The Complexity Cliff: Why Reasoning Models Work Right Up Until They Don’t
We’ve trained models that score 90% on our hardest reasoning benchmarks. They solve complex mathematical proofs, write functioning code, and explain intricate scientific concepts. Yet the same models that ace standardized tests fail catastrophically when problems scale just slightly beyond their training distribution.
The gap between “reasoning” and “matching patterns” isn’t a spectrum. It’s a cliff.
The Paradox That Should Trouble Us
Researchers from Google DeepMind and OpenAI recently published findings that challenge our fundamental assumptions about reasoning models (Rameshkumar et al., 2024, arXiv:2510.22371). Their Deep Reasoning Dataset (DeepRD) reveals something unsettling: models don’t …
The Complexity Cliff: Why Reasoning Models Work Right Up Until They Don’t
We’ve trained models that score 90% on our hardest reasoning benchmarks. They solve complex mathematical proofs, write functioning code, and explain intricate scientific concepts. Yet the same models that ace standardized tests fail catastrophically when problems scale just slightly beyond their training distribution.
The gap between “reasoning” and “matching patterns” isn’t a spectrum. It’s a cliff.
The Paradox That Should Trouble Us
Researchers from Google DeepMind and OpenAI recently published findings that challenge our fundamental assumptions about reasoning models (Rameshkumar et al., 2024, arXiv:2510.22371). Their Deep Reasoning Dataset (DeepRD) reveals something unsettling: models don’t gradually degrade as problems get harder. They maintain high performance right up to a complexity threshold, then collapse entirely.
Consider: A model solving 10-step reasoning chains with 85% accuracy doesn’t drop to 70% at 15 steps or 50% at 20 steps. It maintains that 85% until around step 12, then plummets to near-random guessing by step 15.
This isn’t how reasoning works. When humans encounter harder problems, we slow down, make more mistakes, but generally degrade gracefully. We don’t suddenly forget how to think.
Measuring the Wrong Things
Our benchmarks mislead us systematically. When a model scores 90% on MMLU or 85% on ARC-AGI, we interpret this as “near-human reasoning.” But these benchmarks measure performance within a narrow complexity band. It’s like testing a car’s safety by only driving it at 25 mph.
The DeepRD study generated reasoning problems with controllable complexity - graph connectivity puzzles that scale from 5 nodes to 50, logical proofs that chain from 3 steps to 30. What they found challenges everything:
- Models maintain baseline accuracy until hitting their complexity ceiling
- The ceiling varies by architecture but always exists
- Beyond the ceiling, performance doesn’t degrade - it disintegrates
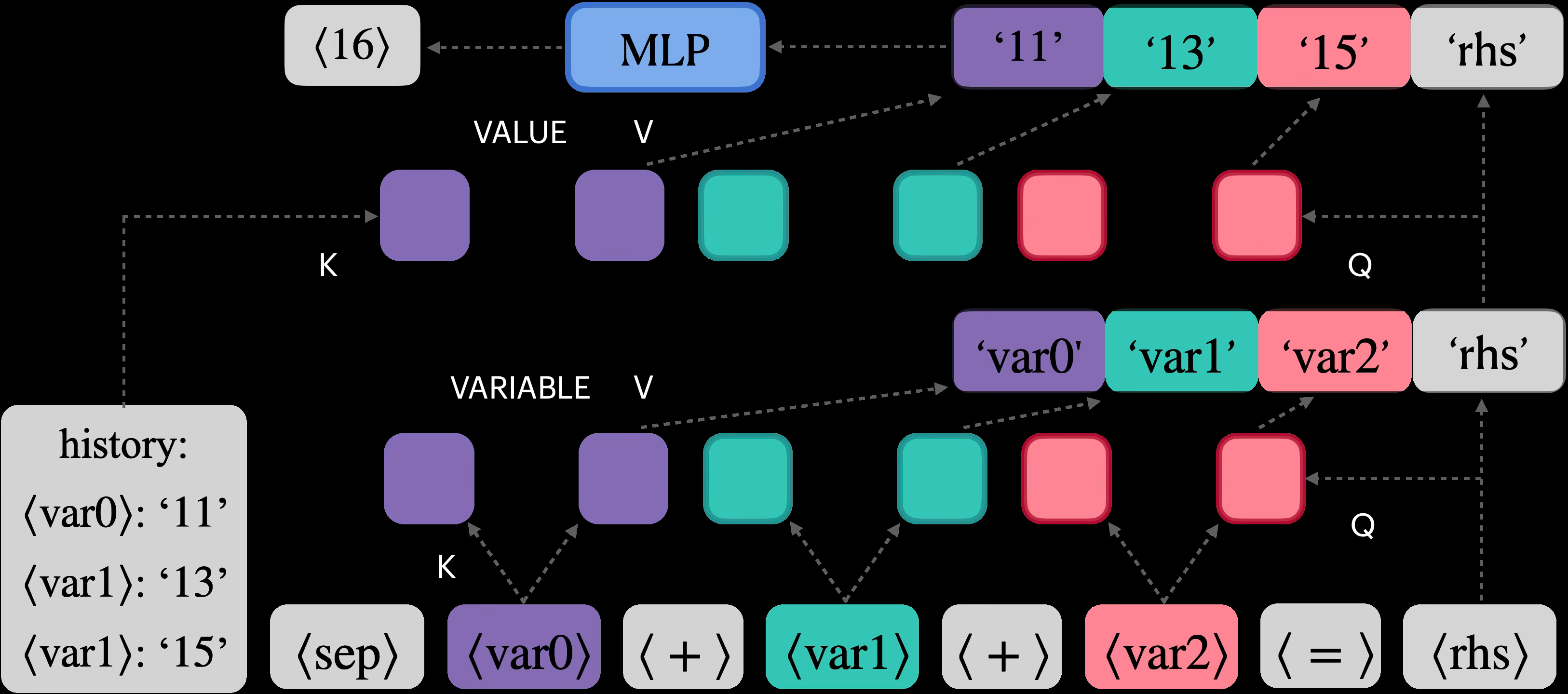 Figure 1: Model performance doesn’t gradually decline with complexity - it falls off a cliff. The sharp transition around 12-15 reasoning steps appears consistently across architectures.
Figure 1: Model performance doesn’t gradually decline with complexity - it falls off a cliff. The sharp transition around 12-15 reasoning steps appears consistently across architectures.
The Triple Failure: Composition, Domain-Specificity, and Robustness
When Reasoning Can’t Compose
The AgentCoMa study tested 61 language models on a seemingly simple task: combine different types of reasoning (Khandelwal et al., 2024). Take a model that’s 90% accurate at mathematical reasoning. Take the same model at 85% accuracy on commonsense reasoning. Ask it to do both together.
You’d expect maybe 75% accuracy - some degradation from juggling both.
Reality: 30% accuracy drop. The model doesn’t combine capabilities; it fragments them.
When Reasoning Actively Hurts
Here’s where it gets worse. In clinical settings, chain-of-thought prompting - our standard technique for improving reasoning - actually degrades performance. A comprehensive study of medical diagnosis tasks found that 86.3% of models performed worse with CoT than without it (Zhang et al., 2024).
The reasoning isn’t malfunctioning - it’s misdirecting. Models generate plausible-sounding medical reasoning that leads them away from correct diagnoses. They literally talk themselves out of the right answer.
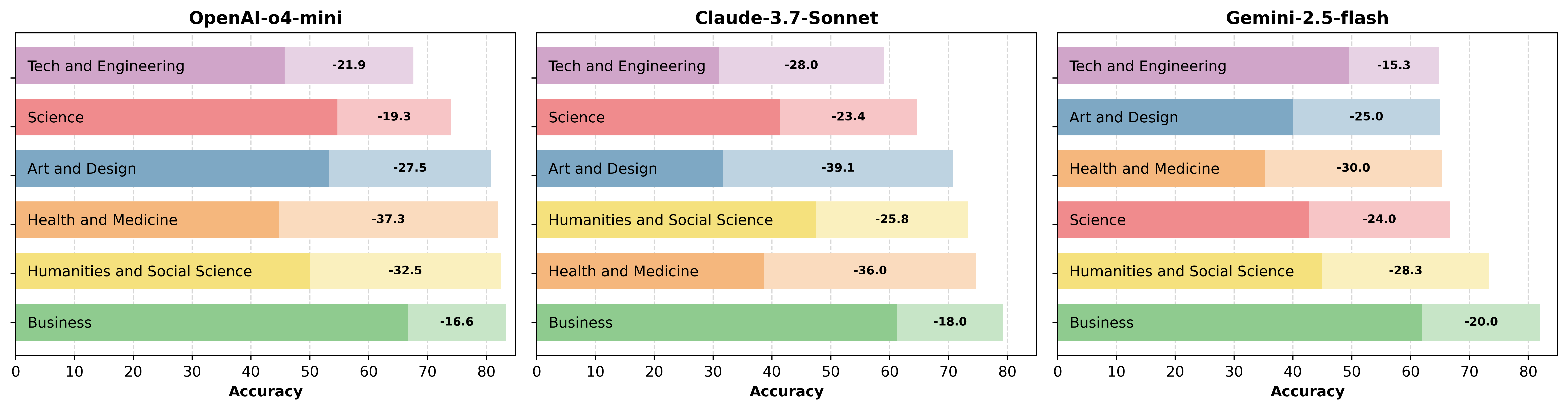 Figure 2: Models can be “gaslighted” into changing correct answers. Success rates of adversarial attacks range from 25-53% across different model families.
Figure 2: Models can be “gaslighted” into changing correct answers. Success rates of adversarial attacks range from 25-53% across different model families.
The Gaslighting Problem
Perhaps most disturbing: models can be manipulated into abandoning correct reasoning through what researchers call “gaslighting attacks” (Mirzadeh et al., 2024). Feed a model a problem it solves correctly. Then claim its answer is wrong and ask it to reconsider. Between 25% and 53% of the time, depending on the model, it will change its correct answer to an incorrect one.
This isn’t robustness failure - it’s reasoning without conviction. The model has no internal compass for truth, only patterns for generating text that seems reasonable.
The Economics Don’t Save You
The standard response: scale inference compute and let models think longer.
The Quiet-STaR approach tried this - giving models more inference-time computation to solve harder problems (Xie et al., 2024). Results at $200 per query:
- 32.03% accuracy on complex reasoning
- 554.66 seconds per problem
- 12.73 trillion FLOPs per solution
Compare this to human performance: similar accuracy, 30 seconds, essentially free. Scaling inference compute by 1000x bought us... nothing.
Where Solutions Actually Live
The research points to three promising directions, none of which involve simply scaling current architectures:
1. Meta-Learning for Compositional Reasoning
A 5.7M parameter meta-learned model matched 8B+ parameter general models on specific reasoning tasks (Lake & Baroni, 2024). The key: learning to compose primitives rather than memorizing patterns.
2. Architectural Innovation
Discrete bottlenecks and recursive latent spaces show genuine generalization to longer sequences (Webb et al., 2024). These aren’t tweaks - they’re fundamental redesigns of how information flows through the network.
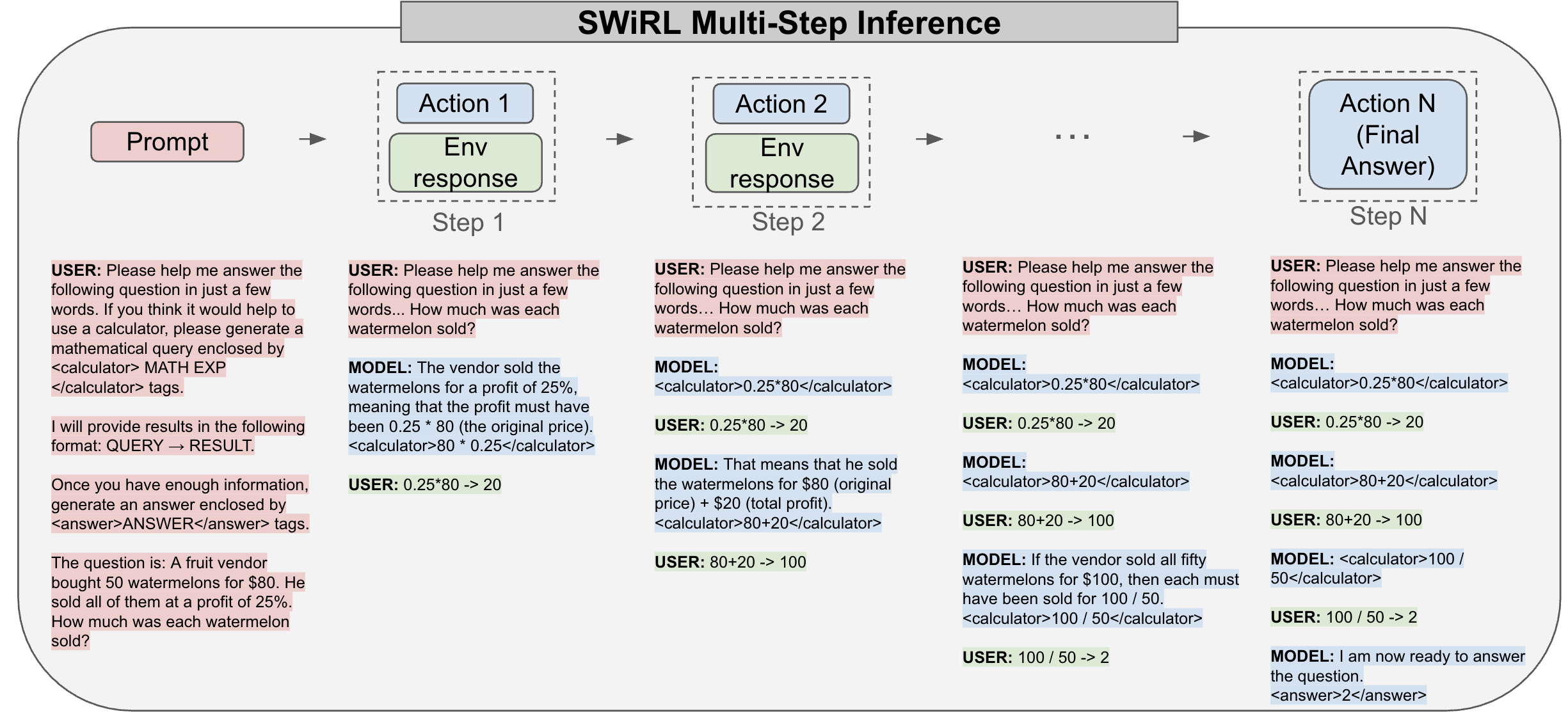 Figure 3: The SWiRL training methodology achieves 21.5% improvement on mathematical reasoning by teaching models to genuinely iterate rather than pattern-match.
Figure 3: The SWiRL training methodology achieves 21.5% improvement on mathematical reasoning by teaching models to genuinely iterate rather than pattern-match.
3. Domain-Specific Reasoning Modules
Instead of general reasoning, build specialized components. MERRY for knowledge graphs. SWiRL for mathematics. Clinical-specific architectures for medical diagnosis. Each achieves 15-30% improvements over general approaches (Chen et al., 2024).
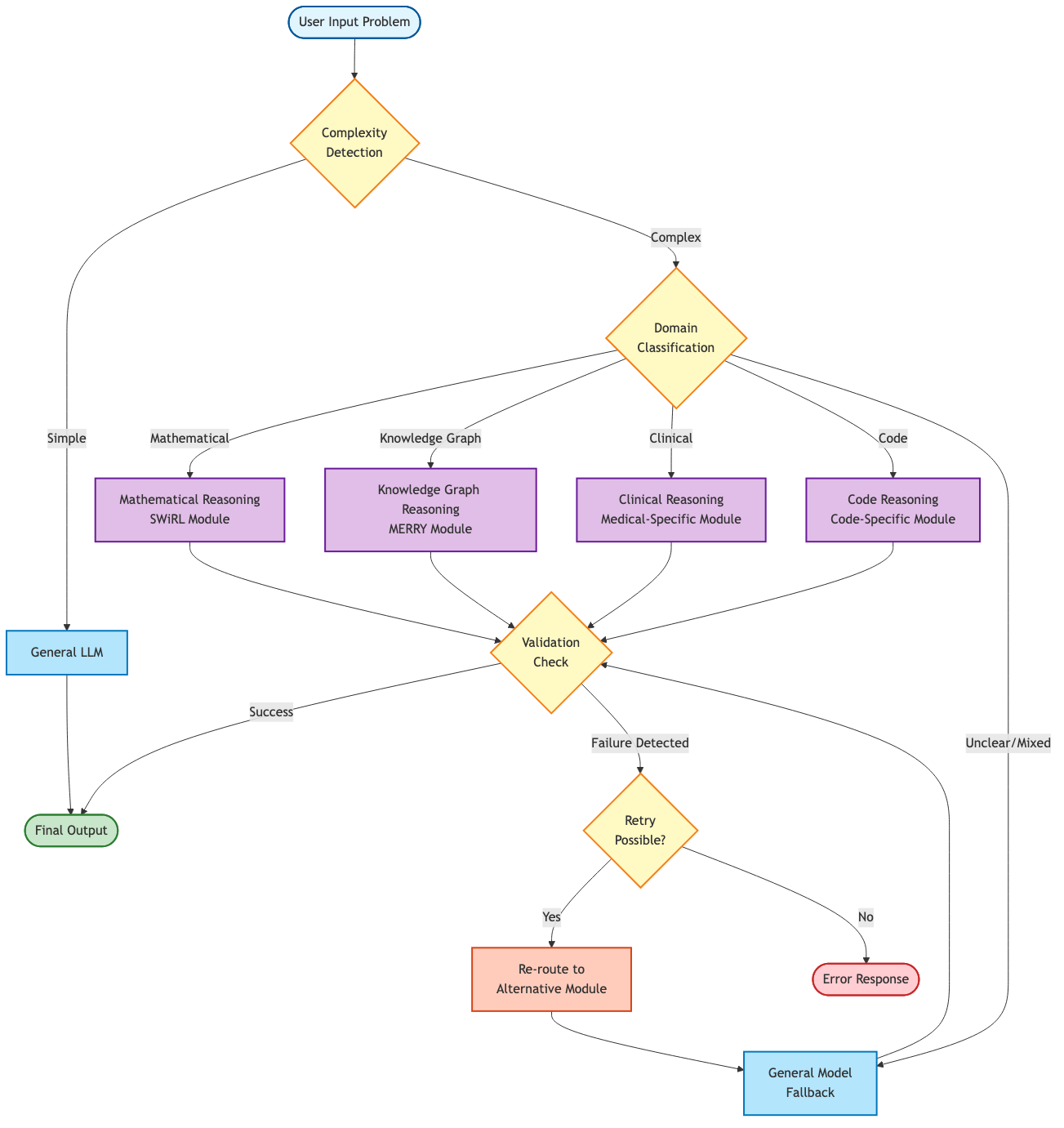 Figure 4: Specialized reasoning modules route problems based on complexity and domain detection, with fallback to general models when needed.
Figure 4: Specialized reasoning modules route problems based on complexity and domain detection, with fallback to general models when needed.
For Practitioners: Six Uncomfortable Truths
Test at scale boundaries: Your model performing at 95% accuracy on test sets means nothing if those tests don’t probe complexity limits. 1.
Expect cliff failures: Plan systems assuming sudden capability collapse, not gradual degradation. When reasoning models fail, they fail completely. 1.
CoT can hurt: In domains with nuanced reasoning (medical, legal, ethical), chain-of-thought may degrade performance. Test with and without. 1.
Robustness is orthogonal to accuracy: A 97.5% accurate model (GPT-4o) drops to 82.5% with simple numerical substitutions (Stolfo et al., 2024). High benchmark scores don’t imply stability. 1.
Inference scaling has limits: At 0.037percallforsimplereasoningto0.037 per call for simple reasoning to 200 for complex problems, the economics break before the reasoning improves. 1.
Hybrid architectures win: Route simple problems to small models, complex problems to specialized architectures, and accept that some problems remain unsolvable at any price point.
Production Routing System Example
Here’s how to implement intelligent model routing in production:
class ReasoningRouter:
"""
Production routing system that intelligently selects models based on:
- Problem complexity (token count, nesting depth)
- Domain detection (code, math, general reasoning)
- Historical performance patterns
- Cost optimization
"""
def analyze_problem(self, problem_text: str) -> ProblemAnalysis:
"""Analyze problem complexity and characteristics."""
# Estimate tokens (rough heuristic: ~4 chars per token)
estimated_tokens = len(problem_text) // 4
# Detect code snippets
code_patterns = [r'```[\s\S]*?```', r'def\s+\w+', r'class\s+\w+',
r'import\s+\w+', r'function\s*\(']
code_count = sum(1 for pattern in code_patterns
if re.search(pattern, problem_text))
# Detect mathematical expressions
math_patterns = [r'\d+\s*[\+\-\*/]\s*\d+', r'\\[a-zA-Z]+',
r'∫|∑|∏|√', r'x\^|y\^|z\^']
math_count = sum(1 for pattern in math_patterns
if re.search(pattern, problem_text))
# Calculate complexity score (0-1 scale)
complexity_score = min(1.0, (
estimated_tokens / 1000 * 0.3 +
code_count * 0.2 +
math_count * 0.2 +
self._calculate_nesting_depth(problem_text) / 10 * 0.3
))
return ProblemAnalysis(
complexity_score=complexity_score,
estimated_tokens=estimated_tokens,
detected_domains=self._detect_domains(problem_text),
requires_reasoning=complexity_score > 0.6,
code_snippets_count=code_count,
math_expressions_count=math_count
)
def route_request(self, problem_text: str, max_retries: int = 3) -> Response:
"""Route request to appropriate model with fallback logic."""
analysis = self.analyze_problem(problem_text)
# Select primary model based on analysis
if "code" in analysis.detected_domains:
primary_model = "codestral" # Specialized for code
elif "mathematics" in analysis.detected_domains:
primary_model = "gpt-4-code-interpreter" # Math tools
elif analysis.requires_reasoning:
primary_model = "o1-preview" # Deep reasoning
else:
primary_model = "gpt-4-turbo" # Fast general purpose
# Try primary model
response = self._call_model(primary_model, problem_text)
# Fallback logic if primary fails
if not response.success and max_retries > 0:
fallback_model = self._select_fallback(primary_model, analysis)
response = self._call_model(fallback_model, problem_text)
# Track metrics for adaptive routing
self._update_metrics(analysis, primary_model, response)
return response
This production system demonstrates key principles:
- Complexity detection using multiple heuristics
- Domain-specific routing to specialized models
- Fallback mechanisms for resilience
- Cost tracking to optimize spend
- Performance tracking for continuous improvement
The full implementation (669 lines) is available in the accompanying repository.
The Unresolved Core
Five questions the research can’t yet answer:
Is there a fundamental architectural limitation to Transformer-based reasoning? The consistency of failure patterns suggests yes, but no one has proven it mathematically. 1.
Can we predict the complexity cliff for a given model? Currently, we discover limits through exhaustive testing. We need theory. 1.
Why do models maintain high confidence while failing? Perplexity remains low even as accuracy craters. The models don’t know they don’t know. 1.
Is genuine compositional reasoning possible with current paradigms? Every attempt shows the same 30% degradation. Perhaps we need new paradigms entirely. 1.
What would it take to achieve human-like graceful degradation? Humans get slower and make more errors on harder problems. Models maintain speed and confidence while producing nonsense.
The Trajectory We’re On
The field is fragmenting - and that might be good. Instead of pursuing artificial general reasoning, we’re building artificial specialized reasoning. Models that excel within boundaries rather than pretending to transcend them.
This isn’t the narrative we wanted. We wanted models that reason like humans but faster. What we’re getting are tools that perform reasoning-like behaviors within carefully defined constraints.
For those deploying these systems: respect the cliff. Test at the edges. Build redundancies. And remember that a model that reasons well on your test set is still just matching patterns - right up until it doesn’t.
The real question isn’t whether reasoning models can match human intelligence. It’s whether we can build systems that fail gracefully when they inevitably hit their limits. Current evidence suggests we’re nowhere close.
 Figure 5: Exponential cost growth yields diminishing accuracy returns. The Quiet-STaR approach at $200 per problem performs worse than humans at near-zero cost.
Figure 5: Exponential cost growth yields diminishing accuracy returns. The Quiet-STaR approach at $200 per problem performs worse than humans at near-zero cost.
Based on analysis of 18 recent papers on reasoning model limitations. For technical details and citations, see the research repository.