Background: Hybrid Inference for Sparse MoE Models
Modern Mixture-of-Experts (MoE) language models such as DeepSeek-V3 contain hundreds of billions of parameters, but only a small subset of experts are activated per token.
This sparse activation pattern makes MoE models ideal for CPU/GPU hybrid inference: the sparsely activated experts can run efficiently on CPUs with large memory capacity, while the dense and compute-intensive components — attention and shared experts — execute on GPUs with higher bandwidth and throughput.This hybrid design allows trillion-parameter models to be deployed on a single machine with limited GPU memory, enabling local inference for research and private applications.
 language models such as DeepSeek-V3 contain hundreds of billions of parameters, but only a small subset of experts are activated per token.
This sparse activation pattern makes MoE models ideal for CPU/GPU hybrid inference: the sparsely activated experts can run efficiently on CPUs with large memory capacity, while the dense and compute-intensive components — attention and shared experts — execute on GPUs with higher bandwidth and throughput.This hybrid design allows trillion-parameter models to be deployed on a single machine with limited GPU memory, enabling local inference for research and private applications.
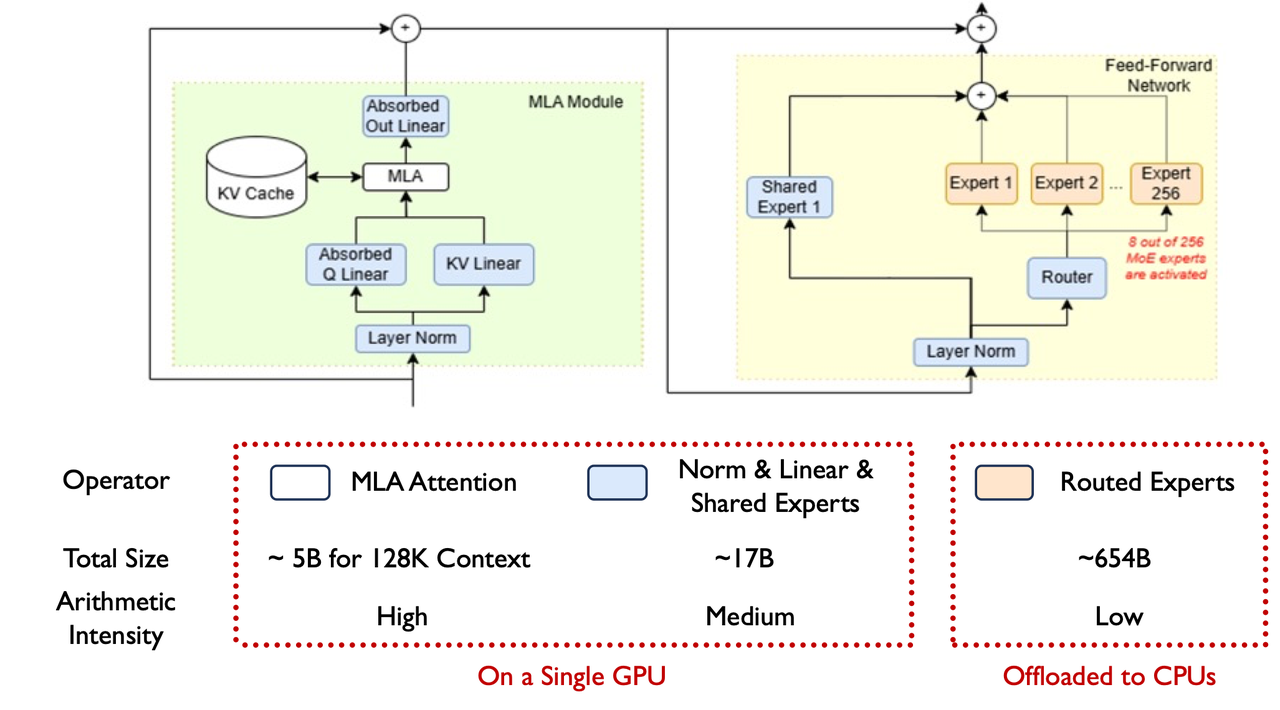
This hybrid design allows trillion-parameter models to be deployed on a single machine with limited GPU memory, enabling local inference for research and private applications.
Yet, fully exploiting both CPUs and GPUs remains challenging due to coordination overheads and underutilized compute, which limit effective throughput.
KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models
To solve the above problem, MadSys @ Tsinghua and Approaching.AI created the KTransformers project, presented at SOSP’25, introduces a collection of optimizations that make CPU/GPU collaboration for MoE inference far more efficient.
Its improvements fall into three main categories:
1. AMX-Specialized CPU Kernels
KTransformers redesigns CPU computation with Intel AMX–optimized kernels and a tiling-aware memory layout that aligns weight storage with cache hierarchies. It also supports dynamic switching between AMX (for high-intensity prefill workloads) and AVX-512 (for lightweight decode). On a single Xeon socket, the AMX-optimized kernels can reach up to 21.3 TFLOPS of sustained throughput — 3.9× faster than PyTorch native implementations. This directly translates into substantially higher CPU-side expert throughput during prefill and overall token throughput in hybrid runs.
2. Efficient Device Coordination
To reduce coordination costs between CPUs and GPUs, KTransformers introduces NUMA-aware tensor parallelism and CUDA Graph–backed scheduling.
NUMA-aware tensor parallelism places expert weight slices in the local memory of each NUMA node so that compute is mostly local, avoiding expensive cross-NUMA memory traffic; this yields up to 63% decoding throughput improvement on dual-socket servers.
CUDA Graph integration captures the hybrid CPU/GPU execution as continuous graphs. To make captures robust, KTransformers uses asynchronous task scheduling so that CPU tasks and data transfers do not create “breakpoints” in the captured graph. Capturing the workload this way reduces GPU kernel-launch overhead from over 20% to nearly zero.
Together, these optimizations ensure both devices operate with minimal synchronization delays.
3. Expert Deferral: Overlapping Model Execution
KTransformers further introduces an Expert Deferral mechanism that reorders expert execution across layers. Some experts are deferred to later stages, allowing CPU expert computation to overlap with GPU attention processing.
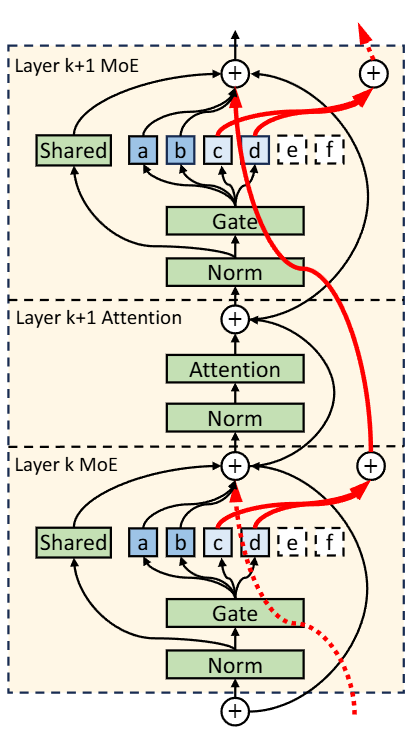
Because modern Transformers use residual connections, they are inherently tolerant of small delays to intermediate computations. Consequently, deferring certain expert computations enhances scheduling flexibility at the cost of only slight changes in model behavior.
This mechanism increases concurrent utilization of both devices and yields up to 1.45× higher decoding throughput, with accuracy variation below 0.5%.
Integrating KTransformers into SGLang
SGLang now integrates KTransformers as a backend library to enable efficient CPU/GPU hybrid inference, combining GPU Tensor Parallelism with CPU/GPU Hybrid Expert Parallelism for MoE models. This integration supports inference across heterogeneous devices, where KTransformers provides highly optimized AMX-based CPU kernels that work seamlessly with GPU execution.
While KTransformers focuses on single-GPU setups and high-efficiency CPU cooperation, SGLang excels at scaling across multiple GPUs, which is particularly advantageous in high-concurrency scenarios. In the hybrid setting, multiple GPUs can handle larger request contexts and perform fast attention computation, while experts are intelligently scheduled across CPUs and GPUs—storing frequently used (“hot”) experts on GPUs to alleviate CPU compute and bandwidth pressure.
With this joint design, users across diverse hardware configurations can fully utilize available resources, achieving better throughput, scalability, and cost efficiency.
We have already developed a proof-of-concept implementation, and the roadmap for full integration into SGLang is underway.
Benchmark Results (Preview)
Single-GPU + CPU Performance
Native KTransformers conducted detailed performance evaluations on a single-GPU + CPU setup. Under the same configuration, SGLang integrated with KTransformers achieves comparable performance to native KTransformers.
The evaluations are set on a dual-socket Intel® Xeon® Platinum 8452Y server (36 cores × 2, 1 TB DDR5 × 2) with an NVIDIA A100 (40 GB) for full-precision models and an RTX 4080 (16 GB) for quantized models.
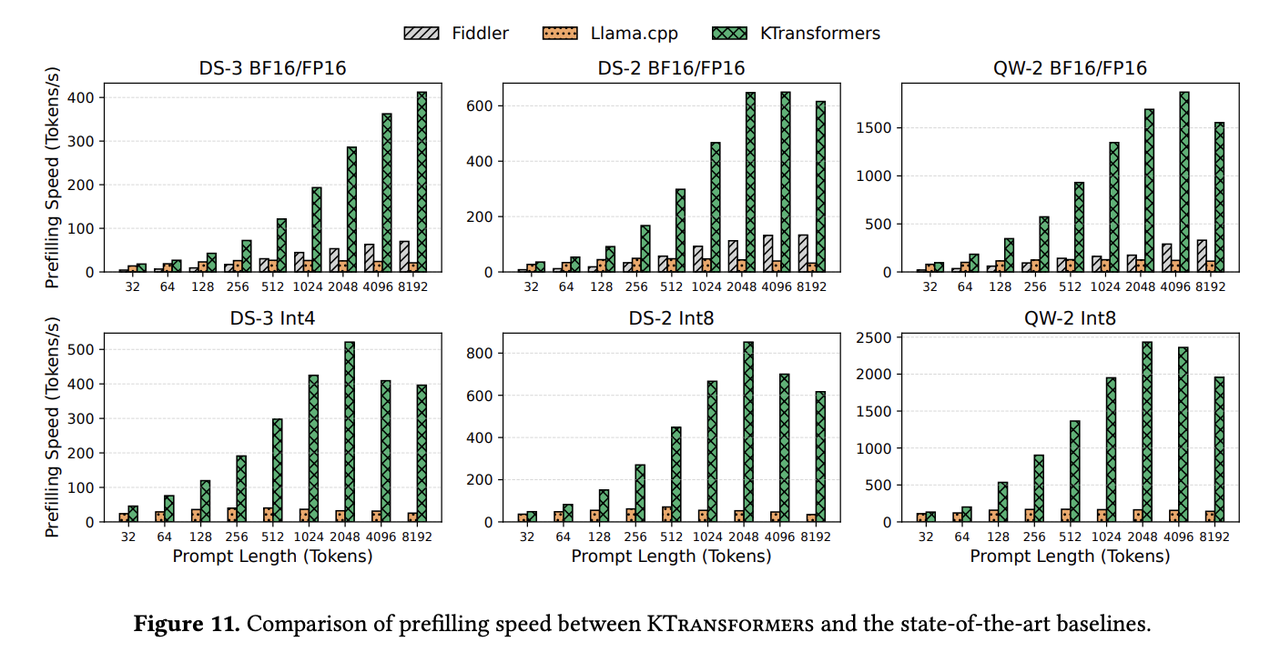
In the prefill phase, KTransformers consistently outperforms both baselines across all prompt lengths, benefiting from AMX-optimized CPU kernels and achieving speedups of up to 20×.
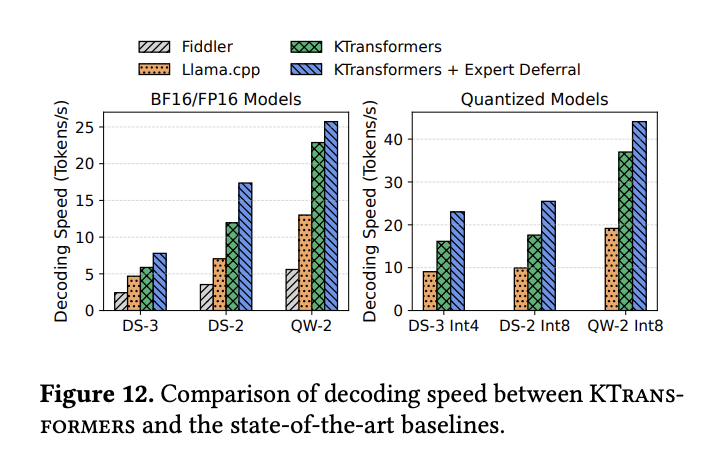
In the decode phase, KTransformers also outperforms both baselines, with gains mainly attributed to reduced CPU/GPU coordination overhead, reaching up to 4× speedup.
Multi-GPU + CPU Performance
We further evaluate the multi-GPU + CPU hybrid inference capability enabled by integrating KTransformers into SGLang. Specifically, we tested int4-quantized DeepSeek-V3 on a system equipped with 8× L20 GPUs and dual-socket Intel Xeon Gold 6454S CPUs, using workloads with an average input length of 128 tokens and output length of 512 tokens.
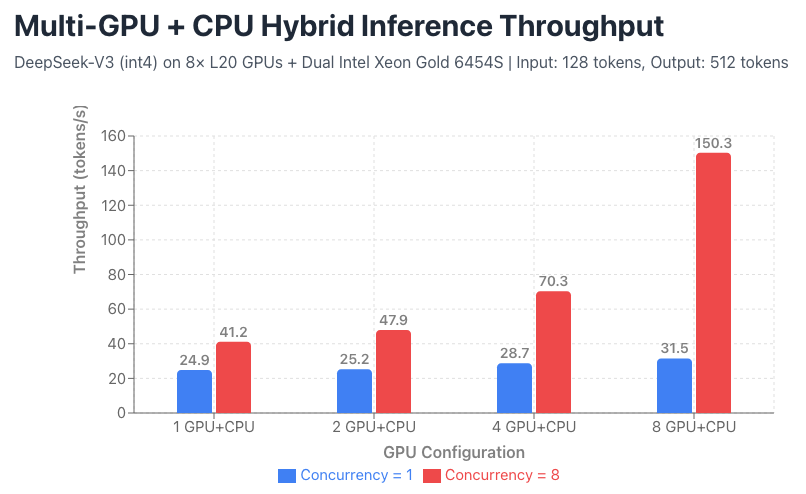
The table above presents the total throughput (tokens/s) under different levels of concurrency and varying numbers of GPUs. As shown, under single-concurrency conditions, the 8-GPU configuration provides only a limited improvement over the 1-GPU setup (an increase of merely 26%). However, under 8-way concurrency, the same 8-GPU configuration achieves a 264% throughput gain compared to 1 GPU, demonstrating excellent usability—each request achieves nearly 20 tokens per second on average. The improvement mainly comes from placing more experts on GPUs, which reduces CPU memory accesses under bandwidth bottlenecks.
Acknowledgements
We would like to thank everyone in the community that helped make this effort possible.
KVCache.AI team: Boxin Zhang, Jianwei Dong, Hongtao Chen, Weiyu Xie, Shaoyuan Chen, Chen Lin, Chengyu Qiu, Yuening Zhu, Jingqi Tang, Qingliang Ou, Yongwei Wu and Mingxing Zhang from MadSys @ Tsinghua University.
Approaching AI: Jiahao Wang, Ziwei Yuan, Yaochen Han, Jiaqi Liao, Xianglin Chen, Zhiyuan Ai, Yongsen Hu, Zhuo Wang, Daocheng Ye, Yanlong Wu, Yufeng Tian, Heng Guo, Hao Wu, Zirui Li, Yingqi Tian, Yue Qin, Xin Qu, Baijin Hao, Donghui Liu.
SGLang team and community: Jingyi Chen, Shangming Cai, Lianmin Zheng, Yineng Zhang and many others for their insightful review comments on this PR and for their work on SGLang framework.
Related resources
Repo:https://github.com/kvcache-ai/ktransformers
SOSP25 Paper:https://madsys.cs.tsinghua.edu.cn/publication/ktransformers-unleashing-the-full-potential-of-cpu/gpu-hybrid-inference-for-moe-models/