At Perplexity, we use the best models for our product, our APIs, and our research teams. Large open-source Mixture-of-Experts models, such as Kimi-K2 pose particular challenges, as the largest inference nodes with 8x NVIDIA H200 GPUs cannot efficiently accommodate them, necessitating multi-node deployments. We present a set of kernels for expert parallelism which achieve state-of-the-art latencies on ConnectX-7, exceeding the performance of DeepEP. The same kernels are also the first to achieve viable latencies on AWS Elastic Fabric Adapter (EFA), enabling trillion-parameter model deployments.
Try our kernels on GitHub and read the full research paper on arXiv.
Introduction
Mixture-of-Experts (…
At Perplexity, we use the best models for our product, our APIs, and our research teams. Large open-source Mixture-of-Experts models, such as Kimi-K2 pose particular challenges, as the largest inference nodes with 8x NVIDIA H200 GPUs cannot efficiently accommodate them, necessitating multi-node deployments. We present a set of kernels for expert parallelism which achieve state-of-the-art latencies on ConnectX-7, exceeding the performance of DeepEP. The same kernels are also the first to achieve viable latencies on AWS Elastic Fabric Adapter (EFA), enabling trillion-parameter model deployments.
Try our kernels on GitHub and read the full research paper on arXiv.
Introduction
Mixture-of-Experts (MoE) has emerged as the standard architecture for scaling to hundreds of billions or trillions of parameters while also offering reasonable latency at inference time. MoE models replace the dense layer of a transformer with a set of experts and a small linear routing layer that decides which experts to multiply a token with. By grouping the tokens associated with the same expert, the problem becomes sparse and trivially parallelizable, as different experts can now be hosted on different GPUs spread across multiple nodes.
Unlike other forms of parallelism, such as Tensor Parallelism (TP) and Data Parallelism (DP) which can be easily implemented using collective communication libraries such as torch.distributed and NCCL, MoE routing involves sparse peer-to-peer communication. A dispatch kernel must split the set of incoming tokens and dispatch them to the ranks hosting the experts, while its dual problem, the combine kernel, must receive their processed counterparts and compute their weighted average. These transfers do not map to collectives and require customized kernels to achieve low latency.
At Perplexity, we have been developing both portable inter-node kernels and specialized intra-node kernels, presenting our work in greater depth in a previous article on MoE communication. We also showed in another blog post that multi-node deployment can bring lower latency and higher throughput for large MoE models.
In this article, we deep-dive into the implementation of our new inter-node kernels which greatly improves upon the performance of our NVSHMEM-based previous work. Besides showcasing state-of-the-art results on ConnectX-7, we also demonstrate that within our inference runtime, the kernels can be used to effectively serve the largest open-source models.
Inference over InfiniBand
Tensor parallelism and expert parallelism can effectively scale within a single node, as NVLink offers high throughput (900GB/s) at microseconds of latency. While NVIDIA GB200 and GB300 systems are equipped with sufficient memory to hold the weights and KV caches of trillion-parameter models, deployments on AWS p5en instance with up to 8 H200 GPU are limited to 1120GB of HBM, which must be split across both model weights and KV caches. Consequently, certain models necessitate inter-node deployments over InfiniBand.
Although InfiniBand is still blazing fast, it only offers 400Gbps (50GB/s) of throughput, adding tens to hundreds of microseconds of latency for MoE routing. Fortunately, the added latencies can be hidden through the use of shared experts, micro-batching and computation-communication overlapping to deliver viable throughput at a competitive cost. DeepSeek pioneered these techniques via DeepSeek-R1, deployed on clusters of H800 GPUs and NVIDIA ConnectX-7 InfiniBand adapters.
On AWS clusters, the situation is different due to the use of their custom Elastic Fabric Adapters (EFA). Even though these deliver peak 400Gbps throughput on the collectives typically used in training workloads, they fall slightly short of ConnectX-7 on the message sizes exchanged during MoE dispatch and combine. Additionally, EFA does not support GPUDirect Async, requiring a CPU proxy thread bridging the GPU to the NIC in order to initiate transfers. Besides the added complexity, the additional PCIe transactions add microseconds worth of overhead to all transfers. Frameworks such as NVSHMEM allow kernel writers to provide device-independent implementations, however the generic APIs incur overheads that render deployments ineffective in terms of both cost and latency.
NVSHMEM-based pplx-kernels
Our previous kernels abstracted away the underlying transport implementation through NVSHMEM. They relied on nvshmemx_putmem_signal_nbi_warpto transfer tokens one-by-one, using atomic counters to synchronize peers. While this offered reasonable performance on ConnectX-7 NICs with IBGDA, the proxy-based ConnectX-7 IBRC implementation was significantly slower, while the EFA implementation failed to deliver latencies under a millisecond.
We used the kernels as a testbed for the underlying hardware, while also pinning down the most suitable interface to expose to our models. We hypothesized that the frequent transfers and interactions between the kernels and the NICs or the proxy threads hindered performance. Additionally, our implementation did not rely on any guarantees from the hardware other than reliability, suggesting that we could speed things up by reducing the overhead of synchronization primitives.
Following these observations, we devised our EFA-based kernels exposing the same interface, optimizing the device kernel - host proxy interactions under the hood for peak performance.
MoE all-to-all over EFA
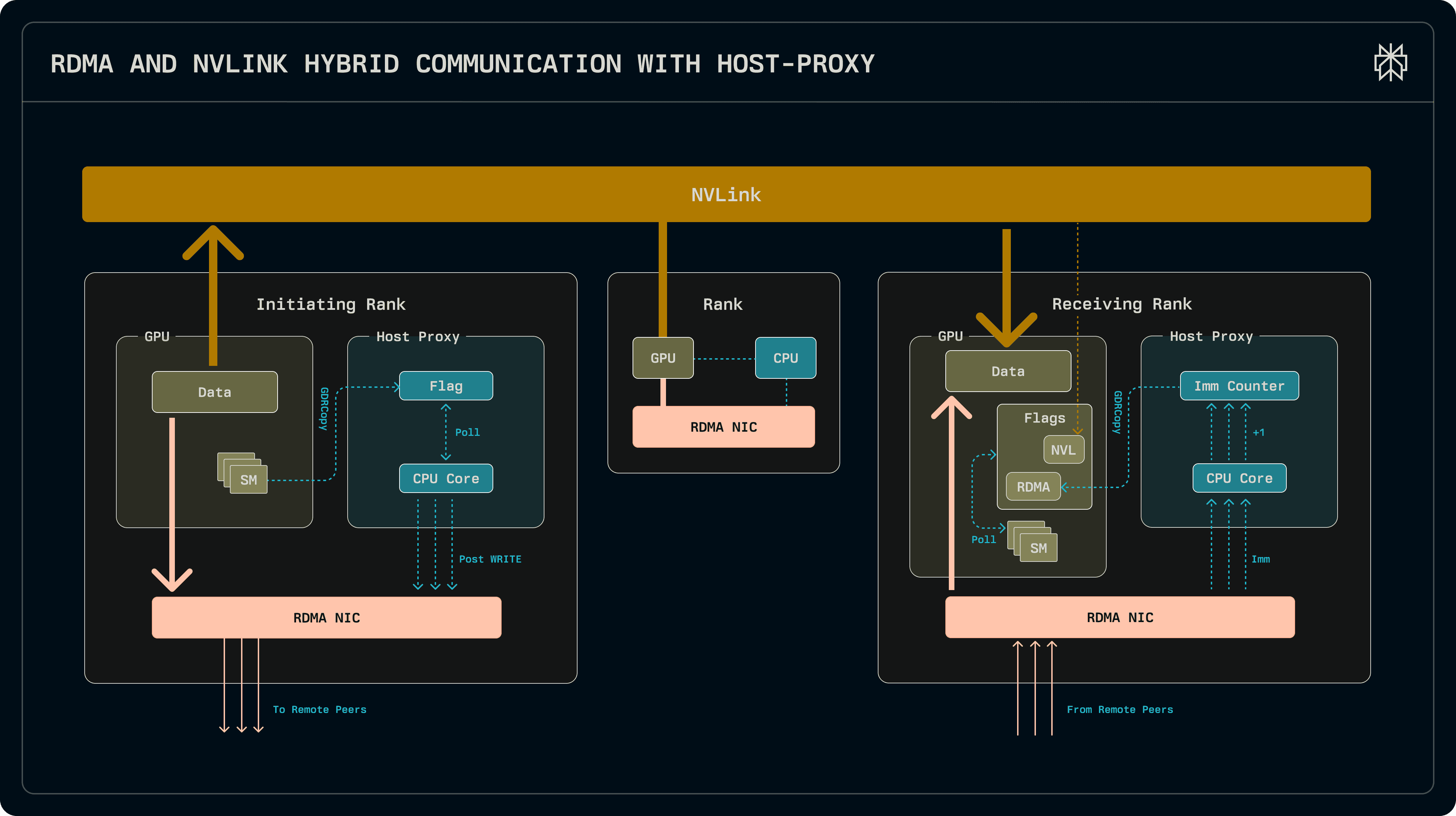
The new kernels follow a hybrid CPU-GPU architecture, where GPU kernels interact with the model on the device and a proxy thread running on the host CPU handles interactions with the NIC. The new kernels re-use the same TransferEngine that we built for KV cache transfers.
MoE routing is performed by a dispatch kernel, which receives the tokens and the per-token experts to route them to from the model, shipping them over the network to the ranks which host the experts. After the grouped GEMM kernels multiply the tokens with the expert weights, the combine kernel transfers the tokens over to their source ranks and computes their weighted average before returning them to the model.
Both the dispatch and combine kernels are split into a sender and a receiver half to facilitate overlapping and micro-batching. The sender shuffles the tokens into send buffers so they can be written to peers through a single RDMA write operation. After executing the sender, the GPU can perform other work (such as shared expert multiplication) while the transfers over the network are pending in the background. The receiver kernels block until all transfers have been received. In the background, a host-side worker thread handles the transfers: it is signalled by the GPU when the send buffers have been populated, after which it dispatches the RDMA writes. Once the NIC signals completion, it unblocks the receiver, which returns the tokens to the model.
The kernels are tightly coupled with the host, communicating with each other through both unified memory and GDRCopy. CUDA unified memory allows device memory or host memory to be mapped into the address spaces of both, transparently handling communication via PCIe.
While unified memory is suitable for bulk transfers, low-latency polling is done through GDRCopy. GDRCopy uses GPUDirect RDMA to read from and write to GPU memory at microsecond latency.
In addition to RDMA, within a node the kernels also leverage NVLink to exchange tokens. This can offload a significant fraction of the traffic, up to a quarter for EP32 and up to an eight for EP64, achieving overall lower latencies.
Send and Receive Buffers
The design of the send buffers for the dispatch kernel is crucial towards achieving viable latencies involving the host proxy. If there are N ranks each dispatching T tokens, each routed to R experts out of E, a rank can receive up to N * T * max(R, E / N) tokens in the worst possible case, if all are routed to it. Furthermore, this minimum bound can be achieved only when the senders lay out their writes contiguously, as private receive buffers would use up too much memory. For senders to be able to lay out their writes consecutively without conflicts, full knowledge of the routing information must be distributed to each rank. Consequently, our dispatch kernels first exchange per-expert token counts, after which they can each determine where their writes go and which offset they receive tokens from each rank from.
Simply exchanging routing information would result in unnecessarily high latencies, as each rank would have to wait for the writes to arrive before dispatching any writes of its own. Instead, we reserve a small amount of private per-sender space on each receiver rank and dispatch some of the tokens alongside the writes of the routing information. This ensures full bandwidth utilization throughout most of the dispatch process. After routes are exchanged, the remaining tokens are transferred via a single write per remote peer. The exchange of routing information and the fixed-sized buffers, along with the transfers populating them, are illustrated in the figure below.
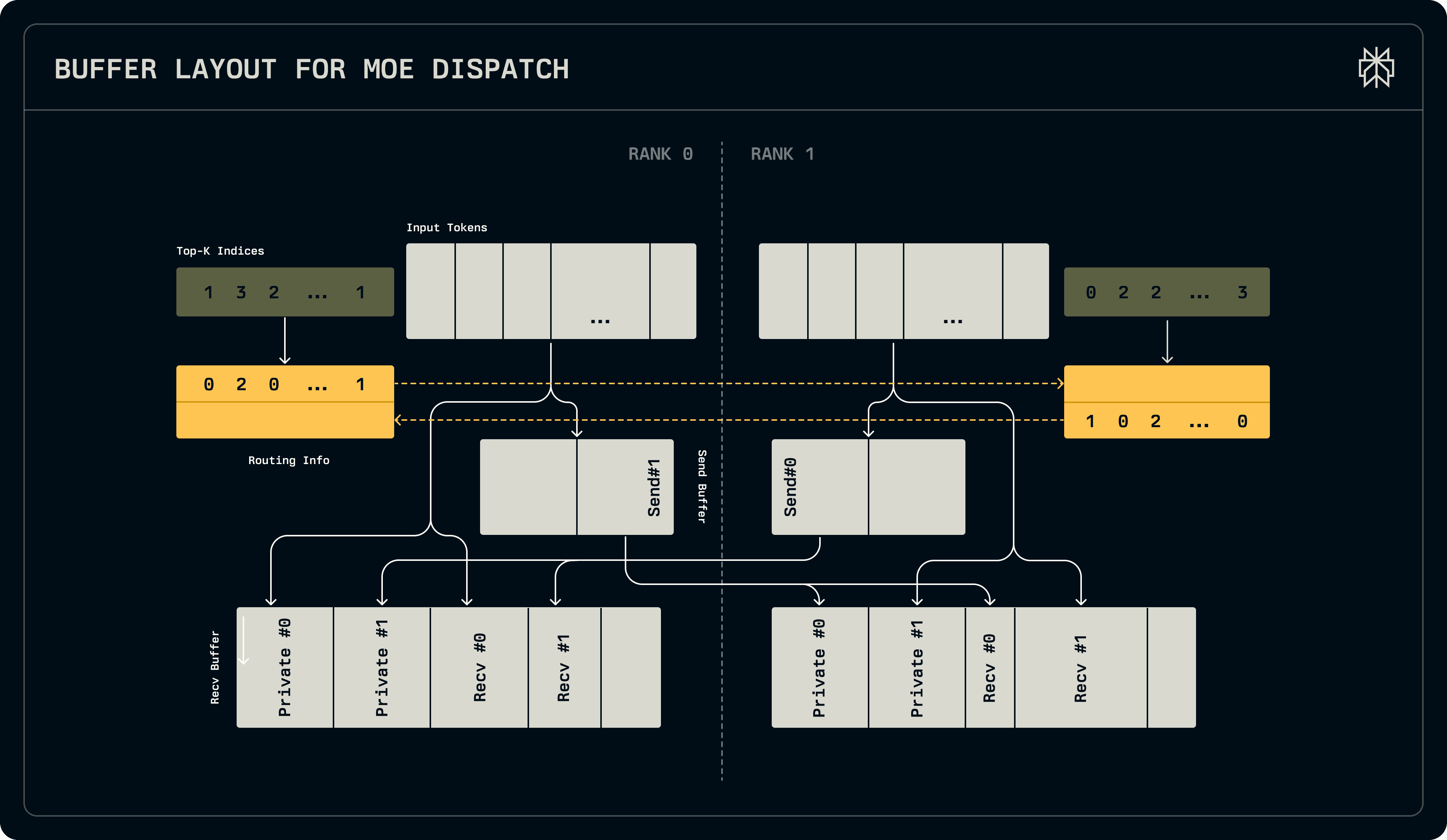
The combine kernels are substantially simpler, as routing information is already available to them from the dispatch stage. They can copy the tokens over in a single write per peer, after which they read from the receive buffer to compute the weighted average of the tokens into the output tensors.
For NVLink, the send and receive buffers within a node are mapped into the peers for them to be able to directly push or pull tokens from neighbouring ranks.
Dispatch and Combine
The figures below details the timing and the interactions between the GPU, CPU and NIC, showing one iteration of dispatch and combine interleaved with the kernels of the model.
Work starts off in dispatch send, with the kernel aggregating the routing information and computing per-expert token counts via atomic accumulation in shared memory within a single block. Once the token counts are available, they are copied to host memory and the proxy is immediately notified to start dispatching the routing information to all other peer ranks. In parallel, dispatch continues to compute the cumulative sum of the token counts, identifying the offsets required to pack tokens into contiguous per-per send buffers. Once the offsets are available, all tokens to be sent via EFA are packed into the send buffers. The proxy is notified to post the writes into the send buffers of inter-node peers. Intra-node, the kernels also immediately push tokens into private buffers within the same node through NVLink.
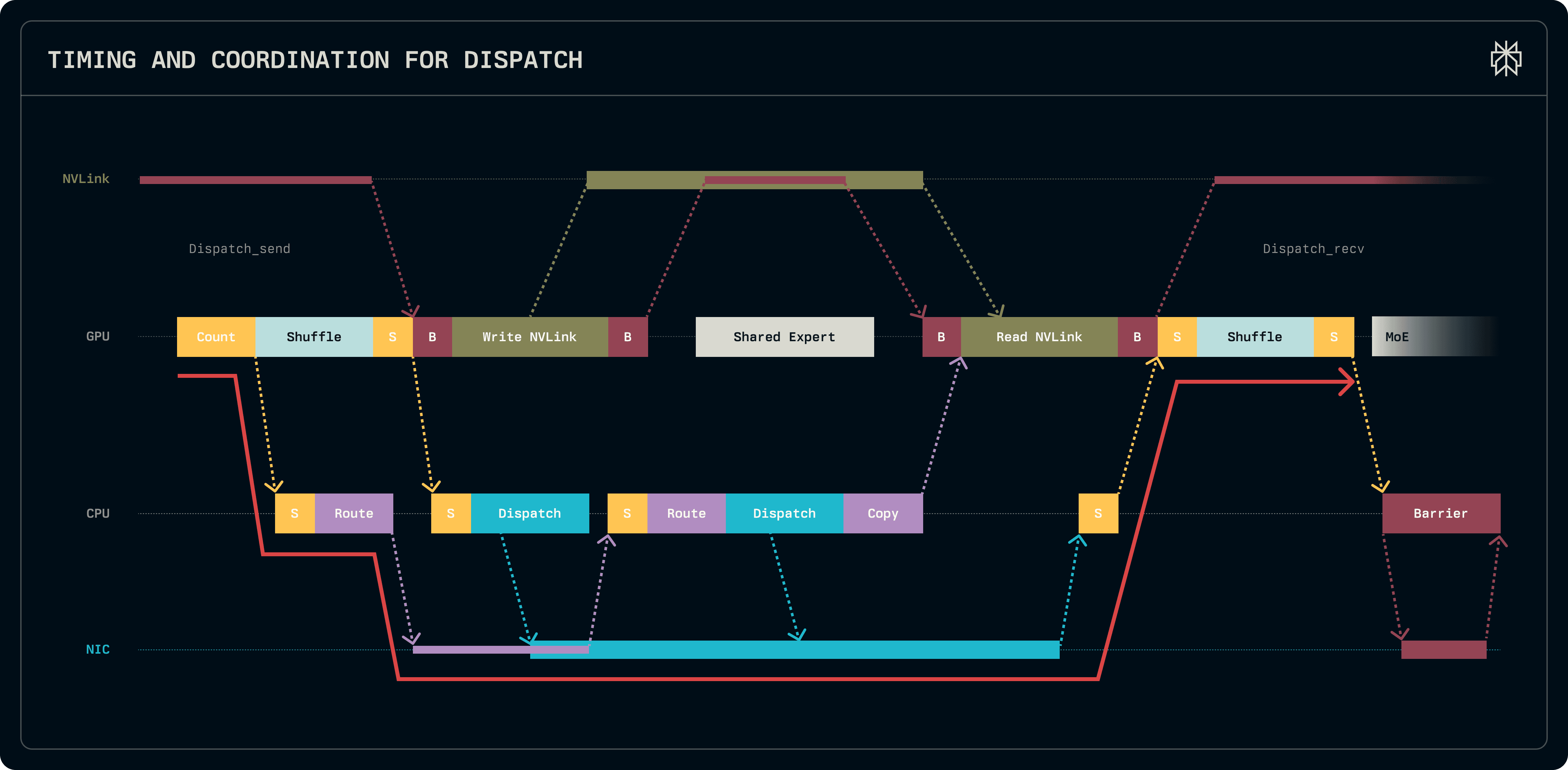
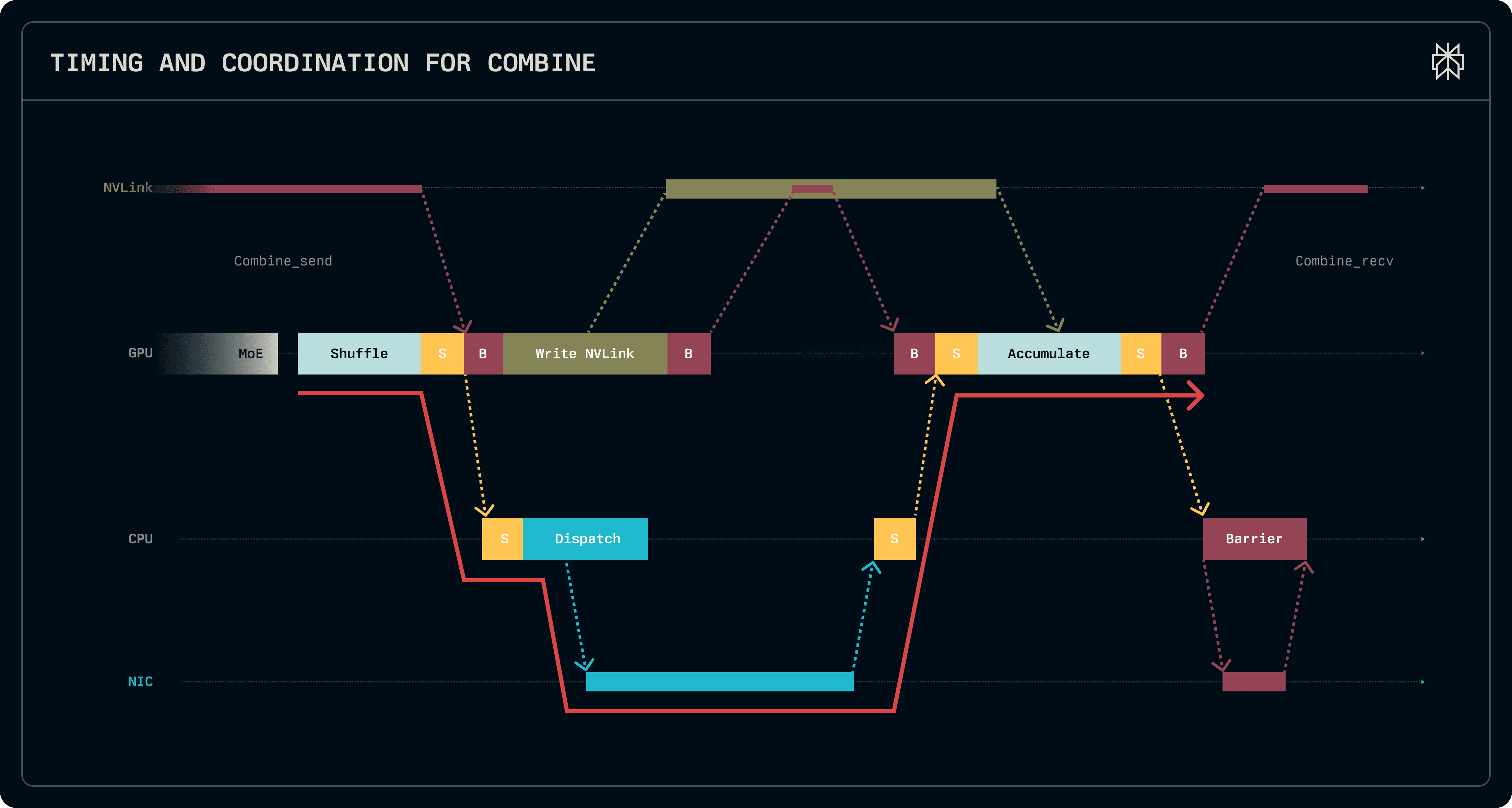
Once a rank receives routing information from all peers, it centralizes it and computes various offsets necessary to identify tokens for dispatch and combine. This work is done on the CPU while transfers are already pending, thus it is not latency critical. Subsequently, once all offsets are known, writes for the remainder of the tokens, which exceed the private buffer size, are posted and the send phase of dispatch is complete.
On the receiver end, the kernel first pulls tokens from the same node which are beyond the capacity of private buffers through NVLink. Next, it blocks until the host proxy signals the completion of all transfers. Once the signal is received, tokens are shuffled from the receive buffers into the output tensor passed to group GEMM. Since buffers are re-used between dispatch and combine, both NVLink and RDMA barriers ensure that the receiver buffers have been read before allowing the next kernel to overwrite them.
The combine kernels follow a roughly similar pattern, shuffling tokens, signalling the proxy and waiting for completion. However, the metadata for posting their writes is readily available and all remote offsets are known, thus all tokens transferred intra-node are pushed via NVLink to the receivers and the inter-node tokens are transferred via a single write. Before returning the results, the kernel accumulates the tokens from the receiver buffers, writing them into the output tensors.
TransferEngine for MoE routing
To prototype our implementation, we initially re-used the Transfer Engine built for disaggregate prefill and decode in order to issue and track RDMA writes. However, unlike disaggregated decoding where each node posts a large number of writes to the same peer, MoE dispatch posts small transfers to all the peers in one operation. Out-of-the box, performance was not optimal and our implementation was lagging behind DeepEP on ConnectX-7 by about 20us. Consequently, we specialized the TransferEngine to support two operations, scatter and barrier, to optimize interactions with a large number of peers.
Both scatter and barrier operations expose peer groups which can be pre-registered to pre-populate the data structures used by the underlying transport implementation (Work Request (WR) templating). Scatter copies different slices from the same source buffer into different offsets on all the members of a peer group. Barrier signals all the peers through an immediate. Enqueuing and handling these operations in bulk saves valuable microseconds on the critical path. On EFA, where two 200Gbps NICs aggregate to provide 400Gbps bandwidth, we shard group peers across the two NICs instead of sharding the bytes of each transfer.
Although initially we developed the TransferEngine solely on EFA using libfabric, the MoE kernels work on ConnectX-7 without changing a single line of code after adding ConnectX-7 support in the TransferEngine using libibverbs. Compared to Scalable Reliable Datagram (SRD) based EFA, ConnectX-7 requires additional work for connection setup and peer management. We use a Unreliable Datagram (UD) queue pair to bootstrap Reliable Connection (RC). We create two queue pairs for each remote peer, one for two-sided SEND/RECV and one for one-sided WRITE_IMM, because both RECV and WRITE_IMM consume RECV operation in order while the two operations require different buffer sizes. Besides, we relax PCIe transaction ordering between ConnectX-7 and GPU memory. Similar to EFA, we implement the WR templating optimization. Additionally, when sending multiple small messages to the same peer, we use WR chaining to improve message rate.
Since the GPU-side work is identical across both adapters, we pushed the underlying transport implementation to its limits to exceed the performance of DeepEP to highlight that the gap between EFA and ConnectX-7 MoE routing is determined by the capabilities of the underlying hardware.
Evaluation
Dispatch/Combine Latency
We evaluated dispatch and combine latencies on H200 systems equipped with ConnectX-7 and EFA adapters on the standard DeepSeek-V3 and Kimi-K2 configuration with a hidden dimension of 7168, block-scaled fp8 dispatch and bf16 combine. We consider a batch size of 128 for dispatch and 4096 for combine. On ConnectX-7, we compare to DeepEP and our previous NVSHMEM-based pplx-kernels, using both GPUDirect Async (IBGDA) and a host proxy (IBRC). We achieve combined latencies of 459us, 582us and 692us on EP16, EP32 and EP64, respectively. We outperform other EFA-based kernels relying on generic proxies, such as UCCL-EP, which achieve 519us, 966us and 1159us.
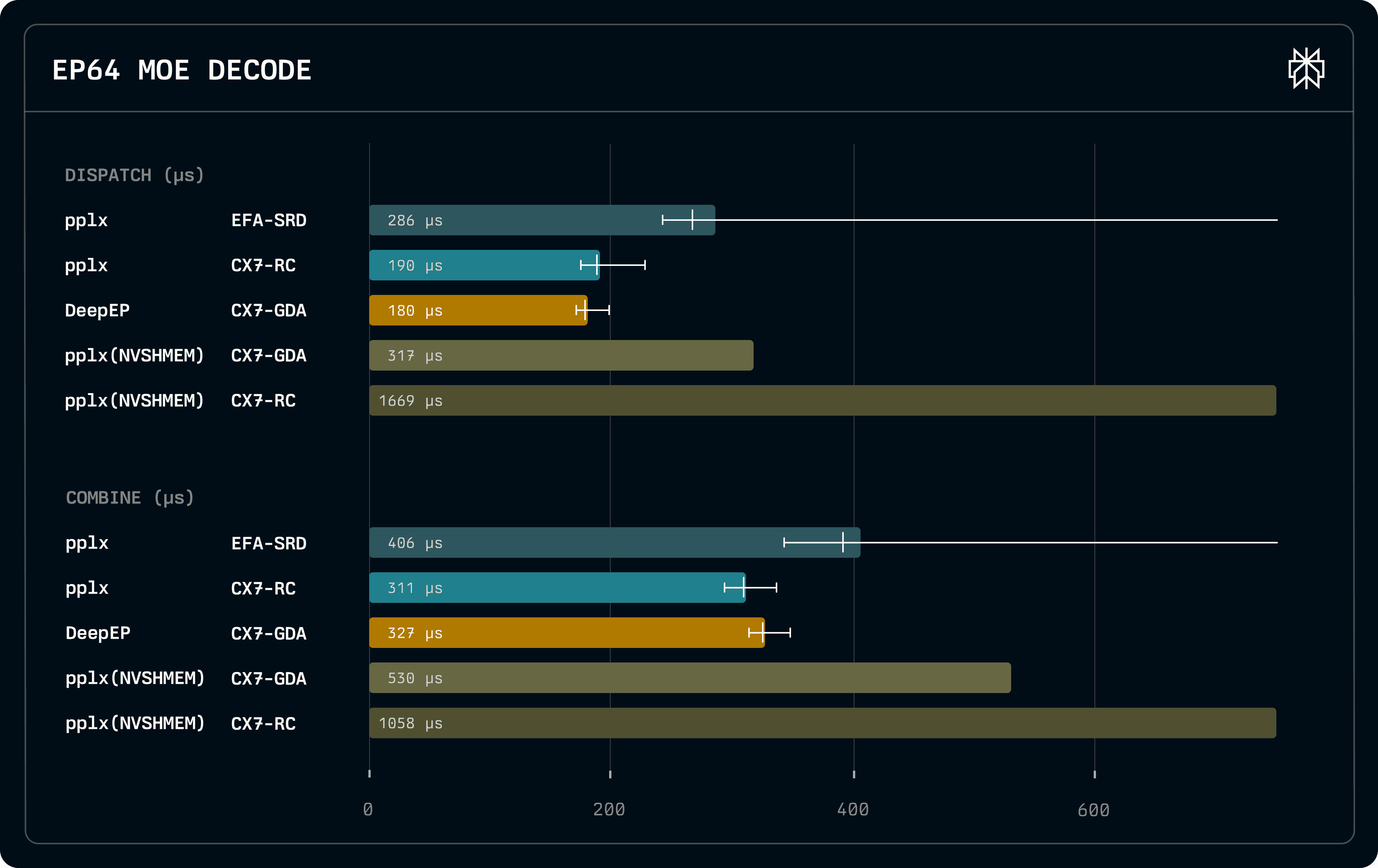
On decode, despite our kernels being a few microseconds slower than DeepEP, we achieve overall lower latencies as our combine kernels are substantially faster. Although we use a host proxy, due to our bulk transfers we exceed the performance of all IBGDA-based proxyless implementations. We also show that proxy implementation matters, as our highly specialized proxy is an order of magnitude faster than the generic NVSHMEM implementation. Despite the fact that EFA is twice as slow as ConnectX-7 when transferring 256KB packets, which are close to the typical packet size exchanged by MoE routing, the gap between the two adapters is overall less substantial.
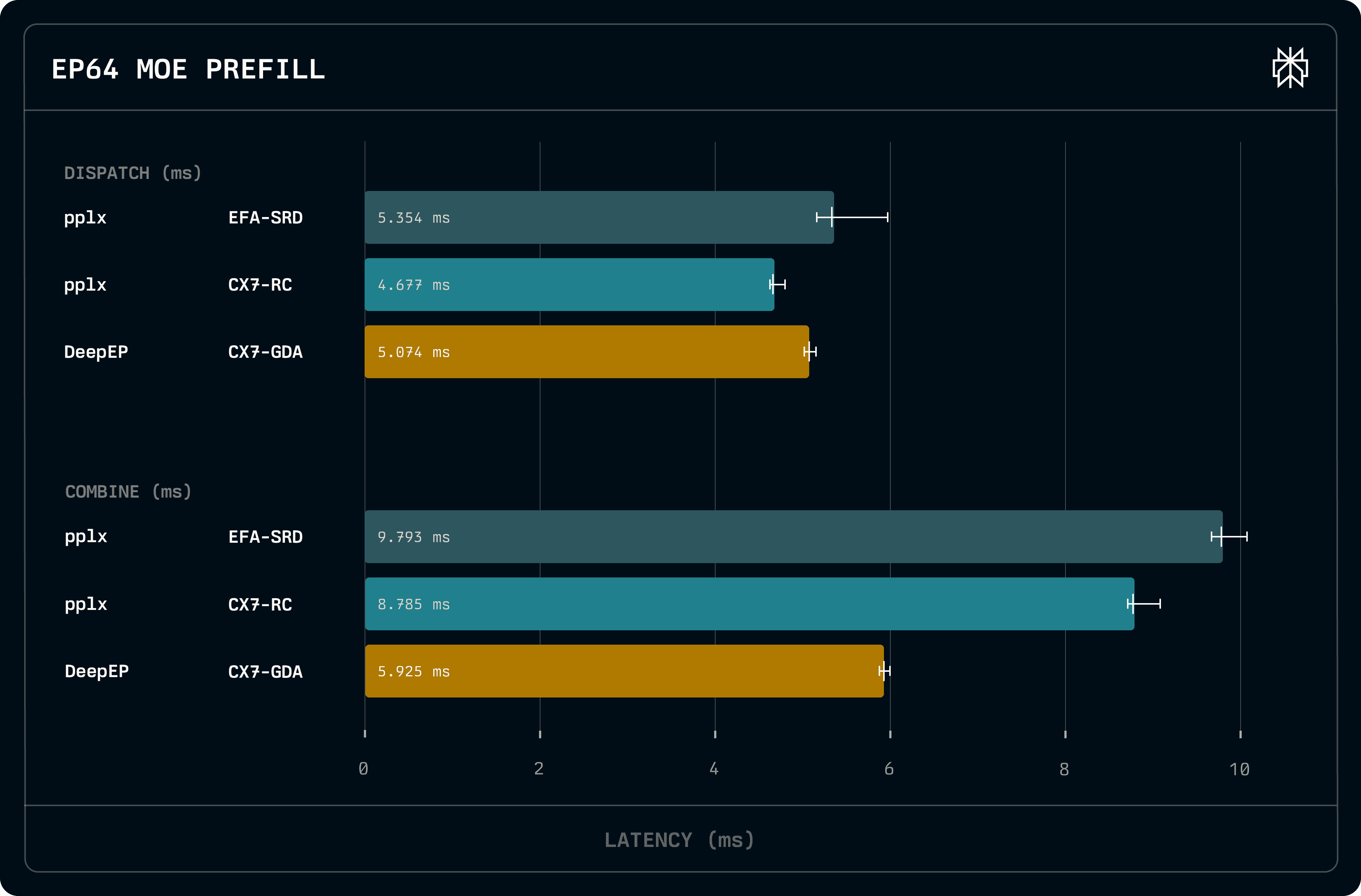
Even though our decode-optimized kernels can scale to prefill batch sizes without any additional tweaks, performance is lagging behind DeepEP. This is primarily due to the fact that we accumulate tokens only on the receiver side of combine, whereas DeepEP accumulates in the sender to reduce the amount of data transferred. However, this optimization can have accuracy implications. Additionally, since the kernels transfer data in one write, we utilize more memory for send and receive buffers.
Kimi-K2 / DeepSeek-V3 Throughput
To prove the viability of our kernels, we benchmark the end-to-end performance of our in-house inference engine serving DeepSeek-V3 (671B parameters) and Kimi-K2 (1T parameters) on multiple p5en instances equipped with Elastic Fabric Adapters (EFA) and H200 GPUs. We run the model in draft verification mode and report latency assuming an acceptance rate of 80% using a single MTP layer.
On DeepSeek-V3, we compare against an EP=8 intranode baseline running efficient NVLink-only dispatch and combine kernels. Inter-node deployments overall either match or exceed the performance of the single-node deployment, particularly on medium-sized batches, demonstrating that scaling across nodes does bring improvements to overall throughput.
On Kimi-K2, the kernels enable serving. Due to its size, the model cannot fit within the same node using Data Parallelism (DP) on an H200 node, thus an inter-node deployment is required to serve the model. As the model has fewer attention heads, we achieve better latencies than DeepSeek-V3 and we can serve the model on EFA at a viable latency.
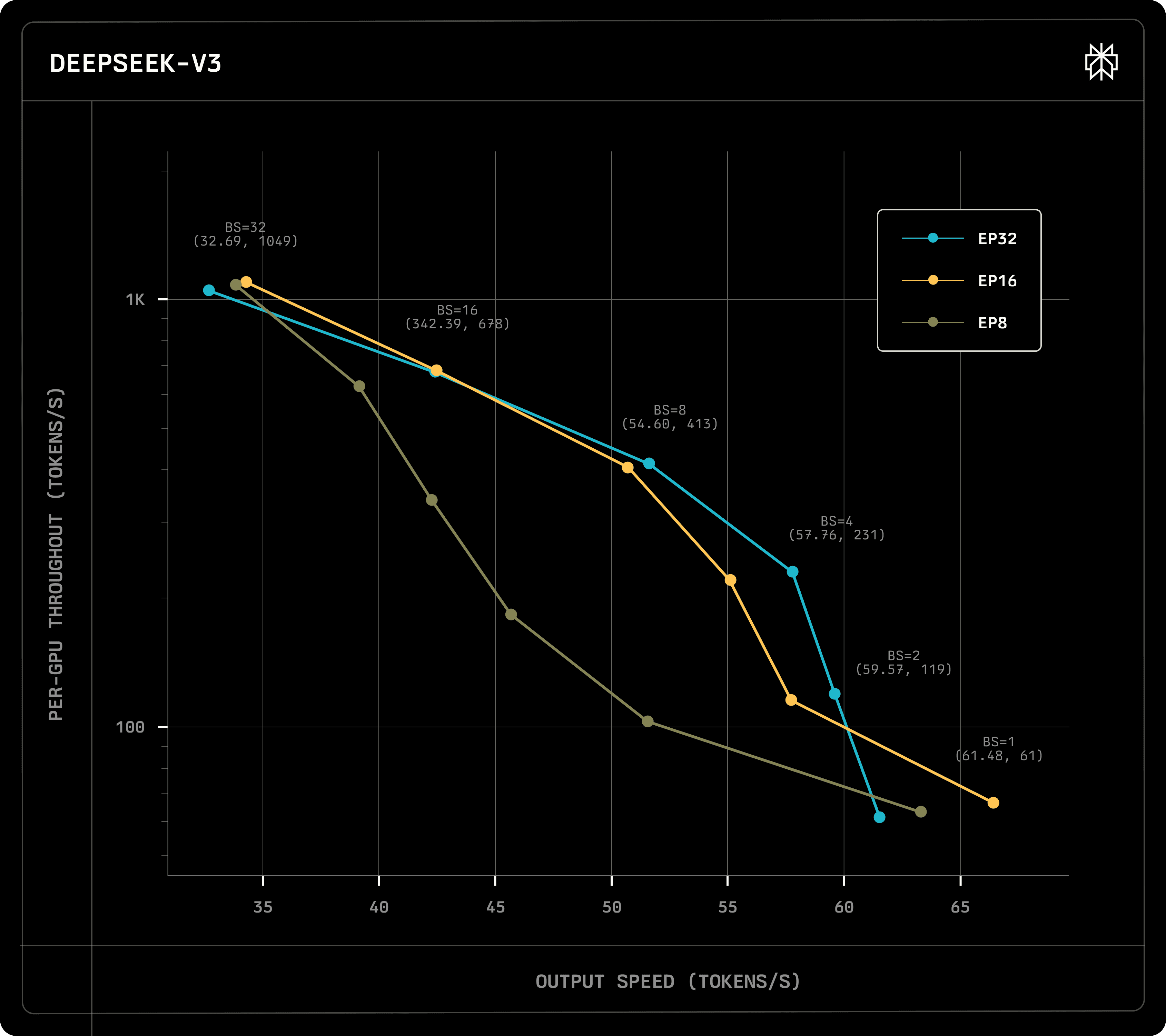
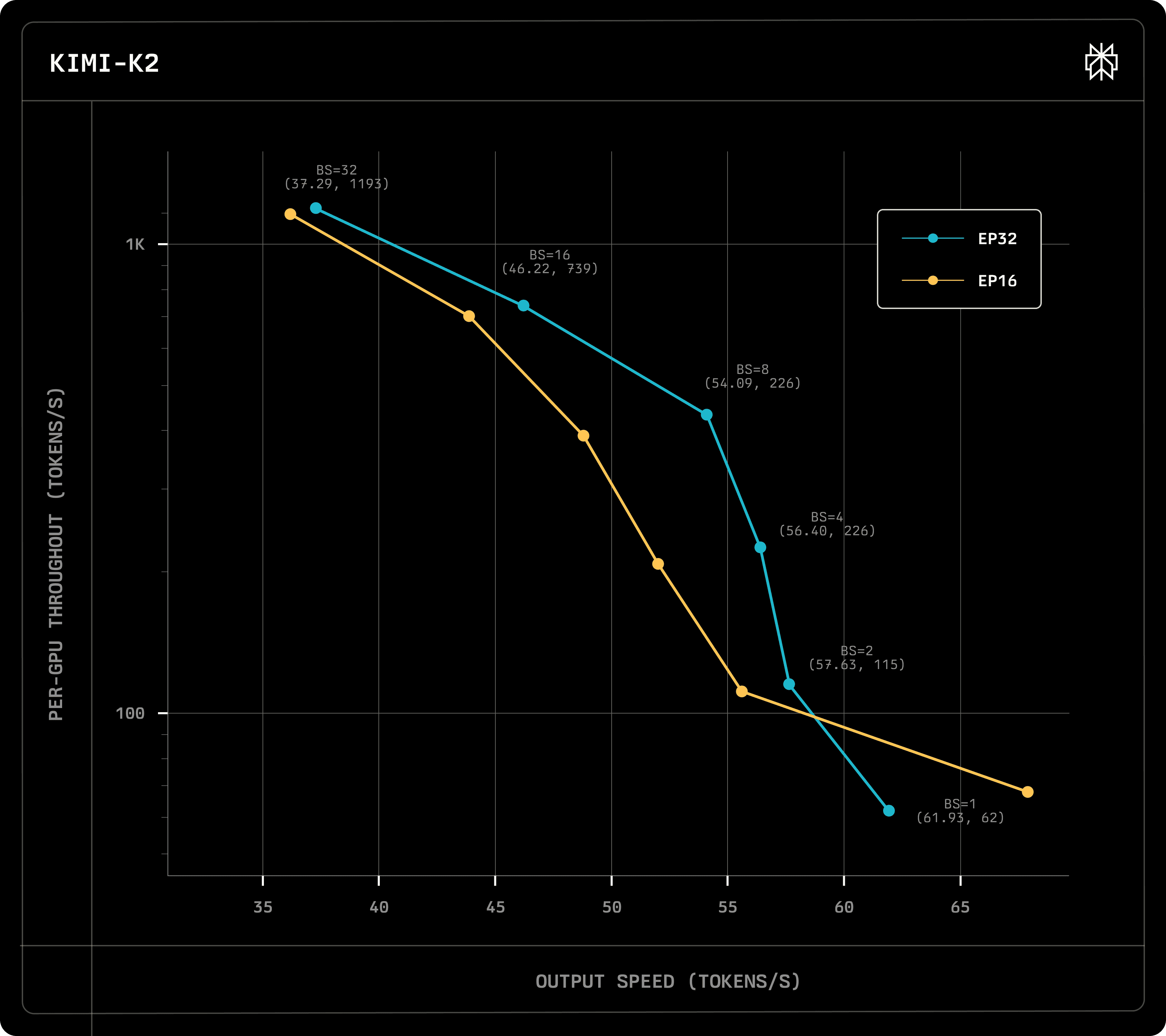
We have also considered micro-batching, albeit it only improved latencies at very high batch sizes or when using more than one draft tokens. To benefit from splitting grouped GEMM problems into two, token batch sizes must be sufficiently dense. The bulk of the time is still spent on MoE dispatch and combine, indicating that any further improvements to the kernels will consequently improve latencies and facilitate micro-batching.
Future Work
We are working closely with AWS engineers to improve the performance on EFA. On our end, we will be following updates to libfabric which will reduce the data plane overhead. Additionally, we will experiment with efa-direct to further reduce userspace overheads and interface directly with the hardware.