NovaEval Evaluation Framework
73+ built-in metrics. Automated scoring. Continuous quality assurance. Know your agents are production-ready.
Traditional metrics like accuracy are insufficient for AI agents. You need a multi-dimensional approach that measures accuracy, safety, cost-efficiency, and more. Noveum.ai’s NovaEval engine provides everything you need to evaluate agents comprehensively and continuously.
73+ pre-built evaluation metrics
Automated evaluation pipelines
LLM-as-Judge for subjective qualities
Continuous quality monitoring
Built-in Metrics
73+
The Challenge
Why Evaluating AI Agents is Hard
Evaluating A…
NovaEval Evaluation Framework
73+ built-in metrics. Automated scoring. Continuous quality assurance. Know your agents are production-ready.
Traditional metrics like accuracy are insufficient for AI agents. You need a multi-dimensional approach that measures accuracy, safety, cost-efficiency, and more. Noveum.ai’s NovaEval engine provides everything you need to evaluate agents comprehensively and continuously.
73+ pre-built evaluation metrics
Automated evaluation pipelines
LLM-as-Judge for subjective qualities
Continuous quality monitoring
Built-in Metrics
73+
The Challenge
Why Evaluating AI Agents is Hard
Evaluating AI agents is fundamentally different from evaluating traditional software or ML models. Agents are non-deterministic, complex, and often produce novel outputs that don’t match any pre-defined ‘correct’ answer.
AI agents can take hundreds of steps per execution. Even running 10 times a day generates 1000+ traces and spans. It’s impossible for humans to manually review all this data - you’ll miss 90% of errors. This is the biggest hindrance to scaling AI agents. You need automated evaluation that pinpoints exact error locations with reasoning.
1000+Traces/Day at Scale
Beyond Accuracy
Traditional accuracy is a poor measure for AI agents. An agent might produce an answer that’s not in your training set but is still correct, or a technically accurate answer that’s not helpful.
The Hallucination Problem
AI agents can confidently produce false information (hallucinations). You need specific metrics to detect and measure hallucinations, not just overall accuracy.
Safety & Compliance
You need to ensure agents don’t produce toxic, biased, or non-compliant outputs. This requires specialized evaluation metrics for safety, bias detection, and regulatory compliance.
Cost-Quality Trade-offs
You need to balance quality with cost. A more expensive model might produce better results, but is the improvement worth the extra cost? You need metrics to measure this trade-off.
Eval Makes Observability Actionable
NovaEval doesn’t just show you data - it pinpoints the exact traces where errors occur, identifies what went wrong, and provides reasoning for every issue. This is what transforms raw observability into actionable intelligence.
90%of Errors Caught Automatically
The NovaEval Solution
NovaEval: Comprehensive Agent Evaluation
NovaEval is Noveum.ai’s powerful evaluation engine, designed specifically for AI agents. It provides 73+ pre-built metrics, custom metric creation, and automated evaluation pipelines.
73+ Pre-Built Metrics
Evaluate every dimension of agent quality with our comprehensive metric library
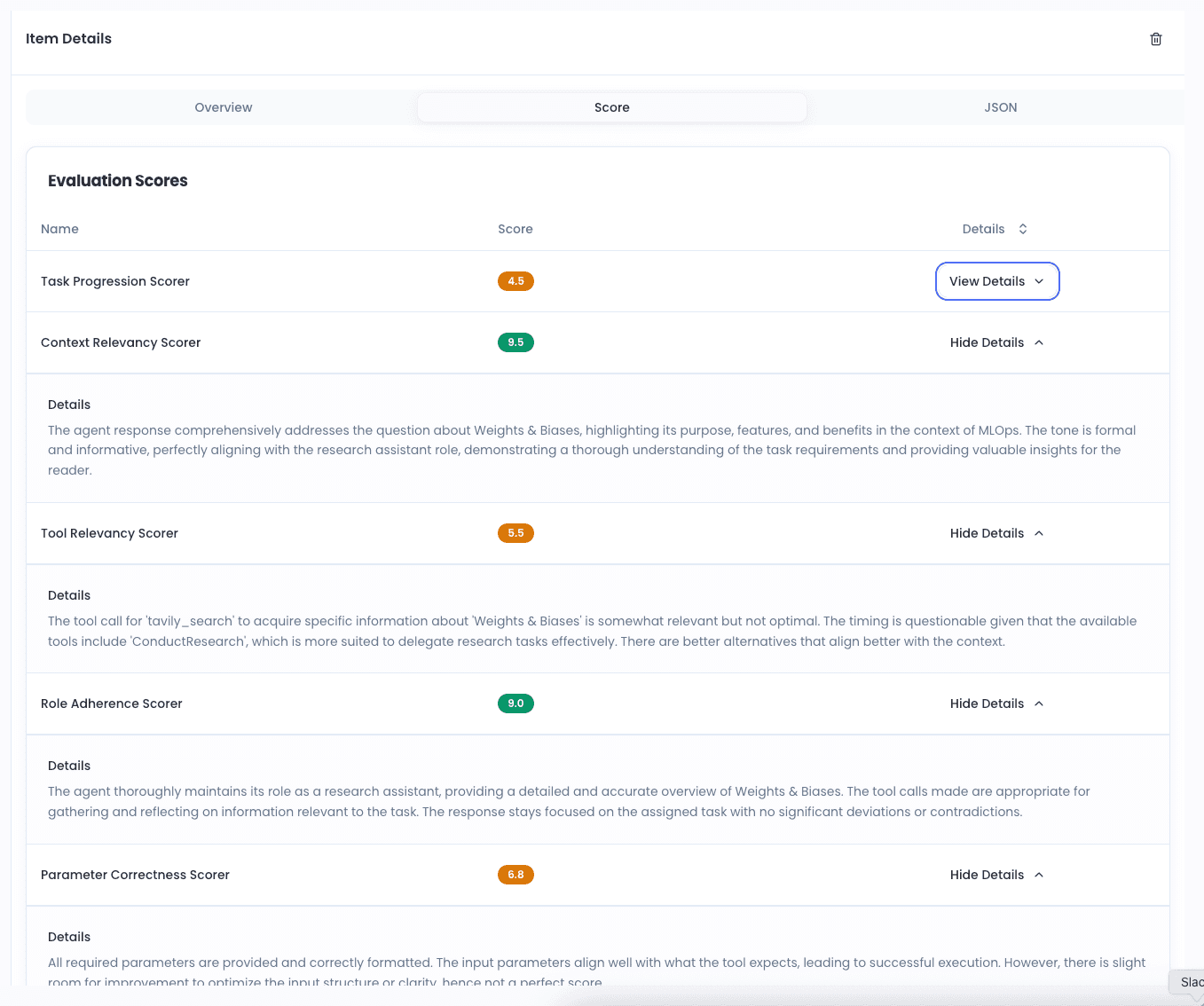
Agent Scorers
- Tool Relevancy Scorer
- Task Progression Scorer
- Goal Achievement Scorer
- Role Adherence Scorer
Conversational
- Coherence Scorer
- Empathy Scorer
- User Satisfaction Scorer
- Persona Adherence Scorer
RAG Quality
- Faithfulness Scorer
- Context Relevancy Scorer
- Answer Correctness Scorer
- Context Recall Scorer
Safety & Bias
- Toxicity Detection Scorer
- Bias Detection Scorer
- PII Detection Scorer
- Response Safety Scorer
Hallucination Detection
- Factual Accuracy Scorer
- Claim Verification Scorer
- Groundedness Scorer
- Context Faithfulness Scorer
Advanced Quality
- Information Density Scorer
- Clarity & Coherence Scorer
- Technical Accuracy Scorer
- Citation Quality Scorer
Key Benefits
Why Teams Choose NovaEval
NovaEval provides comprehensive agent evaluation that goes beyond traditional testing.
Comprehensive Quality Assurance
Evaluate agents across all dimensions of quality, not just accuracy. Ensure agents are safe, compliant, cost-effective, and performant.
Faster Quality Gates
Set up automated quality gates that ensure agents meet your standards before deployment. Catch regressions early and prevent bad code from reaching production.
Data-Driven Decision Making
Use evaluation data to make informed decisions about model selection, prompt optimization, and tool improvements. Move from guessing to knowing.
Continuous Improvement
Use production data to create evaluation datasets and continuously improve your agents. Identify failure patterns and create test cases to prevent regressions.
Regulatory Compliance
Demonstrate to regulators and auditors that your agents are evaluated, monitored, and compliant with regulations. Use evaluation reports as evidence of responsible AI practices.
Stop Guessing, Start Knowing
With NovaEval, you don’t have to wonder if your agents are production-ready. You know for certain, backed by comprehensive metrics and continuous evaluation.
Getting Started
How NovaEval Works
Get started with comprehensive agent evaluation in four simple steps.
01
Automatic Dataset Creation
Datasets are automatically created from your production traces using AI-powered ETL jobs. No manual data collection needed.
02
Select Scorers
Choose from 73+ scorers to enable, or let NovaPilot recommend the best scorers for your use case automatically.
03
Setup Eval Jobs
Configure evaluation jobs to run daily, weekly, or on certain thresholds. Set up continuous quality monitoring.
04
Get Detailed Reports
Receive comprehensive reports from NovaPilot with identified problems, recommended fixes, and actionable insights.
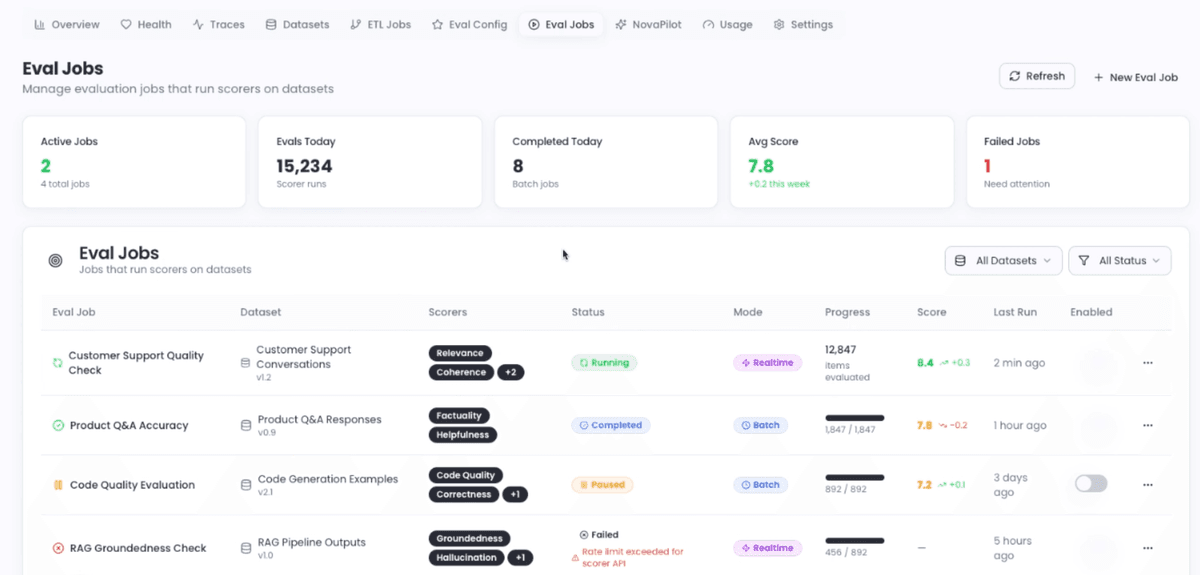
Evaluation Workflow
The NovaEval workflow is designed for both one-time evaluation and continuous monitoring. Here’s what happens when you run an evaluation:
- 1Traces are processed and datasets created automatically
- 2NovaPilot recommends or you select scorers
- 3Eval jobs run on your configured schedule
- 4NovaPilot delivers detailed reports with fixes
Real-World Applications
How Teams Use NovaEval
See how organizations use NovaEval to ensure agent quality in production.
Complete Solution
Part of the Noveum.ai Ecosystem
NovaEval integrates seamlessly with tracing and AutoFix for a complete observability and improvement loop.
The Continuous Improvement Loop
Trace
Capture behavior
Evaluate
Measure quality
AutoFix
Get recommendations
Improve
Apply & repeat
Traces capture agent behavior, evaluation measures quality, AutoFix analyzes failures and recommends improvements. Apply fixes and repeat.
Why NovaEval Stands Out
vs. Braintrust
Braintrust is evaluation-focused only.
NovaEval integrates evaluation with tracing and AutoFix for complete observability.
vs. DeepEval
DeepEval is an open-source library requiring self-management.
NovaEval is a managed platform with 73+ metrics and automated pipelines.
vs. Custom Solutions
Building custom evaluation is time-consuming and error-prone.
NovaEval provides battle-tested, pre-built metrics that work out of the box.
Start Evaluating Your Agents Today
Stop guessing about agent quality. Know for sure. Start evaluating with NovaEval and ensure your agents are production-ready.
14-day free trial
No credit card required
73+ evaluation metrics
Explore more solutions