We now live in a world where ML workflows (pre-training, post training, etc) are heterogeneous, must contend with hardware failures, are increasingly asynchronous and highly dynamic. Traditionally, PyTorch has relied on an HPC-style multi-controller model, where multiple copies of the same script are launched across different machines, each running its own instance of the application (often referred to as SPMD). ML workflows are becoming more complex: pre-training might combine advanced parallelism with asynchrony and partial failure; while RL models used in post-training require a high degree of dynamism with complex feedback loops. While the logic of these workflows may be relatively straightforward, they are notoriously difficult to implement well in a multi-controller system, wh…
We now live in a world where ML workflows (pre-training, post training, etc) are heterogeneous, must contend with hardware failures, are increasingly asynchronous and highly dynamic. Traditionally, PyTorch has relied on an HPC-style multi-controller model, where multiple copies of the same script are launched across different machines, each running its own instance of the application (often referred to as SPMD). ML workflows are becoming more complex: pre-training might combine advanced parallelism with asynchrony and partial failure; while RL models used in post-training require a high degree of dynamism with complex feedback loops. While the logic of these workflows may be relatively straightforward, they are notoriously difficult to implement well in a multi-controller system, where each node must decide how to act based on only a local view of the workflow’s state.
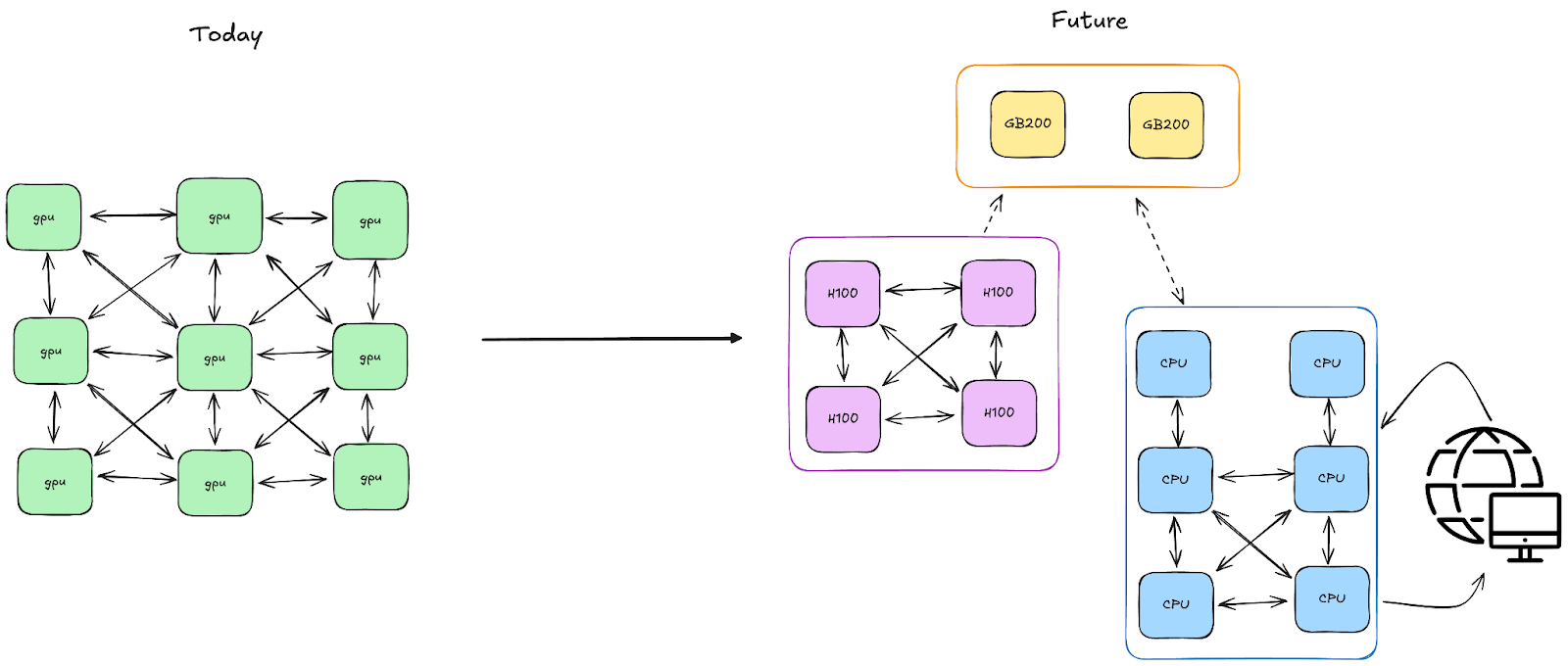
We believe that the long-term sustainable way to address this is through a single controller programming model, in which a single script orchestrates all distributed resources, making them feel almost local. This architectural shift simplifies distributed programming—your code looks and feels like a single-machine Python program, but can scale across thousands of GPUs. You can directly use Pythonic constructs—classes, functions, loops, tasks, futures—to express complex distributed algorithms.
We’re excited to introduce Monarch, a distributed programming framework that brings the simplicity of single-machine PyTorch to entire clusters.
Monarch lets you program distributed systems the way you’d program a single machine, hiding the complexity of distributed computing:
- Program clusters like arrays. Monarch organizes hosts, processes, and actors into scalable meshes that you can manipulate directly. You can operate on entire meshes (or slices of them) with simple APIs—Monarch handles the distribution and vectorization automatically, so you can think in terms of what you want to compute, not where the code runs.
- Progressive fault handling. With Monarch, you write your code as if nothing fails. When something does fail, Monarch fails fast by default—stopping the whole program, just like an uncaught exception in a simple local script. Later, you can progressively add fine-grained fault handling exactly where you need it, catching and recovering from failures just like you’d catch exceptions.
- Separate control from data. Monarch splits control plane (messaging) from data plane (RDMA transfers), enabling direct GPU-to-GPU memory transfers across your cluster. Monarch lets you send commands through one path, while moving data through another, optimized for what each does best.
- Distributed tensors that feel local. Monarch integrates seamlessly with PyTorch to provide tensors that are sharded across clusters of GPUs. Monarch tensor operations look local but are executed across distributed large clusters, with Monarch handling the complexity of coordinating across thousands of GPUs.
Programming Model
Key APIs: Process and Actor Meshes
Monarch organizes resources into multidimensional arrays, or meshes. A process mesh is an array of processes spread across many hosts; an actor mesh is an array of actors, each running inside a separate process. Like array programming in NumPy or PyTorch, meshes make it simple to dispatch operations efficiently across large systems.
At launch, Monarch supports process meshes over GPU clusters—typically one process per GPU—onto which you can spawn actors into actor meshes. For local development, the same meshes can also run on a local development server.
Advanced APIs: Tensor Engine and RDMA Buffer
Monarch’s tensor engine brings distributed tensors to process meshes. It lets you write PyTorch programs as if the entire cluster of GPUs were attached to the machine running the script. For bulk data movement, Monarch also provides an RDMA buffer API, enabling direct, high-throughput transfers between processes on supported NICs.
Extensive details and more detailed examples can be found on our GitHub page.
A Simple Example
Monarch code imperatively describes how to create processes and actors using a simple Python API:
from monarch.actor import Actor, endpoint, this_host
procs = this_host().spawn_procs({"gpus": 8})
# define an actor that has one method
class Example(Actor):
@endpoint
def say_hello(self, txt):
return f"hello {txt}"
# spawn the actors
actors = procs.spawn("actors", Example)
# have them say hello
hello_future = actors.say_hello.call("world")
# print out the results
print(hello_future.get())
In the above example, we define an Actor called “Example” that is deployed on 8 GPUs on the local host. The controller then invokes this example across the host and waits for their response. The actors can expose a variety of interfaces.
Slicing Meshes
We express broadcasted communication by organizing actors into a Mesh – a multidimensional container with named dimensions. For instance, a cluster might have dimensions {“hosts”: 32, “gpus”: 8}. Dimension names are normally things like “hosts”, indexing across the hosts in a cluster, or “gpus”, indexing across things in a machine.
from monarch.actor import Actor, endpoint, this_host
procs = this_host().spawn_procs({"gpus": 8})
# define an actor that has two methods
class Example(Actor):
@endpoint
def say_hello(self, txt):
return f"hello {txt}"
@endpoint
def say_bye(self, txt):
return f"goodbye {txt}"
# spawn the actors
actors = procs.spawn("actors", Example)
# have half of them say hello
hello_fut = actors.slice(gpus=slice(0,4)).say_hello.call("world")
# the other half say good bye
bye_fut = actors.slice(gpus=slice(4,8)).say_bye.call("world")
print(hello_fut.get())
print(bye_fut.get())
Fault Recovery
Users can express distributed programs that can error through pythonic try, except blocks. Complex fault detection and fault recovery schemes can be built on top of these primitives. The following showcases handling a simple runtime Exception in a remote actor.
from monarch.actor import Actor, endpoint, this_host
procs = this_host().spawn_procs({"gpus": 8})
class Example(Actor):
@endpoint
def say_hello(self, txt):
return f"hello {txt}"
@endpoint
def say_bye(self, txt):
raise Exception("saying bye is hard")
actors = procs.spawn("actors", Example)
hello_fut = actors.slice(gpus=slice(0,4)).say_hello.call("world")
bye_fut = actors.slice(gpus=slice(4,8)).say_bye.call("world")
try:
print(hello_fut.get())
except:
print("couldn't say hello")
try:
print(bye_fut.get())
except Exception:
print("got an exception saying bye")
See “Case Study 2: Fault Tolerance in Large Scale Pre Training” for a more realistic use case.
The Monarch Backend
Monarch is split into a Python-based frontend, and a backend implemented in Rust. Python is the lingua franca of machine learning, and our Python frontend APIs allow users to seamlessly integrate with existing code and libraries (like PyTorch!), and to use Monarch with interactive computing tools like Jupyter notebooks. Our Rust-based backend facilitates our performance, scale, and robustness — we amply use Rust’s fearless concurrency in Monarch’s implementation.
Hyperactor and hyperactor_mesh
At the bottom of the stack is a Rust-based actor framework called hyperactor. Hyperactor is a low-level distributed actor system, focused on performant message passing and robust supervision. hyperactor_mesh is built on top of hyperactor, and combines its various components into an efficient “vectorized” actor implementation. Hyperactor_mesh is oriented towards providing actor operations cheaply over large meshes of actors.
Monarch’s core Python APIs, in turn, are fairly thin wrappers around hyperactor_mesh.
Scalable messaging
Everything in Monarch relies on scalable messaging: the core APIs supporting casting messages to large meshes of actors. Hyperactor achieves this through two mechanisms: multicast trees and multipart messaging.
First, in order to support multicasting, Hyperactor sets up multicast trees to distribute messages. When a message is cast, it is first sent to some initial nodes, which then forward copies of the message to a set of its children, and so on, until the message has been fully distributed throughout the mesh. This lets us avoid single-host bottlenecks, effectively using the whole mesh as a distributed cluster for message forwarding. (Cite scalability numbers here.)
Second, we ensure that the control plane is never in the critical path of data delivery. For example, we use multipart messaging to avoid copying, to enable sharing data across high-fanout sends (such as those that occur in our multicast trees), and materialize into efficient, vectorized writes managed by the OS.
Case Studies
We believe that this general purpose API and its native integration with PyTorch will unlock the next generation of AI applications at scale and the more complex orchestration requirements that they present.
Case Study 1: Reinforcement Learning
Reinforcement learning has been critical to the current generation of frontier models. RL enables models to do deep research, perform tasks in an environment and solve challenging problems such as math and code. For a deeper dive, we recommend this post for a deeper dive into the topics.
In order to train a reasoning model (see figure below), generator processes produce prompts from the reasoning model specializing in a specific domain (say, programming code generation). The generator uses these prompts (an incomplete coding problem statement) to derive a set of solutions or trajectories (executable code in this example) often interacting with the world through tools (compiler) and environments. Reward pipelines evaluate these solutions and come up with scores. These scores and rewards are used to train the same model whose weights are then transferred back to the systems that generated the prompt responses.
This constitutes a single training loop! As illustrated in the figure below, this is effectively a real-time pipeline of a number of heterogeneous computations within a training loop that may have to be orchestrated and scaled individually.
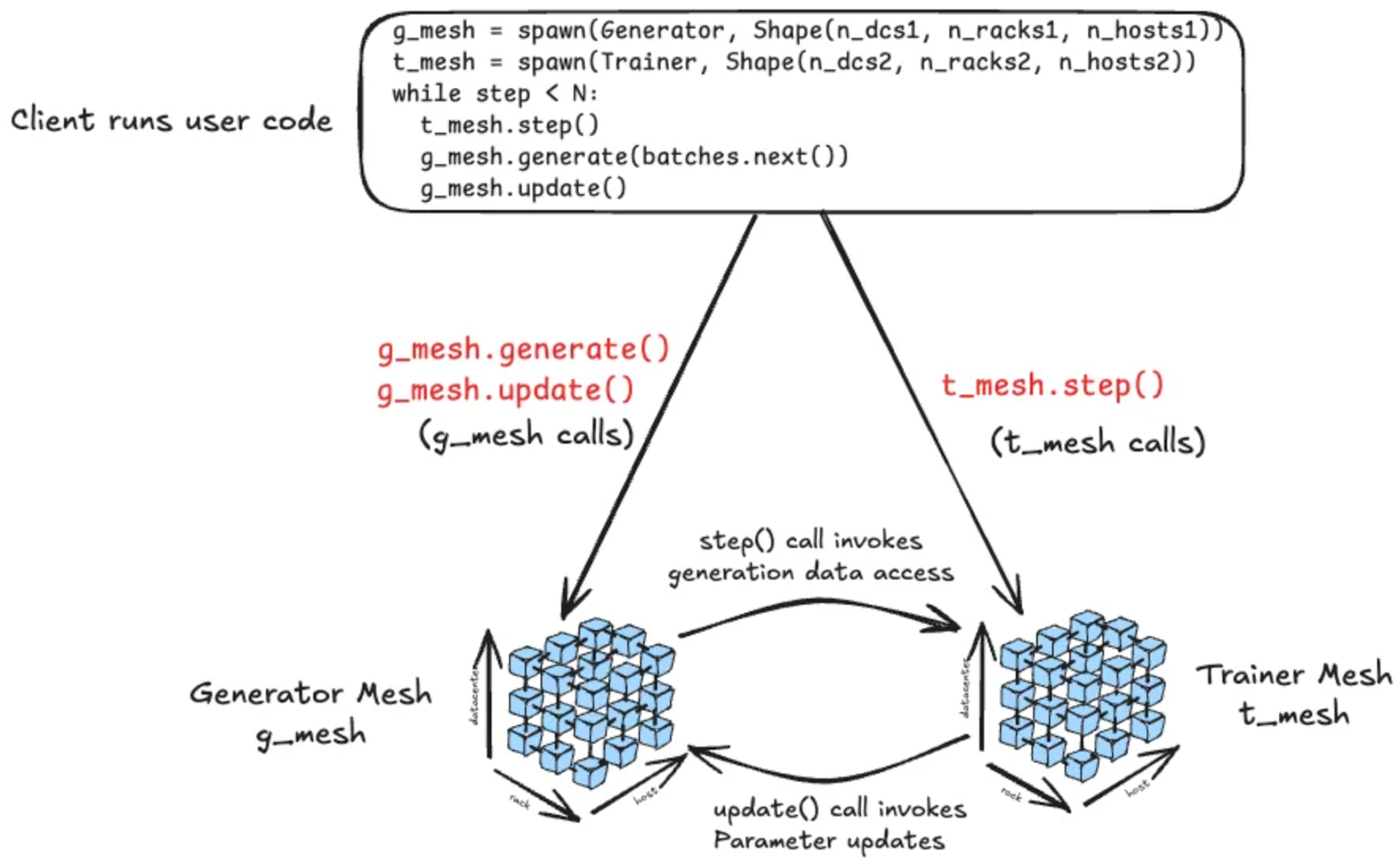
When implementing the RL example above in Monarch, each component — generator, trainer, inference engine, reward pipeline — might be represented by a mesh: a mesh of generators, a mesh of trainers, a mesh of inference nodes, a mesh of reward pipelines. (The figure above shows a simplistic example with only two meshes: generator and trainer).
The training script then uses these meshes to orchestrate the overall flow of the job: telling the generator mesh to start working from a new batch of prompts, passing the data to the training mesh when they are done, and updating the inference mesh when a new model snapshot is ready. The orchestrator is written as an ordinary Python program, calling methods on meshes and passing data between them. Because Monarch supports remote memory transfers (RDMA) natively, the actual data is transferred directly between members of meshes (just like you might copy a tensor from one GPU to another), enabling efficient and scalable workflows.
VERL
Volcano Engine Reinforcement Learning (VERL) is a widely used Reinforcement Learning framework in the industry today.
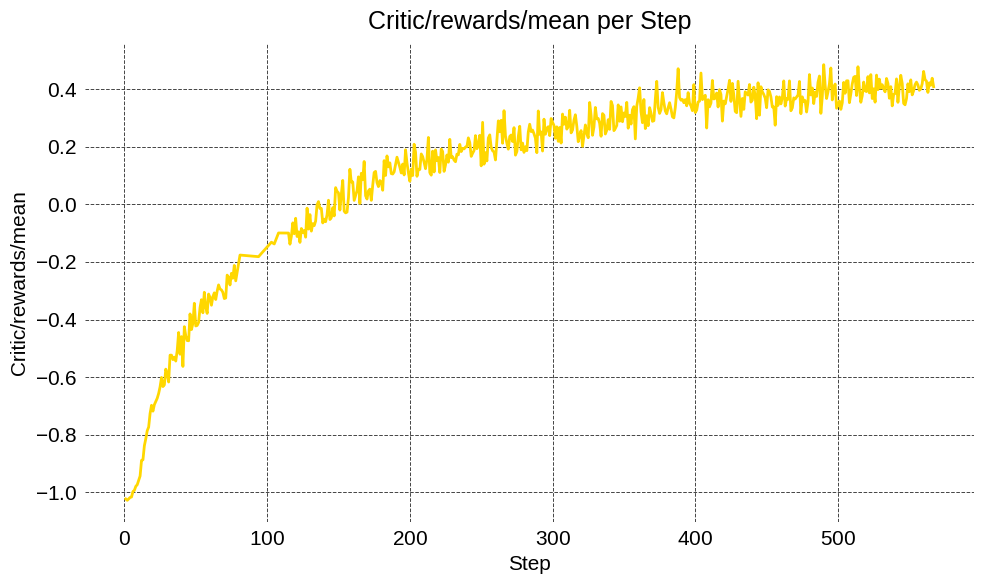
We integrated Monarch with VERL as a proof-of-concept and post-trained the Qwen-2.5-7B math model using GRPO on a curated math dataset and evaluated it on the AIME 2024 benchmark. We trained for 500+ training steps on H200 GPUs using Megatron-LM scaling progressively from 16, 64, 1024 to 2048 GPUs. The runs were stable and yielded good numerical parity with existing options, demonstrating that Monarch can orchestrate existing RL frameworks.
We are actively working on open-sourcing this integration to allow future users to evaluate Monarch as an option in their VERL jobs.
TorchForge
TorchForge represents a different approach: a pytorch native RL framework designed from the ground up with Monarch primitives.
TorchForge’s goal is to let researchers express RL algorithms as naturally as pseudocode, while Monarch handles the distributed complexity underneath. The result is code that looks like this:
async def continuous_rollouts():
while True:
prompt, target = await dataloader.sample.route()
response = await policy.generate.route(prompt)
reward = await reward.evaluate_response.route(prompt, response.text, target)
await replay_buffer.add.route(Episode(...))
No distributed coordination code, no retry logic, just RL written in Python.
Building on Monarch: Services and TorchStore
This clean API is possible because torchforge builds two key abstractions on Monarch’s primitives:
“Services” wrap Monarch ActorMeshes with RL-specific patterns. They leverage Monarch’s fault tolerance, resource allocation, and mailbox system, while adding patterns like load-balanced routing (`.route()`), parallel broadcasts (`.fanout()`), and sticky sessions for stateful operations.
# A service is a managed group of ActorMeshes with routing primitives
policy = PolicyActor.options(
procs=8, with_gpus=True, num_replicas=16 # Creates 16 replicas, each with 8 GPUs
).as_service()
# Services provide RL-friendly adverbs built on Monarch actors
response = await policy.generate.route(prompt) # Load-balanced routing
await policy.update_weights.fanout(version) # Parallel broadcast
TorchStore is a distributed key-value store for PyTorch tensors that handles weight synchronization between training and inference. Built on Monarch’s RDMA primitives and single-controller design, it provides simple DTensor APIs while efficiently resharding weights on the fly – critical for off-policy RL where training and inference use different layouts.
These abstractions demonstrate Monarch’s composability: torchforge uses Monarch’s primitives (actors, RDMA, fault tolerance) as building blocks to create RL-specific infrastructure. The resulting framework handles coordination complexity at the infrastructure layer, letting researchers focus on algorithms.
For detailed examples of Forge’s APIs, component integration, and design philosophy, see our torchforge blog post.
Case Study 2: Fault Tolerance in Large Scale Pre Training
Hardware and software failures are common and frequent at scale. For example, in our Llama3 training runs we experienced 419 interruptions across a 54 day training window for a 16k GPU training job. This averages to about one failure every 3 hours. If we project this out to 10s of thousands of GPUs, this represents a failure once every hour or more frequently. Restarting the entire job for each of these failures will reduce the effective training time.
A solution is to use methods to further leverage distributed training through methods to make the numerics of the model more tolerant of having the various groups run more asynchronously. For example, TorchFT, released from PyTorch, provides a way to withstand failures of GPUs and allow the training to continue. One strategy is to use Hybrid Sharded Data Parallelism that combines fault tolerant DDP with FSDP v2 and PP. On failure we use torchcomms to gracefully handle errors and UI training on the next batch without downtime. This isolates failures to a single “replica group” and we can continue training with a subset of the original job.
Monarch integrates with TorchFT. Monarch centralizes the control plane into a single-controller model. Monarch uses its fault detection primitives to detect failures, and upon detection, can spin up new logical replica groups (Monarch Meshes) to join training once initialized. TorchFT’s Lighthouse server acts as a Monarch actor. Monarch provides configurable recovery strategies based on failure type. On faults, the controller first attempts fast, process‑level restarts within the existing allocation and only escalates to job reallocation when necessary, while TorchFT keeps healthy replicas stepping so progress continues during recovery.
We ran this code on a 30 node (240 H100s) Coreweave cluster, using the SLURM scheduler to train Qwen3-32B using torchtitan and TorchFT. We injected 100 injected failures every 3 minutes across multiple failure modes (segfaults, process kills, NCCL abort, host eviction, GIL deadlock). Monarch allows for configurable recovery strategies based on failure type — we observed this to be 60% faster by avoiding unnecessary job rescheduling (relative to full SLURM job restarts). We see 90s avg recovery for process failures and 2.5min avg recovery machine failures. For more details, see the README.
Case Study 3: Interactive Debugging with a Large GPU cluster
The actor framework is not just limited to large scale orchestration of complex jobs. It enables the ability to seamlessly debug complex, multi-GPU computations interactively. This capability represents a fundamental shift from traditional batch-oriented debugging to real-time, exploratory problem-solving that matches the scale and complexity of contemporary AI systems.
Traditional debugging workflows break down when confronted with the realities of modern ML systems. A model that trains perfectly on a single GPU may exhibit subtle race conditions, deadlocks, memory fragmentation, or communication bottlenecks when scaled across dozens of accelerators.
Monarch provides an interactive developer experience. With a local jupyter notebook, a user can drive a cluster as a Monarch mesh.
- Persistent distributed compute allows very fast iteration without submitting new jobs
- Workspace sync_workspace API quickly syncs local conda environment code to Mesh nodes.
- Monarch provides a mesh-native, distributed debugger
See a jupyter tutorial at pytorch.org
Monarch + Lightning AI Notebook
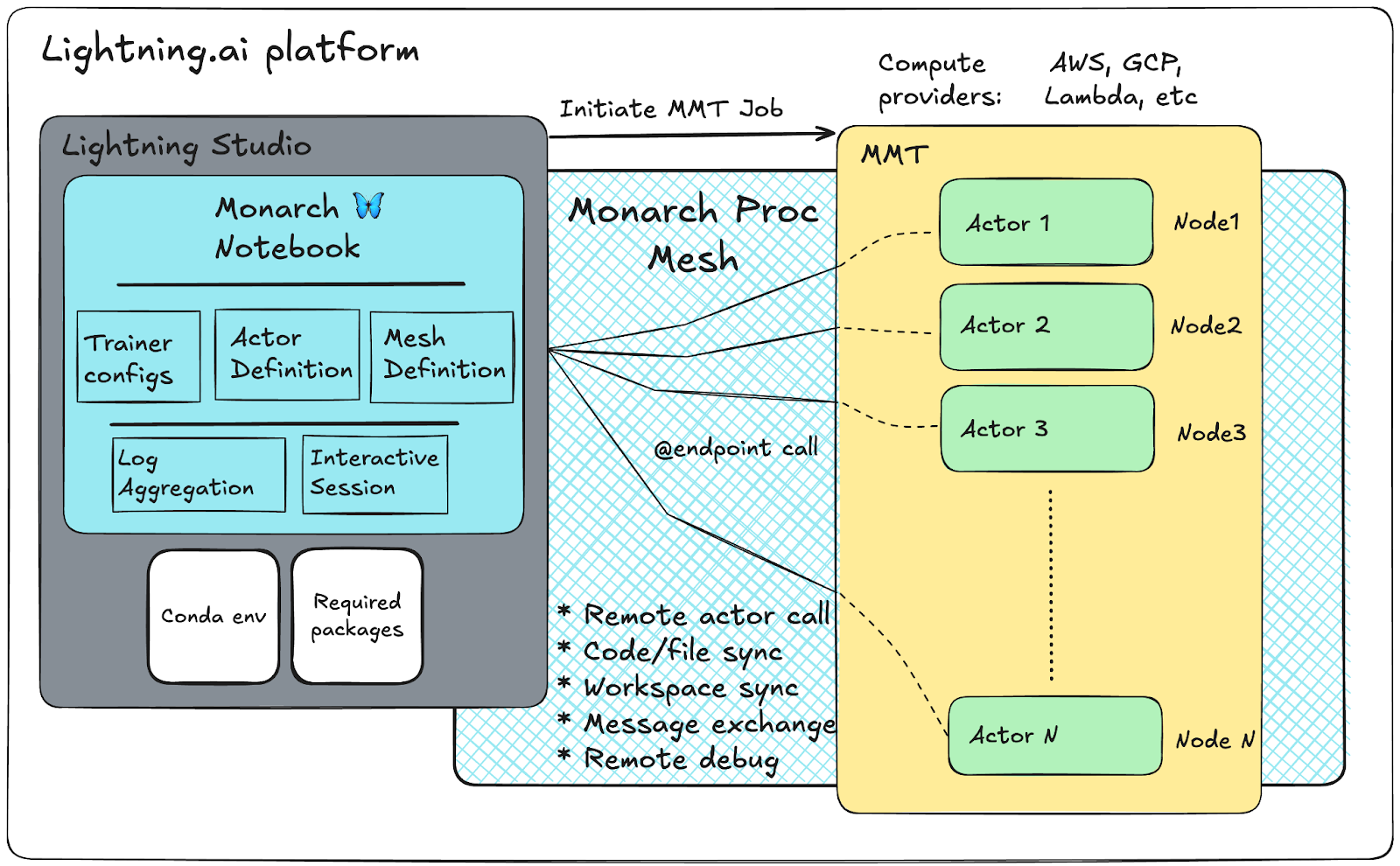
See Monarch in action as we launch a 256-GPU training job from a single Studio notebook, powered by TorchTitan. Experience seamless scaling, persistent resources, and interactive debugging — all in one single Notebook. The figure above shows this schema. Also, see our Monarch-Lightning blog post. In this example, the traditional SPMD TorchTitan workload is encapsulated as an Actor within Monarch, allowing users to pre-train large language models (such as Llama-3 and Llama-4) interactively from a Studio Notebook.
Monarch enables you to reserve and maintain compute resources directly from your local Studio Notebook in lightning. Even if your notebook session is interrupted or code disconnects, your cluster allocation remains active through Multi-Machine Training (MMT). This persistence of the process allocator allows you to iterate, experiment, and resume work seamlessly, reducing manual intervention and making the notebook a reliable control center for distributed training tasks.
Using Monarch’s Actor model, you can define and launch the Titan Trainer as an Actor on a process mesh, scaling your training jobs to hundreds of GPUs – all from within the Studio notebook. Monarch handles the orchestration, code and file sharing, and log collection, so you can reconfigure and relaunch jobs quickly. Logs and metrics are available directly in the notebook, as well as through external tools like Litlogger and WandB, making it easy to monitor and manage large-scale training.
Monarch brings interactive debugging to distributed training. You can set Python breakpoints in your Actor code, inspect running processes, and attach to specific actors for real-time troubleshooting – all from the notebook interface. After training, you can modify configurations or define new actors and relaunch jobs on the same resources without waiting for new allocations. This dynamic workflow accelerates experimentation and provides deep insight into your distributed training runs.
The code snippet in the Monarch-Lightning blog post shows the sample Lightning studio notebook for Monarch to pre-train the Llama-3.1 – 8B model using TorchTitan on 256 GPUs.
Try Monarch Today: Build, Scale, and Debug Distributed AI Workflows with Ease
Monarch is available now on GitHub—ready for you to explore, build with, and contribute to. Dive into the Monarch repo to get started, explore the documentation for deeper technical details, and try out our interactive Jupyter notebook to see Monarch in action. For an end-to-end example of launching large-scale training directly from your notebook, check out the Lightning.ai integration. Whether you’re orchestrating massive training runs, experimenting with reinforcement learning, or interactively debugging distributed systems, Monarch gives you the tools to do it all—simply and at scale.
Acknowledgments
Thank you to the whole Monarch team for making this work possible. Also, a special thanks to our Top Contributors on GitHub!
Ahmad Sharif, Allen Wang, Alireza Shamsoshoara, Amir Afzali, Amr Mahdi, Andrew Gallagher, Benji Pelletier, Carole-Jean Wu, Chris Gottbrath, Colin Taylor, Davide Italiano, Dennis van der Staay, Eliot Hedeman, Gayathri Aiyer, Gregory Chanan, Hamid Shojanazeri, James Perng, James Sun, Jana van Greunen, Jayasi Mehar, Joe Spisak, John William Humphreys, Jun Li, Kai Li, Keyan Pishdadian, Kiuk Chung, Lucas Pasqualin, Marius Eriksen, Marko Radmilac, Mathew Oldham, Matthew Zhang, Michael Suo, Matthias Reso, Osama Abuelsorour, Pablo Ruiz Fischer Bennetts, Peng Zhang, Rajesh Nishtala, Riley Dulin, Rithesh Baradi, Robert Rusch, Sam Lurye, Samuel Hsia, Shayne Fletcher, Tao Lin, Thomas Wang, Victoria Dudin, Vidhya Venkat, Vladimir Ivanov, Zachary DeVito