
# Weight incoming more - being imported signals importance
centrality = (imported_by * 0.7 + imports_others * 0.3) / total_edges
# Logarithmic scaling to prevent dominant nodes
return min(1.0, math.log(1 + centrality * 10) / 3)
Parallel navigation, analysis, and aggressive file caching based on Git history
We use parallelization in multiple stages.
def rank_files_parallel(files, query, workers=8):
# Phase 1: Build indices (sequential, 2-3s)
bm25_corpus = BM25Corpus(files)
import_graph = build_import_graph(files)
# Phase 2: Parallel factor calculation (2-3s for 500 files)
with ThreadPoolExecutor(max_workers=workers) as executor:
futures = []
for file in files:
future = executor.submit(calculate_all_factors,
file, query, bm25_corpus, import_graph)
futures.append((file, future))
# Collect as they complete
ranked = []
for file, future in futures:
factors = future.result(timeout=1.0)
score = compute_weighted_score(factors)
ranked.append((file, score, factors))
return sorted(ranked, key=lambda x: x[1], reverse=True)
We stream results as they become available instead of waiting.
def scan_and_analyze(self, path: Path):
"""Stream files as they're discovered and analyzed"""
with Progress() as progress:
scan_task = progress.add_task("Scanning", total=None)
for file_batch in self.scanner.scan_parallel(path, batch_size=50):
# Process batch while next batch is being discovered
results = self.analyze_batch(file_batch)
for result in results:
yield result
progress.advance(scan_task)
And based on the intentions classified in the prompt, rankings are adjusted with some weights.
if intent == "debug":
weights["git_recency"] *= 2.0 # Recent changes matter
weights["code_patterns"] *= 1.5 # Error handling patterns
elif intent == "refactor":
weights["complexity_relevance"] *= 2.0 # Complex code needs refactoring
weights["import_centrality"] *= 1.5 # Core abstractions
elif intent == "test":
weights["path_relevance"] *= 2.0 # test/ directories
weights["ast_relevance"] *= 1.5 # assert statements
ML embeddings / semantic similarity
For now, the ML features in tenets weren’t a priority for pre-v1.0 release, but will be ramped up (gracefully with lazy loading) in future versions.
We use sentence-transformers with a default model in all-MiniLM-L6-v2 which provides general-purpose embeddings and can be configured to use other models like microsoft/codebert-base (trained on code), microsoft/unixcoder-base (better for code search), and future support for codellama-13b (for heavier workloads).
Dense embeddings convert your code into numerical vectors where similar code ends up nearby in vector space. We pre-compute embeddings for all files once, then at search time only need to embed your query and find the closest matches - fast but sometimes misses nuanced relationships since query and document are processed separately.
tenets employs a multi-stage ranking system that combines lexical (priority) and semantic signals.
| Stage | Method | Weight | Speed | Use Case |
|---|---|---|---|---|
| Primary | BM25 | 25% | Fast | Exact matches, keywords |
| Secondary | Dense Embeddings | 10% | Fast* | Semantic similarity |
| Optional | Cross-Encoder Reranking | N/A | Slower | Maximum precision |
*After initial embedding computation
Enable different modes based on your needs:
tenets distill "query" --mode quick # BM25 only
tenets distill "query" --mode balanced # BM25 + embeddings (default)
tenets distill "query" --mode thorough # All signals + optional reranking
tenets distill "query" --rerank # Force reranking for precision
Cross-encoder reranking (cross-encoder/ms-marco-MiniLM-L-6-v2) works like a judge that reads both things at once to score relevance. Instead of converting query and document into separate vectors and comparing them, it literally concatenates them.
Dense embeddings compress everything into one vector and hope similar things land nearby.
"implement OAuth2" → [0.2, 0.5, -0.3, ...]
"def oauth2_authenticate()" → [0.3, 0.4, -0.2, ...]
Similarity = high
The model made those vectors separately without ever seeing them together. It’s guessing they’re related based on vector proximity.
Cross-encoders actually read both and make a judgment.
Input: "implement OAuth2 [SEP] def oauth2_authenticate(client_id, secret):..."
Output: 0.95 (this function directly implements OAuth2)
Input: "implement OAuth2 [SEP] # OAuth2 is deprecated, use OAuth3"
Output: 0.15 (mentions OAuth2 but has the **opposite** intent)
Thus, the optional re-ranking takes additional time but is recommended for best accuracy.
Architecture challenge: A functional CLI + Python API
Building a code intelligence platform needs to be responsive and fast, even as it loads necessary ML dependencies or performs recursive folder searching.
With tenets, naturally we’d want to build a nice CLI and Python API in parallel (one of tenet’s major use cases is potential integration into AI tools in IDEs, etc).
# Initial this is our build - looks clean, but circular import hell
from tenets import Tenets
@app.command()
def distill(prompt: str):
tenets = Tenets() # Imports everything
return tenets.distill(prompt)
Python 3.7+ enables proper lazy loading without breaking conventions:
# tenets/__init__.py
_LAZY_IMPORTS = {
'Distiller': 'tenets.core.distiller.Distiller',
'Instiller': 'tenets.core.instiller.Instiller',
'CodeAnalyzer': 'tenets.core.analysis.analyzer.CodeAnalyzer',
}
def __getattr__(name):
"""Lazy import heavy components on first access."""
if name in _LAZY_IMPORTS:
import importlib
module_path, attr_name = _LAZY_IMPORTS[name].rsplit('.', 1)
module = importlib.import_module(module_path)
attr = getattr(module, attr_name)
globals()[name] = attr # Cache for future
return attr
raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
# Usage remains clean:
from tenets import Distiller # No import yet
d = Distiller() # NOW it imports
The CLI only imports what each command needs:
# app.py - Conditional command loading
import sys as _sys
if len(_sys.argv) > 1 and _sys.argv[1] in ["distill", "instill"]:
from tenets.cli.commands.distill import distill
app.command()(distill)
else:
# Lightweight placeholder for help text
@app.command(name="distill")
def distill_placeholder(ctx: typer.Context, prompt: str):
"""Distill relevant context from codebase."""
from tenets.cli.commands.distill import distill
return ctx.invoke(distill, prompt=prompt)
The import time problem is real - import transformers cascades to torch (500ms), numpy (100ms), CUDA (200ms), totaling over 1 second. Our solution: defer until needed.
Import condensation (distilling)
Large files with dozens of imports waste precious tokens. We intelligently condense based on known file structure patterns in programming langues (we support 15+ languages as core first-class features, and have generic analyzers for logical flows).
# Instead of:
import os
import sys
import json
import yaml
from pathlib import Path
from typing import Dict, List, Optional
from collections import Counter, defaultdict
# ... 20 more lines
# We generate:
# Imports: 27 total
# Dependencies: os, sys, json, yaml, pathlib, typing, collections
# Local imports: 3
Saves hundreds of tokens per file while preserving essential dependency information.
Rather than naive line truncation, our summaries are AST-aware and understand code structure:
def summarize_with_ast(file_content, max_tokens):
tree = ast.parse(file_content)
# Extract and score structural elements
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
score = calculate_relevance(node, query)
tokens = estimate_tokens(node)
# Greedy selection within budget
Multi-tier caching
The caching system evolved through iterations:
- Memory-only (first version): Fast but limited
- SQLite-backed (next iterations): Persistent but slower
- Hybrid multi-tier (final release): Memory for hot, SQLite for warm, disk for cold
class HybridCache:
def __init__(self):
self.memory = {} # Hot: <100ms
self.sqlite = SQLiteCache() # Warm: <500ms
self.disk = DiskCache() # Cold: <2s
def get(self, key):
if key in self.memory:
return self.memory[key]
if value := self.sqlite.get(key):
self.memory[key] = value # Promote to hot
return value
if value := self.disk.get(key):
self.sqlite.set(key, value) # Promote to warm
return value
Usage Examples
Basic Context Building
# Intelligent context extraction
tenets distill "implement OAuth2 authentication"
# With optimizations
tenets distill "implement caching layer" \
--remove-comments \
--condense \
--max-tokens 8000 \
--include-tests
# Focus on specific patterns
tenets distill "refactor authentication" \
--glob "**/*auth*.py" \
--exclude "tests/*"
Advanced Configuration
# Custom ranking weights
tenets rank "optimize queries" \
--weight-keyword 0.3 \
--weight-imports 0.2 \
--weight-complexity 0.2
# Preserve full methods
tenets distill "understand payment flow" \
--no-truncate \
--preserve-structure \
--include-docstrings
Code Quality Analysis
# Full examination
tenets examine . \
--complexity \
--hotspots \
--ownership \
--show-details \
--format json > metrics.json
# Track momentum
tenets momentum \
--team \
--since "last month" \
--detailed
Visualization
# Interactive dependency graph
tenets viz deps --format html --output deps.html
# Complexity heatmap
tenets viz complexity --format svg --output complexity.svg
# Export session history
tenets session export payment-integration --format markdown
Closing
We’re closing in on a future where LLMs are becoming the glue to hold other pieces and services together that fundamentally should be deterministic, even to the point where it can become LLM calls verifying other LLM calls in guardrails or other forms of abstractions.
It seems like being in favor of “cleanliness” or perhaps laziness or just plain intentional design decisions to not utilize anything but LLMs for agency when we build and use AI agents, choosing to ignore existing, well-documented static solutions in text analysis and natural language processing, is going to be a decision that compounds in slight effects overtime to snowball into something contentious.
The future of AI pair programming isn’t about throwing more compute at the problem or simply relying on models to get bigger and better.
As for the future of tenets, there are clear applications for document similarity matching at the performance and complexity that this library can perform at beyond building developer tools. While tenets is currently fully implemented just to support programming contexts, the modules can easily be packaged out into something composable for any type or genre of documents. At some point I think I’ll be using tenets in some capacity for PKMS and other personal bookkeeping.
Install: pip install tenets
Docs: tenets.dev
GitHub: github.com/jddunn/tenets