- 31 Oct, 2025 *
With vibecoding I naturally tried making my own dream app. It was massive failure because asking claude code to make frontend-backend code looks really nice until you look into the details and find some bug and spend hours begging claude to fix it. It would be probably faster to write it from scratch after carefully designing, but vibe coding is definitely addictive and exciting when it works (e.g. when it steals from existing code instead of trying to write new code).
I did not make a functioning product, but I did get to explore concepts that will maybe one day help me write my dream app.
The purpose is to write a web-app where I can write notes every day and also query and process them. It should handle structured and raw data. It should import my DayOne jo…
- 31 Oct, 2025 *
With vibecoding I naturally tried making my own dream app. It was massive failure because asking claude code to make frontend-backend code looks really nice until you look into the details and find some bug and spend hours begging claude to fix it. It would be probably faster to write it from scratch after carefully designing, but vibe coding is definitely addictive and exciting when it works (e.g. when it steals from existing code instead of trying to write new code).
I did not make a functioning product, but I did get to explore concepts that will maybe one day help me write my dream app.
The purpose is to write a web-app where I can write notes every day and also query and process them. It should handle structured and raw data. It should import my DayOne journal with 2000 entries and allow me to process it from within the system. I was mostly inspired by jupyter notebooks and elixir livebooks that have code snippets and text snippets. Those systems have markdown text as comments for the code like in literate programming. I wanted text blocks to be first class citizens with python code.
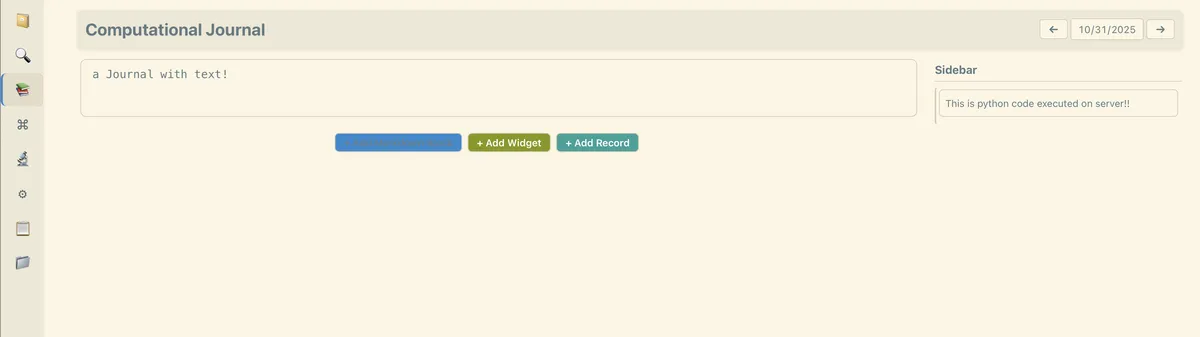
Python
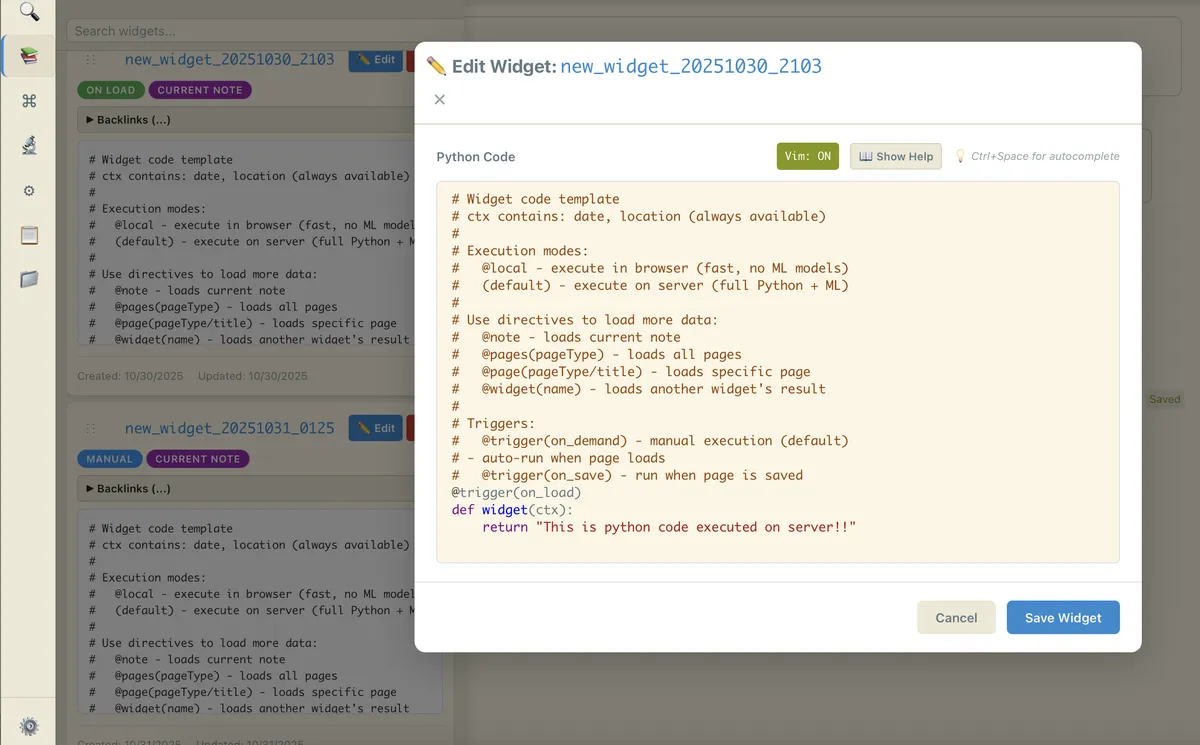
I wanted my app to run user provided python code just like in jupyter notebooks. Since it was arbitrary code, this would never be safe to multi host and it was explicitly meant to be a selfhosted, single user solution for yolo people. It was pretty neat (frontend sends python string to backend, which calls exec(). I even had directives that modify the input into the python code. (It is parsed on server, which executes a sql query to collect the requested data).
so if I had a widget with a @note and @trigger(on_demand) directive, the backend would load all blocks from the current note, store it in ctx object and call the widget function on it. It would also not execute it until user pressed run on the frontend.
It even had a codemirror editor and LSP as a light weight jupyter notebook! I felt this is nicer than implicit ordering of code snippets, since the directives setup the input to the cell.
Malleability vs extensibility
I wanted to make a journal that can be extended from within itself instead of downloading and installing some plugins. I really wanted users to be able to modify it in the environment. The best example would be silverbullet, tiddlywiki and maybe glamorous toolkit (which isn’t usable otherwise, but is a excellent example of malleability). In my experiment I failed, because I had frontend and backend and it was too difficult to modify it. I had executable python code that would be sent to the backend, and I had drag and drop sidebar and header to display dynamic content, but I kept having to modify the system to accommodate new use cases, defeating the purpose.
For example, I can make widgets that output data or html snippets which I can show on the frontend, but when I want to make them interactive and spawn new blocks it becomes an instant refactor.
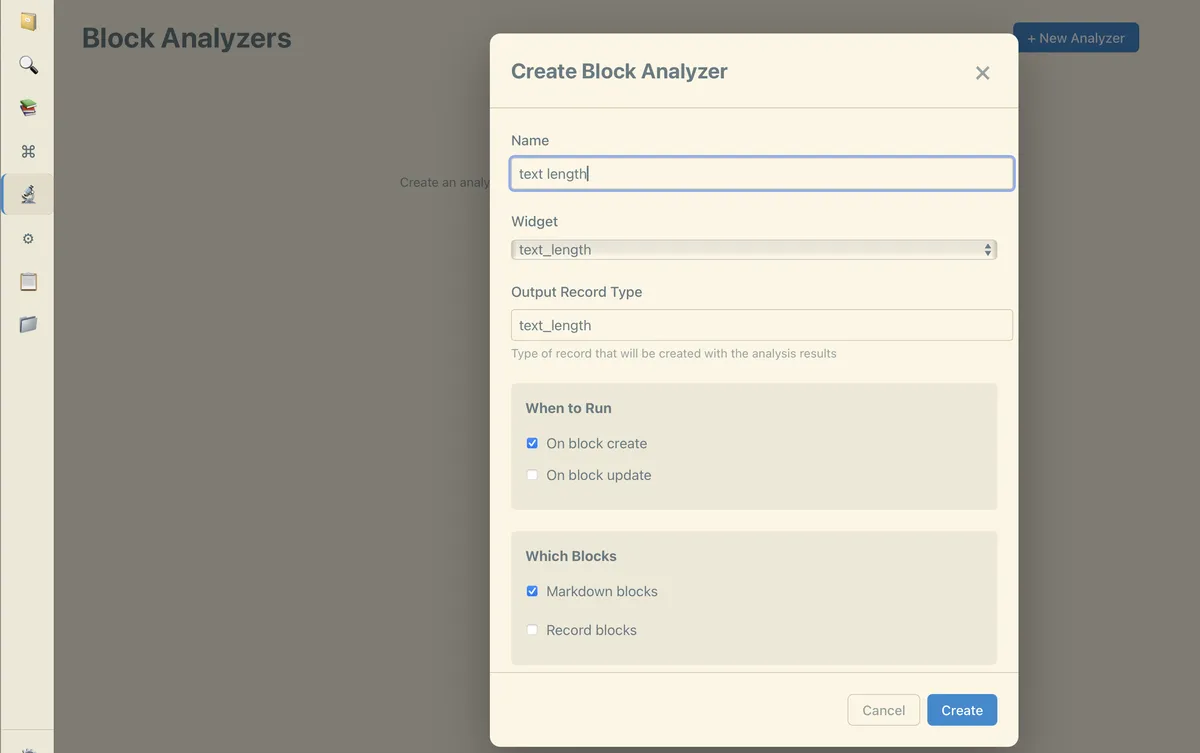
I even introduced a block analyzer, where I can schedule python widgets to be run on ALL blocks and output records (json blocks) as children


Nesting
One thing I really enjoyed conceptually (and actually) is nesting blocks into each other. When I nest a json block into a markdown block it becomes instant metadata. If I drag and drop a python block into a markdown block, it gains access to the raw text data. If I nest a markdown block into a python block, it becomes a comment! 
I found this really elegant and a bit playful when drag and dropping notes into each other and figuring out what they do. It had lots of edge cases and failures (what if I drag a block that has a nested block, into another block? What if I delete the middle note?) but as a concept it was fairly interesting and I think fairly intuitive. It is of course stealing from outliners, inspired by Tana and logseq.

Tagging and aggregation
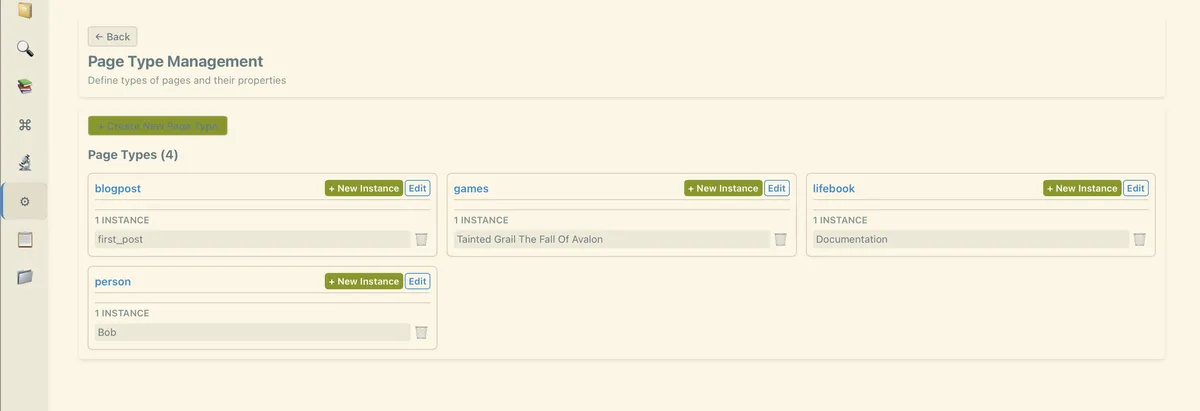
An important aspect is to be able to tag a block, and later aggregate the blocks with same tag. Then I felt I need metadata for the tags (Tana supertags), such as birthdays for person tags. This lead to making additional tables with pages and page schemas just to make sense of it. It was a blurry concept and unclear what is difference between the page and daily note. Adding properties to page was a modeling mightmare and probably a mistake. It was nice to browse all pages but there were issues with autocomplete and it was not clear if I should open a page and add note there, or add note in daily view and link a page.

When premature optimization becomes the whole purpose
Since I vibe coded the database schema (even switching between postgres and sqlite midway) it became incredibly large, and I kept discovering inefficient loops and fought complexity. I probably spent more time fighting claude to make a good (==efficient) data model than actually writing anything in the app. I was really obsessed with efficiency and “doing things once”. I did not want to use markdown because I don’t want to read files every time. I wanted to keep json objects in a database because I don’t want to parse the raw text every time, I don’t like frontmatter. But this chase turned out to be all consuming and honestly all markdown is probably sufficient for remainder of my life given my 4nm CPU macbook. I still think there is some good schema to be used. Maybe notion-all-is-block?
Ingest the universe
I liked exposing APIs to insert blocks from anywhere. I feel for markdown you need to append to the end. With a REST api I can use any interface to add data to my system, and even write data convertors from existing content (thanks obsidian!) I think there could be a intelligence layer in this ingestion that maps it to format that exists in the system. I want to explore that further.
Not a god damn chatbot
I did not include any LLM integrations. I was planning to use structured extraction and play with the concept a bit, but I did not feel the app needs LLM chat window inside. I did want to expose an MCP to use within claude app though. I feel a lot of note taking apps should do that approach instead of having their own (even though it kills profitability). Local LLM with OLLAMA have awful performance and I would rather use a big model.