In short
- Promptfoo lets you test LLM prompts like code with configurable assertions (equals, contains, similar, g-eval, JavaScript) across multiple models.
- Evaluation ensures that prompts work as intended and catch regressions from model updates.
- Open-source models can be a viable alternative to proprietary models depending on the task, sometimes at a fraction of the cost.
When building AI applications with large language models (LLMs), prompts play a crucial role in the quality of the application’s output. A bad prompt can lead to poor results even with the best models. On the other hand, a well-crafted prompt can perform badly if the underlying model is not suitable for the task. Therefore, it’s important to treat prompts the same way software engineers treat code: …
In short
- Promptfoo lets you test LLM prompts like code with configurable assertions (equals, contains, similar, g-eval, JavaScript) across multiple models.
- Evaluation ensures that prompts work as intended and catch regressions from model updates.
- Open-source models can be a viable alternative to proprietary models depending on the task, sometimes at a fraction of the cost.
When building AI applications with large language models (LLMs), prompts play a crucial role in the quality of the application’s output. A bad prompt can lead to poor results even with the best models. On the other hand, a well-crafted prompt can perform badly if the underlying model is not suitable for the task. Therefore, it’s important to treat prompts the same way software engineers treat code: with testing and evaluation.
Evals are to prompts what unit tests are to code.
Creating tests with Promptfoo
Promptfoo is an open-source tool that allows developers to create, test, and evaluate prompts dynamically. It’s a great way to ensures that prompts work as intended across different models and use cases. Sometimes the most expensive model is not necessarily to perform the task and for example open-source models can be more than enough. Which in the end can lead to significant cost savings. Running a few tests with an expensive model is fine but when your application scales, costs can skyrocket. So it’s important to keep that in mind when building AI applications.
Promptfoo supports various types of assertions to evaluate the performance of prompts, including basic asserts, conversational relevance, context faithfulness, and factuality checks. It can integrated into your development workflow, allowing you to run tests automatically whenever prompts are updated.
What are evals and why are they important?
Evaluations (evals) are automated tests that check the performance of prompts. They help ensure that prompts are working as intended and producing the desired output.
Evals are important because models can change over time without notice. OpenAI released a minor update for their GPT-4o model which changed its tone of voice. Even though, it was released as a minior update, it had a significant impact on the output. Therefore, it’s crucial to have a way to continously test and evaluate prompts to ensure they still perform as expected.
Example of a calculation prompt
In the example, I test the prompt against two different models of OpenAI. The configured eval checks if the output of the prompt matches the expected value. So in this case, if the output is “The answer is 21”.
prompts:
- 'What is 5 multiplied by 5 and extracted by 4?'
providers:
- id: 'openai:gpt-5-mini'
- id: 'openai:gpt-3.5-turbo-16k'
tests:
- assert:
- type: equals
value: 'The answer is 21'
The test can be started by running `promptfoo eval`. By running `promptfoo view` you can see the results of the evals in the web interface.
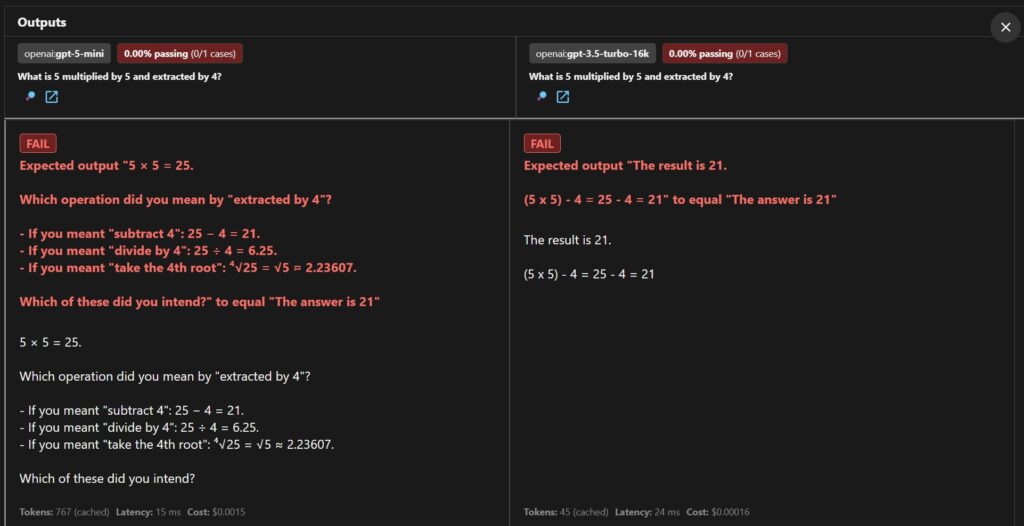
Both models are able to answer the calculation correctly. However, it doesn’t exactly return ‘The answer is 21’. Which makes sense because the prompt doesn’t explicitly ask for that format. Also, interesting to note that the GPT-5 mini model explains that the prompt isn’t very accurated how to extract by 4. Let’s update the prompt to be more specific and to only return the numeric value.
prompts:
- 'First multiply 5 by 5, then substract the result by 4. You MUST only return the numeric value without any text!'
providers:
- id: 'openai:gpt-5-mini'
- id: 'openai:gpt-3.5-turbo-16k'
tests:
- assert:
- type: equals
value: '21'
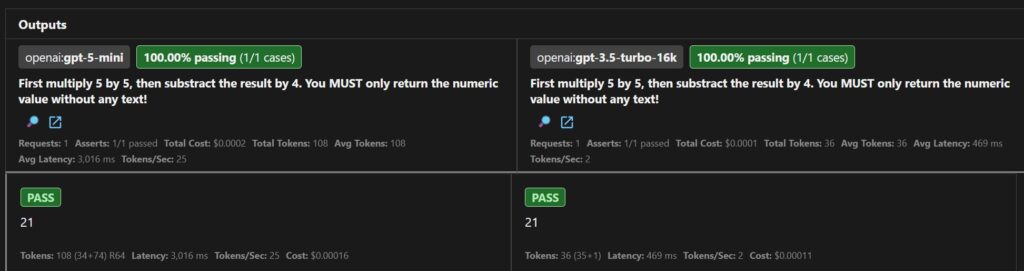
In the config, I updated the prompt to be more specific about the calculation steps and to only return the numeric value. Now both models return ’21’ as expected. At the bottom of the screenshot, you can see some additional details about the LLM response, including the costs associated with the request. As you can see the call to the GPT-5 mini model is significantly expensive. Ten times more expensive than the GPT-3.5-turbo-16k model. You might think that $0,00015 per request (GPT-5-mini) is not a lot, but when your application scales to thousands of requests the costs can add up quickly. Therefore, it’s important to evaluate the performance of different models because sometimes a cheaper model can be sufficient as well. As you can see in this example.
So far I only showed OpenAI models, but Promptfoo also supports open-source models. Below, is an updated config that includes two open-source models. I refactored the config a bit to use variables for the calculation. The last test is a more complex calculation to see how well the open-source models perform.
prompts:
- '{{calculation}} You MUST only return the numeric value for the calculation!'
providers:
- id: 'openai:gpt-3.5-turbo-16k'
- id: 'ollama:completion:qwen3:8b'
- id: 'ollama:chat:mathstral'
tests:
- description: 'Easy calculation'
vars:
calculation: 'What is 5 multiplied by 5 and extracted by 4?'
assert:
- type: equals
value: 21
- description: 'More complex calculation'
vars:
calculation: 'Compute the following exactly: Take the least common multiple of 10 and 15, add the greatest common divisor of 84 and 36, multiply that sum by (3^4 - 2^3), then divide the product by the factorial of 3.'
assert:
- type: equals
value: 511
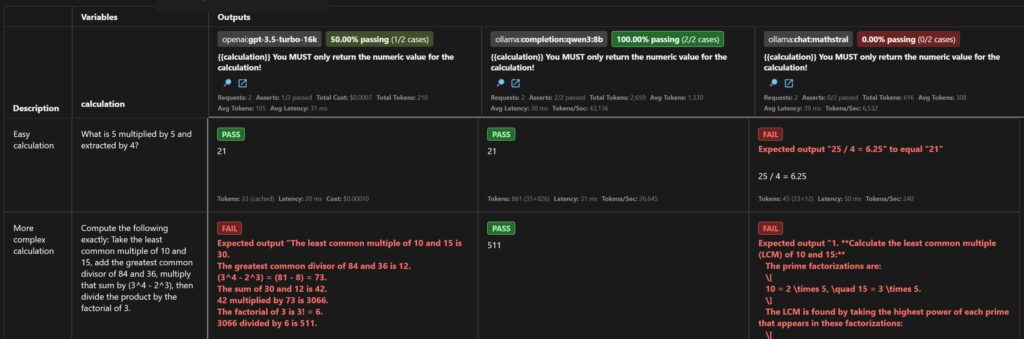
Only qwen3 was able to answer both calculations correctly. Mathstral struggled with both calculations, while GPT-3.5-turbo-16k only struggled with the more complex calculation. This shows that open-source models can be a viable option for certain tasks, but their performance can vary significantly depending on the complexity of the task.
Test reasoning capabilities
Let’s say you have a more complex prompt that requires reasoning over a business report to calculate the total revenue of a company. Below is an example config that tests three different models, including OpenAI’s GPT-3.5-turbo-16k (which obvious doesn’t support reasoning), GPT-5-mini, and Qwen3-8b.
providers:
- id: 'openai:gpt-3.5-turbo-16k'
- id: 'openai:gpt-5'
config:
showThinking: true
think: true
- id: 'ollama:completion:qwen3:8b'
config:
showThinking: true
think: true
prompts:
- |
Read the business report and calculate the **total company revenue in USD**.
Only return the number (in millions) rounded to **two decimals**.
Think before you answer.
Report:
{{report}}
tests:
- vars:
report: |
BluePeak Analytics provides logistics optimization software and consulting services.
In 2024, the company earned $18 million from software subscriptions in North America, which represented 40% of its global software revenue.
European software revenue was 20% lower than North America’s, while Asia contributed half as much as Europe.
Consulting services made up 35% of total company revenue and brought in $24.5 million.
Hardware sensor sales accounted for the remaining 5% of total revenue, generating $3.5 million.
The company noted that subscription renewal rates improved, and operating profit increased by 12%.
Management highlighted that overall financial targets were exceeded despite rising cloud infrastructure costs.
assert:
- type: contains
value: 70.00
- type: g-eval
value: 'Check if the answer contains that the revenue is 70 million'
provider: openai:gpt-4.1-mini
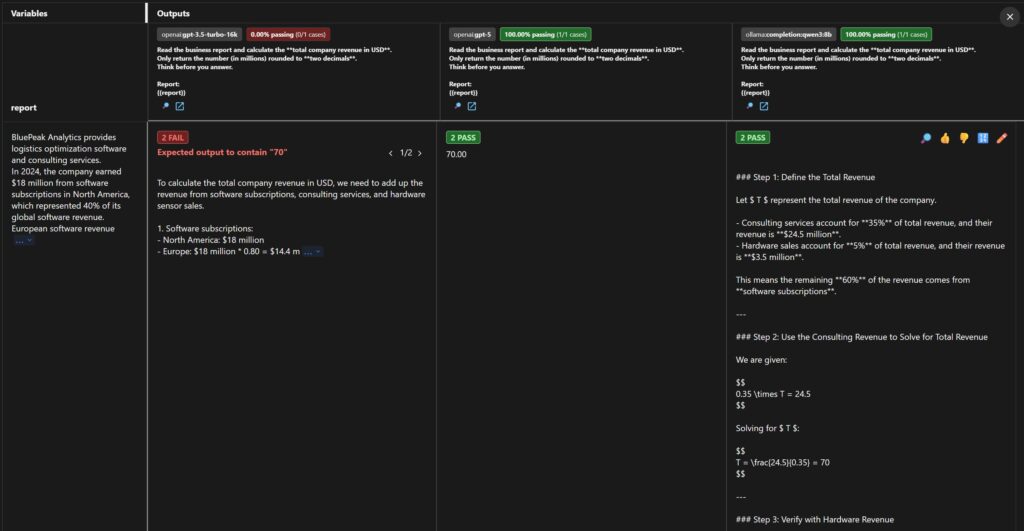
A couple of things to note at the config. First, I enabled the `think` option for both GPT-5 and Qwen3. The `showThinking` property allows you to see the model’s reasoning steps which is useful for debugging. Even though, I enabled it for both models, GPT-5 doesn’t show any reasoning steps in the output. That is because it’s simply not supported. In the prompt, I explicitly ask the model to think before answering. Two asserts are configured for this eval. A basic assert that simply checks if the output contains the expected value of 70.00 million. The second assert which is a bit more advanced uses the g-eval type. This assert uses another model (GPT-4.1-mini in this case) to evaluate the output of the main prompt. It checks if the answer contains that the revenue is 70 million. This is useful when the expected output can vary in format or when you want to check for specific content in the response.
Test tool calling
One of the most used features of LLMs is tool calling or function calling. This allows models to interact with external tools or APIs to enhance their capabilities. This behavior can perfectly be tested with Promptfoo because the LLM’s response for tool calling is just a JSON structure. Below is an example config that tests tool calling with both GPT-5 and Qwen3. Given is a business report of a company and a question about the revenue of the maintenance subscriptions. The model must call the function `get_financial_metric` to get the total revenue of the company because it’s not explicitly stated in the report. You might notice in the config below that the Ollama provider doesn’t use the `tools: file://./tools.json` but instead has the tool definition inline. This is because the Ollama provider (apparently) doesn’t support loading tools from a file.
providers:
- id: openai:gpt-5
config:
temperature: 0
tools: file://./tools.yaml
- id: ollama:chat:qwen3:8b
config:
temperature: 0
tools: #file://./tools.json
- type: function
function:
name: get_financial_metric
description: >
Lookup financial metrics for a company by name and year.
You MUST call this if you need revenue, operatingCost,
profitMargin, or other totals that are not explicitly stated.
parameters:
type: object
properties:
company:
type: string
description: "The company name. Example: 'LumaEdge Robotics'"
year:
type: number
description: "4-digit year, e.g. 2024"
metric:
type: string
description: >
The specific metric you want:
- 'totalRevenueUSD'
- 'operatingCostUSD'
- 'netIncomeUSD'
- 'grossMarginPct'
currency:
type: string
description: "Currency code (e.g. USD, EUR)"
enum: ['USD', 'EUR']
required: ['company', 'year', 'metric', 'currency']
prompts:
- |
You are a financial analyst assistant.
You will be given:
1. A short internal performance summary for a company.
2. A question you must answer.
Rules:
- If the answer requires any metric that is NOT directly stated in the summary
(for example, total revenue, operating cost, or margins),
you MUST call the function get_financial_metric with the right arguments,
instead of guessing.
Company performance summary (FY2024):
LumaEdge Robotics manufactures industrial cleaning robots for warehouses and airports.
During 2024, the company sold 420 units of the AeroSweep model at $48,000 each and
310 units of the DustPilot model at $36,500 each. Its maintenance subscriptions
generated an additional $4.6 million, while custom installation projects contributed
$2.4 million. The European market accounted for 60% of total sales, with the remainder
coming from North America and Asia. Management reported stable profit margins and noted
that all operational goals, including expansion into two new airports, were achieved on schedule.
Question:
{{question}}
tests:
- vars:
question: "What percentage of total company revenue came from maintenance subscriptions in 2024?"
assert:
- type: javascript
value: |
if (false) {
throw new Error('This is an error');
}
const data = output[0];
if (data.function.name !== 'get_financial_metric') {
throw `Expected tool=get_financial_metric, got ${data.tool}`;
}
if (!data.function.arguments) {
throw 'Missing arguments in tool call';
}
const arguments = JSON.parse(data.function.arguments);
if (arguments.company !== 'LumaEdge Robotics') {
throw 'Expected company=LumaEdge Robotics';
}
if (arguments.year !== 2024) {
throw 'Expected year=2024';
}
if (arguments.metric !== 'totalRevenueUSD') {
throw 'Expected metric=totalRevenueUSD';
}
if (arguments.currency !== 'USD') {
throw 'Expected currency=USD';
}
return true;
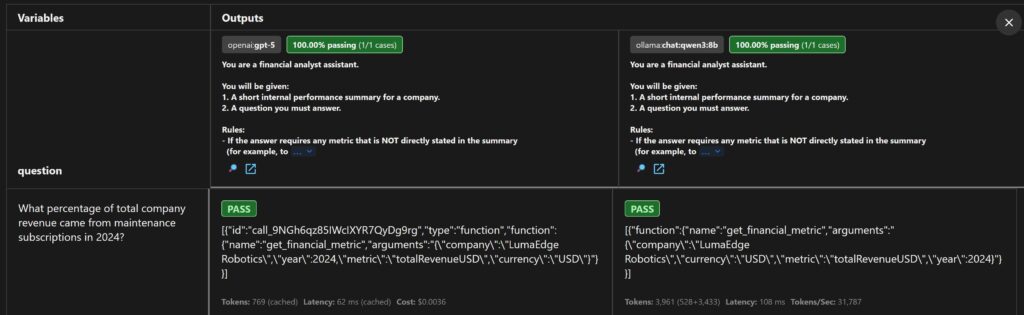
In the config, you can see that I’m using the JavaScript assert type to validate the tool call. This is basically custom code that runs against the LLM’s output. To ensure that the model is calling the function correctly, I check if the correct function is used with the right arguments. If any of the checks fail, an error is thrown which causes the eval to fail. Qwen3 is surprisingly good at tool calling. Again, this shows that open-source models can be a good alternative to proprietary models depending on the use case.
Test semantic similarity with embeddings
Another useful assert type is the similarity check. This assert uses embeddings to compare the semantic similarity between two texts. Below is an example config that summarizes a business report into two sentences. The eval checks if the summary is similar to an expected text.
providers:
- id: openai:gpt-4o-mini
config:
temperature: 0
- id: ollama:tinyllama
config:
temperature: 0
- id: ollama:gemma3:1b
config:
temperature: 0
prompts:
- |
You are an analyst.
Task:
Summarize the following business report in EXACTLY 2 sentences.
The summary MUST mention:
- what the company sells,
- how it makes money,
- and one business outcome (growth, expansion, goal achievement, etc.).
Do not include numbers or currency symbols in your summary.
Output plain text only.
Report:
{{report}}
tests:
- vars:
report: |
LumaEdge Robotics manufactures industrial cleaning robots for warehouses and airports.
During 2024, the company sold 420 units of the AeroSweep model at $48,000 each and
310 units of the DustPilot model at $36,500 each. Its maintenance subscriptions
generated an additional $4.6 million, while custom installation projects contributed
$2.4 million. The European market accounted for 60% of total sales, with the remainder
coming from North America and Asia. Management reported stable profit margins and noted
that all operational goals, including expansion into two new airports, were achieved on schedule.
assert:
- type: similar
threshold: 0.8
value: >
LumaEdge Robotics builds and sells autonomous cleaning robots for large facilities,
and earns additional revenue from ongoing maintenance and installation services.
The company reports stable performance and successful expansion into new sites.
provider: openai:embeddings:text-embedding-3-large
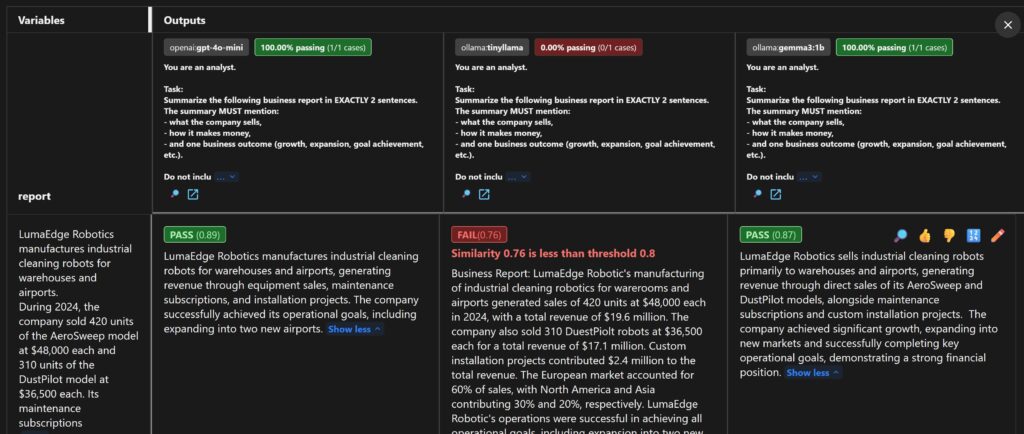
For this similarity test, I configured two smaller open-source models: TinyLlama and Gemma3-1b. TinyLlama struggles a bit with the task and is making up some details.
I showed various examples of testing prompts with different models. In this article, I just demonstrated a few assert types but Promptfoo supports many more:
- Basic asserts
- G-eval
- Conversational relevance
- Context faithfulness
- Context relevance
- Factuality
- … and more
Just like code, prompts should go through a proper development lifecycle. As mentioned earlier, models can change over time (tone of voice, behavior) which can impact the performance of prompts. Therefore, it’s important to have continuous testing and evaluation of prompts. Also, it’s good to evaluate prompts against different models to find the best fit for your application. An important factor is costs. Especially when your application scales, costs can add up quickly. Even though, a model from a proprietary provider performs better, it might not be worth the extra costs if a cheaper model performs good enough.