
Branching lets developers spin up isolated environments that perfectly mirror production in a single click or API call. This is a major upgrade for developer experience: teams can skip the tedious work of keeping databases in sync and focus on shipping code.
But until now, there’s been one limitation. If your production data includes sensitive information, compliance and security rules often prevented you from creating dev or test branches directly. That changes today.
**When creating a branch in Neon, you can now select **…
Branching lets developers spin up isolated environments that perfectly mirror production in a single click or API call. This is a major upgrade for developer experience: teams can skip the tedious work of keeping databases in sync and focus on shipping code.
But until now, there’s been one limitation. If your production data includes sensitive information, compliance and security rules often prevented you from creating dev or test branches directly. That changes today.
**When creating a branch in Neon, you can now select Anonymized data: Neon will mask sensitive information according to rules you define, giving you realistic, production-shaped data without exposing PII. **When you’re done, simply delete the branch and move on. You can even automate the whole workflow with the Neon API or GitHub Actions.
All those dreadful environment maintenance tasks (manually managing separate staging databases, working with synthetic data, updating seed scripts) are becoming a thing of the past. **The future of developer experience is branching, and we’re gonna tell you why. **
To jump straight to the update on anonymized branches, click here.
**“Our testing process was very manual before Neon. Product would create a test customer in our development environment, the QA team would test and manually run through all the math, then an engineer would have to go into the database, look at all the values, and handwrite them into fixtures for our end-to-end tests… That’s multiple days for every single change” ** (Miguel Hernandez, Backend Tech Lead at Neo.Tax)
No matter how small or large, every engineering team needs non-production environments – places to test new features, run CI pipelines, reproduce bugs, or review schema changes before they reach production. These environments are supposed to behave like production, but maintaining that parity is one of the most annoying hardest ongoing operational tasks in software development.
Most teams start simple – copy the production database and scrub it. They run pg_dump, maybe write shell scripts to remove or redact sensitive data, and restore the dump into a staging instance. The hard reality is that production data changes often, especially as you’re shipping quickly or the business is growing. New tables, columns, and configs are added all the time, and the scripts quickly fall out of date.
We all know what happens when your environments fall out of sync with production (bugs undetected), so teams spend time trying to prevent this from happening. One option is automating this with nightly jobs or pipelines that recreate staging from production snapshots; you can also go the opposite way and maintain a seed dataset – a small, curated sample of data that’s “good enough” for testing, and do their best to refresh it often.
Both options are hardly anyone’s favorite to work on and they always introduce problems.
Staging data starts drifting from production almost immediately. New records, customer behaviors, or schema changes in production don’t make it into staging at the same pace. Within days, the shape and distribution of your data no longer match. Queries that perform fine in staging might time out in production because the row counts or index selectivity are different.
Database migrations are another failure point. A migration might be applied to production but not staging, or run in a different order, or use slightly different data. That inconsistency leads to subtle issues – columns missing in staging, default values that don’t match, foreign keys referencing outdated IDs. CI pipelines fail, tests pass for the wrong reasons.
When teams copy or scrub production data manually, they strip or anonymize columns independently. That breaks the relationships between tables in Postgres: foreign keys no longer align, there’s orphaned records and inconsistent IDs. It’s hard testing with this data and reproducing real user flows because the underlying relational context is gone. This is also one of the hardest issues to detect until something breaks downstream.
Synthetic or seeded datasets rarely reflect the scale and cardinality of real production workloads – they miss outlier values and the edge cases that stress indexes and constraints. Performance regressions, deadlocks, and memory issues stay hidden until production traffic hits. This causes fragile release confidence: your tests may go green but production starts breaking more than you wish.
“Our workload ingests hundreds of data points per second and our RDS costs were increasing, especially since we had multiple regions and environments. With Neon, we found a way to scale our setup more efficiently, using branching instead of duplicating instances and autoscaling to match our actual load”
(Thorsten Rieß, Software Architect at traconiq)
Maintaining separate environments isn’t just slow and annoying. It’s also expensive, both in engineering team time and in cloud costs.
- **Each staging or testing database consumes storage and compute continuously, even when idle. **Teams end up maintaining multiple long-lived managed Postgres clusters that serve no customer traffic but still end up costing hundreds or even thousands of dollars a month, especially as the setup bloats after a while.
- But the human cost is probably the largest one. Someone on the team becomes* the unofficial data janitor*, responsible for keeping all these environments usable even if they’re supposed to be a developer. This is a common pain in many smaller / leaner engineering teams, where there’s no designated DBA. Maintaining migration scripts, scrubbers, and seed files takes a lot of time.
Testing environments don’t catch bugs, development and staging environments rarely behave like production. Bugs that depend on real-world data distributions slip through, developers waste hours debugging issues that only exist because the data is different, companies end up with multiple always-on instances that are barely used, and developers end up spending more and more time on maintenance tasks that nobody saw coming.
This is a pattern that teams end up accepting as normal, but it doesn’t have to be.
One of the reasons we built Neon was to eliminate the grind described above. In 2025, developers shouldn’t be hand-curating test data – we deserve better. The way out is adding branching to databases, creating an experience similar to what we’re used to in Git. But this only works if branching is a storage-level primitive built into the database, not a scripted clone of an instance.
**“When we moved to Neon, we consolidated all our non-prod services into a single Neon project. We just load our synthetic dataset once into the main staging branch and spin off child branches as needed. With Aurora, the process was more complex. We had to duplicate databases per service, which meant loading data separately for each environment” ** (Cody Jenkins, Head of Engineering at Invenco)
Separation of compute and storage
In traditional Postgres setups, compute (the Postgres process) and storage (the data directory) live on the same machine. If we were to build any sort of environment-cloning feature this way, it would still be slow and expensive. Each would need its own VM, its own disk, its own lifecycle, etc.
But in Neon,the architecture is decoupled. Compute is stateless and ephemeral, running Postgres but holding no durable data. All persistent data lives in the storage layer, which is shared and distributed across the platform, and has a very particular design (as we’ll see now).
A decoupled compute and storage architecture eases the path towards cloning environments, but one still has to solve the problem of duplicating data very quickly. Neon built a custom storage layer for this, in which every write is captured as a stream of WAL records which are stored durably by a quorum of lightweight services called Safekeepers.
Safekeepers guarantee that once a transaction is acknowledged, it’s safely persisted, even if no compute is currently attached. They also record precise Log Sequence Numbers (LSNs), which act as version markers in the database’s history.
This is essential for branching. This makes it possible to say: “Create a new branch at LSN X” which is an exact point in time. That’s how Neon can spin up a new environment from any moment in production history, without needing a dump, restore, or snapshot job.
From there, the Pageserver reconstructs data pages from WAL and stores them as immutable layers in object storage. Branching uses copy-on-write semantics on those layers: the new branch references the same base data as its parent and only diverges when new writes occur.
For developers, this means every branch is space-efficient, created in seconds, and mirrors production exactly.
Because compute and storage are decoupled, each branch can attach its own temporary compute, a lightweight Postgres process that runs only when needed. When a branch is idle, its compute scales down to zero automatically while the storage layer remains intact. Spinning it back up is instant, since Postgres simply reattaches to the branch’s timeline.
In practice, this keeps workflows lean. Teams can create hundreds of short-lived branches (e.g. one per developer, test run, CI job) without paying for hundreds of always-on instances. The database behaves the way infrastructure should: on when you need it, gone when you don’t.
**Together, these architectural components make Neon branching an actual substitute for manually deploying and maintaining separate non-prod instances. **Neon branches can be used as your environments, and they all can be understood as ephemeral – you create them right when needed, you do whatever you need to do, you delete them / resync them with production after.
Let’s go through a few workflow examples that thousands of developers are already using every day.
Developers need their own isolated environment that mirrors production, and these often need to live in the same cloud environment due to security and compliance reasons. Instead of maintaining long-lived dev instances and populating them manually, a developer on Neon can spin up a new branch from production in seconds. The branch has its own compute, independent from prod, and perfectly mirrors its schema and data. You can run migrations, test queries, seed data, and when you’re done, delete or resync the branch with production.
**“We’re a small team, but we’re scaling quickly and doing a lot. We’re shipping multiple times a day – to do that, we need to test stuff quickly and merge to main very quickly as well. Neon branches are a game changer for this” ** (Avi Romanoff, Founder at Magic Circle)
When deploying previews on platforms like Vercel, every feature branch can automatically get its own Neon branch. During build, a new database branch is created from production and linked to that preview deployment, with the same production schema and data, giving every preview app a realistic backend for QA and design review. When the PR closes, both the preview and the database branch are deleted automatically.
**“Branching with scale to zero makes our lives markedly easier. We’re able to use real data without risky scripts touching production, and we don’t pay overnight for what we don’t use” ** (Ryan McHenry, Head of Technology, Sharing Excess)
Ephemeral testing and CI environments
Ephemeral environments are short-lived copies of your system and are ideal for CI pipelines and automated testing, but databases have traditionally been a friction point. With branching, each test run can automatically create a temporary branch from production, execute all tests against it, and delete it afterward. Because branches are copy-on-write and compute scales to zero when idle, you get instant, isolated test databases that cost virtually nothing when not in use – and GitHub Actions and the Neon API make it easy to automate.
**“Anytime we need to test a new feature or extension, we branch off from production, run our checks, and reconnect when we’re ready. It’s simple, safe, and saves us huge amounts of time” ** (Ahsan Nabi Dar, CTO and co-founder of DAT)
Staging is where most teams try to get close to production but it’s also where data drift and compliance risks creep in. With Neon, you can create a long-lived staging branch derived directly from production and refresh it as often as you need. This ensures schema and data parity without complex sync jobs or downtime.
*“Branching lets us test big migrations safely with production data, and if something breaks, we just delete the branch and start fresh. That makes us a lot faster and more confident when shipping, even as a small team” * ** (Dominik Koch, CEO and Co-Founder of Marble)
Some teams use real data in staging for full-fidelity testing, but others need anonymized data for compliance. Neon now supports both:
Adopting the branching workflows above could get tricky for teams handling sensitive data in prod – things like names, emails, addresses, payment details. That changes with our recent release of anonymized branches.
When you create a new Neon branch, you can now choose “Anonymized data” as the data option:
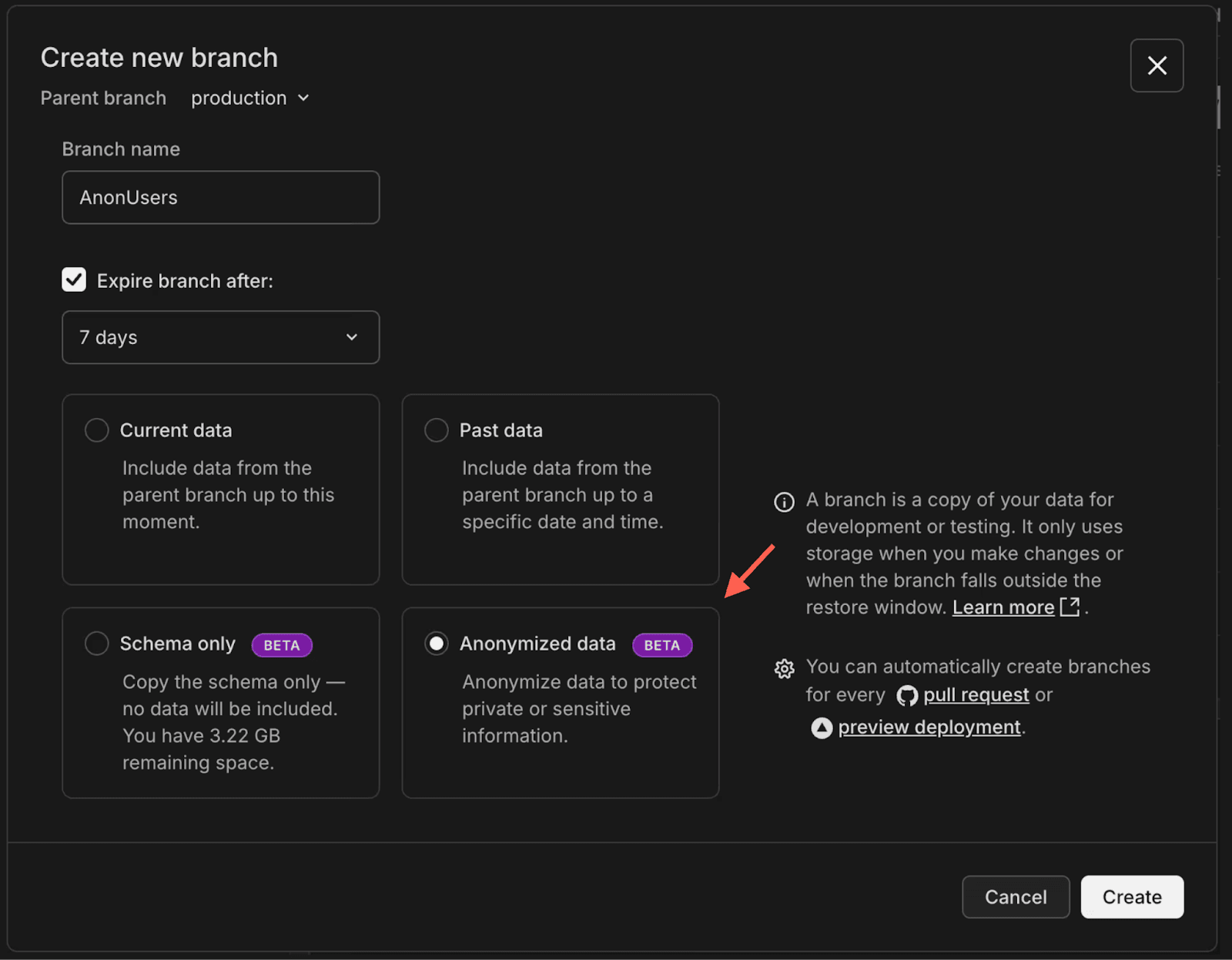
Neon copies your schema and data from the parent branch (e.g. prod) and immediately applies masking rules using the PostgreSQL Anonymizer extension. The anonymization process is all handled by the platform: all you have to do is wait until the masking is done. This will be fast for tables with small PII columns, and it might take longer if you have a lot of PII to mask.
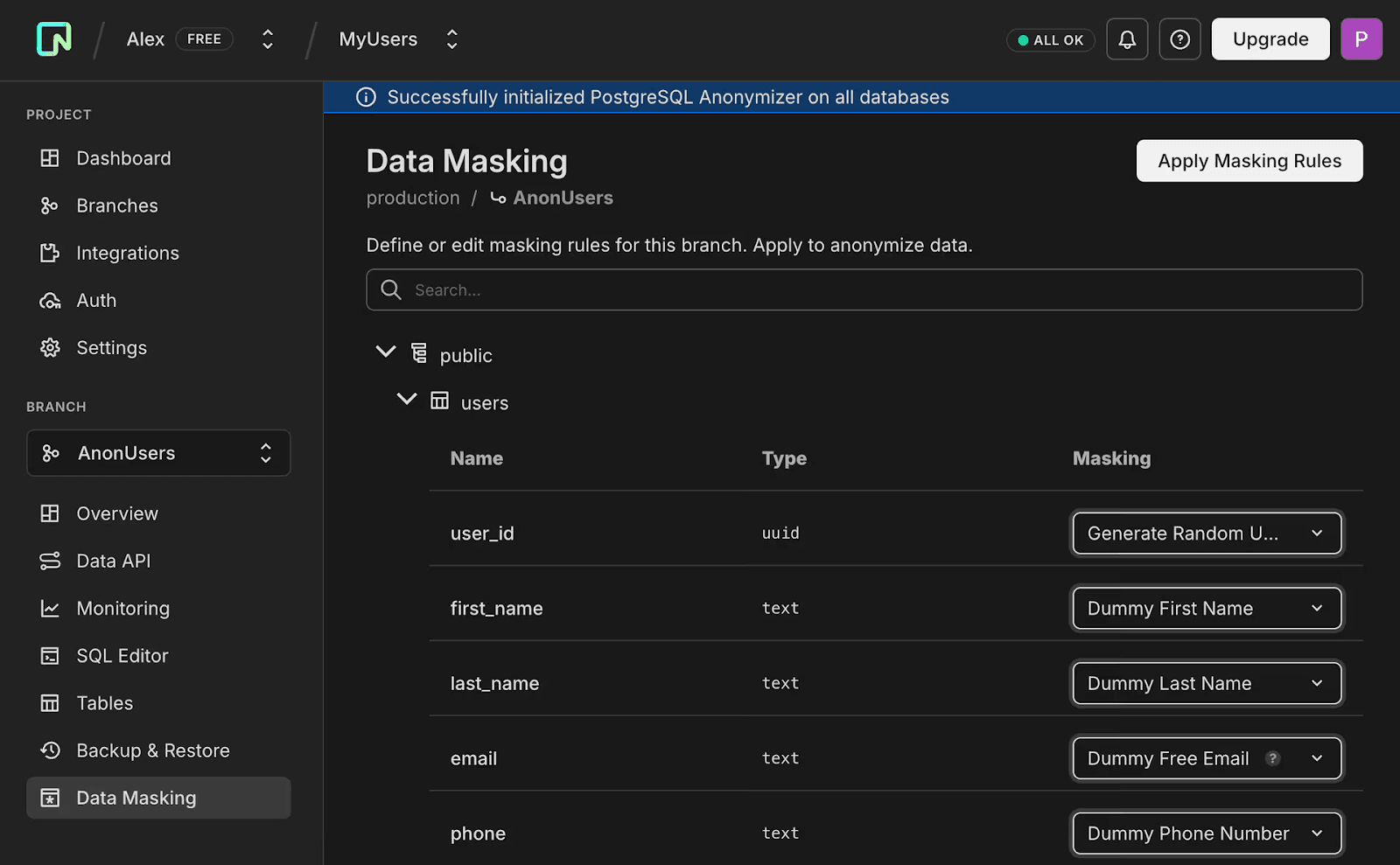
Regardless of if you have few or lots of PII,** this gives you a database branch that behaves completely like production but holds no sensitive information.** Fields such as names, emails, phone numbers, and addresses are replaced with safe, dummy equivalents, keeping foreign key relationships and constraints intact. You can pick exactly the masking rule you want to apply to each column, e.g.
- Dummy Free Email – replaces email addresses with realistic dummy addresses.
- Dummy Last Name generates random but plausible names.
- Dummy Phone Number – substitutes phone numbers with valid, formatted dummies.
- Generate Random Value – randomizes numeric values such as age or salary
**Of course, you can also define masking rules programmatically via the API. **Each branch can have its own rules, so you can anonymize them differently for different use cases, e.g. for dev or demos, and you can automate all of this.
This first beta version of anonymized branches uses static masking, meaning that:
- Masking runs once when the anonymized branch is created (or when you rerun anonymization)
- Parent data stays untouched. All masking happens in the new branch
- Anonymization rules are branch-specific
**Since we’re doing static masking by now, there’s storage costs implications to anonymizing data. **The masked columns will generate a storage delta that will add to your overall project storage bill; how large this delta will be depends on how much data you anonymize. If you’re masking a few small columns, the increase is minimal; if you’re masking many or large columns, it will be higher. Keep this in mind when estimating your storage usage.
Future plans
It’s important to us to stick to our copy-on-write philosophy even with data anonymized, so we’re already working on the next version of anonymized branches** **which will use dynamic masking. After this update, we will apply masking at query time, rather than storing transformed copies - which will mean no additional storage created and no additional costs for you. Stay tuned.
With the launch of anonymized branches, we’ve removed one of the last blockers to fully adopt branching workflows. Combined with Neon’s existing branching and scale-to-zero capabilities, this unlocks a complete workflow that frees developers from the old grind of maintaining environments, allowing them to focus their time and budget on more important things.
production → anonymized staging → anonymized dev/test/preview branches → delete branch
You can explore anonymized branches in Neon today. Full setup steps, API examples, and masking function references are availablein our docs. If you’re new to branching workflows altogether, explore our guide.